
问答社区问句中多字词表达提取
2014-09-06 10:13吴瑞红吕学强
吉林大学学报(理学版) 2014年6期
吴瑞红, 吕学强, 李 卓, 舒 燕
(1.北京信息科技大学 网络文化与数字传播北京市重点实验室, 北京 100101;2.北京拓尔思信息技术股份有限公司, 北京 100101)
问答社区问句中多字词表达提取
吴瑞红1, 吕学强1, 李 卓1, 舒 燕2
(1.北京信息科技大学 网络文化与数字传播北京市重点实验室, 北京 100101;
2.北京拓尔思信息技术股份有限公司, 北京 100101)
基于互动问答社区问句中多字词表达和问句理解的关系, 提出针对互动问答社区问句进行多字词表达抽取, 并基于互动问答社区问句中多字词表达的特点, 提出适用于互动问答社区的多字词表达提取方法.该方法在利用互信息和停用词表的方法从问句中抽取候选多字词表达的基础上, 将候选多字词表达分为正确串、残缺串、冗余串和错误串4类, 借助搜索引擎对查询串的优化和候选多字词表达在互联网上的检索结果, 设计候选多字词表达校正方法, 实现对多字词表达的提取.以新浪爱问知识人问题库中的问句进行实验, 结果表明, 多字词表达抽取的准确率、召回率和F值分别达到84%,52%和0.64, 验证了该方法的有效性.
多字词表达; 问句理解; 互信息; 搜索引擎
多字词表达(MWEs)指内部结合紧密、使用稳定、整体表示一个概念意义, 可作为一个固定短语使用的信息单元[1].多字词表达广泛存在于词典中, 因其组成结构多样、成分复杂, 因此其提取是大规模自然语言处理技术发展的关键问题之一[2].多字词表达也广泛存在于日常交流中, 如食物宜忌、红糖姜茶等, 这些多字词表达在信息检索、本体构建、文本对齐和机器翻译等领域应用广泛.
近年来, 随着互联网的迅速发展, 互动问答社区应运而生, 互动问答社区的问句中蕴含大量的缩略语、歇后语、成语和惯用表达等多字词表达, 它们是问句理解[3]的核心.由于给出回答的用户人数众多且回答质量参差不齐, 因此对回答质量进行自动判断对用户更加重要, 问句理解是进行这项工作的首要任务, 问句中多字词表达提取也因此变得尤为紧迫.
针对多字词表达提取的研究, 早期主要集中在词语搭配方式上[4].Pecina[5]在MWEs测评提供的3种标准语料上针对德语中的Adj-N和PP-Veb搭配做实验, 比较了55种不同的关联方法, 实验表明, 应用统计方法对多个不同的搭配进行融合比单个搭配抽取效果更好.文献[6]研究表明, 互信息方法和对数似然比方法优于其他统计方法.随着语言学规则的发展, 统计方法与语言学规则相结合的方法被大量应用到多字词表达抽取中.Ramisch等[7]以英语中人工构建的Verb-Particle结构和德语中人工构建的Adj-N进行实验, 发现加入语言学规则要比单纯使用统计方法的效果更好; Al-Haj等[8]针对希伯来语提出结合语言学形态规则和句法规则对多字词表达进行抽取, 结果表明, 应用语言学规则与统计结合的抽取效果更好; Tsvetkov等[9]针对希伯来语-英语语料中提出了双语语料中语言学特征的融合方法, 提高了多字词表达抽取的准确率; 文献[10]通过引入词典, 同样提高了识别的准确率; Duan等[11]针对双语语料中多字词表达抽取, 从生物基因得到启发, 提出了一种生物启发的多字词表达抽取方法, 将最长公共子序列和语言学方法进行融合, 提高了双语多字词表达提取的效果.刘荣等[1]利用高频词和互信息对特定领域进行了多字词表达提取.文献[12]针对特定领域, 利用统计量和语言学规则提取多字词表达; 胡玉溪[13]针对中英文双语语料对多字词表达进行研究, 取得了一定的进展.
上述方法均以较规范的语料库作为研究对象, 对互动问答社区这种大众参与的非正规文本语料中多字词表达提取不完全适用.本文首次提出针对互动问答社区问句进行多字词表达抽取, 且充分结合互动问答社区及社区问句中多字词表达的特征提出互动问答社区问句中多字词表达抽取的方法.
1 语料特点
互动问答社区即“互动式知识问答分享平台”, 是目前备受关注的网络应用, 其内容来源于用户, 并服务于用户.新浪爱问知识人是中国第一个中文互动型问答产品, 为用户提供发表提问、解答问题和搜索答案等服务.以爱问知识人为例, 分析问句特点如下:

图1 问句在搜索引擎中的检索结果Fig.1 Retrieval result of the questions in search engines
1) 互动问答社区属于互联网应用, 社区中的问句也属于互联网资源, 这些问句均可通过搜索引擎在互联网上找到与其相同或相关的资源.如问题: “得了白内障, 怎么办”在百度搜索引擎中的部分检索结果如图1所示.
2) 互动问答社区中的真实问题与传统问答系统中的问题不同, 传统问答系统中的问题一般直切主题, 而互动问答社区中的真实问题一般会先对要提问主题的一段场景进行描述, 然后加一个或几个与所述场景相关的问题.
例1“我家女儿6.5岁, 前两天带她测了骨龄和成长激素, 医生说她的骨龄与年龄相符, 根据测试结果孩子只能长到1.53~1.55 cm, 不知这种测试准不准确? 能不能改变? 应该怎样才能让她再长高一点?”
例2“大家好, 我有过敏性鼻炎, 原来一直没有明显症状, 但从去年开始一直犯不停, 尤其是在办公室, 尴尬极了!我也知道这个病不是能够彻底治愈的, 但是希望大家出主意, 能减缓症状即可, 不至于在办公室鼻涕流不停就行了.拜托了!”
由此可见, 互动问答社区的问句与一般问句不同, 蕴含丰富的提问背景信息, 用户为了清晰、准确地描述所在场景, 通常会选择丰富的多字词表达进行阐述, 因此多字词表达对互动问答社区中的问句理解具有重要作用.
3) 问句中表达不规范, 语言描述简练、随意.
例3“以前不知道从几岁开始 我的2棵虎牙都有点向外生长 有点暴起 可现在我都22了 这段时间我发现我又在长大牙 这到没什么 不过下面的还好 上面两边的大牙都在向外长 而且很斜 现在都已经顶到口腔壁了 吃东西有时候要咬到 影响太大了 有高手给我提提建议呀 要不要去拔掉 但是我想 大牙对于吃东西那么重要 要是拔掉了 以后老了就没牙了 老火啊”.
例3中用户的表达非常随意: 没有添加任何标点符号, 而且存在多处句子成分不完整的情况, 如:“不过下面的还好”、“要不要去拔掉”等.由于汉语语法的复杂性和现有汉语词法、句法理论体系的不完备, 对表达不规范的问句做词法、句法、语义分析准确率非常低, 所以在互动问答社区中的多字词表达研究中, 传统相对正规的语料上基于语言学规则提取多字词表达的方法并不适用.
4) 问句中出现大量普通文本语料中不常出现或出现频率较低的词语, 如: 高手、帮忙、解答和咨询等.
多字词表达蕴含于问句中, 多字词表达具有如下特点:
1) 多字词表达由术语、命名实体、专有名词和缩略语等组成, 利用现有分词工具[14]进行分词时, 准确率较低, 通常被切分成多个单元.
例4“磷酸 肌 酸 激酶 英文 名 CK 结果 1596 状态 单位 U/L 参考范围 24~195 肌 酸 激酶 同工酶 英文 名 CK-MB 37 U/L & lt; 24 是 心脏病 吗 ? ? 是 检查 出来 的”.
例4中, 多字词表达“磷酸肌酸激酶”被切分成“磷酸”、“肌”、“酸”、“激酶”; “肌酸激酶同工酶”被切分成“肌”、“酸”、“激酶”、“同工酶”.
2) 由于问句中用户表达不规范和多字词表达成分复杂, 此时的多字词表达一般很难找到规范语料库中多字词表达的搭配规则.
例5“不/d 知道/v 安/g 基酸/n 对/p 乙肝/n 有/v 没/d 有/v 害处/n ?/w 还/d 请/v 各/r 位/q 专家/n 指点/v!”.
例6“我/r 老婆/n 怀孕/v 八/m 个/q 月/n 了/y, /w 一直/d 喝/g 的/u 都/d 是/v 圣/g 元/q 的/u, /w 现在/t 优/g 聪/g 都/d 出/v 问题/n 了/y,/w 不知/v 优/g 博/g 孕妇/n 奶粉/n 到底/d 有/v 没/d 有/v 问题/n, /w 急/ad 死/v 人/n 了/y, /w 请/v 各位/r 知道/v 的/u 多多/d 指教/v !/w 谢谢/v !/w”.

图2 多字词表达“白内障”在搜索引擎中的检索结果Fig.2 Retrieval result of the MEWs “cataract”
一般语料中的多字词表达遵循一定的搭配规律, 如n+v型等的词性搭配规律.例5和例6中, “安/g 基酸/n”的词性构成规则为“g+n”, “圣/g 元/q”的词性构成规则为“g+q”, “优/g 聪/g”的词性构成规则为“g+g”, “优/g 博/g 孕妇/n 奶粉/n”的词性构成规则为“g+g+n+n”.问句中多字词表达不遵循一般多字词表达词性构成规则.
3) 由于互动问答社区的问句属于互联网资源, 问句中蕴含的多字词表达在互联网上有其相关的资源, 如问句“得了白内障, 怎么办”中的多字词表达“白内障”在搜索引擎中的检索结果如图2所示.
2 候选多字词表达的生成
从问句中多字词表达的构成特点1)可见, 多字词表达一般由多个有序词串组合而成, 组成多字词表达的多个有序词串在语料库中出现的频次较大, 其间的结合紧密度也较大; 而不能组成多字词表达的有序词串在语料库中出现的频次较小, 其间的结合紧密度也较小, 因此通过计算有序词串间的结合紧密度可判定有序词串是否组成多字词表达.
词串间的结合紧密度通过互信息体现, 受候选词串各自词频及其共现词频的影响, 而在语料中存在一些类似“高手帮忙”、“怎么回事”的词, 这些词出现频次较高, 但缺乏实际区分性意义, 本文将这些词统称为问句型停用词.在结合紧密度较高的一部分词组中, 不可避免地包含有问句型停用词, 因此, 为了提高多字词表达抽取的准确率, 本文结合问句特点构建问句型停用词表对词串进行过滤.用以上方法生成的词串中含有很多公共子串, 为了提高多字词表达抽取的准确率, 减少对后续工作的影响, 需要对候选词串进行合并, 进而得到候选多字词表达.
2.1基于互信息的词串生成
互信息能较好地度量词串间的结合紧密程度, 对于词串X和Y, 互信息计算方法如下:
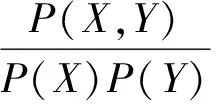
(1)
多字词表达至少包含2个字, 根据刘荣等[12]的统计, 2~4个切分单元构成的多字词表达已占94%, 本文以2~4个切分单元为主要研究对象.为此, 将二元互信息扩展为多元词串内部的互信息.对于多元词串内部的互信息, 采用Magerman等[15]提出的广义互信息概念进行计算, 对于词串x1…xn(2≤n≤4), 互信息计算公式为
(2)

互信息越高, 表明X和Y相关性越大, 词串X和Y组成多字词表达的可能性就越大.通过该方法可初步选定共现可能性较大的词串.设置阈值, 将互信息值大于设定阈值的词串作为候选词串, 过滤掉小于该阈值的词串.
2.2问句型停用词过滤
由互动问答社区问句中的特点4)可知, 在互动问答社区问句文本中, 存在很多不同于新闻语料等普通文本语料的常用搭配, 这些搭配出现的频次较高, 且内部结合紧密度也较高, 但这些搭配缺乏实际意义, 并不是多字词表达, 它们对多字词表达提取带来干扰.如问句: “我儿子得了肠炎, 请高手帮忙?急急!!”, 此句中“高手帮忙”会被识别, 在问句中还有很多类似的搭配.人工观察语料中出现的此类停用词, 可结合常用停用词和问句中的停用词构建适合问句特征的停用词表.为了减少这些词语对多字词表达提取带来的影响, 可利用构建的停用词表, 将含停用词的候选词串删除.
2.3融合公共子串的候选多字词表达生成
经过词串生成和停用词过滤后的词串中存在大量的公共子串, 若不对其进行处理, 会产生众多无意义的词串, 不仅会降低识别的准确率, 而且会产生大量重复计算.候选词串合并包含: 1) 具有包含关系的子串合并; 2) 具有公共子串的相邻候选串合并.具有公共子串的相邻候选词串是指将候选词串按照其在语料中首次出现的顺序排序后, 相邻具有公共子串的词串.互为包含关系的子串是指两词串之间存在包含与被包含的关系, 如在本文中互为包含关系的子串体现在部分三字词词串被四字词词串包含, 部分二字词词串被三字词词串或四字词词串包含.这部分词串合并方法为: 将被四字词词串包含的三字词词串删除, 被三字词串和四字词词串包含的二字词词串删除.
具有公共子串的相邻词串合并: 为了减少合并的次数, 降低计算的复杂度需先对四字词词串进行合并, 然后是三字词词串和二字词词串.对于去除了互为包含关系的子串, 先将候选词串按照其在语料中出现的顺序排序, 然后合并窗口为window, 合并方法为: 在window个词串范围内,n字词词串stri=“ti,1ti,2…ti,n”, stri+1=“ti+1,1ti+1,2…ti+1,n”, 其中ti,j(1≤i 分析得到的候选多字词表达, 存在如下4类词串. 1) 正确串: 内部结合紧密、使用稳定、完整的、具有独立意义的多字词表达, 如“非结合胆红素”、“氯化钠滴眼液”等. 2) 残缺串: 完整多字词表达的一部分词串, 一般不具备独立语义, 在语言结构上不具备完整结构, 如“丙氨酸氨基转移酶”被处理成“丙氨酸氨基转移”、“乳酸左氧氟沙星”被处理成“乳酸左氧氟沙”. 3) 冗余串: 完整多字词表达是其子串, 有的具有独立语义, 有的不具有独立语义, 如“参考范围”被处理成“106参考范围”、“女贞子”被处理成“女贞子12克”. 4) 错误串: 不具备任何语义的串或包含错别字的串.如“瓶六味”、“劲椎病”等. 多字词表达校正是指对候选多字词表达进行类型判别和更正, 包括对正确串的识别、残缺串的补全、冗余串中蕴含正确串的抽取和错误串的去除.根据互动问答社区是互联网资源的特点和问句中多字词表达的构成特点可知, 问句中多字词表达抽取不适合用语言学规则进行抽取, 因此, 本文利用问句中多字词表达在互联网资源中有其相关检索结果的特点, 提出一种新思路: 结合不同类型候选多字词表达在搜索引擎中查询优化和搜索结果中的分布特征进行多字词表达校正. 3.1基于互联网的多字词表达类型判别 候选多字词表达类型判别是指区分出候选多字词表达的类型, 包括正确串、冗余串、残缺串和错误串4种类型. 搜索引擎在对查询串进行检索前, 通常先对查询串进行优化, 这些优化方式包括查询扩展和重构等.查询优化对多字词表达抽取具有很大帮助; 重构可将部分冗余串进行切分, 也能对部分残缺串进行一定补足.搜索引擎返回的搜索结果是与查询串最相关的信息, 问句及其中的多字词表达来源于互联网, 可借助查询返回结果校正多字词表达.将候选多字词表达作为查询串在搜索引擎中进行检索, 获取候选多字词表达在搜索引擎检索结果中的前20条结果标题及摘要信息, 作为搜索结果语料. 3.1.1 候选多字词表达在搜索结果中的出现规律 记待判别类型的候选多字词表达为candiateExp, 对每个候选多字词表达进行如下定义. 定义1将candiateExp的搜索结果语料按中英文标点符号和空格进行划分后形成的单元称为词串单元. 定义2将candiateExp搜索结果语料划分成词串单元后, 该词串单元在所有词串单元中出现的次数称为词串单元频次. 定义3词串单元-频次对集合定义为SenPairSet={〈s1,c1〉,〈s2,c2〉,…,〈sn,cn〉}, 其中:n为candiateExp搜索结果语料中词串单元的个数;si(1≤i≤n)为任一词串单元;ci为词串单元si的频次; len(si)为si的长度. 定义4切分单元来源于两种切分方法: 正向切分和逆向切分.正向切分指将candiateExp从左向右删除字, 直至仅剩下两个字; 逆向切分指将candiateExp从右向左删除字, 直至仅剩下两个字.将每次删除后剩下的单元称为切分单元. 定义5切分单元-频次对集合记为CandiateExpSet, 获取candiateExp的切分单元及切分单元在candiateExp搜索结果语料中的频次, 形成candiateExp的切分单元-频次对集合,CandiateExpSet={〈splitCan1,splitCanNum1〉,〈splitCan2,splitCanNum2〉,…,〈splitCann,splitCanNumn〉},其中: splitCanj(1≤j≤n)为candiateExp的任一切分单元; splitCanNumj为splitCanj(1≤j≤n)在candiateExp搜索结果中出现的频次;n为切分单元的总个数. 正确多字词表达是一种具有稳定性、特指性的语义概念单元, 它通常会被互联网知识库收录, 表现在检索结果中是该多字词表达的下一个词串单元中包含“百科”二字; 还有一部分正确多字词表达虽未被互联网知识库收录, 但却在检索结果中多次独立成为一个词串单元, 可利用这两条规则对正确多字词表达进行判别.冗余串中包含正确多字词表达, 搜索引擎在对冗余串进行检索时, 会对其进行一定的切分, 使冗余串作为一个整体在检索结果中出现的频次会很低, 而冗余串的切分单元在搜索结果中出现的频次会相对较高.残缺串是正确多字词表达的子串, 将其在搜索引擎中检索时, 搜索引擎会对残缺串进行一定的补全, 表现在检索结果上是残缺串可能在一定的窗口范围内, 与词串单元存在被包含关系, 且该词串单元在搜索结果中多次独立出现; 此外, 残缺串在搜索结果语料中出现的次数相对较高, 且残缺串的切分单元出现次数均大于或等于残缺串的出现次数.错误串不含有任何语义或包含错别字, 其在搜索结果中的出现规律不明显, 因此不作为单独类型进行判断. 3.1.2 基于规则的候选多字词表达类型判别 根据不同类型候选多字词表达在搜索结果中出现的规律, 候选多字词表达类型判别较易解决. 1) 正确多字词表达判别规则. 正确多字词表达在搜索结果中出现的规律有两个特点, 相应判别规则为: ① 在candiateExp搜索结果语料划分成的词串单元中, candiateExp为一个词串单元, 且candiateExp紧邻的下一个词串单元包含“百科”二字, 则candiateExp为正确多字词表达; ② 若存在candidateExp∈SenPairSet, 即在SenPairSet集合中存在si, 使得candidateExp=si; 且SenPairSet集合中ci高于一定阈值FreqThreshold, 则candidateExp为正确多字词表达. 2) 残缺串判别规则. 记c(candidateExp)为candidateExp在检索结果中出现的频次, 残缺串在搜索结果中出现的规律也有两个特点, 残缺串类型判别规则为: ① 若集合SenPairSet存在〈si,ci〉, 使得candidateExp是si的子串,ci高于一定阈值FreqThreshold, 且len(si)-len(candidateExp) ② 在candidateExp的CandidateExpSet集合中, ∀splitCanNumi≥c(candidateExp)(1≤i≤n), 且c(candidateExp)>FreqThreshold, 则candidateExp为残缺串. 3) 冗余串判别规则. 冗余串在搜索结果中出现的频次较低, 将在检索结果中出现频次低于阈值threshold的候选多字词表达判断为冗余串.综合考虑候选多字词表达在切分后所有切分单元出现的次数, 候选多字词表达为冗余串的类型判断阈值为 其中: threshold为candiateExp的类型判断阈值, 1≤j≤n;n为切分单元总个数.若候选多字词表达在搜索结果中出现规律不符合正确串、残缺串和冗余串的判定规则, 则将其删除, 不作为研究对象. 4) 候选多字词表达类型判别算法. 综合以上候选多字词表达判别的规则, 候选多字词表达类型判别算法如下. 输入: 候选多字词表达; 输出: 已分类的候选多字词表达; ① 读入一条候选多字词表达candidateExp; ② 将candidateExp作为查询串在搜索引擎中进行搜索, 获取搜索结果的前20条标题和摘要信息作为搜索结果语料; ③ 对搜索结果语料进行切分, 并获取candidateExp的SenPairSet集合; ④ 判断candidateExp出现的特点是否符合正确串判别规则, 如果符合, 判定candidateExp为正确串, 转⑨; 否则转⑤; ⑤ 对candidateExp进行切分, 统计切分单元频次并构建candidateExp的CandiateExpSet集合; ⑥ 判断candidateExp出现的特点是否符合残缺串的判别规则, 若符合, 判定candidateExp为残缺串, 转⑨; 否则转⑦; ⑦ 根据式(3)计算冗余串类型判断阈值threshold; ⑧ 如果candidateExp在搜索结果中出现的次数小于threshold, 则判断其为冗余串; 否则将其删除; ⑨ 如果读完最后一个候选多字词表达, 则退出; 否则转①, 读入下一条候选多字词表达. 3.2残缺串和冗余串的纠正 残缺串和冗余串的纠正是将残缺串和冗余串中蕴含的正确多字词表达抽取出来.根据正确多字词表达是冗余串的子串特点, 在冗余串的切分单元集合中, 必存在被包含的多字词表达.因此, 对冗余串进行切分, 将切分出的子串作为残缺串进行处理. 残缺串的纠正是根据残缺串相邻出现字与残缺串间的共现程度进行扩展, 若残缺串与其相邻字共现程度较大, 则认为该残缺串与相邻字同属于一个多字词表达.因此, 可用相邻差率的概念衡量两个词串的共现程度, 相邻差率是指一个词串在语料中出现的频数与相邻字出现频数的绝对差占该词串频数的比率.左、右相邻差分别为词串左侧的相邻差率和词串右侧的相邻差率, 分别统计串左、右两侧相邻出现的字及其频数, 记词串str出现的频数为f(str), 其左侧相邻出现的字l_str及其频数为f(l_str), 则左相邻差率leftRate计算方法为 同理, 串str右侧相邻出现的字r_str及其频数为f(r_str), 右相邻差率rightRate计算方法为 rightRate=|f(str)-f(r_str)|/f(str). (5) 对残缺串str的所有相邻差率进行计算后, 形成左相邻差率集合: leftRateSet={leftRate1,leftRate2,…,leftRateln}, 其中ln为左相邻差率的个数.则左相邻差率的阈值选取方法为 同理, 右相邻差率阈值选择方法为 其中rn为右相邻差率的个数.若str的相邻差率小于阈值, 则向相应边界添加一个字, 然后迭代计算其左右相邻差率, 直至大于阈值或迭代次数大于一定次数, 将扩展出的词串作为纠正的多字词表达. 对残缺串进行补全时可能会由一个串得到多个串, 因此需要对得到的多字词表达在原问句语料库中进行验证, 将不属于原语料库中的多字词表达删除, 最终得到多字词表达列表. 实验选用新浪爱问知识人中健康与医学领域已解决问题的154 003个问句作为实验对象, 从中提取多字词表达. 4.1实验结果 本文采用多字词表达抽取的准确率(precision,P)、召回率(recall,R)和F值(F-measure,F)评价指标对实验结果进行评价, 计算方法为: 实验中, 过滤掉在语料中出现次数小于3的字符串.选用多组实验对参数进行最优选择, 最终选定结果为: 互信息阈值经过实验观察, 选取-10作为阈值; 词串合并窗口window为4; 判断词串单元独立出现次数的阈值FreqThreshold=4, 判断为残缺串在搜索结果中出现的次数最低为10, 窗口window为3; 残缺串补全迭代次数最多为4次.本文未将分词词表中已有的词列入考察范围, 实验共获取候选多字词表达10 326个, 经过本文方法处理, 最终获得9 822个多字词表达. 为验证本文方法的有效性, 参考文献[1]并结合本文语料的特点, 选用文献[1]中提出的互信息和停用词过滤方法作为对比实验.随机从实验得到的多字词表达列表中抽取1 000个多字词表达, 人工标注其正确的个数, 并计算其准确率; 再随机从实验语料中抽取1 000个多字词表达, 统计其在实验抽取的多字词表达中正确识别的个数, 计算其召回率.准确率、召回率和F值的计算结果列于表1. 表1 实验结果对比Table 1 Comparison of experimental results 实验过程中, 在对候选多字词表达类型进行判别时, 被剔除的候选多字词表达共有13个, 其余均被判别到3个类别中; 分别从正确串、冗余串、残缺串类别中各随机抽取500个多字词表达, 统计其识别的准确率, 结果列于表2. 表2 3个类别的准确率对比Table 2 Three categories of precision comparison 选取部分候选多字词表达和其经过本文候选多字词表达类型判断、纠正后的结果列于表3. 表3 实验抽取的部分多字词表达对比Table 3 MWEs comparison of experimental results 4.2实验分析 由表1可见, 对比实验存在准确率和召回率均偏低的问题, 而本文方法中, 借助搜索引擎对候选多字词表达进行类型判别, 并对其中的冗余串和残缺串进行纠正, 使准确率和召回率都得到了提高, 表明本文方法具有较好的实验效果. 由表2和表3可见, 对判别为正确串的多字词表达, 识别准确率较好; 对残缺串和冗余串的识别效果较未进行校正的结果有较大提高.由于将词频小于3的候选串过滤掉, 存在一些仅出现一次的人名、地名、机构名等不能被识别出来, 导致召回率低; 停用词表过滤时, 像“阿”等类别字, 对大部分词串均是停用词, 而对小部分的多字词表达如“阿奇霉素”却不是停用词, 将这类词作为停用词, 也是导致召回率低的原因.在分析识别错误的多字词表达时, 发现大部分不正确的多字词表达类似: “谷丙转氨酶58”等冗余串和不具有实际意义的错误串, 多字词表达后加一个数字的情况主要是由于这两部分经常共现的缘故, 而错误串本身的统计特征不明显, 是识别的难点. 综上所述, 本文首次在互动问答社区的问句中进行多字体表达提取, 提出了互动问答社区问句中多字词表达提取的方法.在分析互动问答社区中用户提问问题特点的基础上, 结合这些特点和已有的研究结果, 采用互信息方法及停用词表的方法获取问句中的候选多字词表达.进一步分析了候选多字词表达的特点, 并结合问句中多字词表达属于互联网资源的特点, 提出了基于搜索引擎的多字词表达校正方法.利用搜索引擎对查询串的优化和其在互联网的搜索结果, 对候选多字词表达进行类型判别, 并根据不同类型进行纠正, 最终在原语料中对得到的多字词表达进行验证, 达到了较好的实验效果. [1]刘荣, 王丽娟, 张志平, 等.利用高频词和互信息面向特定领域提取多字词表达 [J].太原理工大学学报, 2009, 40(3): 210-214.(LIU Rong, WANG Lijuan, ZHANG Zhiping, et al.The Extraction of Multiword Expression in Special Field with High Frequency Words and Mutual Information [J].Journal of Taiyuan University of Technology, 2009, 40(3): 210-214.) [2]Sag I A, Baldwin T, Bond F, et al.Multiword Expressions: A Pain in the Neck for NLP [C]//Proceedings of the Third International Conference on Computational Linguistics and Intelligent Text Processing.Berlin: Springer, 2002: 1-15. [3]王恒.中文问答系统的研究与实现 [D].哈尔滨: 哈尔滨工业大学, 2008.(WANG Heng.Research and Implement of Chinese Q & A System [D].Harbin: Harbin Institute of Technology, 2008.) [4]Kenneth W C, Hanks P.Word Association Norms, Mutual Information and Lexicography (rev) [J].Comput Linguist, 1990, 16(1): 22-29. [5]Pecina P.A Machine Learning Approach to Multiword Expression Extraction [C]//Proceedings of the LREC 2008 Workshop towards a Shared Task for Multiword Expressions.Marrakech, Morocco: [s.n.], 2008: 54-57. [6]Aline V, Kordoni V, ZHANG Yi, et al.Validation and Evaluation of Automatically Acquired Multiword Expressions for Grammar Engineering [C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL).Prague, Chech: [s.n.], 2007: 1034-1043. [7]Ramisch C, Schreiner P, Idiart M, et al.An Evaluation of Methods for the Extraction of Multiword Expressions [C]//Proceedings of the LREC 2008 Workshop towards a Shared Task for Multiword Expressions.Marrakech, Morocco: [s.n.], 2008: 50-53. [8]Al-Haj H, Wintner S.Identifying Multi-word Expressions by Leveraging Morphological and Syntactic Idiosyncrasy [C]//Proceedings of the 23rd International Conference on Computational Linguistics.Beijing: IEEE, 2010: 10-18. [9]Tsvetkov Y, Wintner S.Identification of Multi-word Expressions by Combining Multiple Linguistic Information Sources [C]//Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing.Edinburgh, England: [s.n.], 2011: 836-845. [10]Fazly A, Stevenson S.Automatically Constructing a Lexicon of Verb Phrase Idiomatic Combinations [C]//Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics (EACL).Trento, Italy: [s.n.], 2006: 337-344. [11]DUAN Jianyong, ZHANG Mei, TONG Lijing, et al.A Hybrid Approach to Improve Bilingual Multiword Expression Extraction [C]//Advances in Knowledge Discovery and Data Mining.Berlin: Springer, 2009: 541-547. [12]刘荣, 王奕凯.利用统计量和语言学规则提取多字词表达 [J].太原理工大学学报, 2011, 42(2): 133-137.(LIU Rong, WANG Yikai.Extracting Multiword Expressions with Statistics and Linguistic Rules [J].Journal of Taiyuan University of Technology, 2011, 42(2): 133-137.) [13]胡玉溪.基于双语语料的汉语多词表达抽取 [D].北京: 北京邮电大学, 2011.(HU Yuxi.Multi-word Expression Extraction Based on Chinese-English Bilingual Corpus [D].Beijing: Beijing University of Posts and Telecommunications, 2011.) [14]ZHANG Huaping, YU Hongkui, XIONG Deyi, et al.HHMM-Based Chinese Lexical Analyzer ICTCLAS [C]//Proceedings of the 2nd SigHan Workshop on Chinese Language Processing.Sapporo, Japan: ACL, 2003: 184-187. [15]Magerman D M, Marcus M P.Parsing a Natural Language Using Mutual Information Statistics [C]//National Conference on Artificial Intelligence.Palo Alto, USA: AAAI, 1990: 984-989. ExtractionofMultiwordExpressionsinQuestionsofQuestionAnsweringCommunities WU Ruihong1, LÜ Xueqiang1, LI Zhuo1, SHU Yan2 The multiword expressions (MWEs) in the questions of question answering communities have direct relationship with question interpretation.We first proposed the idea of extracting MWEs from the questions of question answering communities.According to the characteristics of multiword expressions in the questions, we proposed a method of extracting MWEs in questions of question answering communities.In this method, we first used mutual information method and stop words filtering method to get the candidate MWEs.Then we classified the candidate MWEs into four types: right string, incomplete string, redundancy string and error string.At last, with the help of query optimization in search engines and the candidate MWEs retrieval results on the internet, we designed a revising method to get the MWEs.We took the questions in Sina iask question library as the experimental corpus.And the results show that the precision, recall and theF-measure can reach 84%, 52%, 0.64 respectively, which proves the effectiveness of the proposed method. multiword expressions; question interpretation; mutual information; search engine 2013-09-09. 吴瑞红(1988—), 女, 汉族, 硕士研究生, 从事自然语言处理的研究, E-mail: ruihong0417@163.com. 国家自然科学基金(批准号: 61171159; 61271304)和北京市教委科技发展计划重点项目暨北京市自然科学基金B类重点项目(批准号: KZ201311232037). TP391.1 A 1671-5489(2014)06-1230-09 10.13413/j.cnki.jdxblxb.2014.06.25 韩 啸)3 多字词表达校正



4 实验结果与分析




(1.BeijingKeyLaboratoryofInternetCultureandDigitalDisseminationResearch,
BeijingInformationScienceandTechnologyUniversity,Beijing100101,China;
2.BeijingTRSInformationTechnologyCo.Ltd.,Beijing100101,China)
猜你喜欢
新世纪智能(教师)(2019年2期)2019-09-11新闻传播(2018年15期)2018-09-18北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27西北工业大学学报(2015年4期)2016-01-19中国卫生(2015年12期)2015-11-10电测与仪表(2015年9期)2015-04-09弹箭与制导学报(2015年1期)2015-03-11新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06科学导报·学术论坛(2013年5期)2013-06-26当代外语研究(2010年9期)2010-12-07
