
基于支持向量机对稻米淀粉含量的回归预测研究
2014-08-06 03:30周志聪祁广云
黑龙江八一农垦大学学报 2014年6期
周志聪,祁广云
(黑龙江八一农垦大学信息技术学院,大庆 163319)
水稻是世界是上最重要的粮食作物之一,也是我国最重要的粮食作物之一。近些年随着生活水平的提高,人们对稻米品质的要求越来越高,而稻米中所含淀粉含量的高低是决定稻米口感和食味品质的重要因素之一[1],对淀粉含量的相关测定越来越重要,对生产加工流水线作业实时检测的需求越来越高。传统的测定方法:酶水解法和酸水解法测试过程繁琐而且对测定样品造成破坏,而近红外检测结合支持向量机在对样品测定的过程简单、快速,还不会对样品本身造成任何的损害。
1 支持向量机简介
支持向量机(SVM)是Vapnik 等人根据统计学理论提出的一种新的通用学习方法,它是建立在统计学理论的结构风险最小原理与VC 维理论基础上的,能够较好地解决小样本、非线性、高维数和局部极小点等实际问题。已成为机器学习界的研究热点之一,并且成功在分类、函数逼近和时间序列预测等方面广泛应用。另外SVM 的求解最后转化成二次规划问题的求解。因此,SVM 的解是唯一且全局最优的。基于这两个优点,使得SVM 被提出后就得到了广泛的重视和应用。
SVM 方法最初只在模式识别问题方面应用研究,随着Vapnik 比对ε 不敏感损失函数的引入,SVM已经被推广到非线性系统的回归估计,并展现出了极好的学习能力和问题处理能力。支持向量机方法在非线性系统分类辨识、建模与控制、预测和预报有着潜在的广泛应用,使得对其研究显得非常重要。
1.1 支持向量机的原理
从搜集的数据中学习归纳出系统的相关规律,然后利用这些规律对未来数据或无法观测到的数据进行预测,是进行数据挖
掘一直以来关注的重要问题。回归分析是预测方法之一,其目的是找出数值型变量间的相关关系,用函数关系式表达出来。回归分析可以进行因果预测,模型仅仅依赖于要预测的变量与其他变量的关系。
回归方法假定数据分布之前建立一个特定的模型,再根据实际数据求模型的参数值。模型是否能提供合理的预测,主要在于自变量和因变量的分布是否符合模型。一般在建立回归预测方程的时候,都将会考虑多种可能的自变量的集合,确保回归预测方法的精准性。回归分析中的变量有两类:自变量和因变量。根据自变量的个数,回归分析分为:一元回归和多元回归。根据自变量和因变量的函数关系分为:线性回归和非线性回归,其中非线性回归又包括不同的类型。
支持向量机首先考虑线性回归,但主要运用支持向量机非线性回归,故线性回归方法省略。支持向量机在考虑非线性回归,首先使用一个非线性映射把数据映射到一个高维特征空间,再在高维特征空间进行线性回归,从而取得在原空间非线性回归的效果。
假设样本x 用非线性函数Φ(x)映射到高维空间,并令K(xi,xj)=Φ(Xi)·Φ(xj),则非线性回归问题转化为:
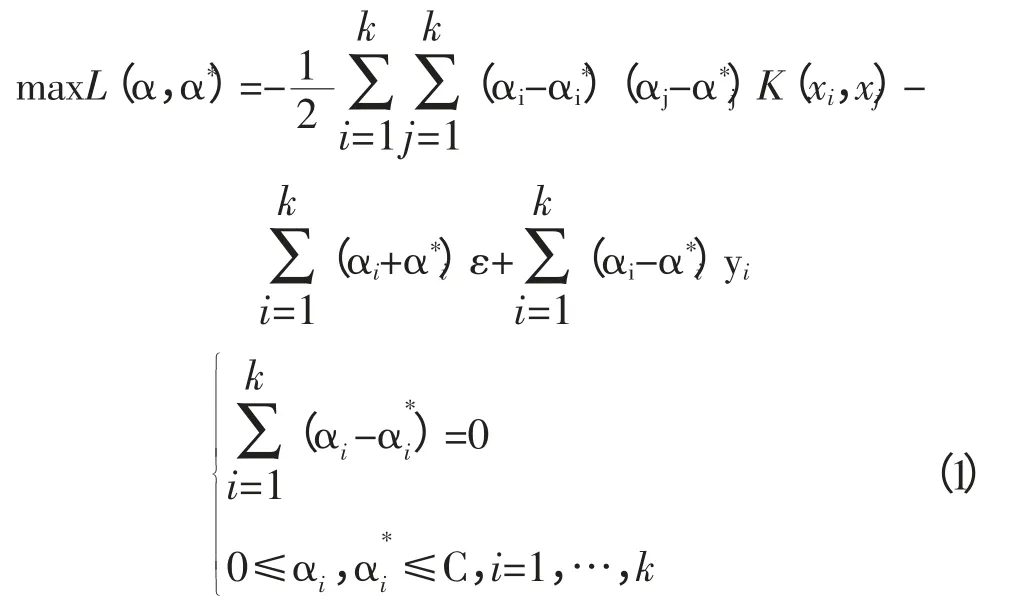
此时,回归估计函数为:
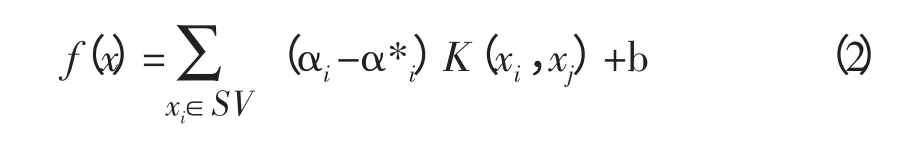
SV 是支持向量机和,即满足二次规划中约束等式成立的那些点的集合。另外b 按如下公式计算:
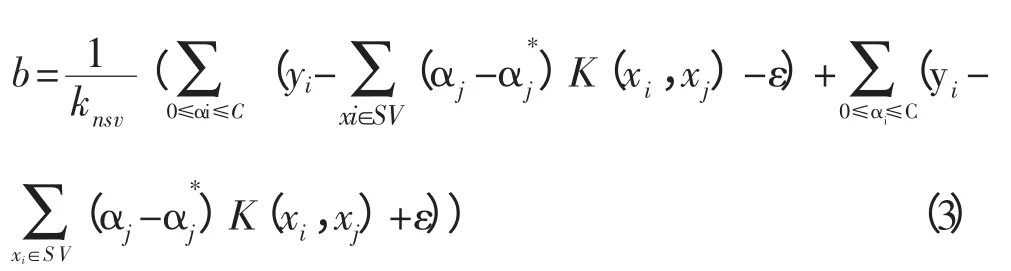
式(3)中:knsv为支持向量数量。
SVM 理论只考虑高维特征空间的运算K(xi,xj)=Ф(xi)·Ф(xj),而不直接使用函数Ф,从而巧妙地解决了因Ф 未知而w 无法显示表达的问题,称K(xi,xj)为核函数。已经证明只要满足Mercer 条件的对称函数既可作为核函数,常用的核函数有:
多项式核函数:K(x,y)=((x·y)+1)d
Sigmoid 核函数:K(x,y)=tanh(κ(x·y)+Θ)[2-4]
2 材料与方法
2.1 试验材料与试验仪器
材料:80 份稻米样品取自黑龙江八一农垦大学农学院。
试验仪器:傅里叶变换近红外光谱仪WQF-600N,北京北分瑞利分析仪器(集团)公司。
2.2 数据采集
2.2.1 光谱采集
通过WFQ-600N 傅立叶变换近红外光谱仪采集了80 份稻米样品近红外光谱数据,波长范围为1 100~2 498 nm,每隔2 nm 扫描一次。共700 个通道扫描,光谱图如图1 所示:
2.2.2 淀粉的测定(酸水解法)
参照GB/T5009.9-2008。由表1 可知,稻米淀粉含量所占比例的最小值为62.826%,最大值为66.472%,大部分分布在63%~65%之间。可见,所选的80 个稻米样品的淀粉含量涵盖范围广泛,淀粉含量数据分布合理,表明试验选取的稻米样品具有代表性。
3 SVM 模型建立与训练
3.1 SVM 模型调用
在MATLAB 中载入libsvm 3.17 工具箱,分别调用svmtrain 和svmpredict 两个函数。
Svmtrain 调用格式为model=svmtrain(train_y,train_x,'options');
Svmpredict 调用格式为[predicttest_y,accuracy,dec_value] = svmpredict(test_y,test_x,model)。
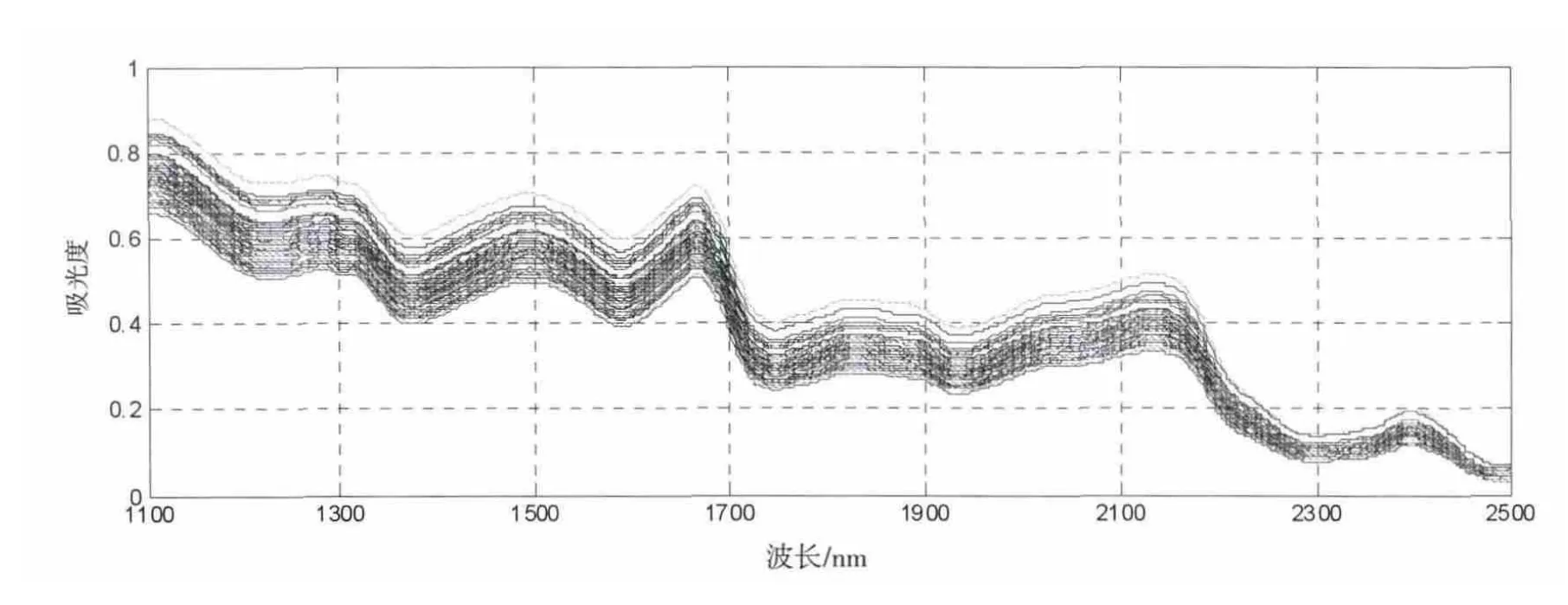
图1 稻米籽粒的原始近红外全光谱图Fig.1 NIR spectra of rice grain
表1 稻米样品淀粉含量化学值Table 1 The chemical value of starch content on rice samples
3.2 SVM 模型参数寻优
支持向量机模型参数寻优方法主要有:网格寻优、粒子群算法寻优、遗传算法寻优。
如图2,经比对训练结果分析后,采用遗传算法寻优。运用遗传算法参数寻优代码运算求得寻优参数为:c = 18.72、g = 36.066 1、p = 0.000 122 07[7-8]。然后将采集到的数据中的前60 个作为训练集,后20 个作为预测集,在MATLAB 中调用libsvm 3.17 工具箱,选用径向基核函数,建立模型:
model = svmtrain(train_y,train_x,'-s 3 -t 2 -c 18.72 -g 36.066 1-p 0.000 122 07');
[predicttest_y,accuracy,dec_value] = svmpredict(test_y,test_x,model)。
4 预测与结果分析
图3 为运用遗传算法参数寻优后的训练集原始数据与模型预测数据对比和预测集原始数据与模型预测数据对比,图3 中的纵坐标表示水稻淀粉含量,横坐标表示对应样品号,蓝色圆形代表原始数值,红色三角形代表预测数值。图3 中的下图为训练集原始样品淀粉含量与训练后所预测的淀粉含量,上图为预测集原始样品淀粉含量与所预测的淀粉含量,由预测相关结果的图3 中图像显示可知支持向量机回归性能已达标,经过训练后所建立模型可以使用。
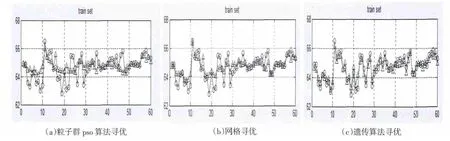
图2 各算法参数寻优训练结果对比Fig.2 The training results of optimal parameter on different algorithms
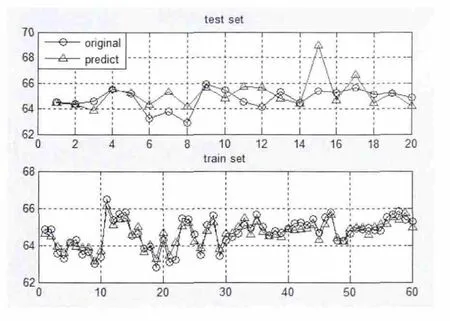
图3 预测相关结果显示Fig.3 The prediction results
从表2 中可以看出,稻米样本的淀粉含量实际化学值与预测值有所差别,最大误差为4.47%,但只要增加训练样本的数量,预测结果会更加精确。这足以说明利用matlab 的libsvm 工具箱建立模型对稻米淀粉含量进行预测是可行的。
5 结论
试验用20 个样品作为验证集进行模型验证,得到稻米淀粉含量的模型预测值和化学真实值之间的相关系数为0.89 ,说明文中所建立的预测模型的准确性较高。支持向量机结合近红外光谱法是一种非常值得推广的分析方法,将其应用于稻米籽粒淀粉含量测定是可行的,并有很好的发展前景。是未来稻米籽粒检测的研究方向之一。
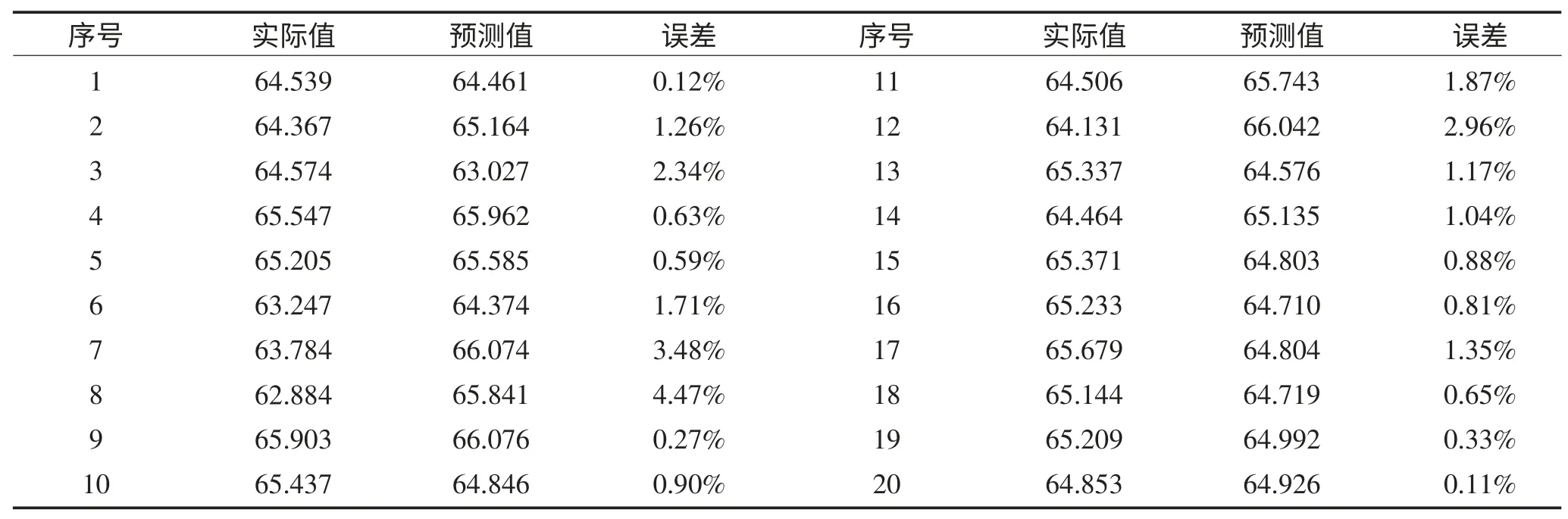
表2 淀粉预测的结果与实际结果对照Table 2 The comparison of starch prediction results and the actual results
[1]余飞,邓丹雯,董婧,等.直链淀粉含量的影响因素及其应用研究进展[J].食品科学,2007,28(10):604-608.
[2]郭水霞,王一夫,陈安.基于支持向量机回归模型的海量数据预测[J].计算机工程与应用,2007,43(5):12-14.
[3]袁玉萍,魏玉芬,代冬岩,等.基于支持向量顺序回归机对农业经济预警的研究[J].黑龙江八一农垦大学学报,2012,24(1):92-95.
[4]杨铭,杨费莉.基于最小二乘支持向量机的苯麻滴鼻液含量测定[J].中国医药工业杂志,2008,38(11):790-793.
[5]张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32-42.
[6]李海生.支持向量机回归算法与应用研究[D].广州:华南理工大学,2005.
[7]李翠平,郑瑶瑕,张佳,等.基于遗传算法优化的支持向量机品位插值模型[J].北京科技大学学报,2013,35(7):837-843.
[8]冯振华,杨洁明.SVM回归的参数选择探讨[J].机械工程与自动化,2007(3):17-18.
猜你喜欢
农业技术与装备(2022年6期)2022-08-17
美食(2022年5期)2022-05-07
少儿科学周刊·儿童版(2021年21期)2021-12-11
中国粮食经济(2018年5期)2018-12-27
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
西安工程大学学报(2016年6期)2017-01-15
现代计算机(2016年34期)2016-02-28
中国粮油学报(2016年1期)2016-02-06
智能系统学报(2015年4期)2015-12-27
