
支持跨步访问的嵌入式存储系统*
2014-09-14 01:24丁亚军谢向辉
计算机工程与科学 2014年2期
吕 晖,丁亚军,郑 方,吴 东,谢向辉
(1.数学工程与先进计算国家重点实验室,江苏 无锡 214125;2.江南计算技术研究所,江苏 无锡 214000)
支持跨步访问的嵌入式存储系统*
吕 晖1,丁亚军2,郑 方1,吴 东1,谢向辉1
(1.数学工程与先进计算国家重点实验室,江苏 无锡 214125;2.江南计算技术研究所,江苏 无锡 214000)
提出了一种新型多素数嵌入式存储系统,能够显著改善系统跨步访问的性能。提高跨步访存的带宽,对于改善系统的整体性能有着重要的意义。但是,在嵌入式系统中,受片外结构的尺寸限制,直接应用经典的素数存储系统理论无法显著改善跨步访存性能。为此,该新型系统以素数存储系统理论为基础,引入主存访问调度策略并结合嵌入式系统的实际结构特征,构造了一种两层结构的多素数存储系统,可以用较少数量的存储模块实现,而且从逻辑地址到物理地址的映像计算简单,能够以相对较小的硬件代价实现对嵌入式存储系统跨步访问的有效支持。理论分析和实验结果均证实了该系统的正确性和有效性。
嵌入式系统;跨步访问;存储系统;主存调度访问策略
1 引言
数字信号处理和通信领域中的很多应用,如向量计算、矩阵计算、快速傅里叶变换FFT(Fast Fourier Transform)、Viterbi算法等,都具有大量的跨步访存行为,提高跨步访存的带宽,对于改善其系统的整体性能有着重要的意义。提高跨步访存带宽的关键在于如何解决体冲突问题[1]。素数存储系统是解决访问冲突,有效利用多体存储系统的带宽、提高存储系统效率的一类重要方法[2]。但是,在嵌入式系统中,由于受片外结构的尺寸限制,可使用的存储模块(Memory Module)数目较少,如果以存储模块为单位直接构造素数存储系统,并不能显著改善跨步访存的性能。
使用主存访问调度策略,能在不增加数据总线宽度的前提下,有效提高存储模块中存储体(Bank)的并行度[3~5]。基于主存访问调度策略,本文提出了支持跨步访问的嵌入式存储系统。该系统是一种两层结构的多素数存储系统,可以用较少数量的存储模块实现,而且从逻辑地址到物理地址的映像计算简单,能显著提高嵌入式系统的跨步访存性能。
第2节将简单介绍现代DRAM体系结构和主存访问调度策略;第3节将对本文提出的嵌入式存储系统进行形式化描述,并对从逻辑地址到物理地址的映像公式的正确性进行证明;第4节给出系统的硬件体系结构;第5节给出实验和结果,并证实跨步访存性能显著提高;第6节为结束语。
2 DRAM体系结构和主存访问调度策略
现代DRAM存储芯片,如DDR3 SDRAM和DDR4 SDRAM,其内部都是由多个存储体组成,每个存储体内的存储单元以行(Row)、列(Column)二维结构的形式排列[6, 7]。这样,DRAM存储芯片具有三维结构特征:存储体、行、列,如图1所示。
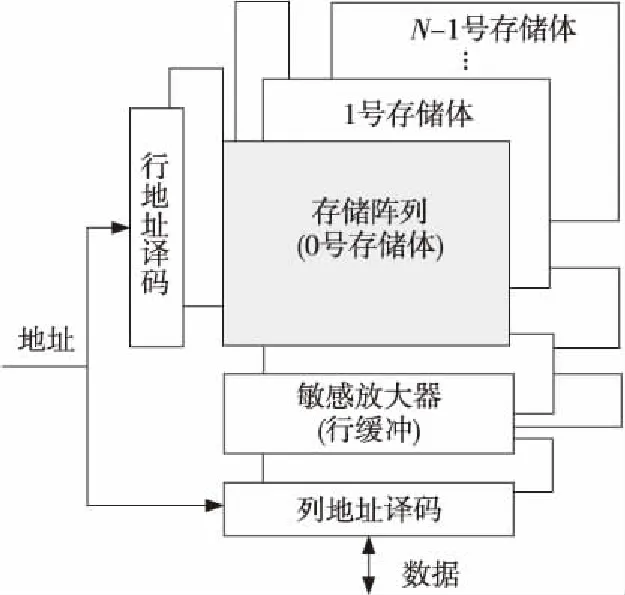
Figure 1 DRAM architecture图1 DRAM体系结构
每个芯片中包含若干个存储体,其数量一般为2的完全方次。
一般地,对不同存储体的访问操作相互独立。当首次访问存储体内某一行中的数据时,需要对该行进行激活(Activate)操作,即通过敏感放大器(Sense Amplifier)将整个数据行读出,并储存到行缓冲区(Row Buffer)中。行缓冲区相当于一个Cache,能够减小连续访问的延迟。行缓冲区中的数据称为活动行(Active Row),可以通过列访问(Column Accesses)对其进行读或写。当访问另一数据行时,需要使用预充电操作(Precharge) 关闭当前的活动行,将行缓冲区中的数据写回存储体内的存储单元。预充电操作为下一次行激活操作做好准备。
例如,4 Gb容量的Micron MT41J512M8RA-125芯片[8]是一个典型的DDR3 SDRAM,内部包括8个存储体,每个存储体由65 536个数据行和1 024个数据列组成。该芯片的工作频率为800 MHz,预充电延迟为11个时钟周期(13.75 ns) ,行激活延迟为11个时钟周期(13.75 ns)。如果对该芯片中的活动行的列访问是连续的,那么每个时钟周期能完成16 bit的数据传输,这样该芯片的峰值传输速率可达1 600MB/s。但是,在一般情况下该峰值传输速率难以达到。首先,这是因为在某个存储体进行预充电或者行激活操作期间,不能对该存储体进行访问;第二,在列访问的读写操作之间进行切换的时候,数据引脚需要一个周期的高阻抗状态;第三,所有存储体共享一套地址线资源和一套数据线资源。这样,在各个主存访问的操作之间,存在着若干时间约束和资源约束关系,这在一定程度上使访存带宽受到了限制。
虽然指向DRAM芯片中同一个存储体的主存访问只能顺序处理,但是指向不同存储体的主存访问可以在一定约束条件下并行处理[3]。这样,就可以为主存控制器构建一个与DRAM时间和资源约束相一致的主存访问调度策略,以充分挖掘在某一时刻可并行的存储体数量,从而最大限度地提高主存系统带宽。
主存访问调度策略有多种实现方案[3~5]。其中,文献[3]首次提出使用主存访问调度策略提高主存控制器的性能。文献[4]则提出一种针对异构多核片上系统的访存调度结构。而文献[5]给出了一种用于单核处理器的主存访问调度技术方案,当主存访问没有数据一致性问题的时候,该方案可以在满足同步DRAM资源约束的前提下使各个体尽可能并行执行操作;同时,由于该方案以访问为基本单位面向不同DRAM芯片中的不同体,其硬件实现的复杂程度较文献[3,4]的方案更低,更适合应用于嵌入式系统。
文献[5]所提出的主存访问调度方案需要N个同步DRAM体控制器和一个端口仲裁模块。如图2所示。
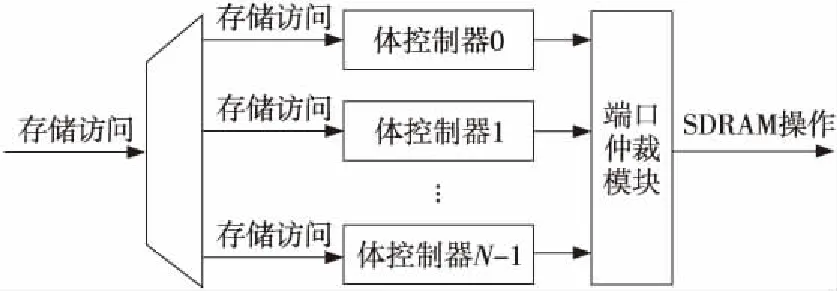
Figure 2 Implementation structure of memory access scheduling图2 主存访问调度实现结构
图2中,N是每个芯片中存储体的数量。每个体控制器将处理指向与其相对应的存储体的所有主存访问。它采用先来先服务的策略,以保证满足主存访问数据一致性的要求。全部体控制器向端口仲裁模块申请所使用的同步DRAM端口资源,仲裁端口将根据资源约束条件,允许若干个体控制器通过端口将操作命令发给相应的存储体,从而达到并行访问多个存储体的目的。
3 支持跨步访问的嵌入式存储系统描述
该存储系统需满足如下的构造要求:
构造要求1具有p个存储模块,编号分别为0,1 ,… ,p-1。
构造要求2全部p个存储模块中,有p-b个模块包含n个存储体,有b个模块包含n+1个存储体,令q=n×p+b,则共包含q个存储体。
构造要求3每个存储体有m个字的存储容量。
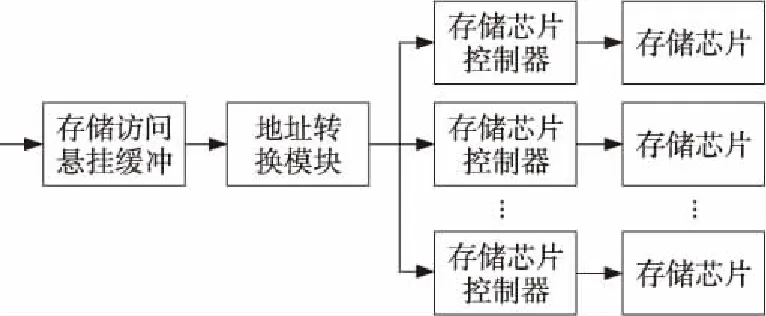
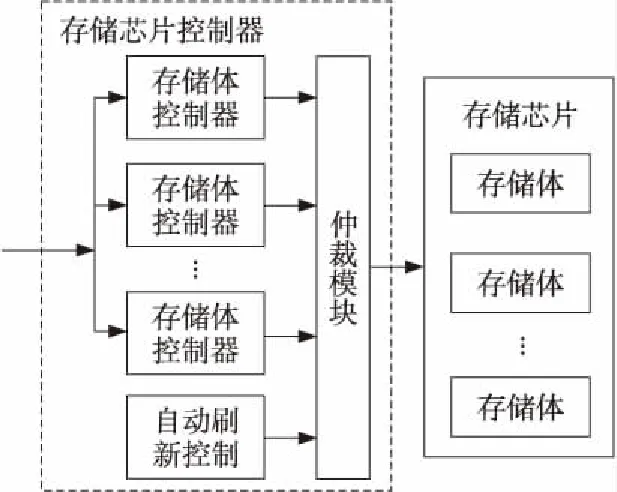
其中,p、q均为大于2的素数,n≤2k,0 系统中任一个字的物理地址可用一个三维向量(u,v,w)来表示,其中,0≤u≤p-1,0≤v≤n,0≤w≤m-1,特别地,当0≤u≤b-1时,有0≤v≤n,当b≤u≤p-1时,有0≤v≤n-1。其中,u表示所在存储模块的编号,v表示所在存储模块内部体的编号,w表示存储体中的内部地址。一个字的逻辑地址用d表示,其中,0≤d≤q×m-1。 3.1 地址转换公式及正确性证明 在该存储系统中,从逻辑地址到物理地址的转换公式为: (1)u=(dmodq) modp; (2)v=(dmodq) mod 2k; (3)w=dmodm。 可以证明,存储系统中的逻辑地址和物理地址满足以下两个条件: (1)每一个逻辑地址d,d∈N,对应于一个且仅对应于一个物理地址(u,v,w), (u,v,w)∈Ω。 (2)每一个物理地址(u,v,w)对应于一个且仅对应于一个逻辑地址d,同样,d∈N且(u,v,w)∈Ω。其中,N为自然数的集合,Ω为三维向量的集合。 证明(1) 由转换公式可知,对于任一逻辑地址d,若存在一个有效物理地址与其对应,则该物理地址必定是唯一的。因此,只需证明,对于任一逻辑地址d,都存在一个有效物理地址与其对应,其中,0≤d≤q×m-1。 由u=(dmodq) modp可知,0≤u≤p-1,符合系统的构造要求1。 由w=dmodm可知,0≤w≤m-1,符合系统的构造要求3。 以下,证明若v=(dmodq) mod 2k,则有0≤v≤n。按照u的取值范围,可分为两种情况进行证明:当0≤u≤b-1时,有0≤v≤n;当b≤u≤p-1时,有0≤v≤n-1。 设任意一个逻辑地址d,令x=dmodq。因为,u=xmodp,所以,可记x=k1×p+u。因为对于所有的x的取值,需要满足条件0≤x 当u的取值范围为u∈[0,b-1]时,即u的最小取值为0,-k1×p需要小于u的最小取值,且(n-k1)×p+b需要大于u的最大取值b-1,因此推得0≤k1≤n。因此,对于任意确定的u,符合约束条件x的值有n+1个。由此,xmod 2k的值域中的元素数量不多于n+1,即当0≤u≤b-1时,有0≤v≤n,这符合构造要求2。 当u的取值范围为u∈[b,p-1]时,即u的最小取值为b,-k1×p需要小于u的最小取值,且(n-k1)×p+b需要大于u的最大取值p-1,因此推得0≤k1≤n-1。因此,对于任意确定的u,符合约束条件x的值有n个。由此,xmod 2k的值域中的元素数量不多于n,即当b≤u≤p-1时,有0≤v≤n-1,符合构造要求2。 由此,若v=(dmodq) mod 2k,则有0≤v≤n。 综上所述,每一个逻辑地址d,d∈N,对应于一个且仅对应于一个物理地址(u,v,w), (u,v,w)∈Ω。 (2)首先给出孙子定理的描述如下: 孙子定理[9]:给定两组整数{ai|i=1, 2,…,k}和{bi|i=1, 2,…,k},它们满足如下条件:{a1,a2, …,ak}中的整数两两互素,且对于1≤i≤k,有bi=xmodai,此处x是一取值为整数的变量。在满足上述条件下,x有且仅有一个解。 以下,证明每一个物理地址(u,v,w)对应于一个且仅对应于一个逻辑地址d: 令d′=dmodq,u=d′ modp,v=d′ mod 2k。 由于p是一个素数,因此p和2k互素,根据孙子定理,每一对(u,v)对应于一个且仅对应于一个d′。 再考虑d′=dmodq和w=dmodm,因为q是一个素数,m是2的幂,因此q和m互素,根据孙子定理,每一对(d′,w)对应于一个且仅对应于一个d。 综上所述,每一个物理地址(u,v,w)对应于一个且仅对应于一个逻辑地址d。 □ 以上证明了地址转换公式的正确性,即该存储系统中,该地址转换公式能够保证物理地址和逻辑地址一一对应。 3.2 地址转换公式的有效性 该存储系统中,w的计算方法为w=dmodm,因为m是2的幂,所以w即为其二进制表示的最右log2m位。这样,w不需要复杂的计算。 同理,v的计算过程中第二步不需要复杂的计算,只需要在第一步计算中进行模p运算。根据参考文献[2],当p为2k+1或2k-1形式的素数时,模p运算可以用并行循环加法器实现,计算复杂度可以接受。 u的计算方法为u=(dmodq) modp,根据参考文献[2],当p和q均为2k+1或2k-1形式的素数时,模运算可以用并行循环加法器实现,计算复杂度可以接受。 因此,地址转换公式可以使用硬件有效实现。 本文提出的嵌入式存储系统由以下几部分组成:存储访问悬挂缓冲模块、地址转换模块、存储芯片控制器模块、存储芯片,如图3所示。其中,存储访问悬挂缓冲模块用于缓存外界的访问请求;地址转换模块负责从逻辑地址到物理地址的映像计算;整个系统中总共包括p个存储芯片控制器模块,其作用是,对外界的访问请求进行译码,翻译成相应的操作序列,并根据存储芯片固有的时间约束和资源约束条件,将操作序列发射给存储芯片。 Figure 3 Memory system architecture图3 存储系统的体系结构 每个存储芯片控制器模块都具有一个自动刷新控制模块、若干个存储体控制器模块以及一个仲裁模块,如图4所示。 自动刷新模块每隔固定的周期向存储芯片发送刷新(Refresh)操作命令,以保持存储芯片内的信息。整个存储系统一共有q个存储体控制器模块,它的作用是根据外界的访问请求生成操作序列,并根据DRAM芯片的时间约束和资源约束条件向仲裁模块发出仲裁请求。由仲裁模块从多个仲裁请求中选择一个操作,发给存储芯片。 Figure 4 Memory device controller图4 存储芯片控制器 本文使用SystemC2.2硬件描述语言在RTL级实现了该存储系统。其中,存储芯片模块根据Micron公司MT41J512M8RA-125芯片的Verilog行为模型开发,两者外部特征完全一致,因此实验得到的数据可以真实地反映设计的实际效果。 实验所实现的支持跨步的嵌入式存储系统共包括3个存储模块、17个存储体控制器。每个存储模块使用一个MT41J512M8RA-125芯片,每个MT41J512M8RA-125芯片中包含8个存储体,所以整个存储系统中共有24个存储体。由于所实现的存储系统中只使用了17个存储体控制器,因此有7个存储体空闲,为避免空间浪费,可用于存储那些不需要跨步访问的数据和代码。 实验的对比方案也采用3个存储模块交叉编址的方式构建,但与本文所提方案的不同之处在于存储模块内部采用顺序编址方式。 实验中的访存测试数据量为32KB,数据总线位宽为24bits,分别对上述两存储系统中随机访存、跨步访存(跨步为1、2、4、8、16、32)等情况进行测试。表1给出了实验结果。 从实验结果中可以看出,系统的跨步访存性能得到了显著改善。 本文提出并实现了一种可支持跨步访问的嵌入式存储系统。该系统以素数存储系统为基础构建,避免了跨步访问所引起的体冲突问题;同时,通过对主存访问进行有效调度,提高存储模块中存储体的并行度,降低系统的实现规模,满足嵌入式系统的要求。 Table 1 Experimental results表1 实验结果 μs 实验结果表明,本文的方法能显著提高嵌入式系统的跨步访存性能。 [1] Aho E, Vanne J, Hamalainen T. Parallel memory architecture for arbitrary stride accesses[C]∥Proc of the 9th IEEE Workshop on Design and Diagnostics of Electronic Circuits and Systems, 2006:63-68. [2] Gao Q S. The Chinese remainder theorem and the prime memory system[C]∥Proc of the 20th Annual International Symposium on Computer Architecture, 1993:337-340. [3] Rixner S,Dally W J,Kapasi U J,et al. Memory access scheduling[C]∥Proc of the 27th International Symposium on Computer Architecture, 2000:128-138. [4] Ausavarungnirun R, Chang K K W, Subramanian L, et al. Staged memory scheduling:Achieving high performance and scalability in heterogeneous systems[C]∥Proc of the 39th International Symposium on Computer Architecture, 2012:416-427. [5] Bai Feng, Cheng Xu. The design of main memory controller for high bandwidth based on memory disambiguation, memory reference scheduling and address remapping[J]. Computer Engineering and Applications, 2003,39(26):125-128.(in Chinese) [6] JEDEC Solid State Technology Association.JESD79-3E,DD-R3 SDRAM specification[S]. Arlington(VA, USA):JEDEC Solid State Technology Association, 2010. [7] JEDEC Solid State Technology Association.JESD79-4,DDR4 SDRAM specification[S]. Arlington(VA, USA):JEDEC Solid State Technology Association, 2012. [8] Micron DDR3 SDRAM MT41J512M8RA-125 Datasheet [EB /OL]. [2010-06-06].http://www.micron.com/~/media/Documents/Products/Data%20Sheet/DRAM/4Gb_DDR3_SDRAM.pdf. [9] Pan Cheng-dong, Pan Cheng-biao. Elementary number theory[M]. 2nd Ed. Beijing:Peking University Press, 2003. (in Chinese) 附中文参考文献: [5] 白锋, 程旭. 基于主存访问相关解决等技术的高带宽主存控 制器设计[J]. 计算机工程与应用, 2003,39(26):125-128. [9] 潘承洞, 潘承彪. 初等数论[M]. 第2版. 北京:北京大学出版社, 2003. LÜHui,born in 1978,PhD candidate,assistant researcher,his research interests include high performance computing, and many-core processor architecture. 丁亚军(1967-),男,浙江衢州人,硕士,高级工程师,研究方向为高性能计算和众核处理器体系结构。E-mail:dyjdoc@163.com DINGYa-jun,born in 1967,MS,senior engineer,his research interests include high performance computing, and many-core processor architecture. 郑方(1984-),男,陕西咸阳人,博士生,助理研究员,CCF会员(E200030852M),研究方向为高性能计算和众核处理器体系结构。E-mail:zhengfangwww_2000@163.com ZHENGFang,born in 1984,PhD candidate,assistant researcher,CCF member(E200030852M),his research interests include high performance computing, and many-core processor architecture. 吴东(1971-),男,江苏苏州人,博士后,副研究员,研究方向为高性能计算与可重构计算体系结构。E-mail:wu.dong@meac-skl.cn WUDong,born in 1971,post doctor,associate research fellow,his research interests include high performance computing, reconfigurable computing architecture. Anovelembeddedmemorysystemforstrideaccesses LÜ Hui1,DING Ya-jun2,ZHENG Fang1,WU Dong1,XIE Xiang-hui1 (1.State Key Laboratory of Mathematical Engineering and Advanced Computing,Wuxi 214125;2.Jiangnan Institute of Computing Technology,Wuxi 214000,China) A novel multi-prime embedded memory system is proposed, based on the theory of prime memory system and memory access scheduling. The system can significantly improve the performance of stride memory access at low hardware cost. Theoretical analysis and the experimental results prove the correctness and effectiveness of the system. embedded system;stride accesses;memory system;memory access scheduling 2013-04-28; :2013-08-26 国家863计划资助项目(2013AA010105) 1007-130X(2014)02-0211-05 TP333 :A 10.3969/j.issn.1007-130X.2014.02.004 吕晖(1978-),男,山东高密人,博士生,助理研究员,研究方向为高性能计算与众核处理器体系结构。E-mail:iamlyuhui@gmail.com 通信地址:214125 江苏省无锡市滨湖区楝泽路30号山水城软件园18号楼Address:Building 18,Shanshuicheng Software Park,30 Lianze Rd,Binhu District,Wuxi 214125,Jiangsu,P.R.China4 存储系统的体系结构
5 实验
6 结束语




 猜你喜欢
人民调解(2019年1期)2019-03-15电脑知识与技术·经验技巧(2018年5期)2018-09-29无线电工程(2018年9期)2018-08-23青年时代(2016年32期)2017-01-20生态毒理学报(2016年2期)2016-12-12科技与创新(2016年12期)2016-06-25电子世界(2015年24期)2015-01-16科技致富向导(2013年6期)2013-04-23振动与冲击(2012年18期)2012-09-15
猜你喜欢
人民调解(2019年1期)2019-03-15电脑知识与技术·经验技巧(2018年5期)2018-09-29无线电工程(2018年9期)2018-08-23青年时代(2016年32期)2017-01-20生态毒理学报(2016年2期)2016-12-12科技与创新(2016年12期)2016-06-25电子世界(2015年24期)2015-01-16科技致富向导(2013年6期)2013-04-23振动与冲击(2012年18期)2012-09-15
