
面向WCET分析的实时多核体系结构研究
2014-09-15 00:53陈芳园丁亚军张冬松任秀江
计算机工程与科学 2014年3期
陈芳园,丁亚军,张冬松,吴 飞,任秀江
(1.江南计算技术研究所,江苏 无锡 214083;2.中国人民解放军镇江船艇学院,江苏 镇江 212000;3.上海工程技术大学电子电气工程学院,上海 201620)
面向WCET分析的实时多核体系结构研究
陈芳园1,丁亚军1,张冬松2,吴 飞3,任秀江1
(1.江南计算技术研究所,江苏 无锡 214083;2.中国人民解放军镇江船艇学院,江苏 镇江 212000;3.上海工程技术大学电子电气工程学院,上海 201620)
随着工艺技术的发展以及嵌入式实时应用范围的不断扩大和需求的不断提升,多核处理器必将凭其高性能和低功耗特性应用到嵌入式实时领域中。但是,多核处理器体系结构很难甚至无法满足实时系统的实时限制和对WCET的可预测性要求。从多核中的共享资源入手,分析多核中的片上共享资源(共享Cache、片上互连)和片外共享资源(片外存储)对WCET分析的影响,探讨了各种干扰下的WCET分析方法。介绍了两种多核WCET分析模型:多核静态WCET分析模型和多核混合WCET分析模型;同时,针对嵌入式实时应用提出了多核设计原则。
多核体系结构;嵌入式实时系统;实时任务;WCET
1 引言
现实世界的实际需求促进了实时系统的产生和发展,随着电子技术和计算机技术的飞速发展,实时系统的应用范围也在不断扩大,如汽车、航空、远程通讯、空间系统、医疗图像和消费类电子设备等。这些领域的发展迫切需要提供性能更强大、操作更灵活、效能比更高的微处理器系统,以满足实时应用的需求。而当今处理器市场中的片上多核处理器[1]已以其强大的优势成为主流,其多核结构也必将应用到嵌入式实时系统,以满足实时系统日益增长的需求。当前,高端嵌入式应用正朝着多核处理器平台的方向不断发展[2]。例如,ARM11 MPCore[3]已经完成多核实现,包括8段流水线、Cache和动态分支预测等;IBM/Sony/Toshiba Cell体系结构[1, 4]也被应用于高性能嵌入式多核处理器中。可以预见,随着技术的发展和应用需求的增加,多核处理器也必将进入到嵌入式实时领域中,以促进嵌入式实时应用的大力发展。
尽管多核处理器可以为嵌入式系统带来诸多好处,但目前多核处理器却很难甚至不能应用于嵌入式实时系统中。这是因为实时系统必须保证任务满足时间限制,也就是说,实时系统的正确性不仅仅体现在程序执行的结果,还体现在任务的执行时间不能超过截止期的要求。其任务的执行如果不能满足对截止时间的要求,会降低系统服务的级别,甚至造成系统崩溃。因此,获得任务安全、准确的最坏情况执行时间WCET(Worst Case Execution Time)是至关重要的。通常研究者可以使用静态分析方法和基于测量的方法来计算WCET。但是,这些方法的精确性和有效性高度依赖于实际处理器平台的可预测性,也就是说,处理器体系结构决定了这些方法的实际可行性以及结果的精确性。研究表明,工业界仍在使用的WCET分析方法对于复杂的处理器结构,例如多核处理器体系结构,不再适用。这种对处理器体系结构的高度依赖性引起了设计者对WCET分析的关注。
事先获知任务的WCET估值是实时系统调度及可调度性分析的前提,也是检查实时系统的性能是否满足要求的依据。研究者已经对WCET分析深入研究了几十年[5],然而,这些研究都假设每个任务的WCET是可确定的,然后基于WCET进行全局的调度分析[6]。这种方法对于单核处理器系统和传统的具有独立存储的多处理器来说是有效的。随着处理器体系结构的发展,研究者开始考虑Cache、流水线和分支预测对单个任务执行时间的影响[7,8]。然而,此时的WCET分析仍然假设任务是独立的,不会产生相关性或资源共享。文献[9,10]也只考虑了单核结构中任务抢占引起的Cache效果。随着复杂的多核体系结构的出现以及多核在嵌入式实时中应用的必然趋势,嵌入式实时系统的WCET的分析变得越来越复杂,无法再保证WCET的可确定性。在当前的具有共享资源的多核结构中,例如对共享的、复杂存储结构的访问,每个任务的WCET取决于全局系统调度,任务之间对共享资源的干扰给时序分析提出了挑战,以往传统的WCET分析将不再适用于多核结构。
多核的片上共享资源和片外共享资源的处理方式对时间的可预测性有着重要的影响,例如共享二级Cache、片上互连、片外存储等,这些硬件共享资源使得实时系统中的WCET分析越来越复杂,随着多核处理器在嵌入式实时应用领域中的应用越来越广泛,这个问题亟待解决。
2 实时多核体系结构中Cache敏感的WCET分析
处理器和主存储器间的速度差距对多核而言是一个突出的矛盾,为了缓解访存性能瓶颈,多核处理器通常设置包括Cache和局部存储器等在内的多级存储层次。但是,在多核处理器中内核共享Cache等存储资源,对于嵌入式实时系统而言,对这些资源的共享和竞争除了会进一步影响到处理器性能的提高外,多核中并行任务在共享存储上的竞争还会导致任务间的干扰,这种干扰使得多核系统的时序可预测性变得更加复杂。
在多核结构中,运行在一个核上的任务可能会破坏二级Cache中的一些数据,而这些数据正是运行在另一个核上的任务所需要的。因此,在多核结构中,任务的最坏情况执行时间不能与其他任务分离开孤立地进行估计,这一点与单核处理器系统截然不同。从本质上讲,多核面临的挑战是模拟和预测运行在不同核上的并行程序的Cache行为(这不同于单核处理器系统中的顺序程序),实时多核系统中WCET估计的最大问题就是如何预测Cache行为。因此,任务的WCET不能再与其他任务分离开独立地进行分析,无法利用单核针对Cache的WCET分析方法。
目前还很少有研究考虑多核平台中的WCET分析。在多核结构中,有一些任务在执行时会产生大量的存储到二级Cache的访问,如果在调度时减少这种线程的同时调度,则可以降低二级Cache竞争[11]。Anderson J H等人[12,13]使用这种策略来提高Cache性能,以满足实时限制。这些工作假设实时线程的WCET事先已知。然而,事实上尽管提高Cache性能可以直接降低平均执行代价,但是在这些系统模型中仍然很难获得每个实时线程的WCET。
WCET领域的研究者认为,在共享Cache的多核结构中,设计一个可以精确捕捉多核竞争的分析方法非常困难。当前,只有文献[14~16]研究了共享Cache的多核中的WCET。
文献[14]为了避免多核中由二级Cache引起的干扰问题,利用page-coloring技术以及调度策略将Cache进行了划分,该研究将并行运行的硬实时任务的Cache分离开来,从而消除了任务间的干扰。文献[15]基于共享Cache的多核平台分析了线程间的Cache冲突,探讨了共享二级Cache的多核结构中的WCET分析问题。但是,该研究基于的是一个直接映射的二级指令Cache,当今的多核结构一般采用的是组相连Cache;其次该研究只探讨了双核结构、两个任务(一个硬实时任务,一个非硬实时任务)下的WCET估计,当核的数量和任务数量增加时其分析不再有效。文献[16]描述的方法无法扩展任务大小和任务数量。
多核中共享Cache导致最坏情形的不可预测性和不可分析性主要是由体干扰[15]引起的。在Cache结构中为了可以进行并行操作通常将Cache划分为多个体,当两个存储请求试图同时访问同一个体时,片上互连仲裁器为了避免冲突将把一个访问操作延迟一段时间。这种影响称为体干扰或者体冲突。如图1所示。

Figure 1 Bank interruption图1 体干扰
在图1中,两个线程同时访问同一个存储体M1,在仲裁器的仲裁下第二个线程被延迟了数个时钟周期。针对这种干扰设计者需要确定这种干扰引起的上界延迟UBD(Upper Bound Delay)的大小。该延迟要根据任务的类型(实时任务、非实时任务)区别分析。一般对于实时系统而言,实时任务的优先级高于非实时任务的优先级,在这个原则下实时任务不会受到非实时任务的影响。但是,也存在一种情况使得非实时任务影响实时任务的访问:在实时任务访问Cache的前一个时钟周期恰好有一个非实时任务对Cache进行了访问。此时,该实时任务必须等待非实时任务完成才可以开始Cache访问,则实时任务由于非实时任务的影响而延迟的时间为:
UBDNHRT=Lbank-1
(1)
其中,Lbank指Cache体访问时间。
另一方面,实时任务由于其他实时任务而需要等到其他实时任务请求完成,则由实时任务引起的上界延迟为:
UBDHRT=(NHRT-1)·Lbank
(2)
其中,NHRT指多核中的核数目或Cache仲裁中的缓冲队列大小。
综合两种影响可以得到当前实时任务由于共享Cache访问竞争而引起的上界延迟为:
UBD=(NHRT-1)×Lbank+
Lbank-1 =NHRT×Lbank-1
(3)
公式(2)中考虑的任务优先级仲裁策略使用的是Round-Robin。而在嵌入式实时系统中,任务的优先级一般是固定的,此时实时任务的延迟应与其优先级相关,优先级最大的实时任务无论何时都会优先执行,其延迟只会出现公式(1)中的情况,并且此时该任务可以是非实时任务也可以是实时任务。而对于优先级最低的实时任务,其延迟可以由公式(3)确定,对于中间级别的实时任务需要针对其优先级来分析,但是其延迟大小却无法确定。
3 实时多核体系结构中片上互连敏感的WCET分析
在多核结构中,多个任务可以在每个核上并行执行,并行任务会同时对片上互连发出请求。当片上互连接受某个任务的访问请求时,根据互连的方式来决定访问请求的授权。此时,一个线程可能会延迟另一个线程的执行时间,即产生互连干扰(或通信冲突)。这种干扰使得在进行多核的WCET估计时,相对于单核中的独占总线而言,变得比较复杂。
目前针对总线干扰复杂化WCET分析的问题主要有两种解决方法:一是消除总线竞争,二是简化总线仲裁策略。
对于消除总线竞争,文献[17]提出了一个系统级任务映射与调度的框架。在这个研究中,为了避免有关总线竞争的问题,设计者使用了所谓的附加总线模型,即假定任务的执行时间与总线内存访问竞争影响很小。在这种模型下设计者忽略了总线竞争对任务执行时间的影响。作者的实验表明,在总线负载小于50%时这种模型具有较好的近似性。但是,这种方法存在两个严重的问题:(1)为了使附加模式可用必须保持较低的总线利用率;(2)即使在较低的总线利用率情况下也无法对任何最坏的行为提供可靠的保证。
线程由于总线干扰所引起的延迟与总线仲裁策略密切相关。可以请求访问总线的实例称为总线Master。目前有设计者对简化总线仲裁策略展开了研究,由多种总线仲裁策略来处理多个总线Master请求,控制总线访问顺序的中央总线仲裁器具有一定的确定性。每个请求访问总线的Master必须获得仲裁器的授权才可以开始访问总线。
对于Round-Robin仲裁策略,一个实时任务的最大延迟界定于同时请求总线的任务总数。图2显示了多个实时任务同时向总线发出请求的情形。
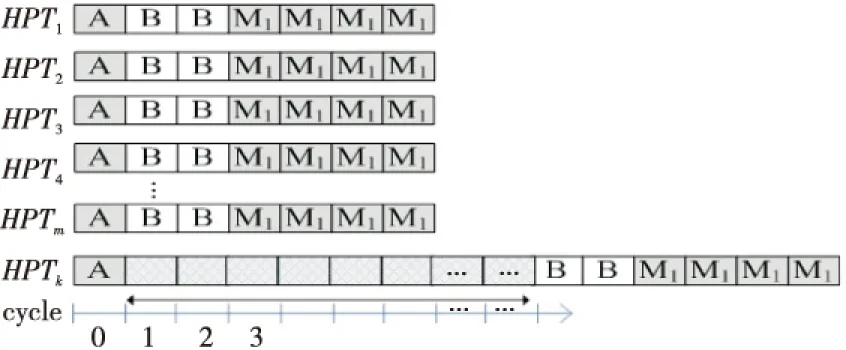
Figure 2 Bus interruption图2 总线干扰
此时实时任务的等待时间取决于其在请求队列中的位置。对于HRTk而言,必须等待前面的任务都完成了才会获得总线使用权,并且在这期间其他任何新的总线请求都会在HRTk之后执行。所以,对于一个实时任务,当该任务恰好处于实时任务请求队列的最后时,其延迟最大。所以,一个实时任务的上界延迟为:
UBDHRT=(NHRT-1)×Lbus
(4)
其中,NHRT是同时运行的硬实时任务数,一般是多核结构中的内核数量;Lbus是总线完成一个请求的时间。
一般对于实时系统而言,实时任务的优先级高于非实时任务的优先级,在这个原则下实时任务不会受到非实时任务的影响。但是,与Cache中类似,也存在一种情况使得非实时任务影响实时任务的访问:在实时任务访问总线前一个时钟周期恰好有一个非实时任务对总线进行了访问。则此时实时任务由于非实时任务而延迟的时间为:
UBDNHRT=Lbus-1
(5)
综合实时任务和非实时任务请求,实时任务的上界延迟为:
UBD=Lbus-1+(NHRT-1)×
Lbus=NHRT×Lbus-1
(6)
根据底层硬件结构分析中得到的这个总线请求上界延迟,在静态分析的计算阶段加入这个影响即可得到一个实时任务安全的WCET。
在多核结构中,基于总线的WCET估计方法已经展开了初步的研究;对于其他互连方式,由于实际应用的限制,目前并未有相关的研究。但是,随着工艺和计算机技术的高速发展,多核中的核数目将越来越多,其互连结构也将由简单的、只能处理单一请求的总线转变为结构复杂、可以同时处理多个请求的片上网络、交叉开关、点到点通信等片上互连结构。
4 实时多核体系结构中片外存储敏感的WCET分析
之前的研究都是集中在由访问片上资源而引起的干扰(共享二级Cache、片上互连),而在多核结构中片外共享存储对任务执行时间以及WCET估计也有很大的影响。文献[15,16]等关注于WCET估计中由片上共享资源引起的干扰,例如Cache和总线。然而,在多核结构中由片外共享存储系统引起的干扰对任务的执行时间和WCET估计也有着非常重要的影响[18],所以在多核的WCET分析中设计者需要考虑由片外存储引起的干扰影响。
目前针对片外共享存储也有相关的研究,AkessonB等人[19]设计了一个片上多处理器的存储控制器Predator,该存储控制器给每个任务分配了指定的带宽,同时要求用户指定每个任务的优先级,PaolieriM等人在硬实时多核系统设计了一个可预测的存储控制器AMC,该控制器可以减少WCET估计中的存储干扰因素,提供了一个可预测的存储访问时间,可以实现紧凑的WCET估计计算。
基于多核的片外共享存储资源,研究者展开了片外存储可预测控制器的研究,针对某种常用的存储设备设计一个存储控制器,在保证可预测的前提下获得一个较好的性能。研究者在其设计中分析存储请求的执行时间,计算存储请求的上界延迟UBD对WCET估值的影响,最后进行WCET分析。
(1)存储请求的执行时间。
不同的存储操作有不同的延迟,存储读操作和存储写操作的延迟已在特定的存储设备中设定。定义tIL为存储请求由于前一个请求而延迟的最大时间值。tIL的大小与下列两个因素密切相关:①在同一体中激活两个连续的行的最小时间间隔tIB;②数据总线用于传输请求的时间,即tBURST×Nbanks(Nbanks是指存储设备的体个数)。所以,对于同一体的两个活动间的最小间隔时间tIB至少等于tRC。然而,根据之前的请求类型的不同(例如读或写操作),tIB会随之改变,因此产生了四种类型的延迟:tILRR:前一个请求是读操作,当前操作也是读操作;:tILRW前一个请求是读操作,当前操作是写操作;tILWW前一个请求是写操作,当前操作也是写操作;tILWR前一个请求是写操作,当前操作是读操作。
(2)计算存储请求UBD。
在计算WCET估计时需要考虑每个存储请求最大可能的tIL,定义为:
tILWORST=max{(tILRR,tILRW,tILWW,tILWR}
(7)
此时无需再考虑所有任务的存储访问序列在WCET计算中引起的存储干扰影响,因为最坏情形已经考虑过。因此,存储请求的UBD取决于tILWORST和同时运行的实时任务和非实时任务产生的干扰。假定实时任务的优先级高于非实时任务的优先级,而在实时任务间采用循环策略,则上界延迟UBD可以定义为:
①针对实时任务,最坏的情况是多核中同时执行的所有实时任务同时发出访存请求,此时任务的最大延迟由同时执行的实时任务数界定,即:
UBDHRT=(NHRT-1)×tILWORST
(8)
②即使实时任务的优先级高于非实时任务,但是也有可能恰好在非实时任务请求发送到主存后一个时钟周期时到达,此时最大延迟由tILWORST界定,即:
UBDNHRT=tILWORST-1
(9)
综上所述,实时任务存储请求的最大延迟为:
UBD=UBDNHRT+UBDHRT=
NHRT×tILWORST-1
(10)
利用WCET计算模式在WCET分析中加入UBD因素,即在分析实时任务时,将每个任务独立运行,但是存储控制器在该任务进行存储访问时总是将该操作延迟UBD。此时,该任务的执行模式考虑了该任务所有可能受到的、来自其他任务的、最坏情况下的最大延迟。
5 实时多核系统中的WCET模型
对于多核而言,传统的针对单核结构的WCET估计技术不再适用于现在复杂的多核处理器结构,因此,需要对WCET针对新的体系结构特性进行分析。对于复杂的硬件结构而言,动态硬件模拟仍然存在很多问题,WCET估计分析时间较长,并且有可能产生较大的WCET估计。而静态WCET分析可以获得安全的上限值。因此研究者试图使用静态分析方法或者混合的方法来进行多核的WCET估计,在混合方法中使用测量的方法来增强或替代底层静态分析。针对多核复杂的硬件结构和已有的成熟的单核WCET估计方法,可以通过采用混合的WCET估计方法来对多核结构进行WCET估计,这样不仅可以节约时间,有效利用已有技术和方法,而且可以使设计者更专注于底层硬件结构的分析。文献[13]采用以下步骤设计了一个多核系统中的混合WCET估计模型:
(1)针对多核中的共享资源(片上共享资源Cache和总线、片外共享存储资源),分析这些共享资源给任务执行带来的影响,计算任务最大延迟时间:上界延迟UBD。
(2)在多核硬件结构中设置一个延迟表和一个延迟部件,延迟表用于记录上界延迟UBD,延迟部件用于将任务访问贡献资源的操作进行延迟,延迟大小为对应的延迟表中记录的UBD。
(3)使用WCET计算模型进行WCET估计,即:在底层硬件多核结构中将每个任务单独执行(与任务在单核中独立执行一样),但是在执行的过程中将任务每个访问共享资源的操作延迟一定的时间。
在该WCET估计模型中将任务在最坏情形下执行:任务每次访问共享资源都受到干扰,都需要延迟一段时间,这种计算模型考虑了该任务所有可能受到的、来自其他任务的、最坏情况下的最大延迟,所以在该情形下一定可以保证WCET估计的有效性。
虽然上述模型可以得到一个有效的WCET估计,但是对其精度和效率都还没有进行研究和比较,所以还需要对WCET分析的精度和WCET分析方法的性能进行研究。
6 结束语
实时系统必须保证任务满足时间限制,通常研究者可以使用静态分析方法和基于测量的方法来计算WCET。但是,这些方法的精确性和有效性高度依赖于实际处理器平台的可预测性,也就是说,处理器体系结构决定了这些方法的实际可行性以及结果的精确性。工业界仍在使用的WCET估计分析方法对于复杂的处理器,例如多核处理器,不再适用,这是由于多核结构中的共享资源使得实时任务间互相产生了干扰,任务的执行时间和WCET不能再独立进行分析。多核中的多任务在同时运行时由于竞争共享资源,例如共享Cache、片上互连、片外存储,使得任务的最坏情况下执行时间无法再利用单核中的WCET分析方法得到,设计者需要针对多核中的共享资源重新进行WCET分析。
对于一个应用于实时系统的多核结构而言,其最重要的一个因素是要保证可预测性,即一个任务在多核中运行可以预测出其WCET以进行后续的实时任务调度。多核时序可预测结构的设计原则是要在嵌入式硬实时系统中保证可预测性、较好的最坏情况下性能。在进行可预测实时多核设计时应尽量遵循如下原则[20]:
(1)结构与应用相关,即针对特定的嵌入式硬实时系统进行多核结构设计,在提高最坏情况下性能的同时保证可靠的、精确的可预测性。
(2)简化设计中的部件结构,在保证可预测性的前提下将那些与性能无关的特性取消。例如,在以存储系统性能界定系统性能的系统中可以尽量简化流水线结构。
(3)尽量减少系统中共享资源的干扰,可以在不影响性能的前提下尽量避免构建共享Cache或存储。
在将应用程序集映射到目标体系结构中时尽量避免引入应用程序间的共享干扰。
[1] International technology roadmap for semiconductors 2008 update[EB/OL].[2008-08-21]. http://public.itrs.net.
[2] Davis R I, Burns A. A survey of hard real-time scheduling algorithms and schedulability analysis techniques for multiprocessor systems[R]. Technical Report YCS-2009-443, Department of Computer Science University of York, 2009.
[3] Hirata K, Goodacre J. Arm mpcore:The streamlined and scalable arm11 processor core[C]∥Proc of Design ASP-DAC’07, 2007:747-748.
[4] Pham D C, Aipperspach T, Boerstler D, et al. Overview of the architecture, circuit design, and physical implementation of a first-generation cell processor[J]. IEEE Journal of Solid-State Circuits, 2006,41(1):179-196.
[5] Puschner P, Burns A. A review of worst-case execution-time analysis[J]. Real-Time Systems, 2000,18(2/3):115-127.
[6] Thiele L, Wilhelm R. Design for timing predictability[J]. Real-Time Systems, 2004,28(2/3):157-177.
[7] Li Y T S, Malik S, Wolfe A. Cache modeling for real-time software:Beyond direct mapped instruction caches[C]∥Proc of IEEE Real-Time Systems Symposium, 1996:254-263.
[8] Theiling H,Ferdinand C,Wilhelm R.Fast and precise WCET prediction by separated cache and path analysis [J]. Real-Time Systems, 2000,18(2/3):157-179.
[9] Ramaprasad H, Mueller F. Bounding preemption delay within data cache reference patterns for real-time tasks[C]∥Proc of Real-Time and Embedded Technology and Applications Symposium, 2005:71-80.
[10] Staschulat J, Schliecker S, Ernst R. Scheduling analysis of real-time systems with precise modeling of cache related preemption delay[C]∥Proc of ECRTS’05, 2005:41-48.
[11] Fedorova A, Seltzer M, Small C, et al. Throughput-oriented scheduling on chip multithreading systems[R]. Technical Report TR-17-04, Cambridge:Harvard University, 2005.
[12] Anderson J H, Calandrino J M. Parallel real-time task scheduling on multicore platforms[C]∥Proc of RTSS’06, 2006:89-100.
[13] Calandrino J M, Anderson J H. Cache-aware real-time scheduling on multicore platforms:Heuristics and a case study[C]∥Proc of ECRTS’08, 2008:299-308.
[14] Nan Guan, Stigge M, Wang Yi, et al. Cache-aware scheduling and analysis for multicores[C]∥Proc of EMSOFT’09, 2009:245-254.
[15] Paolieri M, Quinones E, Cazorla F J, et al. Hardware support for WCET analysis of hard real-time multicore systems[J]∥ACM SIGARCH Computer Architecture News, 2009,37(3):57-68.
[16] Rosen J, Andrei A, Eles P, et al. Bus access optimization for predictable implementation of real-time applications on multiprocessor systems-on-chip[C]∥Proc of Real-Time Systems Symposium, 2007:49-60.
[17] Bertozzi D, Guerri A, Milano M, et al. Communication-aware allocation and scheduling framework for stream-oriented multi-processor systems-on-chip[C]∥Proc of DATE’06, 2006:3-8.
[18] Burger D, Goodman J R, Kägi A. Memory bandwidth limitations of future microprocessors[C]∥Proc of ISCA’96, 1996:78-89.
[19] Akesson B,Goossens K,Ringhofer M.Predator:A predictable SDRAM memory controller[C]∥Proc of CODES+ISSS, 2007:251-256.
[20] Wilhelm R, Grund D, Reineke J, et al. Memory hierarchies, pipelines, and buses for future architectures in time-critical embedded systems[J]. IEEE Transactions on Computer-aided Design of Integrated Circuits and Systems, 2009,28(7):966-978.
CHEN Fang-yuan,born in 1982,PhD,engineer,her research interests include computer architecture, and real-time system.
Research of real-time multi-core architecture for WCET analysis
CHEN Fang-yuan1,DING Ya-jun1,ZHANG Dong-song2,WU Fei3,REN Xiu-jiang1
(1.Jiangnan Institute of Computing Technology,Wuxi 214083;2.Zhenjiang Watercraft College of PLA,Zhenjiang 212000;3.College of Electronic and Electrical Engineering,Shanghai University of Engineering Science,Shanghai 201620,China)
With the development of technology and the increasing growth of applications and requirements in embedded real-time systems, multi-core processors will be adopted in embedded real-time systems for its high performance and low power features. However, the multi-core architecture is hard, even impossible to satisfy the requirement of real-time and the predictability of WCET. Starting with the shared resources, we analyze the influence of on-chip shared resources and off-chip resources on WCET analysis, and discuss various WCET methods. Two WCET models are introduced: multi-core static WCET model and multi-core hybrid WCET model. At last, the multi-core design rule for the real-time application is proposed.
multi-core architecture;embedded real-time system;real-time task;WCET
2013-10-12;
2013-12-20
国家自然科学基金资助项目(61272097);上海市教委科研创新重点基础研究项目(12ZZ182)
1007-130X(2014)03-0393-06
TP303
A
10.3969/j.issn.1007-130X.2014.03.003

陈芳园(1982-),女,湖北钟祥人,博士,工程师,研究方向为计算机体系结构和实时系统。E-mail:fychen@nudt.edu.cn
通信地址:214083 江苏省无锡市江南计算技术研究所
Address:Jiangnan Institute of Computing Technology,Wuxi 214083,Jiangsu,P.R.China
猜你喜欢
测控技术(2018年6期)2018-11-25
测控技术(2018年8期)2018-11-25
铁道通信信号(2018年2期)2018-04-18
电镀与环保(2016年3期)2017-01-20
系统工程与电子技术(2016年4期)2016-08-24
现代防御技术(2016年1期)2016-06-01
海军航空大学学报(2015年1期)2015-11-11
空间控制技术与应用(2015年4期)2015-06-05
电子设计工程(2015年8期)2015-02-27
单片机与嵌入式系统应用(2014年9期)2014-03-11
