
基于CRF的中文评论有效性挖掘产品特征*
2014-09-14 01:35蔡敦波吴云韬
计算机工程与科学 2014年2期
吕 品,钟 珞,蔡敦波,吴云韬
(1.武汉理工大学计算机科学与技术学院,湖北 武汉 430070;2.武汉工程大学计算机科学与工程学院,湖北 武汉 430073;3.武汉工程大学智能机器人湖北省重点实验室,湖北 武汉 430073)
基于CRF的中文评论有效性挖掘产品特征*
吕 品1,2,3,钟 珞1,蔡敦波2,3,吴云韬2,3
(1.武汉理工大学计算机科学与技术学院,湖北 武汉 430070;2.武汉工程大学计算机科学与工程学院,湖北 武汉 430073;3.武汉工程大学智能机器人湖北省重点实验室,湖北 武汉 430073)
方面级意见挖掘的任务通常包括从客户评论中抽取产品的特征、与产品特征相关联的观点词识别以及观点的极性判断三个方面。围绕如何实现中文评论的方面级意见挖掘问题,提出了利用条件随机场实现中文评论的方面级意见挖掘的四个主要步骤:数据预处理、训练集准备、为条件随机场模型定义学习函数、应用模型标注新的评论数据。在此基础上,通过以五种实际产品的中文评论语料为数据集,对该方法进行了数据实验。实验结果表明,该方法针对不同类型观点元素的抽取在评估性能指标上大部分达到或超过80%。为了进一步验证所提出方法的有效性,将研究结果进行了差异显著性检验。结果显示,用CRF对中文评论进行方面级意见挖掘和对英文评论的方面意见挖掘的性能差异不大。最后,比较了三种不同方法的方面抽取精度和情感分类精度,实验结果表明,CRF方法优于词典化的隐马尔可夫模型和关联规则挖掘方法。
条件随机场;方面级意见挖掘;观点元素
1 引言
随着Web上社会媒体(评论、论坛讨论、博客和社会网络)爆炸性的增长,许多个人和组织都想利用这些媒体上的内容为自己的决策作支持。然而,由于各种各样的网站大量出现,寻找、监测和抽取这些网站中的信息是一个艰巨的任务。为了解决这一问题,许多研究者提出了各种各样的Web意见挖掘方法,旨在从这些媒体中发现必要的信息并把它们呈现给用户。绝大多数意见挖掘方法可以归为两大类:篇章级意见挖掘和方面级意见挖掘。方面级意见挖掘中所指的方面可以是被评论产品的某个物理组成部分、功能或性质,亦可以是被评论事件的某一个特征等。篇章级意见挖掘主要解决一篇文档的总体观点极性;方面级意见挖掘主要解决从句子中发现方面然后找出与该方面相联系的观点。显然,篇章级意见挖掘不能向用户提供观点持有者对某一实体各方面的评价信息。为了获得这样的详细信息,方面级意见挖掘日趋成为情感分析领域的一个研究热点。
以英文语料为研究对象的方面级意见挖掘早在2004年就被提出,研究者已经取得一些初步成果,而针对中文的研究还处于起步阶段。不断增长的中文评论已经成为互联网上一个重要的组成部分,为了给企业和个人提供更为方便的工具,自动化和智能化地挖掘中文评论中的有价值信息是非常必要的。但是,由于中英文语言存在着较大的差异,目前针对英文评论的研究成果很多无法直接应用于中文评论。这些差异的主要根源在如下一些问题上:(1)文化差异导致语言表达方式不同;(2)语言结构的差异;(3)中英文词汇语法的差别。
本文正是在中英文语言存在差异的条件下,探索中文评论中意见挖掘中的信息提取技术。通过研究如何在方面级意见挖掘的三个任务中运用条件随机场模型,把目前主要面向英文的评论挖掘方法拓展到中文,从而解决中文环境下,如何对客户评论中所隐含的信息进行自动挖掘的问题。
2 相关研究背景
2.1 基于频率统计的挖掘方法
此方法是2004年Hu和Liu等人[1]首次提出的。它的基本原理是:(1) 使用关联规则挖掘算法、压缩修剪、冗余修剪等技术抽取频繁名词或名词短语作为方面,如“价格”作为被评价实体的方面;(2)识别与这些频繁方面最近的观点词,如价格的“高”或“低”;(3)形成一个基于被评价实体各方面的意见文摘系统。此方法最大的优点是通常领域独立或语言独立,思想简单,易实现,并且不需要训练数据集。但是,它也有一定的局限性,如:不能自动识别观点的强度,不能很好处理隐含的方面表达。从2005年至今,许多研究者对该方法进行了各种改进,但这些改进工作由于其针对的对象不同也各有其局限性。
2.2 基于监督学习的挖掘方法
Li等人[2]提出了一种基于依存语法图的监督学习方法抽取(方面,观点)信息对。他们在电影评论数据集上评估了该算法,并把得到的结果与Hu等人的方法进行了比较。结果显示他们所提方法的F-measure为52.9%,高于Hu等人方法的F-measure(48.8%)。CRF(Conditional Random Field)模型是另一种基于监督的挖掘方法,在产品评论挖掘中有潜在的优势。因为它通过定义最大化条件概率p(Y|X),选择一个标签序列Y标注一个观察序列X。显然,CRF能考虑被评价实体的任意方面,而且不需要条件独立假设。该特性使得CRF广泛使用于传统的信息抽取任务,如词性标注和解析、命名实体的识别等。近来,有部分研究者利用CRF处理顾客评论。例如,Zhao等人[3]利用CRF执行句子级和篇章级情感分类。Li等[4]研究者整合了两个CRF变量:Skip-CRF和Tree-CRF同时抽取方面的观点词。与普通的CRF只能利用词序列学习不同,Skip-CRF和Tree-CRF还可以利用CRF学习结构特征。Choi等人[5]使用CRF从评论数据中识别观点持有者。他们的错误分析报告报道了不精确的观点识别对挖掘结果有很大程度的负面影响。Miao等人[6]使用CRF执行方面抽取并获得了合理的结果。他们在电影评论数据集中取得了86%的精度。Jakob等人[7]进一步利用CRF解决跨领域应用问题,例如,判断在一个领域上训练的模型是否能在另一个领域上使用。他们还评估了在这种环境下方面抽取的精度。Chen等人[8]利用CRF实现了从评论中抽取多种类型的评论信息,如:实体的组成部分、实体的功能、实体的属性、观点和观点的强度等。并将基于CRF的意见挖掘与基于频率统计的方法及基于词典化的HMM进行了深入的比较。结果表明,该方法在同时抽取多种评论信息时的精度超过其它的所有方法。
目前国内有关方面级意见挖掘的研究还处在起步阶段。李实等人[9]提出了针对中文客户评论中的产品特征的抽取方法,并证明了该方法的可行性和有效性,但该方法是基于频率统计的一种改进的关联规则挖掘算法。据我们所了解,利用CRF研究中文评论中抽取不同类型的信息还很少有研究。本文针对中文评论的语言特点和风格特征,尝试利用CRF实现方面级意见挖掘,探索中文客户评论的意见挖掘方法和理论, 并且通过实验表明了这一方法的有效性。
3 基于CRF的方面级意见挖掘方法
3.1 方法的基本思路
本文利用CRF在中文评论语料上实现方面级意见挖掘。CRF是一种图模型[8]。图中所有结点称之为状态。这些状态包括可以观察到的状态集合W和隐藏的状态集合T。W通常是评论文本,它的词性标注标签表示为集合S。T通常是预先定义好的类别集合。图中的边表示所有状态之间的关系,这个关系通常由学习函数定义。利用CRF进行挖掘的目标就是从产品评论中抽取被评价实体的不同方面,识别与不同方面相关的观点、观点强度和观点的极性等。通常把被评价实体的不同方面及与之相关联的观点、观点强度和观点的极性称之为观点元素。利用CRF进行挖掘的方法就是给W中的每一个词赋予一个T中的标签。由此可见,利用CRF实现意见挖掘就是一个自动标注过程。此过程主要由四个步骤完成:(1)数据预处理;(2)准备符号标记与训练集;(3)为CRF定义学习函数,并训练CRF模型最大化条件概率;(4)应用模型标注新的评论数据中的观点元素。为了突出预先定义符号标记和训练集等步骤的准备,将数据预处理置于实验部分的5.3节。
3.2 准备符号标记与训练集
这一步骤的主要工作分两个阶段完成:首先为CRF准备预先定义好的类别集合T;然后根据类别集合T准备训练语料。表1明确给出了从评论中挖掘的具体信息属于哪一类观点元素,例如:观点元素是被评价目标的组成部分、功能、性质或是与之相关的观点等。观点元素类别集合T的详细类别符号标记如表2所示。

Table 1 Class and description of opinion element表1 观点元素的类别及描述

Table 2 Class and associated symbol tag of opinion element表2 观点元素的类别与该类别对应的符号标记
符号标记的准备工作完成之后,本文采用中国科学院计算机所的中文分词与词性标注工具ICTCLAS对评论语料进行分词与词性标注,为人工标注训练语料中观点元素的类别作准备。由于二级词性标注可以标注出更为具体的情况,包括具有名词功能的形容词或者动词、专有名词、词素等等目标,为了提高挖掘查准率,采用二级标注。同时,中文客户评论中所讨论的产品的组成部分、功能或属性等可能由名词短语构成,但中文评论的词性标注过程中并不能直接标注出名词短语(除了专有名词短语以外,例如,地名、单位名称) ,再加上基本名词的定义各不相同,本文采用的是周雅倩等人[10]提出的基本名词短语定义。它规定基本名词短语为非嵌套的名词短语,包括单个名词、没有任何修饰成分的名词短语、难以确定修饰关系的一串名词、并列名词性成分、专有名词、时间、地点等,这种基本名词短语占语料中所有基本短语的60.8%。根据这个定义,本文在实验中根据以下两种简单情况界定名词短语:(1)两个相邻的名词连接构成的短语(专有名词和时间、地点名词除外,但包含二级分词标注出来具有名词功能的形容词或者动词,具有名词功能的形容词或者动词);(2)用结构助词“的”连接的两个名词构成的短语。
3.3 定义学习函数
学习函数是观察状态词序列W=w1w2w3…wN,W对应的词性标注序列S=s1s2s3…sN以及隐藏状态T=t1t2…ti-1ti+1…tN之间的关系。学习函数的一般形式是fi(tj-1,tj,w1:N,s1:N),它表明了相邻的状态tj-1与tj、词序列W=w1w2w3…wN以及它对应的词性标注序列S=s1s2s3…sN之间的关系。那么,可以定义一个二值函数:如果当前的词wj是“照片”,它对应的词性标注sj为名词,前一个状态tj-1是观点,当前的状态tj是属性,那么函数fi的值为1,否则为0。
fi(tj-1,tj,w1:N,s1:N)=
(1)
于是可得到以下条件概率:
(2)
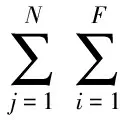
(3)
3.4 训练CRF模型
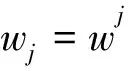
(4)
其中,M是评论语料中句子的个数。为了避免模型过度拟合,可通过对参数的先验分布加入惩罚因子。通常情况下采用均值为0的高斯分布,因而等式(4)变为:
(5)
由于等式(5)是凹的,所以它有一个唯一的全局最优解。可以通过L-BFGS优化算法求解目标函数的梯度学习参数[11]。目标函数的梯度计算如下:
(6)
在等式(6)中,第一项是函数fi在训练数据集中活动(fi=1)的次数。第二项是在当前训练模型下对这个函数预测的活动次数。第三项由先验分布产生。因此,这个派生项测量了精确的频率与预测频率的距离。假定在这个训练数据中,一个函数fk的活动次数是A,在当前模型下,预测活动次数是B:当|A|=|B|,派生项的值为0。因此,训练过程就是找到能最小化派生项的λk。
4 CRF模型的使用
获取了使派生项最小化的参数λk后,使用模型的目标就是应用训练模型给句子中的词自动标注上最合适的观点元素类型符号标记。这必须要求每一步的条件概率都是最大的。假定当前词的位置是j,它有M个不同的候选标记,于是有Viterbi变量αj(m)=p(W,S,tj=m)。Viterbi递归式如等式(7)所示:
(7)
其中,φj(W,S,m′,m)是观察序列为W和S时状态m′到状态m的转换函数。在本文中,转换函数的定义如下:
(8)
递归求解Viterbi变量后,就能识别句子中合适的标记分配。
5 实验验证
5.1 数据集
本文选取了五种商品的网络评论作为实验语料进行数据实验, 这五种商品分别是一款手机(苹果 iPhone 4)、两款数码相机(Cannon PowerShot SX210 IS,Cannon PowerShot A3300 IS)、一款MP3播放器(台电 c700sp)和一本图书(《达芬奇的密码》)。其中手机、数码相机及MP3 播放器的评论从淘宝网下载, 图书评论从卓越网下载。总共选取了821篇评论(1 775个句子)。然后去除这些评论中无意义的符号和标记信息。为了检验CRF方法在中英文评论语料上进行方面级挖掘的差异性,本文在实验中还准备了与中文评论语料中产品种类相似、评论篇数相同的英文语料数据集,该数据集来自文献[1]。
5.2 性能评估方法
为了评估利用CRF实现挖掘的性能,本文采取了在文本处理问题研究中普遍使用的性能评估指标:查准率P(Precision)、查全率R(Recall)、F1-measure值F1(F1-measure)、精确度A(Accuracy)。本文中研究的问题主要是判断利用CRF抽取的观点元素是否为人工标注的真实类别(如表2所示)。评估采用的混淆矩阵(Confusion Matrix)如表3所示。
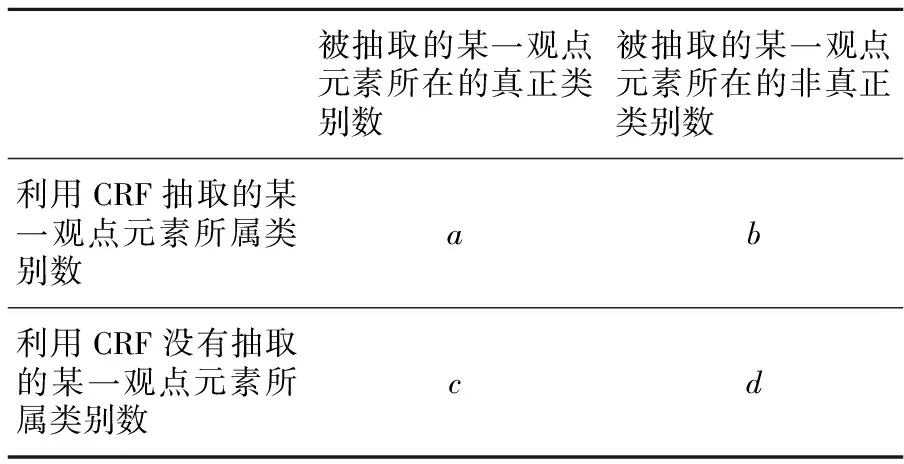
Table 3 Confusion matrix of performance measure表3 性能评估混淆矩阵
根据表3有:P=a/(a+b),R=a/(a+c),F1=2PR/(P+R),A=(a+b)/(a+b+c+d)。实验中分别针对中文语料和英文语料把整个数据集平均分成10个子集,随机选择其中一个子集用作每一轮的测试验证,其它九个子集用作训练集。这样的交叉验证过程执行10次,查全率、查准率、F值和精确度是10次交叉验证的平均值。
5.3 用CRF挖掘中文评论的实验结果
表4列出了10次交叉验证后的比较结果,从中可以看出,用CRF对中文评论进行方面级挖掘也取得了较好的性能指标,大部分性能指标值接近或超过80%。
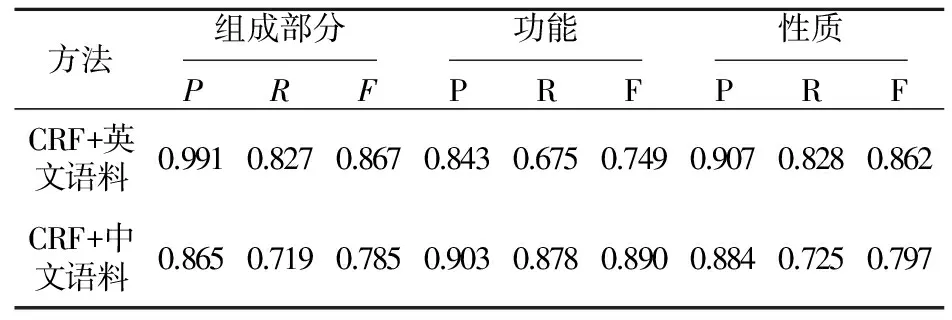
Table 4 Comparison of performance extracted opinionelements:Component, Function, Feature表4 被抽取的观点元素:组成部分、功能、属性的性能比较
为了比较在中文语料中使用名词短语界定的效果,我们利用CRF只针对中文语料中的功能这一观点元素的抽取进行了名词短语的界定。从表4可以看出,该项在中文语料上获得的三个性能指标值要比针对英文语料的高。其中的主要原因有两个方面:(1)在中文词性标注时采用了二级标注。二级词性标注可以标注出更为具体的情况,包括具有名词功能的形容词或者动词、专有名词、词素等,那么在对训练集进行人工标注时,可以给一些不是名词但却具有名词功能的词标注〈COMM_Func〉的符号标记。(2)使用了3.2节的名词短语界定方法,那么在对训练集进行人工标注时,可以给一些名词短语标注为〈COMM_Func〉的符号标记。当模型学习到具有这些特点的词后,就可以对新数据中出现的类似词进行〈COMM_Func〉标记。然而,其它两项观点元素由于没有使用名词短语的抽取,在三项性能指标上均比英文语料低。其中的主要原因是利用CRF对英文语料数据集进行挖掘时,考虑了具有名词词性的词或短语表示功能这一观点元素:组成部分和性质。
对于观点元素:观点与观点强度抽取性能比较,从表5可以看出,用CRF对中文评论进行挖掘也取得了较好的性能指标。每一项的性能指标值都在80%以上,有些值还高出了利用CRF对英文语料的挖掘。例如,观点的查全率是86.1%,这是因为除了形容词或副词明显地表示观点之外,一些表示资源的名词也隐含有观点,我们在人工标注的过程中也给这样的名词赋予了观点的符号标记。而我们针对英文语料的处理使用的是文献[8]中的方法,作者在利用CRF进行观点抽取时并没有涉及如何从评论中推导出隐藏的观点,因而我们在处理英文语料时也忽略了隐含观点的推导。观点强度的查准率达到92.8%,这其中主要原因是当中文评论中出现了感叹词时,在人工标注训练集时,我们给这样的感叹词一个观点强度的标注,由于中英文语料的风格差异,英文语料中没有这样的处理过程。

Table 5 Comparison of performance extracted opinionelements:Opinion, Opinion Intensifier表5 被抽取的观点元素:观点、观点强度的性能比较
表6给出了观点句的判断和句子极性的确定的比较结果。从表6可以看出,所有针对中文语料的性能评估值都在80%以上,这与表5中给出的针对中文语料的实验结果相吻合。也即抽取的观点与观点强度越多越准确,说明对语料中观点句的判断和对句子极性的确定就越具有多样性。因而,针对中文语料句子极性的查全率高。
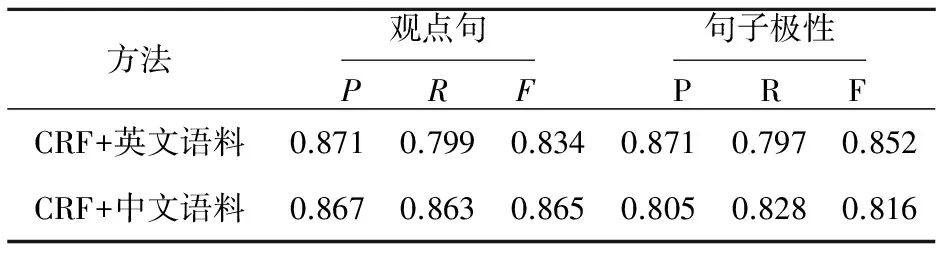
Table 6 Comparison of performance extractedopinion sentences and sentence polarity表6 观点句、句子极性的识别性能比较
通过对相同类型产品的中英文语料的实验研究表明,利用CRF针对中文评论进行方面级挖掘具有一定有效性。为了深入验证方法的实际性能,本文还进一步针对中英文产品评论的挖掘结果进行了差异显著性检验。
5.4 差异显著性检验
为了进一步确认用CRF方法对中文评论挖掘的有效性,将本文研究结果和文献[8]的研究结果进行比较,并对两者差异做显著性检验。如果两个结果接近(即本文结果显著好于或与文献[8]的研究结果的差距不明显) ,则可以进一步验证用CRF方法对中文评论挖掘的有效性。检验过程中所用实验数据与文献[8]中的数据种类相同,评论的篇数相同(注意:文献[8]中的一个数据集是以文献[1]中给出的产品种类与评论篇数为标准的),最后将实验结果与文献[8]的实验结果即查准率和查全率分别进行差异T检验,同时考虑了与分类随机比率50%的差异检验。
实验中采用两个比率之间显著性差异的T检验,具体方法如下:设样本集S中含量n个样本,其中有nk个对象具有类别C,即类别C在样本中出现的比率为p=nk/n。当需要比较该比率与一个给定的比率π是否存在显著差异时,可以用公式(9)计算T值。
(9)
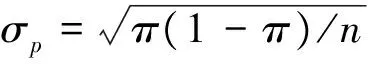
在实验中查准率的n就是指利用CRF识别出的某一观点元素的个数,查全率的n就是人工标注的某一观点元素的个数。自由度为n-2。随机比率0.5的p值指的是分类随机比率50%的差异显著性检验。
最后总体差异显著性检验实验结果如表7所示。可以看到,本文与文献[8]的平均实验结果在观点元素组成部分的查准率差异在0.05水平上显著, 查全率不显著;观点元素功能的查全率在0.05水平上显著,查准率不显著。这说明本文使用CRF对中文评论挖掘和对英文评论挖掘的性能差异不大,进一步验证了CRF对中文语料挖掘的有效性。
5.5 CRF方法与其它方法挖掘中文评论的比较
根据相关研究工作可知,L-HMM方法[12]与ARM(关联规则挖掘)方法[1]分别是基于监督挖掘方法与基于频率统计方法的代表,本节将CRF与这两种方法进行两个方面的比较。一个是方面抽
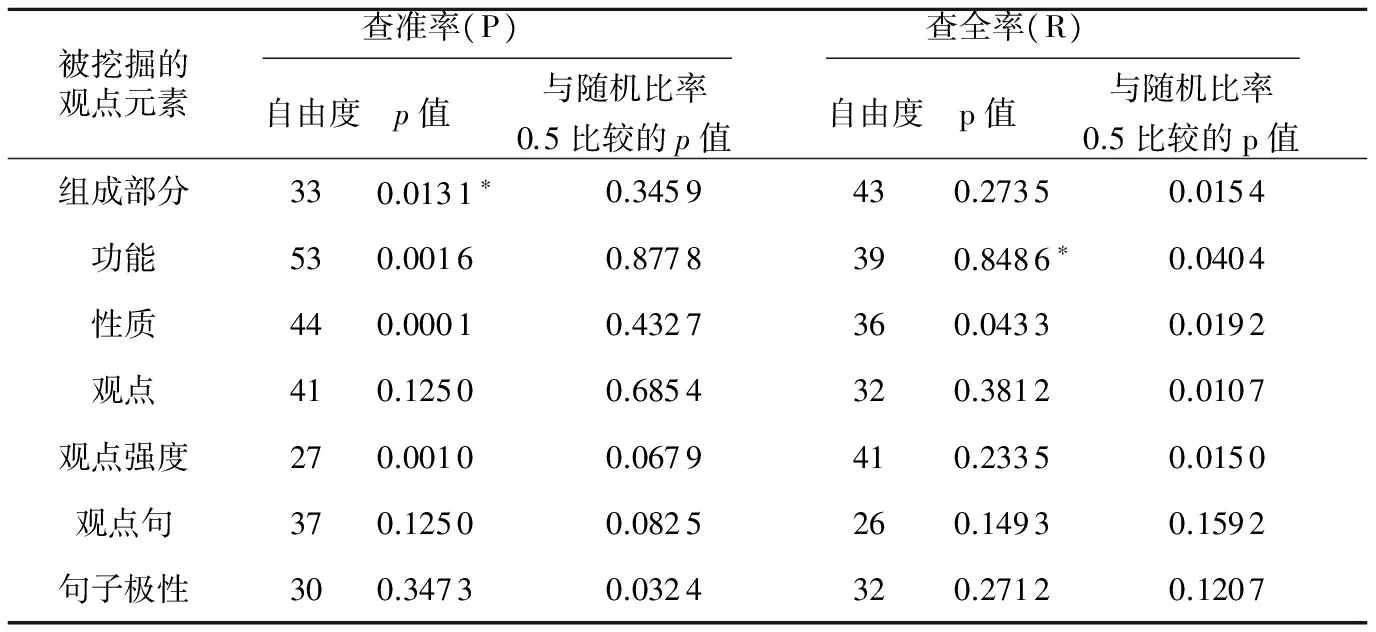
Table 7 Result of difference verification表7 差异检验结果
注:上标*,*分别表示结果在0. 01和0. 05水平上显著,没有*表示不显著
取精度的比较,另一个是针对不同方面情感分类精度的比较。由于篇幅的原因,实验只针对数码相机(Cannon PowerShot SX210 IS)这一被评价实体。实验有两个目的,第一个目的是要观察用户给定被评价实体的方面个数,这三种方法的抽取精确度;第二个目的是要观察针对用户给定的被评价实体的方面,寻找与该方面相关联的观点并按极性(肯定的或否定的)进行分类的情况。从图1中可以看出CRF方法无论用户给定被评价实体的方面是多或是少,该方法抽取方面的精度均值在80%以上,高于L-HMM方法且远远高于ARM方法。这主要是因为ARM方法只关心频繁名词所对应的方面,而忽视了非频繁出现的名词以及一些抽象名词也可能是被评论对象的某一个方面。
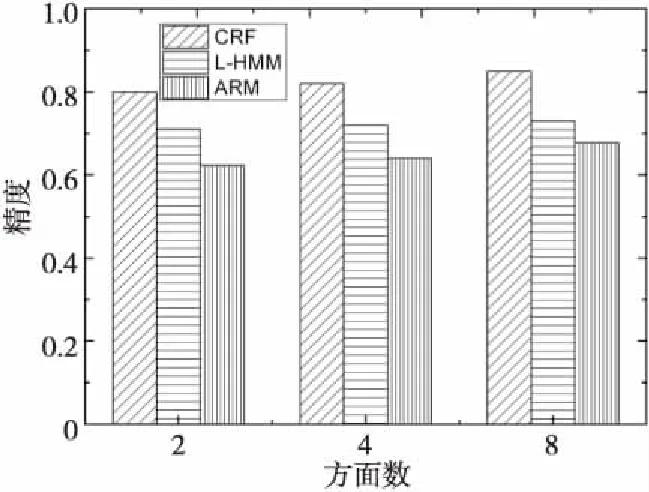
Figure 1 Comparison of aspect extraction accuracy图1 方面抽取精度比较
对于不同抽取方法在情感分类精度上的比较结果如图2所示。从图2中可以看出,随着用户给定被评价实体的方面越来越多,CRF方法的方面级情感分类精度都远远高于ARM方法。这是因为本文在训练数据集的准备时,对评论中某些暗含有观点的名词进行了人工标注,因而训练模型学习到了这方面的知识,从而使得模型在使用阶段能够发现新的评论中具有这样特点的词。然而,由于L-HMM方法与ARM方法都没有涉及到隐式的观点词,所以其分类精度要比CRF低。L-HMM方法高于ARM方法的原因是因为L-HMM方法融合了多个重要的语言特性,如词性标注、词的上下文环境暗示等。

Figure 2 Comparison of aspect sentiment classification accuracy图2 方面情感分类精度比较
6 结束语
方面级意见挖掘的方法主要有两大类:基于频率统计的方法与基于监督学习的方法。关联挖掘算法是典型的基于频率统计的方法,隐马尔可夫模型和条件随机场模型则是基于监督学习的方法。目前这些方法主要针对的研究对象大部分是英文评论语料,并且条件随机场模型是所有这些方法中精度最优的模型。本文围绕如何实现中文评论语料的方面级意见挖掘问题,提出了利用条件随机场实现中文评论语料的方面级意见挖掘的方法与步骤。通过数据实验分析与差异显著性检验,表明了用条件随机场实现中文评论的方面级意见挖掘是有效可行的。由于基于监督学习的方法需要大量的人工标注数据,因而如何减少人工标注工作量,提高挖掘的效率是本工作下一步研究的主要目标。
[1] Hu Min-qing, Liu Bing. Mining and summarizing customer reviews[C]∥Proc of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2004:168-177.
[2] Li Zhuang, Feng Jing, Zhu Xiao-yan. Movie review mining and summarization[C]∥ Proc of the 15th ACM International Conference on Information and Knowledge Management, 2006:43-50.
[3] Zhao J,Liu K,Wang G.Adding redundant features for CRFs-based sentence sentiment classification[C]∥Proc of the Conference on Empirical Methods in Natural Language Processing,2008:117-126.
[4] Li Fang-tao, Han Chao, Huang Min-lie, et al. Structure-aware review mining and summarization[C]∥ Proc of the 23rd International Conference on Computational Linguistics (COLING-2010), 2010:653-661.
[5] Choi Y, Cardie C. Adapting a polarity lexicon using integer linear programming for domain-specific sentiment classification[C]∥Proc of the 2009 Conference on Empirical Methods in Natural Language Processing, 2009:590-598.
[6] Miao Q, Li Q, Zeng D. Mining fine grained opinions by using probabilistic models and domain knowledge[C]∥Proc of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology-WI-IAT’10,2010:358-365.
[7] Jakob N, Gurevych I. Extracting opinion targets in a single and cross domain setting with conditional random fields[C]∥Proc of the 2010 Conference on Empirical Methods in Natural Language Processing, 2010:1035-1045.
[8] Chen Li, Qi Luo-le, Wang Feng. Comparison of feature-level learning methods for mining online consumer reviews[J]. Expert Systems with Applications, 2012, 39(10):9588-9601.
[9] Li Shi, Ye Qiang, Li Yi-jun, et al. Research on the approaches of mining product features from Chinese customer reviews on the internet[J]. Journal of Management Sciences in China, 2009,12(2):142-152.(in Chinese)
[10] Zhou Ya-qian, Guo Yi-kun, Huang Xuan-jing, et al. Chinese and English baseNP recognition based on a maximum entropy model[J]. Jouranl of Computer Research and Development, 2003, 40(3):440-446.(in Chinese)
[11] Liu D, Nocedal J. On the limited memory BFGS method for large scale optimization [J]. Mathematical Programming, 1989, 45(3):503-528.
[12] Jin W, Ho H, Srihari R. OpinionMiner:A novel machine learning system for web opinion mining and extraction[C]∥
Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2009:1195-1204.
附中文参考文献:
[9] 李实,叶强, 李一军, 等.中文网络客户评论的产品特征挖掘方法研究[J].管理科学学报,2009,12(2):142-152.
[10] 周雅倩, 郭以昆, 黄萱菁, 等. 基于最大熵方法的中英文基本名词短语识别[ J ]. 计算机研究与发展, 2003, 40(3):440-446.
LÜPin,born in 1973,PhD candidate,associate professor,her research interests include text mining, and sentiment analysis.

钟珞(1957-),男,湖北武汉人,博士,教授,研究方向为智能技术与智能系统,软件工程,知识发现与数据挖掘。E-mail:zhongluo@netease.com
ZHONGLuo,born in 1957,PhD,professor,his research interests include intelligent technology and system, software engineering, knowledge discover, and data mining.

蔡敦波(1981-),男,吉林长春人,博士,讲师,研究方向为智能规划、自动推理和约束可满足。E-mail:dunbocai@gmail.com
CAIDun-bo,born in 1981,PhD,lecturer,his research interests include intelligent planning, automated reasoning, and constraint satisfaction.

吴云韬(1973-),男,湖北恩施人,博士,教授,研究方向为统计信号处理中的信号检测和参数估计、智能信息处理。E-mail:ytwu@sina.com
WUYun-tao,born in 1973,PhD,professor,his research interests include signal detection and parameter estimator of statistical signal processing, and intelligent information processing.
EffectiveminingproductfeaturesfromChinesereviewbasedonCRF
LÜ Pin1,2,3,ZHONG Luo1,CAI Dun-bo2,3,WU Yun-tao2,3
(1.College of Computer Science and Technology,Wuhan University of Technology,Wuhan 430070;2.School of Computer Science and Engineering,Wuhan Institute of Technology,Wuhan 430073;3.Hubei Province Key Laboratory of Intelligent Robot,Wuhan Institute of Technology,Wuhan 430073,China)
The task of aspect-level opinion mining usually include the extraction of product entities from consumer reviews, the identification of opinion words that are associated with the entities, and the determination of these opinion’s polarities. Aiming at realizing aspect-level opinion mining for Chinese reviews, the paper proposes the four major steps: pre-processing; preparing the training set to learn the model; defining learning functions for conditional random field model; and applying the model to label new review data. At the same time, our experiments on the real Chinese reviews of five types of products show that the conditional random field based method can achieve 80% in most of performance indicators of extracted different types of review opinion elements. In order to verify the effectiveness of the proposed method, a test of the significance of difference is involved. Experiments report that there is scarcely difference of performance on conditional random field based method for both Chinese reviews and English reviews. Finally, we compare the precision of aspect extraction and the accuracy of sentiment classification based on three different methods, and the result shows that CRF-based method outperforms the other two such as lexicalized hidden markov model and association rule mining.
conditional random field; aspect-level opinion mining; opinion elements
2012-09-28;
:2013-02-02
国家自然科学基金青年基金资助项目(61103136);湖北省高等学校优秀中青年科技创新团队计划项目(T201206);湖北省智能机器人重点实验室开放基金资助项目(200906)
1007-130X(2014)02-0359-08
TP274
:A
10.3969/j.issn.1007-130X.2014.02.027

吕品(1973-),女,湖北鄂州人,博士生,副教授,研究方向为文本挖掘和情感分析。E-mail:lpwhict@163.com
通信地址:430073 湖北省武汉市武汉工程大学计算机科学与工程学院Address:School of Computer Science and Engineering,Wuhan Institute of Technology,Wuhan 430073,Hubei,P.R.China
猜你喜欢
军营文化天地(2018年1期)2018-08-15
海外华文教育(2016年1期)2017-01-20
海峡姐妹(2016年2期)2016-02-27
当代教育理论与实践(2015年9期)2015-12-16
营销界(2015年22期)2015-02-28
民族古籍研究(2014年0期)2014-10-27
清风(2014年10期)2014-09-08
外语教学理论与实践(2014年2期)2014-06-21
中国党政干部论坛(2009年9期)2009-09-29
