
数据云中基于启发式反向蜂群的虚拟机选择节能算法
2014-09-06 10:13姜建华王丽敏魏晓辉
吉林大学学报(理学版) 2014年6期
姜建华, 刘 渝, 王丽敏, 陈 坚, 黄 娜,3, 魏晓辉
(1.吉林财经大学 物流产业经济与智能物流实验室, 长春 130117; 2.吉林财经大学 管理科学与信息工程学院, 长春 130117;3.上海财经大学 信息管理与工程学院, 上海 200433; 4.吉林大学 计算机科学与技术学院, 长春 130012)
数据云中基于启发式反向蜂群的虚拟机选择节能算法
姜建华1,2, 刘 渝2, 王丽敏2, 陈 坚1, 黄 娜1,3, 魏晓辉4
(1.吉林财经大学 物流产业经济与智能物流实验室, 长春 130117;
2.吉林财经大学 管理科学与信息工程学院, 长春 130117;
3.上海财经大学 信息管理与工程学院, 上海 200433; 4.吉林大学 计算机科学与技术学院, 长春 130012)
结合数据中心中数据密集型作业的频繁读写数据特点, 综合考虑CPU使用率和RAM使用率两个影响因素构建服务器能耗评价模型, 并引入人工蜂群算法及启发式反向思想, 将其应用于数据中心虚拟机迁移策略中的虚拟机选择环节, 实现云计算中数据中心节能问题的优化.在CloudSim 3.0云计算模拟器中的仿真实验结果表明: 该启发式反向蜂群虚拟机选择节能算法(ABCS)与最大最小时间(MMT)、随机选择(RS)和最小使用率(MU)3种经典虚拟机选择算法相比节能20%~25%, 虚拟机迁移频率减少至5%以下.
云计算; 虚拟机迁移; 虚拟机选择; 人工蜂群算法
由于云计算数据中心能耗巨大, 因此如何在数据中心中进行节能和减少环境危害已成为当前的研究热点问题之一.云数据中心的节能策略主要包括硬件节能策略和软件节能策略[1-5].数据云(data cloud)是建立在网络附加存储(NAS)、存储区域网络(SAN)等基础上, 可通过互联网设备对数据进行实时交换、随时随地使用的无限量数据集合.数据云环境下数据密集型作业成为数据中心的主要作业类型.数据密集型作业以数据处理为主要处理任务, 导致大量内存读写操作.目前, 单个服务器能耗评估模型主要考虑CPU、内存、网络及硬盘读写等因素, 但数据云环境下数据中心主要以计算处理、内存读写操作为主, 因此, 单个服务器的能耗评估模型本文只考虑CPU计算和内存读写两个主要影响因素.虚拟机迁移是当前软件节能领域中最重要的节能策略.虚拟机迁移主要涉及源主机选择、虚拟机选择、虚拟机分配和虚拟机迁移机制等.现有的虚拟机迁移策略核心聚焦于虚拟机分配问题, 而虚拟机选择恰是降低能耗最关键的一环.因为虚拟机选择的结果将直接影响虚拟机分配策略的好坏, 并最终导致数据中心的能耗优化效果.虚拟机选择(VM selection)问题通常存在局部较优、选择反复等现象, 难以获得最优解.人工蜂群(artificial bee colony, ABC)[6]算法具有通过自组织、分工协作的运作模式实现快速收敛获取全局最优的优点.本文结合蜂群算法对虚拟机选择进行优化, 主要思想: 首先对计算节点的负载情况进行判断, 负载过高或过低的计算节点需进行虚拟机迁移, 通过蜂群思想选择出导致数据中心能耗最优的被迁移虚拟机.
本文算法采用蜂群思想对虚拟机选择策略进行新解读, 实现一个启发式反向蜂群优化虚拟机选择算法, 具有自组织、分工协作和快速收敛的特征; 结合数据密集型作业特点和服务器能耗模型考虑CPU使用率和内存利用率两个主要影响因素, 构建适合数据密集型作业的能耗评估模型.实验结果表明: 启发式反向蜂群虚拟机选择节能算法(ABCS)较其他3种虚拟机选择算法(最大最小时间(MMT), 随机选择(RS), 最小使用率(MU))能级数级降低虚拟机迁移次数----从数万次降到一千多次, 并在可容忍服务水平协议违反率(SLAV)下, 能有效降低云计算数据中心的能耗(节约20%~25%), 从而减少CO2的排放, 节约云计算数据中心的运营成本.
1 人工蜂群算法
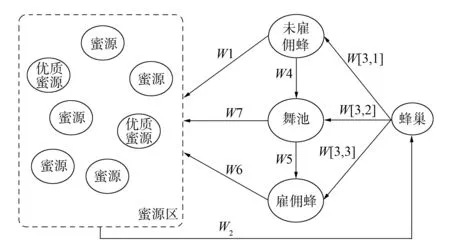
图1 传统人工蜂群采蜜行为算法示意图Fig.1 Workflow of ABC algorithm
人工蜂群算法[7]是一种建立在Seeley自组织模型上的群智能算法, 主要分为基于繁殖行为和基于采蜜行为两类算法[6].本文采用基于采蜜行为的人工蜂群算法思想, 如图1所示.由图1可见: 蜜蜂在采蜜过程中分为雇佣蜂(employed foragers)和未雇佣蜂(unemployment foragers).(W1)采蜜前需从未雇佣蜂中派出蜜蜂, 使之成为侦察蜂(scout bees)对蜜源(foods)进行探查, 并根据阈值对蜜源进行判断.如果该蜜源质量好, 探测该蜜源的侦查蜂即变为雇佣蜂, 并对该优质蜜源进行采集; 反之, 寻找其他蜜源.(W2)雇佣蜂采集蜂蜜后返回蜂巢, 将蜂蜜卸下, 并将蜜源信息带回.(W3)卸下蜂蜜的雇佣蜂有3种选择: 1) (W[3,1])成为未雇佣蜂; 2) (W[3,2])到舞池中跳舞, 并将蜜源信息传递给其他蜜蜂, 招募未雇佣蜂成为雇佣蜂, 并引领它们到优质蜜源采蜜; 3) (W[3,3])继续作为雇佣蜂到优质蜜源采蜜.而未雇佣蜂有两种选择: 1) (W1)成为侦查蜂寻找蜜源; 2) (W4)到舞池中接受招募成为雇佣蜂, 跟随引领蜂到蜜源采蜜.当某一蜜源质量下降到一定程度, 而不需要较多的雇佣蜂时, 则将该蜜源上一定量的雇佣蜂通过舞池转移到其他蜜源.当蜜源质量低于阈值时, 则放弃该蜜源, 转移到其他蜜源.蜜蜂采蜜行为的伪代码如下.
算法1人工蜂群采蜜行为算法.
输入: 未探测蜜源区U={u1,u2,…,um}, 蜂群B={b1,b2,…,bn};
输出: 最优蜜源区uj.
步骤如下:
1) 从蜂群B中派出未雇佣蜂b1,b2,…,bj, 使它们成为侦查蜂, 探测未探测蜜源区u1,u2,…,um;
2) 侦查蜂b1,b2,…,bj探测到优质蜜源则成为雇佣蜂, 采蜜返回蜂巢卸蜜, 否则放弃该蜜源到邻近蜜源探测;
3) 某雇佣蜂bk卸蜜后, 得到该雇佣蜂侦查过蜜源区的蜜源质量, 并得到一个局部最优蜜源区uk, 之后该雇佣蜂可成为未雇佣蜂或继续作为雇佣蜂;
4) 当该雇佣蜂bk成为未雇佣蜂时, 可返回步骤1)成为侦查蜂探测蜜源区, 或跟随舞池中的引领蜂到该蜜源区采蜜;
5) 当该雇佣蜂bk继续作为雇佣蜂时, 可直接返回该蜜源采蜜, 或作为引领蜂在舞池跳舞以招募未雇佣蜂;
6) 返回的局部最优蜜源区, 如uk,uj,um, 并最终得到一个全局最优的蜜源区;
7) 算法结束.
由图1和算法1可见, 人工蜂群采蜜行为是一种群体智能行为.雇佣蜂、侦查蜂、未雇佣蜂之间相互协作以提升采蜜效率和质量.在传统ABC算法中, 食物源的位置表示待优化问题的一个可行解, 食物源的质量表示解的质量, 即适应度; 种群初始化时, 首先随机产生sn个可行解, 并计算其适应度, 然后根据适应度进行排序, 前50%的蜂为雇佣蜂, 后50%的蜂为跟随蜂.随机产生的可行解公式为
其中,j∈{1,2,…,Q}为Q维解向量的某个分量.
蜜蜂记录自己到目前为止的最优解, 并在当前蜜源附近展开领域搜索, 产生一个新位置替代前一个位置, 公式为
其中:k随机产生且k≠i,k∈{1,2,…,Sn};φij为[-1,1]间的随机数.
蜜蜂采蜜采用贪婪原则.算法将当前最优解与领域搜索所得的解进行比较.若所得解更优, 则替换当前最优解.其中, 跟随蜂根据蜜源信息以一定的概率追随引领蜂, 其概率为

2 ABCS算法
2.1虚拟机选择问题
在云计算的数据中心中, 虚拟机实时迁移有利于优化计算节点的负载平衡, 提升处理效率, 降低能耗.虚拟机迁移主要涉及源主机选择、虚拟机选择、目标主机选择及实时迁移过程等.其中, 虚拟机选择是其中的关键环节, 因为虚拟机选择的好坏将直接影响虚拟机迁移的次数、负载的平衡和能源的消耗等.
虚拟机选择问题可描述为: 从某个需迁移源主机上的众多虚拟机中选择出当前最佳被迁移虚拟机的过程, 如图2所示.虚拟机选择问题可描述为: 云计算资源池由异构服务器集群组成, 集合H={h1,h2,…,hj,…,hn}表示服务器集群, 其中hj表示任一服务器.设集合HCPU={hc1,hc2,…,hcj,…,hcn}和HRAM={hr1,hr2,…,hrj,…,hrn}分别表示服务器集群中各主机的CPU使用率和RAM使用率, 集合Hselection={hs1,hs2,…,hsj,…,hsn}表示候选待迁移主机队列, 其中hsj为H集合中通过对HCPU和HRAM的综合阈值筛选出的某个服务器, 集合V={vm1,vm2,…,vmj,…,vmn}表示某个候选待迁移主机中虚拟机(VM)队列的集合,vmj表示某个候选待迁移主机hsk上的某个虚拟机.
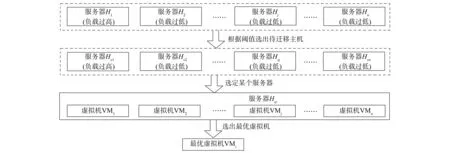
图2 虚拟机选择问题示意图Fig.2 Diagram of VM selection issue
2.2虚拟机能耗评估模型
由于云计算中数据中心的主要作业为数据密集型作业, 该类型作业在处理过程中以数据处理为主, 即频繁进行RAM读写操作, 因此, 虚拟机能耗评估模型不能仅以CPU使用率为影响因素, 而应综合考虑内存使用情况等.但在实际模拟实验中, CloudSim 3.0实验环境未提供内存读写能耗评价模型.同时, 在构建虚拟机能耗评价模型中, 应考虑惩罚能耗V-SLA问题, 即不及时迁移的惩罚能耗.设ECP表示惩罚能耗, 且其为常数.本文实验中, 假设V-SLA具有Poisson分布的特点.此外, 虚拟机固有能耗(某个时间段t)应与服务器节点进行能耗比例划分.因此, 虚拟机能耗主要包括三方面: CPU能耗、内存能耗和惩罚能耗.基于文献[8]中的算法, 并作出调整, 计算公式如下:
1) 主机CPU的能耗
其中,αCPU和γCPU表示模型的特定常数, 可通过训练获得;
2) 虚拟机A的CPU能耗
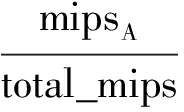
3) 主机RAM的能耗
其中:αRAM表示内存RAM利用率的参数;γRAM表示常数,αRAM和γRAM可通过训练获得;
4) 虚拟机A中RAM的能耗

5) 虚拟机惩罚能耗

6) 虚拟机能耗计算模型
7) 适应度

(10)
2.3虚拟机选择节能算法
本文虚拟机选择节能算法包括候选源主机队列选择算法和虚拟机选择节能算法两部分.候选源主机队列选择算法主要从云计算数据中心中的众多主机中筛选出需要迁移的候选主机队列; 而虚拟机选择节能算法则是从候选主机中选择最佳需迁移的虚拟机.
候选源主机选择主要采用静态双阈值(T1,T2)对云计算数据中心中的主机进行筛选, 选出候选迁移主机队列.静态双阈值计算公式为

图3 T1和T2的内涵示意图Fig.3 Diagram of T1 and T2 meaning
图3为T1和T2的内涵示意图.由图3可见, 阈值T1可表示为矩形面积S,S由CPU利用率和RAM利用率确定.当CPU利用率和RAM利用率均较高, 或CPU利用率和RAM利用率均较低时, 则表现出面积S过大或过小.根据多次模拟实验结果可知, 可设置T1的阈值上下限为(0.1,0.6).若某个主机T1值在该范围外, 则将其添加到候选迁移主机队列中.结合数据中心的作业处理特点, 若某个主机RAM利用率相对过高, 则反映出该主机在一段时间内进行密集的数据读写操作, 这将影响系统的作业处理效率, 也需进行虚拟机迁移操作.对于处于T1阈值内主机所形成的主机集合, 需进一步根据T2(多次模拟实验所得数据, 设T2=2.5)继续筛选.T2表示RAM利用率和CPU利用率的比例关系.若T2过高, 则表明该主机中的RAM利用率相对过高, 可将该主机也置于虚拟机迁移候选主机队列.
算法2候选源主机队列选择算法.
输入: 所有主机队列H={h1,h2,…,hn};
输出: 候选迁移主机队列CMQ={hj,hk,…,hm}.
步骤如下:
1) 将所有主机H={h1,h2,…,hn}都被标记为未被选择状态;
2) 遍历未被选择主机队列H={h1,h2,…,hn}, 判断某主机h的阈值, 若hT1
3) 再次遍历非迁移主机队列UMQ, 若主机h的阈值hT2>T2, 则将主机h放入候选迁移主机队列CMQ中, 并将h从非迁移主机队列中移除;
4) 得到最终的候选迁移主机队列, 如CMQ={hj,hk,…,hm};
5) 算法结束.
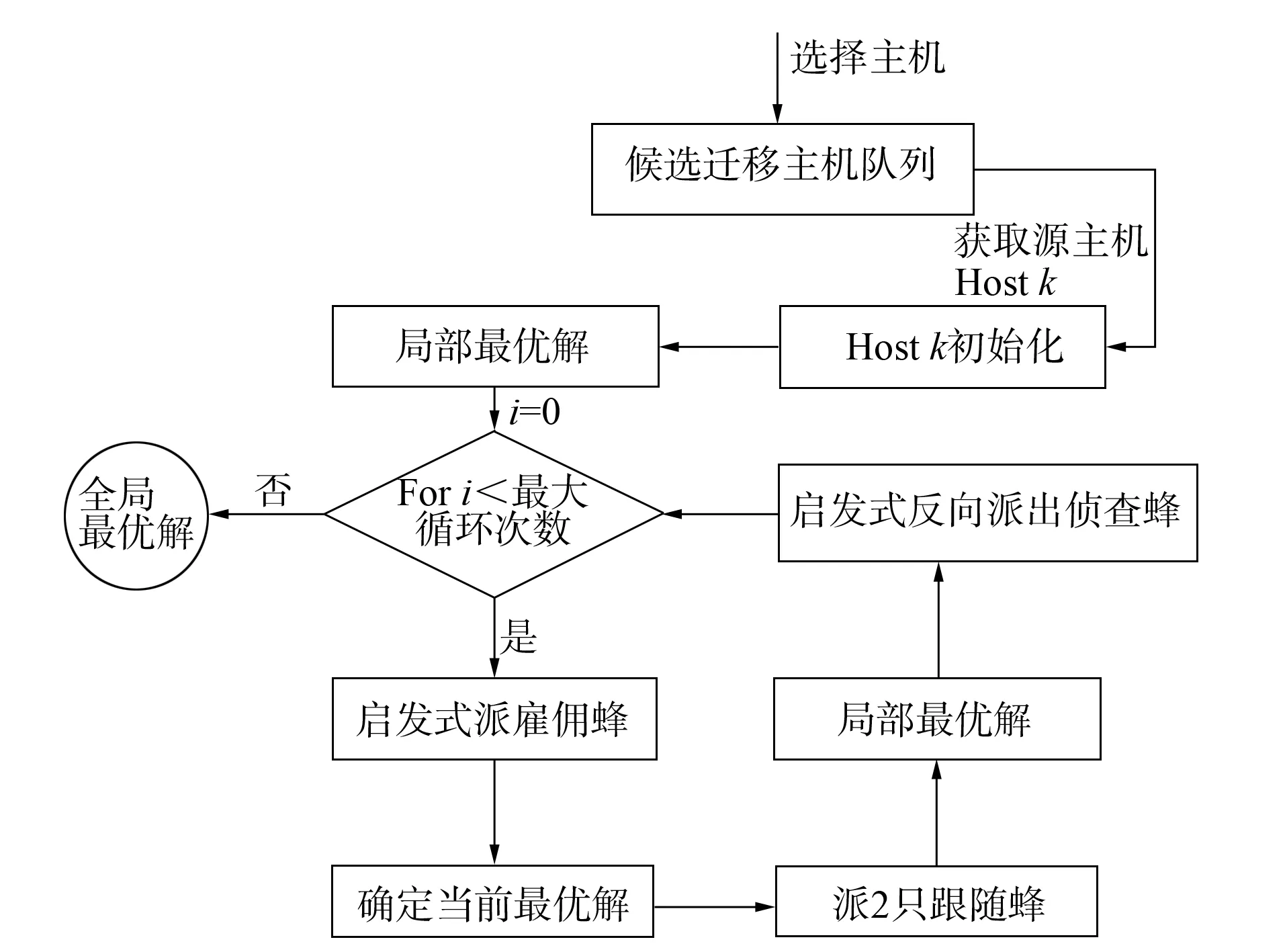
图4 ABCS算法流程示意图Fig.4 Workflow of ABCS algorithm
ABCS算法流程如图4所示.其核心思想就是将蜂群采蜜智能思想应用于虚拟机选择问题的求解过程中, 并对引领蜂、跟随蜂和侦查蜂赋予启发式智能.虚拟机选择是指从已选择出的候选源主机中按一定度量选择满足负荷条件的候选虚拟机.本文通过蜂群算法的思想对需迁移的虚拟机进行选择, 实现数据密集型作业下的虚拟机最优选择策略.
算法3ABCS算法.
输入: 虚拟机队列VM={vm1,vm2,…,vmn};
输出: 返回最佳待迁移虚拟机vmj.
步骤如下:
1) 将所有虚拟机队列VM={vm1,vm2,…,vmn}都标记为未探测;
2) 设置循环次数为5次;
3) 判断未探测虚拟机的数量, 如果未探测虚拟机的数量小于10, 则直接遍历探测所有虚拟机, 找出最优解;
4) 如果未探测虚拟机的数量大于10, 则使用蜂群算法, 每次返回一个局部最优解vmk;
5) 通过局部最优解vmk,…,vmi得到全局最优解vmj, 即全局最佳待迁移虚拟机;
6) 算法结束.

图5 ABCS中的3个列表结构Fig.5 Data structure of 3 lists in ABCS
由图4和算法3可见, 该算法首先从待迁移候选主机队列中选出某个源主机Hostk, 对该源主机Hostk初始化, 将Hostk中可迁移的虚拟机(VMs)按照RAM利用率进行排序.然后判断未被探测的虚拟机数量, 当其小于某一阈值时, 遍历所有未探测虚拟机, 得到最优解.若未探测虚拟机的数量大于一定数量时, 则采用蜂群算法思想选择最优解.主要思想是: 采用启发式派雇佣蜂和跟随蜂, 并采用启发式反向派侦查蜂, 得到局部最优解.其中: 启发式派雇佣蜂指通过对雇佣蜂赋予一定智能进行蜜源的初始选择探测, 得到一个当前最优解; 启发式派跟随蜂指根据当前最优解的左右近邻派出跟随蜂; 启发式反向派侦查蜂指根据不同区域最优解可能性的大小, 派侦查蜂到较小概率区域中.通过多次循环派出雇佣蜂、跟随蜂和侦查蜂, 若可能的解遍历完则直接得出最优解, 反之则在循环次数内, 获得当前最优解中的全局最优解.因此, 算法能快速选出最优的虚拟机进行迁移.从而实现虚拟机迁移效率, 减少迁移次数, 有效节省能耗.
本文通过蜂群算法思想选择最优解, 主要包括启发式派雇佣蜂、跟随蜂和启发式反向派出侦查蜂.为实现算法需要, 本文分别设计了3个列表, 如图5所示, 分别为虚拟机总表(TotalVmList, 列表1)、虚拟机分段列表(VmGroupLinkList, 列表2)和未探测虚拟机表(UncheckedVmList, 列表3).其中列表1包含了所有虚拟机的信息, 包括虚拟机的编号(VmId)、该虚拟机的能耗指标(EnergyCost, 即EA)及用于标记该虚拟机是否被探测的标记(Check_Flag).列表2则是用于存放经蜂群算法探测后所得的虚拟机队列片段, 其中主要包含了虚拟机队列片段的4个属性, 分别为该片段的编号(LinkId)、该片段的起始虚拟机位置(Start_Index)、该片段的结束位置(End_Index)及该片段适应度(Fitness).列表3中只有一项属性, 记录该虚拟机队列的编号.
当启发式派出雇佣蜂进行探测后, 先在列表1中根据探测结果对EnergyCost更新, 并将Check_Flag设为1, 再在列表3中将该虚拟机编号设为-1.同理, 启发式派出跟随蜂探测后也先分别对列表1和列表3进行更改, 再根据列表3中虚拟机编号为-1的点对虚拟机队列进行分段, 找出各段的Start_Index和End_Index, 根据两端点虚拟机的能耗指标计算该段的适应度(Fitness), 并利用LinkId记录各段编号, 将各段的信息填入列表2中.最后通过虚拟机队列各段的Fitness筛选适应度概率较小的几段启发式反向派出侦查蜂, 根据探测结果更新列表1~列表3.
本文在整个ABCS算法过程中, 设计了一个主算法----派送蜜蜂算法, 它包含了启发式派送雇佣蜂算法、启发式派送跟随蜂算法和启发式反向派送侦查蜂算法3个子算法.
算法4派送蜜蜂主算法.
输入: 未探测虚拟机队列VM={vm1,vm2,…,vmn}, 蜂群B={b1,b2,…,bn};
输出: 全局最优虚拟机vmall.
步骤如下:
1) 对未探测虚拟机队列VM={vm1,vm2,…,vmn}根据内存利用率从大到小排序, 得到新的虚拟机队列VM={vmi,vmj,…,vmk};
2) 启发式派送雇佣蜂, 选择几个点派送雇佣蜂b1,b2,…,bs, 得到一个局部最优解vmj;
3) 启发式派跟随蜂, 根据派送出的雇佣蜂得到当前最优解vmj的左右紧邻vmp和vmq, 派送跟随蜂进行探测, 并找出当前最优解vmi;
4) 启发式反向派侦查蜂, 计算各段虚拟机队列的适应度大小, 向出现最优解概率较小虚拟机队列中的某个虚拟机随机派出侦查蜂进行探测, 得到当前最优解vml;
5) 判断是否得到全局最优解, 若提前遍历完整个虚拟机队列, 则跳出循环, 得到全局最优解; 否则转2), 直至循环次数结束, 得到全局最优解vmall;
6) 算法结束.
主算法4包含如下3个子算法.
算法5启发式派送雇佣蜂子算法.
输入: 未探测虚拟机队列VM={vmi,vmj,…,vmk}, 雇佣蜂Bemployed={bi,bj,…,bk};
输出: 当前最优解vmj及其左右邻居虚拟机vmp,vmq.
步骤如下:
1) 根据当前虚拟机列表VM={vmi,vmj,…,vmk}, 启发式选择几个点派出雇佣蜂bi,bj,…,bk进行探测;
2) 根据虚拟机能耗计算模型, 计算各个所探测虚拟机的能耗指标, 获得当前探测点中的最优解vmj;
3) 获得当前最优解左右邻居虚拟机vmp,vmq(若当前最优解为队列的最左端或最右端, 则左邻居为其自身, 或右邻居为自身);
4) 分别更新列表1和列表3;
5) 算法结束.
算法6启发式派跟随蜂子算法.
输入: 当前最优解vmj的左右紧邻虚拟机vmp,vmq位置, 跟随蜂Bonlooker={bi,bj};
输出: 当前最优解vmi.
步骤如下:
1) 根据雇佣蜂获得的当前最优解vmj确定左右近邻虚拟机vmp,vmq在列表中的位置;
2) 根据位置信息判断其是否越出虚拟机列表的范围, 并确保其不越界;
3) 派送跟随蜂bi,bj, 通过适应度函数计算近邻虚拟机vmp,vmq的迁移适应度;
4) 利用函数EnergyCost对虚拟机近邻能耗迁移成本进行计算, 得到一个局部最优解vmi;
5) 更新列表1、列表2和列表3, 其中列表2中存储了虚拟机列表的各段信息;
6) 算法结束.
算法7启发式反向派送侦查蜂子算法.
输入: 成为最优解概率较低虚拟机片段的虚拟机队列VMscouter={vms,vml,…,vmn}, 侦查蜂Bscouter;
输出: 局部最优解vml.
步骤如下:
1) 从未处理的虚拟机列表片段中找出适应度较小的虚拟机片段, 并形成虚拟机队列VMscouter={vms,vml,…,vmn};
2) 随机选择其中一个虚拟机, 派出侦查蜂Bscouter探测, 得到该虚拟机的能耗指标;
3) 与当前最优解比较, 得到一个局部最优解vmm;
4) 更新列表1、列表2和列表3;
5) 算法结束.
3 实验数据与分析
3.1实验环境
CloudSim[9]云计算模拟器适用于云计算环境的模拟, 相比于其他云计算模拟器(如SimGrid[10]和GangSim[11]等), CloudSim对数据资源的管理更有效, 同时提供相关能耗的模拟.因此, 本文选择CloudSim云计算模拟器作为模拟平台.在实验数据上, 本文选择PlanetLab项目中的实验数据.PlanetLab项目[12]由分布于全球的计算机群组成, 目前有1 160台机器, 由547个站点托管, 分布于25个国家.它的实验数据具有数据量巨大、数据类型繁多、价值密度低和处理速度快等特点.本文选择PlanetLab项目云计算环境中的某10 d样本数据作为实验数据, 结果列于表1.仿真中的数据中心由800个异构物理节点组成, 1/2为HP ProLiant ML100 G4服务器, 另1/2为HP ProLiant ML110 G5服务器.这两种服务器在不同负载下的能耗特征列于表2.服务器的CPU频率用MIPS表示, HP ProLiant ML100 G4服务器为1 860 Mips, 而HP ProLiant ML110 G5服务器为2 660 Mips.同时, 每个服务器均拥有1 Gb/s的网络带宽.服务器中的虚拟机被设定为单核虚拟机, 内存RAM也根据虚拟机的多少进行划分.虚拟机的主要类型有: High-CPU Medium Instance (2 500 Mips, 0.85 Gb), Extra Large Instance (2000 Mips, 3.75 Gb), Small Instance(1 000 Mips, 1.7 Gb), 和Micro Instance (500 Mips, 613 Mb).
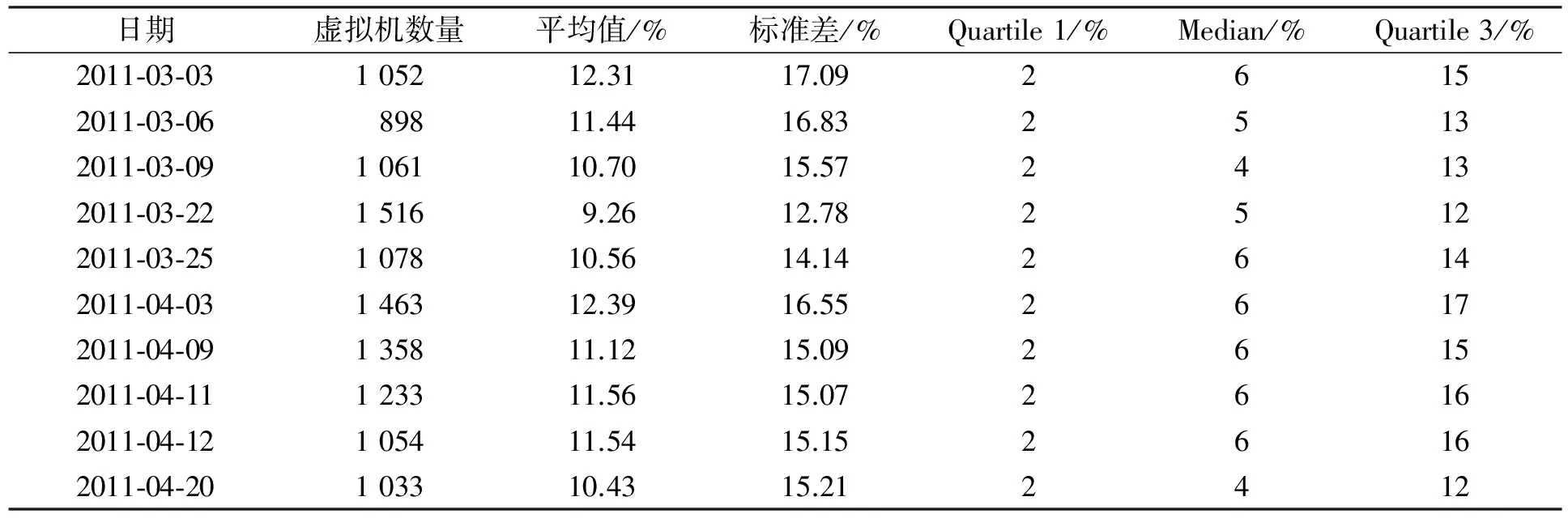
表1 PlantLab中某10 d的不同负载特征Table 1 Workload characteristics of some 10 d in PlantLab

表2 HP G4和HP G5在不同负载下的能耗Table 2 Power consumption distribution of HP G4 and HP G5 by different workload
3.2模拟结果与分析
为了评估云计算数据中心中各种节能调度算法, 云计算模拟器采用几个重要参数进行评估.这些参数包括总能耗、服务水平协议违反率(SLAV)、虚拟机迁移频率等[12].其中最重要的是物理节点能耗和服务水平协议违反率.但这两者是矛盾存在的, 很难同时得到满足.要使总能耗得以降低, 势必会降低服务质量, 从而导致服务水平协议违反率的值升高.本文的主要目标是在服务水平协议违反率可容忍的情况下进行高效节能.因此, 一个由能耗(EC)和服务水平协议违反率组成的新参数可在一定程度上评估调度算法的效果.评估模型如下:
根据云计算数据中心中虚拟机动态迁移需要进行选择和分配的特点, CloudSim云计算模拟器中也有自身的虚拟机选择策略及分配策略.本文选择云计算模拟器CloudSim中自带的虚拟机分配策略(THR,IQR,MAD)与虚拟机选择策略(MMT,MU,RS), 并结合启发式反向蜂群虚拟机选择节能算法(ABCS), 将3个虚拟机分配策略与4个虚拟机选择策略相互组合, 模拟云计算数据中心在10 d不同负载情况下选择不同选择和分配策略组合的运行状况, 得到整个数据中心在不同选择和分配策略组合下每天的能耗指标及其他相关指标, 实验结果如图6~图9所示.
其中每个虚拟机分配策略对应4个选择策略, 通过ABCS分别与虚拟机选择策略IQR,THR,MAD结合所得的实验结果用红色线框与黄色方块表示, 其他3个虚拟机选择策略所得结果则用黑色线框与灰色方块表示.通过Boxplot展示同一分配策略与不同选择策略匹配使用的运行结果.
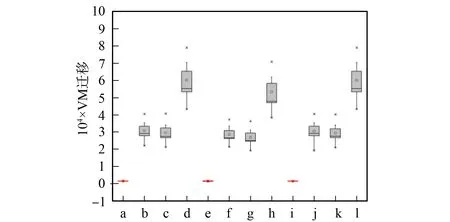
a.IQR_ABCS_1.5; b.IQR_MMT_1.5; c.IQR_RS_1.5; d.IQR_MU_1.5; e.THR_ABCS_0.8; f.THR_MMT_0.8; g.THR_RS_0.8; h.THR_MU_0.8; i.MAD_ABCS_2.5; j.MAD_MMT_2.5; k.MAD_RS_2.5; l.MAD_MU_2.5.
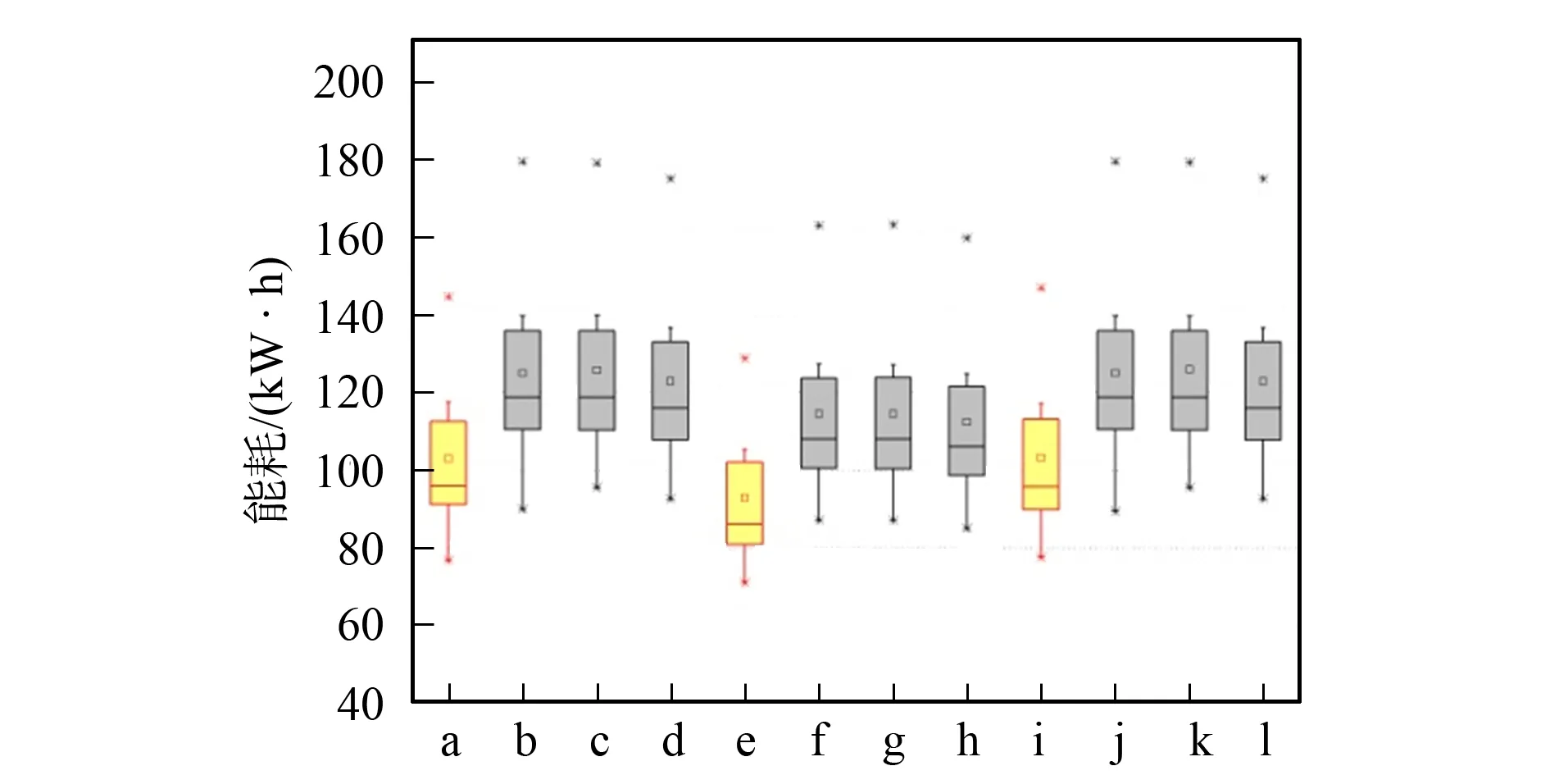
a.IQR_ABCS_1.5; b.IQR_MMT_1.5; c.IQR_RS_1.5; d.IQR_MU_1.5; e.THR_ABCS_0.8; f.THR_MMT_0.8; g.THR_RS_0.8; h.THR_MU_0.8; i.MAD_ABCS_2.5; j.MAD_MMT_2.5; k.MAD_RS_2.5; l.MAD_MU_2.5.

a.IQR_ABCS_1.5; b.IQR_MMT_1.5; c.IQR_RS_1.5; d.IQR_MU_1.5; e.THR_ABCS_0.8; f.THR_MMT_0.8; g.THR_RS_0.8; h.THR_MU_0.8; i.MAD_ABCS_2.5; j.MAD_MMT_2.5; k.MAD_RS_2.5; l.MAD_MU_2.5.

a.IQR_ABCS_1.5; b.IQR_MMT_1.5; c.IQR_RS_1.5; d.IQR_MU_1.5; e.THR_ABCS_0.8; f.THR_MMT_0.8; g.THR_RS_0.8; h.THR_MU_0.8; i.MAD_ABCS_2.5; j.MAD_MMT_2.5; k.MAD_RS_2.5; l.MAD_MU_2.5.
由图6可见, 通过ABCS得到的虚拟机迁移数量(VM migration)相比于其他3种虚拟机选择算法(MMT,RS,MU)在不同的分配策略(IQR,THR,MAD)中都得到大幅度降低.本文所提出的ABCS算法在1 d的运行中迁移次数约为1 000次, 而其他3种选择算法则为20 000~80 000次, 极大减少了云计算数据中心中网络带宽的占用率, 优化了资源管理.由图7可见, 在CloudSim3.0云计算模拟器中, 3种虚拟机选择算法(MMT,RS,MU)与不同分配策略结合, 云计算数据中心中所产生总能耗总体持平.但采用启发式反向蜂群虚拟机选择节能算法(ABCS)在不同分配策略中较其他3种选择算法极大地降低了云计算数据中心的能耗(节省能耗20%~25%), 从而降低了数据中心的运营成本.由图8可见, 启发式反向蜂群虚拟机选择算法(ABCS)所得的平均服务水平协议违反率(ASLAV)相比虚拟机选择算法RS和MMT偏高, 相比虚拟机选择算法MU偏低, 表明本文提出的ABCS算法仍具有较好的竞争力.由图9可见, 启发式反向蜂群虚拟机选择节能算法(ABCS)在ESV指标上, 仍具有较高的竞争力.
综上可见, 启发式反向蜂群虚拟机选择节能算法(ABCS)较其他3种虚拟机选择算法(MMT,RS,MU)通过能级数级降低虚拟机迁移次数, 并在可容忍服务水平协议违反率(SLAV)下, 能有效降低云计算数据中心的能耗, 减少了CO2的排放, 节约了云计算数据中心的运营成本.
[1]Kosar T.A New Paradigm in Data Intensive Computing: Stork and the Data-Aware Schedulers [C]//Challenges of Large Applications in Distributed Environments.Paris: IEEE, 2006: 5-12.
[2]Kosar T, Balman M.A New Paradigm: Data-Aware Scheduling in Grid Computing [J].Future Generation Computer Systems, 2009, 25(4): 406-413.
[3]LIU Liang, WANG Hao, LIU Xue, et al.GreenCloud: A New Architecture for Green Data Center [C]//Proceedings of the 6th International Conference Industry Session on Autonomic Computing and Communications Industry Session.New York: ACM, 2009: 29-38.
[4]Bohrer P, Elnozahy E N, Keller T, et al.Power Aware [M].[S.l.]: Springer, 2002: 261-289.
[5]韩制坤.基于虚拟化技术的集群自适应功耗管理 [D].上海: 上海交通大学, 2012.(HAN Zhikun.The Application of Virtualization in the Cluster Adaptive Power Management [D].Shanghai: Shanghai Jiaotong University, 2012.)
[6]张超群, 郑建国, 王翔.蜂群算法研究综述 [J].计算机应用研究, 2011, 28(9): 3201-3205.(ZHANG Chaoqun, ZHENG Jianguo, WANG Xiang.Overview of Research on Bee Colony Algorithms [J].Application Research of Computers, 2011, 28(9): 3201-3205.)
[7]Karaboga D.An Idea Based on Honey Bee Swarm for Numerical Optimization [R].Erciyes: Erciyes University, 2005.
[8]Kansal A, ZHAO Feng, LIU Jie, et al.Virtual Machine Power Metering and Provisioning [C]//Proceedings of the 1st ACM Symposium on Cloud Computing.New York: ACM, 2010: 39-50.
[9]Calheiros R N, Ranjan R, Beloglazov A, et al.CloudSim: A Toolkit for Modeling and Simulation of Cloud Computing Environments and Evaluation of Resource Provisioning Algorithms [J].Software: Practice and Experience, 2011, 41(1): 23-50.
[10]Casanova H.Simgrid: A Toolkit for the Simulation of Application Scheduling [C]//Proceedings First IEEE/ACM International Symposium on Cluster Computing and the Grid.Brisbane: IEEE, 2001: 430-437.
[11]Dumitrescu C L, Foster I.GangSim: A Simulator for Grid Scheduling Studies [C]//IEEE International Symposium on Cluster Computing and the Grid.Washington DC: IEEE, 2005: 1151-1158.
[12]Boglazov A.Energy-Efficient Management of Virtual Machines in Data Centers for Cloud Computing [D].Melbourne: The University of Melbourne, 2013.
VMSelectionEnergy-EfficiencyAlgorithmBasedonHeuristicBackwardArtificialBeeColonyMethodinDataClouds
JIANG Jianhua1,2, LIU Yu2, WANG Limin2, CHEN Jian1, HUANG Na1,3, WEI Xiaohui4
(1.LaboratoryofLogisticsIndustryEconomyandIntelligentLogistics,JilinUniversityofFinanceandEconomics,Changchun130117,China; 2.SchoolofManagementScienceandInformationEngineering,
JilinUniversityofFinanceandEconomics,Changchun130117,China; 3.SchoolofInformationManagementandEngineering,ShanghaiUniversityofFinanceandEconomics,Shanghai
200433,China; 4.CollegeofComputerScienceandTechnology,JilinUniversity,Changchun130012,China)
Energy-efficiency is a crucial issue in data center.Since data-intensive jobs have the characteristics of frequently reading and writing operations, CPU and RAM utilization rates are considered as two important influencing factors to make energy-efficiency evaluation model.Artificial bee colony algorithm and heuristic backward thinking were applied to VM selection phase in VM migration policy to save energy.Compared with MMT,RS and MU algorithms in CloudSim, the proposed VM selection algorithm, ABCS, made energy 20%—25% saved and VM migration frequency less than 5%.
cloud computing; VM migration; VM selection; artificial bee colony algorithm
2014-03-21.
姜建华(1979—), 男, 汉族, 博士, 副教授, 从事云计算和商务智能的研究, E-mail: jianhuajiang@foxmail.com.通信作者: 王丽敏(1975—), 女, 汉族, 博士, 教授, 从事智能计算的研究, E-mail: wlm_new@163.com; 魏晓辉(1972—), 男, 汉族, 博士, 教授, 博士生导师, 从事云计算的研究, E-mail: weixh@jlu.edu.cn.
国家自然科学基金(批准号: 61170004; 61202306)、吉林省教育厅基金(批准号: 2012188)和吉林财经大学科研项目(批准号: XJ2012007; 2013006).
TP316
A
1671-5489(2014)06-1239-10
10.13413/j.cnki.jdxblxb.2014.06.26
韩 啸)
猜你喜欢
林业与生态(2022年5期)2022-05-23
小学生学习指导(中年级)(2021年4期)2021-04-27
课堂内外(初中版)(2020年5期)2020-06-19
当代工人(2019年13期)2019-08-05
保健与生活(2019年8期)2019-07-31
意林(儿童绘本)(2019年3期)2019-04-04
高中生·天天向上(2018年1期)2018-04-14
中学生数理化·中考版(2015年10期)2015-09-10
读写算·小学低年级(2015年5期)2015-07-13
吉林建筑大学学报(2014年1期)2014-09-13
