
基于辅助短语标记的名词短语识别
2014-08-29 01:46周俏丽张桂平
沈阳航空航天大学学报 2014年1期
刘 飞,周俏丽,张桂平
(沈阳航空航天大学 知识工程中心,沈阳 110136)
基于辅助短语标记的名词短语识别
刘 飞,周俏丽,张桂平
(沈阳航空航天大学 知识工程中心,沈阳 110136)
名词短语的识别是自然语言处理领域中非常重要的子任务。而名词短语的识别性能与识别效率一直是研究人员关注的焦点,为了达到兼顾二者的目的,提出了一种基于辅助短语标记识别名词短语的方法。首先,在分析了短语不同分类体系的基础上,构建了一种映射公式,并根据该公式对不同分类体系的短语类别之间进行映射。然后,根据映射结果及短语的概率分布进行辅助短语标记的组合。实验结果表明,本文的方法在提高F值的基础上,有效地降低了系统的时间开销。
辅助短语标记;名词短语;映射公式
自然语言处理的主要任务是使机器自动的理解人类语言,而名词短语的识别是自然语言处理领域中非常重要的子任务,它直接关系到文本分析和文本处理的正确性。例如,信息抽取系统将名词短语作为它的主要识别对象。同时,名词短语的识别又是自然语言处理领域中许多子任务的基础。
名词短语的实质是关于名词的特殊表达,例如,为了表达“心情愉悦”,通常会附带一系列的例如“跑”、“跳”、“笑”之类的动词,然而通过这些动词很难猜测出文章所要阐述的主要内容。但是,我们可以根据“心情”、“笑容”、“开心”之类的名词,便可以轻而易举的揣测出文章所要表达的主要思想。由此可见,为了使机器自动理解人类语言,名词短语的识别是其必经之路。此外,作为一项重要的基础研究,名词短语的自动识别与分析对于自然语言处理领域中的许多应用研究,包括句法分析、信息检索、信息抽取、机器翻译等,都具有重要的实践意义[1]。当前,针对名词短语(NP)的识别,研究较多的主要有最短名词短语的识别和最长名词短语的识别。其中,识别最短名词短语可以提高信息检索效率。识别最长名词短语可以方便地把握句子的整体结构框架,快速地构建句子的完整句法结构。但是,这两种形式的名词短语都忽略了中间层次的名词短语,通过识别中间层次的名词短语可以分析出子句框架,从而得到子句到整句完整的句子结构框架,同时,中间层次名词短语的识别对基本名词短语的识别和最大名词短语的识别也具有一定的促进作用[2]。
1 相关研究工作
近几年来,国内外研究人员在名词短语的自动识别方面进行了许多有益的探索,提出了一些行之有效的识别方法。主要有基于句法分析的方法和基于机器学习的方法。
基于句法分析方法,Abney[3]首次将句法分析方法运用到英语组块分析系统CASS中。首先对句子进行句法分析,然后从分析的结果中提取名词短语部分,从而得到名词短语的识别结果。但是名词短语的识别效果主要受句法分析器性能的制约。
基于机器学习的方法采用统计学的处理技术从大规模语料库中获取语言分析所需要的知识。基于机器学习产生的方法主要有:(1)基于错误驱动法。错误驱动法也叫基于变换的方法。Lance[4]等人首次利用该方法进行英文组块分析。这种方法适用于解决从语料库中学习转换规则的传统问题。相比而言,对计算机的性能要求较高,并且计算较复杂。(2)基于最大熵(ME)模型。ME模型是基于最大熵理论的统计模型。主要思想是,用有限知识预测未知时,不做任何有偏性假设。周雅倩[5]和Koeling[6]分别利用该模型进行了中英文名词短语的识别。(3)隐马尔科夫(HMM)模型。HMM模型包含一个双重随机过程,一个基本随机过程是系统状态变化的过程;另一个是由状态决定观察的随机过程。李荣[7]在识别非嵌套名词短语时,采用了此模型。这种模型充分利用了词位信息,但由于独立性假设使其忽略了一些特殊特征。(4)支持向量机(SVM)模型。SVM模型根据结构风险最小化原则,对训练样本进行优化学习,能够获得具有很好泛化能力的分类器。Kudo[8]利用这种方法识别基本的名词短语,并在CoNLL-2000基本名词短语识别的评测中,取得了第一名。由于SVM考虑了上下文信息并可以自由加入新特征,使得执行过程非常复杂。(5)基于条件随机场(CRF)模型。CRF模型是在给定需要标注的观察序列的条件下,计算整个标注序列的联合概率。F.Sha[9]在识别名词短语的过程中,使用了CRF模型。由于标记序列的分布条件属性,可以使CRF很好的拟和现实数据,所以不存在标记偏置问题。
在Whitney的论文中,对以上方法做了详细的实验对比,通过对比可以看出,SVM和CRF的识别结果较其它好,F值分别达到94.39%和94.38%,而句法分析方法的识别结果较其它差,F值是77%。由于句法分析方法的效果主要依赖于句法分析器的性能,而在Whitney的论文中,句法分析的方法又是基于规则的,所以识别的效果较其它差。通过10年和12年两届的CIPS-SIGHAN测评可以看出,目前,主流的句法分析方法主要是基于统计的。并且在统计的句法分析器中Berkeley Parser的识别效果较好。所以本文分别利用CRF、SVM和Berkeley Parser工具进行名词短语的识别,并对实验结果进行了对比分析,采用的实验数据来源于宾州树库5.0,在该树库中,训练语料包含18083句,测试语料包含348句。具体结果如表1所示。
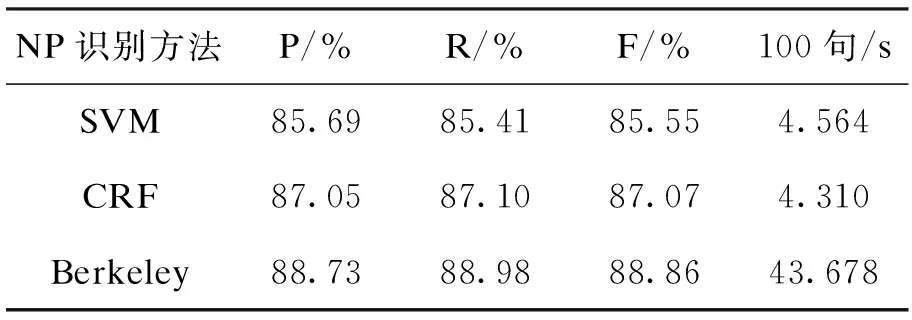
表1 名词短语识别结果对比
通过以上的对比实验可以看出,句法分析方法的识别效果较其他两种好,分析原因主要是由于在进行句法分析时利用了丰富的短语标记信息,但也正是由于丰富的短语标记信息,使得识别效率降低。而SVM和CRF在进行名词短语识别时只有NP标记,由于包含的标记信息少,所以识别的准确率低,识别效率高。由于CRF可以自由选择特征,所以识别的效果较SVM好。为了达到兼顾识别时间和识别性能的目的,本文提出了一种基于辅助短语标记识别名词短语的方法。
2 如何选择辅助短语标记
为了选择辅助短语标记,本文分别从两个角度对短语标记进行分析,一是,从短语的语法功能角度进行分析。二是,从短语的结构组合角度进行分析。通过分析,本文主要从两方面衡量辅助短语标记的选择,一方面,选择的辅助短语标记对名词短语的识别具有促进作用。另一方面,利用选出的辅助短语标记识别名词短语时,能降低系统时间开销。
2.1 短语的语法功能类别
张斌[10]在《现代汉语》中指出,短语是一种句子的结构单位,是造句的备用材料,短语从外部的语法功能进行分类,可以分成体词性短语、谓词性短语、加词性短语。短语这种三分的方法反映了语法学界对实词内部认识的一种深化,是语法研究更加精密化和科学化的必然结果。
体词性短语的语法功能主要做主语、宾语,一般不做谓语。体词性短语包括五种类别。(1)以体词为中心的偏正短语。(2)带有定语的以谓词为中心的偏正短语。(3)由各类体词组成的联合短语。(4)同位短语。(5)“的”字短语和由名量词组成的量词短语。谓词性短语的语法功能与谓词一样,在句子中主要做谓语,有时也能做主语和宾语。从短语的结构分类上看,谓词性短语包括两种类别:(1)形容词短语。(2)动词短语。加词性短语在句子中只能充当定语和状语。加词性短语主要包括介词短语,以及做修饰成分的偏正短语和固定短语。
石毓智[11]在《汉语语法》中指出,句子的基本成分都是S(主语)、V(谓语动词)和O(宾语)。此外,还包括定语、状语和补语。张斌在《现代汉语》中指出,句子中的主语和宾语主要由体词性短语构成,谓语主要由谓词性短语构成,状语和定语主要由加词性短语构成。从短语的角度进行分析,句子的主要成分包含在体词性短语、谓词性短语和加词性短语中。所以分别识别出体词性短语、谓词性短语和加词性短语中的主要部分便可以得到整个句子的框架。
2.2 短语的结构组合类别
周强[12]和俞士汶[12]指出,对短语的标注,除了利用句法功能信息确定不同短语的边界及其相应的标记外,还可以利用不同短语的结构组合信息以及一些特征词信息,得到短语的划分和标注。根据这个原则,产生了不同的短语标注体系。较典型的主要有,北京大学的短语标注体系,中国台湾中研院的短语标注体系,LCD的中文树库的短语标注体系等。由于本文实验语料来自LCD的中文树库Chinese Tree Bank4.0(CTB4.0),所以,本文统计了该树库中的短语类别,共有24类。主要可以分为以下几大类:
(1)名词性短语:NP、DNP、QP、DVP;
(2)动词性短语:VP、VRD、VPT、VCD、VSB、VCP;
(3)介词短语:PP;
(4)形容词短语:ADJP;
(5)副词短语:ADVP;
(6)量词短语:QP,CLP;
(7)并列短语:UCP。
2.3 构建短语类别映射公式
细致考察短语的语法功能类别和短语的结构组合类别,可以发现,两种类别的短语之间存在一定的关联。为达到深度剖析句法内部结构的目的,短语的结构组合类别对短语的语法功能类别做了细化工作。由于体词性短语、谓词性短语和加词性短语,这三类短语在句子中充当主要成分,所以将这三种类型的短语识别出来,便可以得到句子的框架。但是由于目前的语料库是基于短语的结构组合进行短语类别的标注,所以,需要将两种短语类别构建映射关系,本文针对宾州树库4.0中的短语类别做了如下的映射公式。

其中每种标记的具体定义如表2所示。
根据语法功能,可以将名词性质的短语映射到体词性短语中,形容词短语、动词性短语映射到谓词性短语中,介词短语和副词短语等映射到加词性短语中;对于每种短语的分布情况本文分别作了详细统计,具体如表3所示。
从表3可以看出,在体词性短语中,出现频率较高的有NP、DNP、QP和CLP;在谓词性短语中,出现频率较高的有VP、ADJP;在加词性短语中,出现频率较高的有IP、ADVP和PP。所以可以从这三类短语中分别选出频率较高的几种短语类别进行组合。从而本文提出了一种基于辅助短语标记识别名词短语的方法。

表2 短语标记类型定义
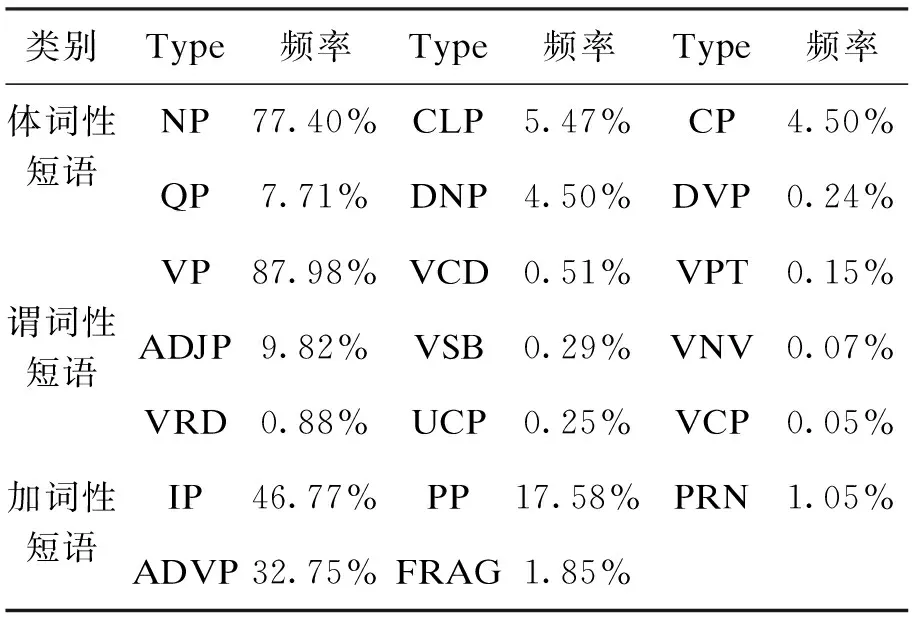
表3 CTB4.0短语频率统计
3 基于辅助短语标记识别任务的介绍及分析
3.1 辅助短语标记任务描述
通过表1可以看出,基于句法分析方法进行名词短语识别的准确率高,但是识别效率低,而基于CRF方法进行名词短语识别的准确率低,但是识别效率高。为了达到兼顾时间和性能的目的,本文通过添加辅助短语标记进行名词短语的识别。从短语的语法功能视角进行分析,句子的主要成分包含在体词性短语、谓词性短语、加词性短语中,其中,体词性短语主要包含句子的主语和宾语,谓词性短语主要包含句子的谓语,加词性短语主要包含句子的状语。所以通过添加这几类相关短语标记便可以构建出句子的整体结构框架,把握句子的概要信息,从而达到兼顾时间和性能的目的。基于此,本文提出了一种基于辅助短语标记识别名词短语的方法。
3.2 系统结构
图1为基于辅助短语标记识别名词短语的大致流程。首先根据映射公式,将宾州树库4.0的短语类别分别映射到体词性短语、谓词性短语、加词性短语中,然后根据表3进行标记组合的选择,本文共做了30余种组合,并通过分析工具生成相应的统计模型。再根据评测公式选择最优的组合模型并利用该模型进行名词短语的识别。
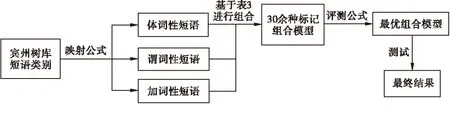
图1 系统流程图
3.3 分析工具简介
为了充分论证基于辅助短语标记识别名词短语方法的有效性,本文采用了当前最具代表性的两种分析工具,一种是Berkeley Parser-1.6;一种是CRF++0.49;
Berkeley Parser是由Dan Klein[13]等人于2006年提出的,是一种基于概率上下文无关文法的句法分析器,由于在解码时采用了分层由粗到细剪枝法,所以识别的准确率较高。同时这种方法还具有可选参数较多,同时支持英语,汉语德语等多种语言等优点。
CRF是John Lafferty[14]等人于2001年提出,是一种基于无向图的条件概率模型,其核心思想是利用无向图理论使序列标注结果达到整个观察序列的全局最优解。CRF已经广泛应用到词性标注、组块识别和命名实体识别等任务中,并且取得了很好的效果。
3.4 辅助短语标记组合实验
本文主要通过映射公式及概率分布选择辅助短语标记。由映射公式可知,NP、QP和DNP被映射到体词性短语中,并且共占体词性短语的比例为89.61%;VP和ADJP被映射到谓词性短语中,并且共占谓词性短语的比例为97.8%;PP、IP和ADVP被映射到加词性短语中,并且共占加词性短语的比例为97.1%。通过以上的分析本文对名词短语(NP)组合了不同的辅助短语标记,其中,列出了准确率排名前10的组合,具体如表4所示:首先,从体词性短语、谓词性短语和加词性短语中分别选出一种或几种短语标记进行组合。其中,组合NP、VP、PP的含义是,从体词性短语中选择NP标记,从谓词性短语中选择VP标记,从加词性短语中选择PP标记,构成组合NP+VP+PP,即训练语料中只含有NP、VP和PP标记,并从最终的识别结果中抽取NP部分,作为NP的识别结果。本节实验所使用的数据如下文表5,同来源于LCD的中文树库Chinese Tree Bank4.0(CTB4.0)。

表4 辅助短语标记组合实验结果对比
通过表4可以发现,在所有组合中,NP+DNP+VP+PP组合的识别结果最好。通过CRF模型识别的F值是87.5886%;通过Berkeley识别的F值是87.39%。NP+DNP+VP+PP组合的识别效果之所以优越,主要有以下几点原因:(1)NP和DNP在体词性短语中,主要做主语和宾语;VP在谓词性短语中,主要做谓语;PP在加词性短语中,主要做状语,此外,又由于PP短语中,主要是以“P+NP”的形式存在[15];所以通过NP+DNP+VP+PP组合,便可以快速构建句子的整体框架。(2)这四类标记在每种短语类别中所占比例较大,其中NP和DNP共占体词性的比例为81.9%;VP占谓词性短语的比例为87.98%;PP占加词性的比例为17.58%。
4 实验结果及分析
本文实验语料来自LCD的中文树库Chinese Tree Bank4.0(CTB4.0),该树库由1064个文件,15162个句子组成。其中训练集为文件号1-885,测试集为文件号900-1078。表5为训练语料与测试语料的统计信息。其中MNP代表最长名词短语。
从表5中可以看出在训练语料和测试语料中NP和MNP复杂度的分布情况,同时也可看出训练语料中NP和MNP的平均长度分别是2.402,6.40;测试语料中NP和MNP的平均长度分别为2.56,5.89。
NP识别性能的评测标准包括准确率(P)、召回率(R)以及召回率和准确率的综合评价指标F值。具体定义如下:

表5 实验语料信息统计
名词短语识别的准确率:

名词短语识别召回率:

以及综合反应二者的指标:
F=(β2+1)×P×R/(β2×P+R),β2=1
系统对“正确的标记”采用了严格的定义,即当且仅当NP的左右边界都被正确识别。
4.2 对比实验
通过表4,可以选出最优辅助短语标记组合NP+VP+PP+DNP,为了证明辅助短语标记对名词短语识别的有效性,本文进行了三种对比实验,(1)最优辅助短语标记组合NP+VP+PP+DNP,即训练语料中标记信息有NP、VP、PP、DNP,并从识别的结果中抽取NP结果,作为NP的最终识别结果;(2)NP标记,即训练语料中标记信息只有NP;(3)所有标记(ALL),即训练语料中包含宾州树库中所有短语标记类型,并从识别的结果中抽取NP结果,作为NP的识别结果。为了充分刻画本文方法的可行性,本文分别利用Berkeley Parser和CRF两种分析工具进行了对比实验。
4.2.1 NP实验
利用Berkeley Parser和CRF两种分析工具,分别对NP、NP+VP+PP+DNP和ALL三种组合标记进行了名词短语的识别。具体实验结果如表6所示,其中最优组合代表NP+VP+PP+DNP组合。在CRF识别方法中,Fs表示在219秒内三种标记识别出名词短语的F值,在Berkeley识别方法中,Fs表示在242秒内三种标记识别出名词短语的F值。

表6 NP实验结果对比
从表6中可以看出,在CRF和Berkeley两种分析工具中,通过最优组合标记识别的NP结果较好。(1)从最优组合标记的识别结果和NP标记的识别结果中可以看出,最优组合标记识别结果的F值比NP标记识别结果的F值分别提高了0.2%和0.99%;由此说明VP、PP和DNP三种辅助短语标记确实促进了名词短语的识别。同时Fs值较NP标记的Fs值也有所提高,由此说明最优组合标记的识别效率较NP标记的识别效率高。(2)从最优组合标记的识别结果和ALL标记的识别结果中可以看出。在Berkeley中,最优组合标记识别结果的F值比ALL标记识别结果的F值有所提高,由此说明了最优组合标记的识别效果较ALL标记的识别效果好。在CRF中,ALL标记识别结果的F值比最优组合标记识别结果的F值提高了0.15%。由于ALL标记包含了宾州树库中所有的短语类别,所以识别的时间约是最优组合标记识别时间的3.08倍。显然,提高的0.15%消耗了系统总时间的0.68倍。而最优组合标记的Fs值比ALL标记的Fs值提高了0.47%,由此说明最优组合标记的识效率较ALL标记的识别效率高。
4.2.2 MNP识别结果
基于MNP在自然语言处理中的重要作用,同时,MNP也是名词短语组成结构中最难识别的一类,本文在识别了名词短语的基础上,从名词短语的识别结果中抽取MNP部分,作为MNP的结果,并对MNP进行了相应的分析,表7为抽取的MNP结果,其中最优组合代表NP+VP+PP+DNP组合。在CRF识别方法中,Fs表示在219秒内三种标记识别出最大名词短语的F值,在Berkeley识别方法中,Fs表示在242秒内三种标记识别出最大名词短语的F值。

表7 MNP识别结果对比
从表7中可以看出,在CRF和Berkeley两种分析工具中,从最优组合标记识别结果中抽取的MNP结果较其他两种都好,F值比从NP标记识别结果中抽取的MNP的F值分别提高了0.43%和2.62%,比从ALL标记识别结果中抽取的MNP的F值分别提高了0.14%和0.95%。由此说明通过辅助短语标记识别名词短语时,对MNP的结果也具有促进作用。同时,Fs值较其他两种标记识别的Fs值也有所提高,由此说明了最优组合标记的识别效率较其他两种高。而在CRF工具的识别过程中,将每次识别后的名词短语归结为一个NP节点并作为下次NP识别的输入,由于归结的过程中,丢失了NP中词和词性的信息,所以导致通过CRF工具得到的MNP效果较Berkeley差。
4.3 错误实例分析
本文对三种标记组合的名词短语识别的错误实例进行分析,发现以下几种类型的句子在错误实例中所占比例较大
(1)名词短语中含有并列连词,在错误率中占有4.22%。如下例子:
错误结果:……NP[NP[台湾/NR]与/CC NP[大陆/NN]]……
正确结果:……NP[台湾/NR 与/CC 大陆/NN]……
(2)名词短语由多个连续名词组成,在错误率中占有56.36%。如下例子:
错误结果:……NP[NP[NP[中华/NR 人民/NN 共和国/NN]NP[国务院/NN]]NP[副总理/NN]]……
正确结果:……NP[NP[中华/NR 人民/NN 共和国/NN 国务院/NN]NP[副总理/NN]]……
(3)名词短语的左边界是介词,在错误率中占有0.23%。如下例子:
错误结果:……对/P NP[NP[台/NR]NP[合作/NN]]……
正确结果:……NP[对/P NP[台/NR]NP[合作/NN]]……
此外,还有以下几种类型错误。
例子1:
错误结果:NP[电文/NN]NP[全/DT NP[文/NN]]……
正确结果:NP[NP[电文/NN]全/DT NP[文/NN]]……
例子2:
错误结果:NP[NP[中国/NR]建立/VV NP[彗星/NN]撞击/VV NP[木星/NR]NP[观测网/NN]]
正确结果:NP[中国/NR]建立/VV NP[NP[彗星/NN]撞击/VV NP[木星/NR]NP[观测网/NN]]
以上几类错误在总的错误实例中所占比例已经超过70%,所以说对并列短语的识别、多个名词连续出现及左边界是介词等几种类别的名词短语的识别还有待加强。
5 总结
名词短语的自动识别是自然语言处理领域中非常重要的子任务,为了同时兼顾名词短语的识别性能和识别效率,本文提出了一种基于辅助短语标记识别名词短语的方法。首先,本文在分析了短语不同分类体系的基础上,构建了一种映射公式,并通过该公式对不同分类体系的短语类别之间进行映射。然后根据映射结果及短语的概率分布进行了辅助短语标记的组合。实验结果表明,基于辅助短语标记的名词短语识别方法在提高了名词短语识别准确率的基础上,有效地降低了时间开销。
在今后的研究中,将从以下两个方面提高识别性能:
(1)针对歧义结构问题,尝试引入语义信息来提高名词短语自动识别的准确率。
(2)集中解决名词短语内部含有并列词的情况。
[1]梁颖红.基于多Agent的英汉文本语块识别技术研究[D].哈尔滨:哈尔滨工业大学,2006:8-14.
[2]Angel S Y,Kam Fai Wong,et al.Effectiveness analysis of linguistics and corpus based noun phrase partial parsers[C].In Proceedings of Natural Language Processing Pacific Rim Symposium,1995:252-257.
[3]Abney S.Partial parsing via finite-state cascades[J].Natural Language Engineering,1996,2(4):337-344.
[4]Ramshaw,Lance and Mitch Marcus.Text chunking using transformation-based learning[C].Somerset,New Jersey:Association for Computational Linguistics,1995.
[5]周雅倩,郭以昆,黄萱菁,等.基于最大熵方法的中英文基本名词短语识别[J].计算机研究与发展,2003,40(3):440-446.
[6]Koeling,Rob.Chunking with maximum entropy models[C].2nd Workshop on Learning Language in Logic and the 4th Conference on Computational Natural Language Learning,2000:139-141.
[7]李荣.基于隐马尔可夫模型的汉语非嵌套名词短语识别[J].忻州师范学院学报,2004,5(20):122-124.
[8]Kudo,Taku and Yuji Matumoto.Chunking with support vector machines[C].2nd Meeting of the North American Chapter of the Association for Computational Linguistics on Language Technologies.Pittsburgh,Pennsylvania:Association for Computational Linguistics,2001:1-8.
[9]Sha Fei and Fernando Pereira.Shallow parsing with conditional random fields[C].Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology.Edmonton,Canada:Association for Computational Linguistics,2003:134-141.
[10]张斌.现代汉语短语[M].上海:华东师范大学出版社,2000.
[11]石毓智.汉语语法[M].北京:商务印书馆,2010:8.
[12]周强,俞士汶.汉语短语标注标记集的确定[J].中文信息学报,1996(4):1-11.
[13]Dan Klein,Slav Petrov.Learning accurate,compact and interpretable tree annotation[C].Proceedings of the 21st International Comference on Computational Linguistics and 44th Annual Meeting of the ACL,2009:25-32.
[14]Lafferty J,McCallum A,Pereira F.Conditional random fields:probabilistic models for segmenting and labeling sequence data[C].In International Conference on Machine Learning,2001:139-141.
[15]李荣.汉语名词短语和动词短语的自动识别方法研究[M].北京:兵器工业出版社,2008.
(责任编辑:刘划 英文审校:刘敬钰)
RecognitionofChinesenounphrasebasedonauxiliaryphrasemark
LIU Fei,ZHOU Qiao-li,ZHANG Gui-ping
Knowledge Engineering Research Center,Shenyang Aerospace University,Shenyang 110136)
Noun Phrase Recognition is one of the most critical components in natural language processing field.The noun phrase recognition performance and its efficiency are the focus of researchers′ attention.In order to combine the two elements,this paper proposes a method of recognizing noun phrases based on auxiliary phrase mark.First,this paper presents a mapping between phrases by using the mapping formula based on the detailed analysis of the different classification system of the phrases.Then,according to the mapping results and the probability of the distribution of the auxiliary phrase mark,lots of combinations are established.Experimental results show that this method effectively reduces the time of noun phrase recognition without reducing the F-value.
auxiliary phrase mark;noun phrase;mapping formula
2013-10-24
国家科技支撑计划项目(项目编号:2012BAH14F00);辽宁省教育厅科学研究一般项目(项目编号:L2012056)
刘飞(1987-),女,辽宁大连人,在读硕士,主要研究方向:知识管理与智能人机交互,E-mail:fei_l2011@163.com;张桂平(1962-),女,辽宁本溪人,教授,主要研究方向:自然语言处理,机器翻译,E-mail:zgp@ge-soft.com。
2095-1248(2014)01-0052-08
TP391.1
A
10.3969/j.issn.2095-1248.2014.01.012
猜你喜欢
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
西夏研究(2020年2期)2020-06-01
海外华文教育(2016年1期)2017-01-20
海峡姐妹(2016年2期)2016-02-27
外语学刊(2016年4期)2016-01-23
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
现代经济信息(2009年8期)2009-02-03
