
一种基于YHFT-MatrixDSP的去块效应滤波算法的向量化实现*
2014-09-14 01:24陈书明陈胜刚
计算机工程与科学 2014年2期
李 勇,陈书明,陈胜刚
(国防科学技术大学计算机学院,湖南 长沙 410073)
一种基于YHFT-MatrixDSP的去块效应滤波算法的向量化实现*
李 勇,陈书明,陈胜刚
(国防科学技术大学计算机学院,湖南 长沙 410073)
针对H.264视频压缩编码标准中去块效应滤波器部分提出了一种基于YHFT-Matrix DSP的并行设计及向量实现方法。重点对H.264协议中去块效应滤波器进行理论分析,并利用向量数据访问单元、向量处理单元、高效的混洗单元和灵活的矩阵对其进行并行算法设计。将去块滤波算法分别映射到YHFT-Matrix和TI的TMS320C6415中,通过统计两者性能,表明YHFT-Matrix的性能优于TMS320C6415。
H.264视频压缩编码;去块效应滤波;并行设计;向量实现
1 引言
H.264/AVC视频压缩编码中的去块效应滤波器被应用到每个解码模块,以减少由块效应所引起的失真,平滑了块的边界、改善了解码帧的质量。滤波后的宏块用于将来帧的运动补偿预测,因滤波过的图像比一个有块效应的未滤波的图像更接近原始图像,能够提高压缩性能。随着视频压缩编码对计算性能的需求越来越高,在高性能视频压缩编码领域,可编程处理器上基于并行计算模型的编码器成为新的研究方向。
现有的运用于通用处理器上的串行结构编码器已经不能满足高性能视频编码需求,而针对本文提出的向量处理器结构,还没有实现去块滤波并行算法,因此本文提出一种在向量处理器上并行实现去块滤波的算法,以完成对性能需求高的协同任务。
文章第2节介绍自主研发的YHFT-Matrix DSP体系结构及其特点;第3节介绍滤波器的算法原理;第4节描述并行实现方法;第5节讲述实验结果和分析;第6节给出结论。
2 YHFT-Matrix体系结构
我们自主研发的YHFT-Matrix DSP内核部分结构如图1所示。其中,取指派发部件可以同时为标量、向量单元派发指令;标量单元(SPE)负责串行任务的处理,以及对向量单元执行的控制,向量单元(VPE)负责计算密集的并行任务的处理,其中每个去处单元(PE)里的MAC单元用于实现乘加等操作,ALU单元用来实现加减、数据搬移、取绝对值及比较等操作,BP单元用于实现移位、混洗等操作;向量访存单元为大宽度向量运算提供高效的数据供给及搬移支持。矩阵寄存器文件MRF通过对矩阵按行列访问的支持,大大加速了应用中大量存在的矩阵类运算的执行。
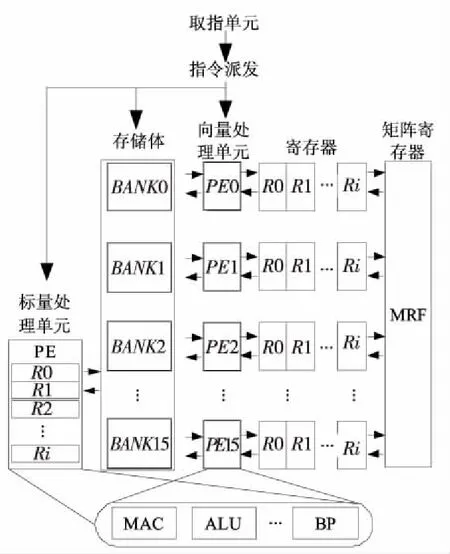
Figure 1 Structure of YHFT-Matrix kernel图1 YHFT-Matrix内核结构
3 去块效应滤波算法原理
宏块内边界滤波顺序及用到的数据:
一个宏块含一个16×16亮度分量(Y)、两个8×8色度分量(Cb和Cr)。滤波器被应用到每个宏块的4×4块的垂直和水平边界(除了块边界),滤波顺序如图2所示(亮度a→b→c→d→e→f→g→h;色度:i→j→k→l)。
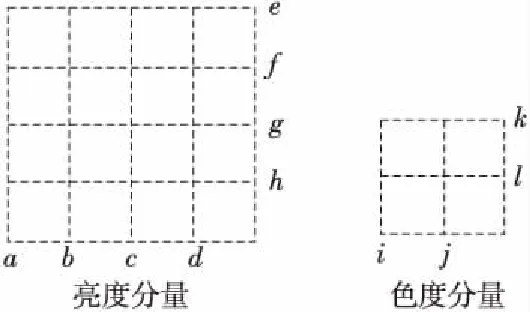
Figure 2 Macro block boundary filtering order图2 宏块内边界滤波顺序
每个滤波操作影响边界两边的像素。图3显示了相邻块p和q的垂直和水平边界两边的四个像素(p0、p1、p2、p3和q0、q1、q2、q3)。
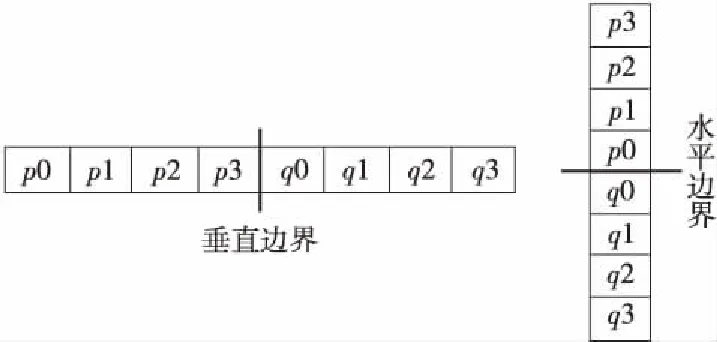
Figure 3 Vertical and horizontal boundary filtering pixels图3 垂直和水平边界滤波像素
边界强度的选择:滤波强度bs依赖于当前量化器、相邻块编码方式及边界上图像像素的梯度。bs值由H.264标准定义:0~4。
滤波器判决条件:集合(p2,p1,p0,q0,q1,q2)的一组像素值在下列情况下才进行滤波:
(1)bs>0;
(2)|p0-q0|<α且|p1-p0|<β且|q1-q0|<β。
滤波器判决条件如图4和图5所示,满足判决条件后,按H.264标准中定义的运算法则实现。其中,α和β是标准中定义的阈值。
Figure 4 Chrominance judgment图4 色度判决条件
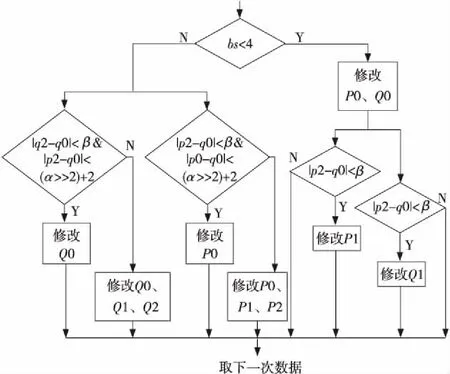
Figure 5 Luminance judgment图5 亮度判决条件
图4、图5中,首先符合滤波条件(1)和(2)后才进行滤波。其次,由0/1来判断对亮度块或色度块像素的滤波。然后,由bs的值1、2、3、4和对应的判决条件来决定对p和q进行怎样的修改。
4 算法的向量化实现
4.1 实现难点
在对去块效应滤波算法分析后,采用向量处理器来实现,由于向量处理单元中有16个PE,另外加入了混洗和矩阵寄存器,所以提高了数据块之间的并行计算,简便地实现了矩阵的行列转换,提高了性能。但是,这种向量化在去块效应滤波算法的应用,也暴露了其不足之处;
(1)数据相关:列边界滤波时,每个4×4块与左右两块存在先后的数据相关,如图6所示。边界a滤波时,当前块与块0存在数据相关,边界b滤波时,修改后的当前块又与块2存在数据相关;行边界滤波时,每个4×4块与上下两块存在先后的数据相关,如图6中块1与当前块、修改后的当前块与块3存在先后的数据相关。
(2)控制相关:不同的输入数据导致程序进入不同分支执行,而SIMD要求并行中不同的数据执行相同的指令。由于去块效应滤波算法中边界强度bs选择的不同,16个运算单元并行实现时,每个运算单元要实现的运算可能不同,如果算法中的分支用跳转来实现,则不能实现16个PE按不同地址进行跳转。
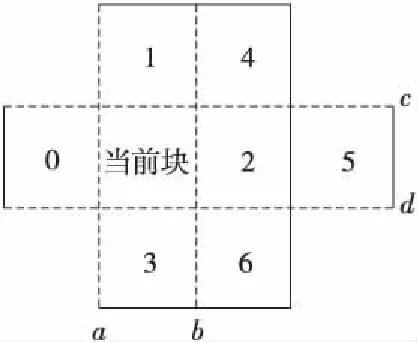
Figure 6 Data correlation图6 数据相关
(3)数据的行列转换:如图7所示,图中每个数据代表一个像素值,每四个像素为一个字。列边界滤波时,数据需按行读取,即第一次读取一个字的位置是0、1、2、3,第二次读取字的位置为4、5、6、7、…;行边界滤波时,数据需按列读取,即第一次读取字的位置为0、4、8、12,第二次读取字的位置为1、5、9、13、…。当列边界滤波完成后执行行边界滤波时,数据要完成行列转换,以满足运算需求。
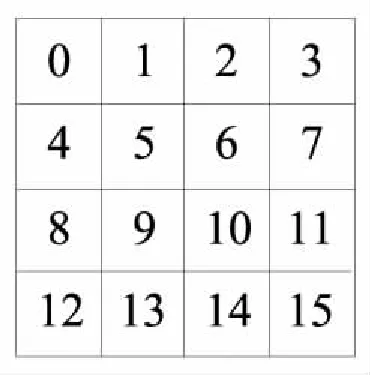
Figure 7 Data reading method图7 数据读取方式
4.2 解决方法
(1)为解决数据相关,列边界滤波时,16行字无相关性,我们将数据按行存储或行边界滤波时,16列字无相关性,我们将数据按列存储,这样每次加载的16个字无相关性, 16个运算单元可以实现并行运算。
(2)为解决控制相关,先求出所有的判决条件,算出所有需要修正的像素点,然后按条件选择出对应于H.264标准定义的修正像素值。这样选择的值可实现不同的输入数据程序进入不同分支执行。
(3)为实现数据的行列转换,可通过混洗指令实现16个运算单元中16个字的行列转换,以实现上一宏块与本宏块边界滤波,如图8所示。还可以通过矩阵寄存器来实现16×16矩阵的行列转换,如图9所示。
图8中,Src1、Src2和Dst分别表示源1、源2和目的操作数,图中的数字表示地址。
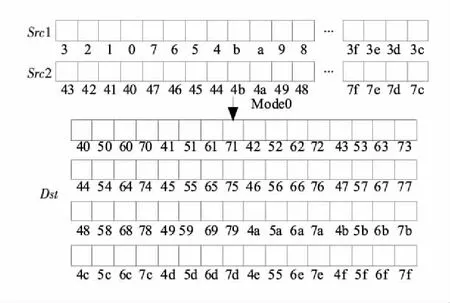
Figure 8 Shuffle mode configuration图8 混洗模式配置
图9中,RR0~RR15表示的是矩阵寄存器的行模式,CR0~CR15表示的是矩阵寄存器的列模式。每一个RR0或CR0对应向量处理单元的16个PE。我们将16个字按列放入CR0~CR15,再按行读出,就实现了16×16矩阵的行列转换。
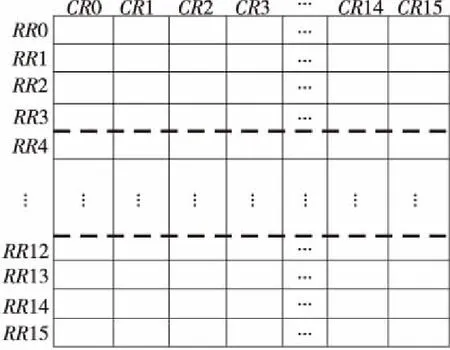
Figure 9 Matrix register图9 矩阵寄存器
4.3 具体方案
16×16亮度块像素值按图10存储,我们先进行列边界滤波,再进行行边界滤波。要完成四次列边界滤波和四次行边界滤波,可将每次边界滤波作为一个核,只要每次循环的接口数据准备好,循环八次即可。8×8色度Cb和Cr按图11存储,要完成列边界滤波和行边界滤波各两次。
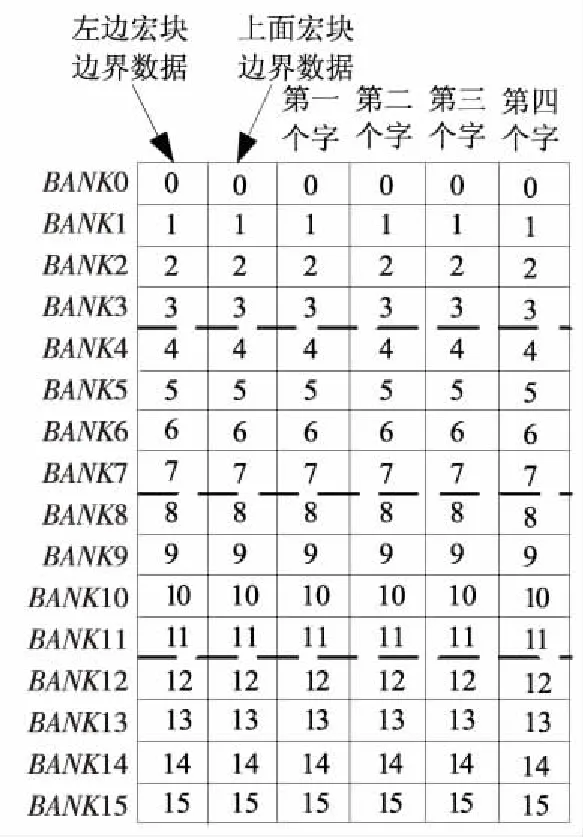
Figure 10 Luminance data preparation图10 亮度数据准备
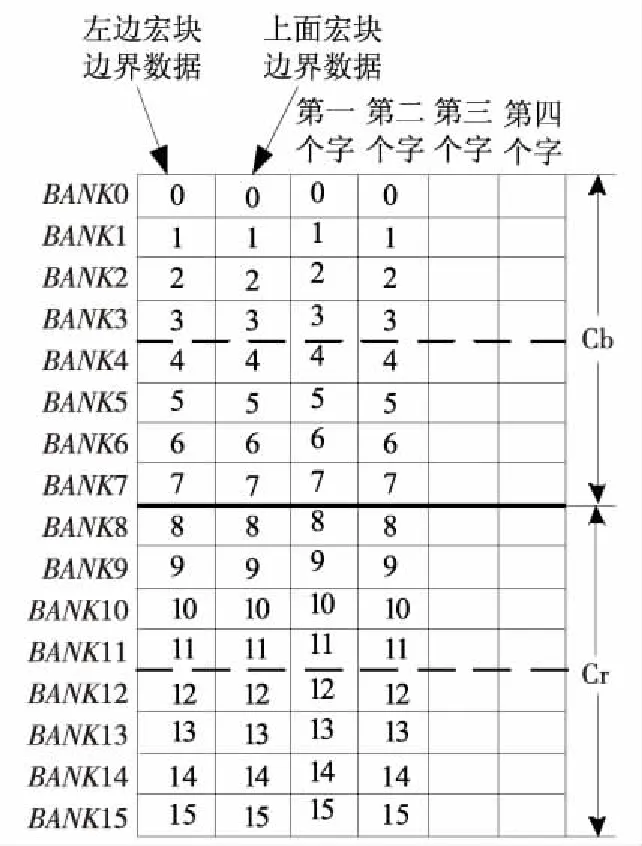
Figure 11 Chrominance data preparation图11 色度数据准备
具体映射步骤如下所示。
已知端口输入数据:16×16宏块的亮度(Y)像素值或8×8宏块的两个色度(Cb和Cr)像素值,标准定义的阈值α、β,边界强度值bs。
第1步数据准备:因Matrix的向量处理单元含16个运算单元,而列边界滤波时,每行数据无相关性,将像素值每一行的1个字按行搬运至存储体中,即图10中第0、1、2、…、15,16个字搬运至BANK0~BANK15中。数据加载时,用标量处理单元对数据存放地址进行初始化,每次加载16个字到16个PE的寄存器中。
第2步列边界滤波:数据加载完成后,16个PE并行运算,每完成一个边界滤波,本次修改完成的q值放入寄存器作为下次滤波的p值,q值由存储体中加载,循环四次,完成列边界滤波后,数据按列写入矩阵寄存器中(CR0~CR15),如图9所示。
第3步条件处理:因边界强度bs的不同,16个运算单元跳转的地址可能不同。要完成并行运算,我们的实现方法是:先完成所有p、q值的修改和所有条件的运算,然后通过有条件MOV选择出对应bs的p、q值。
第4步行边界滤波:第一个行边界的p值是将存储体中上个宏块边界数据读入到寄存器中,再按水平滤波的要求通过如图7所示的混洗完成数据的行转换成列。q值从矩阵寄存器中按行(如RR0~RR3)顺次读入到寄存器中,完成第一个行边界滤波,本次修改完成的q值放入寄存器作为下次滤波的p值。第二个行边界q值从矩阵寄存器中按行顺次读入(如RR4~RR7),依次类推,完成四次行边界滤波。
第5步数据存回:行边界中每完成一次滤波,将四个有效位混洗成一个字,16个PE中的值一次存回。
5 实验结果与分析
本文在构建的精确单核YHFT-Matrix主频为500 MHz的实验模拟平台上,分别编写了16×16亮度块和8×8色度块并行程序。在向量处理器上完成去块滤波算法的映射,测试后得到其性能。然后,在TMS320C6415处理器中编写去块效应滤波算法程序,完成映射,优化后通过测试得到性能。通过比较在两个处理器上得到的性能得到其加速比,给出在YHFT-Matrix上按本文的向量化映射的优点。性能统计如表1所示。

Table 1 Performance statistics表1 性能统计
在表1中,Matrix和TMS320C6415分别表示向量处理器和TI的处理器,第三行是指两个处理器之间的加速比。第二列、第三列分别给出了去块滤波算法16×16的亮度块和8×8色度块在向量处理器和TI的处理器上优化后的时钟数和两处理器实现时的加速比。由表1中的加速比可以看到:在向量处理器中实现去块滤波,16个PE一起工作,使每次运算量加大,滤波处理速度加快,性能得到大幅提升。
表2给出的是去块滤波算法在向量处理器上运用矩阵寄存器映射时得到的性能改善。

Table 2 Reduced overhead statistics of using Matrix register表2 矩阵寄存器使用减小的开销统计表
(1)由于在向量处理器上映射去块滤波算法而带来了混洗操作。从前面讲述的原理中知道,宏块要经过列边界滤波和行边界滤波。列边界滤波时,数据按存储体中读取即按照H.264标准滤波,但第一个行边界滤波时需使用混洗操作对数据进行位置变换,以达到H.264标准定义的行边界滤波要求。
(2)矩阵寄存器在向量处理器上使用带来的性能改善。矩阵寄存器支持的按行或列读取使宏块数据较简便地实现行列转换,以满足H.264标准定义的行边界滤波要求。这种变换会减少向量处理器上映射的额外开销,如表2所示。
总之,16个运算单元并行执行,大大提高了加速比。另外,通过应用混洗和矩阵寄存器,较简便地实现16个字和16×16个字节的行列转换,使程序性能大大提高。
6 结束语
本文针对自主研发的YHFT-Matrix DSP体系结构的特点,利用向量化的映射方法,通过分组并行法解决数据相关性,通过条件选择来解决控制相关性,借助于混洗、矩阵寄存器完成手工汇编,充分发挥了程序间的并行性,提高了程序执行效率,改善了性能。
[1] H.264(E) and ISO/IEC 14496-10:2005(E):Advanced video coding for generic audiovisual services[S].Geneva:Tele-communication Standardization Sector, 2009.
[2] List P, Joch A, Lainema J. Adaptive deblocking filter[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2003,13(7):614-619.
[3] Texas Instruments.TMS320C6000 CPU and instruction set reference guide[M]. Texas Instruments, 2005.
[4] Texas Instruments. TMS320C6000 series of DSP programming tools and guidelines[M]. Tian Li-qing, He Pei-kun, Zhu Meng-yu, translation. Beijing: Tsinghua University Press, 2006.(in Chinese)
[5] Li Fang-hui, Wang Fei, He Pei-kun. Principle and application of TMS320C6000 series DSPs[M].second edition. Beijing: Electronic Industry Press, 2003.(in Chinese)
[6] Gao Hai-lin. DSP technology and its applications[M]. Beijing Jiaotong University Press, 2006.(in Chinese)
附中文参考文献:
[4] 美国德州仪器公司.TMS320C6000系列DSP编程工具与指南[M].田黎青,何佩琨,朱梦宇,译.北京:清华大学出版社,2006.
[5] 李方慧,王飞,何佩琨. TMS320C6000系列DSPs原理与应用[M].第二版.北京:电子工业出版社,2003.
[6] 高海林. DSP技术及其应用[M]. 北京:北京交通大学出版社, 2006.
LIYong,born in 1986,MS,his research interest includes microprocessor design.

陈书明(1961-),男,安徽六安人,博士,教授,研究方向为高性能微处理器设计和超深亚微米VLSI设计理论与技术等。E-mail:smchen@nudt.edu.cn
CHENShu-ming,born in 1961,PhD,professor,his research interests include high-performance microprocessor design, ULSI design theory and techniques.
VectorizableimplementationofadaptivedeblockingfilteronYHFT-MatrixDSP
LI Yong,CHEN Shu-ming,CHEN Sheng-gang
(College of Computer,National University of Defense Technology,Changsha 410073,China)
A parallel vector implementation method for the deblocking filter in H.264 coding algorithm is mapped on the YHFT-Matrix DSP. The deblocking filter is analyzed theoretically. The vector data access unit, the vector processing unit, the data shuffle unit and the flexible matrix are fully used to efficiently develop the parallelism of the deblocking filter algorithm. In experiment, the deblocking filter algorithm is mapped on both YHFT-Matrix and TI TMS320C6415. And the result shows that YHFT-Matrix outperforms TI TMS320C6415.
H.264 video coding;deblocking filter;parallel design;vectorizable implementation
2011-05-12;
:2011-09-20
核高基重大专项资助项目(2009ZX01034-001-006)
1007-130X(2014)02-0206-05
TP332.2
:A
10.3969/j.issn.1007-130X.2014.02.003

李勇(1986-),男,安徽六安人,硕士,研究方向为微处理器设计。E-mail:hglyah@163.com
通信地址:410073 湖南省长沙市国防科学技术大学计算机学院Address:College of Computer,National University of Defense Technology,Changsha 410073,Hunan,P.R.China
猜你喜欢
计算机应用(2020年5期)2020-06-07
单片机与嵌入式系统应用(2017年7期)2017-07-31
电子设计工程(2015年24期)2015-08-26
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
郑州大学学报(理学版)(2013年3期)2013-03-11
杭州电子科技大学学报(自然科学版)(2011年5期)2011-09-04
网络安全与数据管理(2011年24期)2011-08-08
电视技术(2011年11期)2011-03-15
通信技术(2010年8期)2010-08-06
