
一种基于动态权值的改进协同过滤算法研究
2014-07-19 06:59王竹婷
赤峰学院学报·自然科学版 2014年20期
王竹婷
(合肥学院 计算机科学与技术系,安徽 合肥 230601)
一种基于动态权值的改进协同过滤算法研究
王竹婷
(合肥学院 计算机科学与技术系,安徽 合肥 230601)
协同过滤是个性化推荐系统中使用最为广泛的一种推荐算法之一,分为基于用户和基于项目两种协同过滤算法.本文提出的改进算法将两种方法相结合使用,首先改进了传统的相似度度量方法,再分别利用用户和项目之间的相似度值预测未评分项目值,并将两种预测结果加权平均,根据用户近邻数和项目近邻数动态确定加权系数.实验结果表明,改进后的协同过滤算法可以提高推荐质量.
协同过滤;个性化推荐系统;相似度
1 引言
个性化推荐系统就是通过记录用户相关的网上历史行为信息,包括网站的访问次数,网页浏览时间的长短,有无购买行为、评分多少等,利用这些历史信息,提取关键数据,建立用户兴趣模型,并根据用户兴趣模型预测用户可能感兴趣的信息资源,再推荐给用户使用的个性化服务系统.目前国内外大型门户网站和电子商务平台都不同程度的使用推荐系统为用户进行推荐服务,该系统一方面可以帮助用户快速、准确地找到所需资源,而无需耗费大量的时间对海量的信息进行筛选;另一方面可以帮助网络商家在线推销自己的产品.
推荐系统根据推荐算法的不同,可以分为基于内容的推荐[1],基于关联规则的推荐[2],协同过滤推荐[3]和混合推荐算法[4].其中协同过滤算法是目前为止应用于推荐系统的最成功的算法.协同过滤算法又分为基于用户的协同过滤算法和基于项目的协同过滤算法两种,两种方法各具优势,基于用户的算法可以实现跨类型的推荐,但受数据稀疏性影响较大;基于项目的算法受数据稀疏性影响较小,但无法进行跨类型的推荐.本文首先改进了传统的用户和项目之间的相似性度量方法,采用加权平均将两种算法的预测结果相结合,并通过用户近邻数和项目近邻数动态调整加权系数.
2 问题描述及传统的相似性度量方法
传统的协同过滤算法一般分三个步骤:首先,从用户网上行为数据库中提取关键数据,构建用户-评分矩阵;接下来,利用用户-评分矩阵中的用户评分信息,计算用户与用户之间项目与项目之间的相似度;最后利用相似度信息预测用户未评分项目的评分情况,从而选择评分高的项目为目标用户进行推荐.因此,相似度度量方法是协同过滤推荐算法中非常关键的技术,其直接决定了推荐系统的推荐质量.
2.1 用户-项目矩阵的构建
用户-项目矩阵是一个m*n阶的二维矩阵,m是用户数,U={u1,u2,…,um}为用户集合,n是项目数,I={i1,i2,…,in}为项目集合,矩阵中第i行第j列元素Rij表示第i个用户对第j的项目的评分值,矩阵R(m,n)具体形式如表1所示.Rij的值越高表示用户i对项目j越感兴趣.

表1 用户-项目评分矩阵
2.2 传统的相似度度量方法
协同过滤算法根据相似度度量对象的不同分为基于用户和基于项目的两种.基于用户的算法是根据不同用户的共同评分项目,计算出用户与用户之间的相似程度,再找到与目标用户相似度较高的用户群体预测项目评分实施推荐;基于项目的算法则通过评分过共同项目的不同用户群体的评分值,计算项目与项目之间的相似度,再通过目标用户已评分项目与未评分项目之间的相似度预测评分值.基于用户和基于项目的相似度计算都有三种基本方法,余弦相似性、修正的余弦相似性和Pearson相关系数,文献[5]通过实验证明在三种相似性度量方法中Pearson相关系数可以更好的推算出用户或项目之间的相似程度,本文也选用Pearson项目系数作为相似度计算方法.
2.2.1 用户的相似度
用户的相似度表示不同的用户之间在兴趣爱好上相似的程度,其计算公式如下:

公式(1)中,sim(i,a)表示用户i和用户a之间的相似性,Nai表示用户a和用户i共同评分过的项目集分别表示用户i和用户a的平均评分值.该公式通过两用户共同评分过的项目评分值,计算两者之间的相似度.
2.2.2 项目的相似性
项目之间的相似性表示用户对两个不同项目同时发生兴趣的程度,计算公式如下:
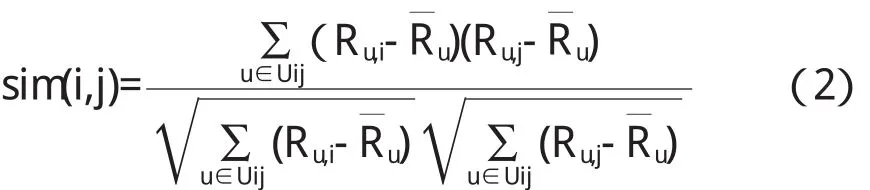
公式(2)中,sim(i,j)表示项目i和项目j之间的相似性,Uij表示共同评分过项目i和项目j的用户集是用户u的平均评分值.该公式通过评分过相同项目的不同用户的评分值,计算项目之间的相似度.
2.3 传统相似性度量算法的缺陷
基于用户的算法,重点在于目标用户和其他用户之间的相似性度量方法,当两个用户共同评分的项目较多,评分相似的时候,说明两者的兴趣爱好相似,通过传统的计算方法也可以得出两者相似度较高,以此数据作为项目预测依据,结果较为准确;但在实际应用中,一个推荐系统可能要推荐成千上万个项目,而一个用户评分过的项目量不足1%,两个用户共同评分过的项目数量就更稀少,很多情况下,只有一到两个共同评分的项目,而且如果这个两个评分相近的话,传统的计算方法相似度非常高,甚至有可能为1,这样的运算结果表明,两者之间的兴趣爱好非常接近,但实际情况并非如此.基于项目的相似性也存在类似的问题,当共同评给两个项目的评分用户过少时,相似度的计算极为不准确.
2.4 相似性度量方法的改进
由于传统的基于用户和基于项目的两种相似性度量方法在共同评分的数据极为稀少或有着共同评分项目的用户极为稀少的时候,计算出来的相似度值与实际情况存在较大的误差,为避免此类问题发生,本文提出在计算相似度时设定两个阈值,并采用分段函数进行计算.
2.4.1 改进的基于用户的相似性度量
在计算用户i和用户a之间的相似性时,首先找出两个用户共同评分过的项目集Nai,计算Nai中的项目个数NumNai,设置好阈值μ1,将NumNai的值与μ1做比较,若小于μ1,则i和a的相似度值为0,如果大于或等于μ1,使用原有的相似度值.

2.4.2 改进的基于项目的相似性度量
在计算项目i与项目j之间的相似度时,采用同样的改进措施,先找出共同评分过项目i和项目j的用户集合Uij,计算Uij中用户的个数NumUij,同样设定阈值μ2,当两个项目共同评分过的用户数量NumUij小于μ2时,则两个项目的相似度为0,如果NumUij大于或等于μ2,则保持原有相似度值不变.
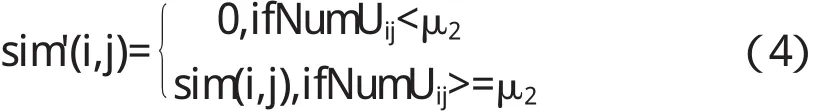
3 协同过滤算法预测评分值
3.1 基于用户的评分值预测
基于用户的评分值预测算法,要根据用户之间的相似性值,找到与目标用户相似程度较高的最近邻居用户集,本文设置最近临用户的相似度阈值为η,当目标用户与某用户的相似度大于或等于η时,则该用户为目标用户的最近邻居.找到最近邻居集合后,根据公式(5)计算出用户对未评分项的评分值.公式(5)中puser(a,y)表示用户a对未评分项目y的预测评分值,NUa为用户a的最近邻居集.

3.2 基于项目的评分值预测
基于项目的评分值预测算法,先设置项目之间的相似度值θ,寻找与目标项目相似度大于或等于θ的作为其最近邻居集集合,再利用公式(6)预测评分值.公式(6)中pitem(a,y)表示用户a对项目y的预测评分值,NIy为项目y的最近邻居集合,为项目y用户给出的平均评分值.

3.3 改进算法的评分值预测
本文在第二部分改进了基于用户和项目的相似性度量方法,改进后的算法虽然保证了相似度的计算更加准确,但最近邻集合的选择条件更加苛刻,无论是用户的最近邻集合还是项目的最近邻集合的规模都大大缩小了,容易对评分值的预测产生负面影响,为尽量减弱最近邻集合缩小而产生的负面影响,本文采用动态的权重系数将基于用户和基于项目的评分值预测算法相结合.
公式(7)为用户未评分项目最终预测值的计算方法,其中NumNUa表示用户a的最近邻居数量,NumUIy表示项目y的最近邻居数量,p(a,y)为用户a对项目y的最终评分值预测结果,按照这种方法,当用户a的最近邻集合规模越大时,puser(a,y)所占比重越大;当项目y的最近邻集合规模越大时,pitem(a,y)所占比重越大.

4 实验仿真
笔者用c语言分别对基于用户的协同过滤算法、基于项目的协同过滤算法、以及本文提出的改进算法编程实现,采用GroupLens项目研究组收集的MovieLens数据集进行测试.该数据集包括943名用户对1682部电影的100,000项评分数据,评分值的取值范围为1-5;每位用户至少有20个评分项;除训练集和测试集外还包括简单的用户信息描述,如年龄、性别、职业等.实验中只用到训练集和测试集数据,用训练集数据产生预测评分,比较其与测试集数据的接近程度.
本实验采用平均绝对偏差MAE衡量算法的有效性,如公式(8)所示,pij是用户i对项目j的预测评分,qij是用户i对项目j的实际评分,Ni是预测得到的用户i的评分项目数,MAEi是用户i预测评分的绝对偏差,公式(9)中M是用户个数,MAE则是算法在M个用户预测评分上的平均绝对偏差.
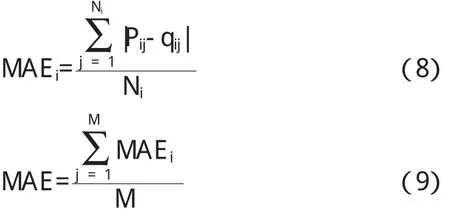
实验采用5组数据集进行测试,这5组数据的训练集都有80000条评分记录,用户——项目评分矩阵的数据密度为5.04%.测试结果如图1所示,图中纵坐标为平均绝对偏差MAE,横坐标为5组数据集的名称.从图中可以看出,本文所提出的改进协同过滤算法MAE值最小,算法预测评分值最接近于真实评分值.

图1 三种协同过滤算法测试结果比较
5 结论
本文首先分析了传统的协同过滤算法在计算用户或项目之间的相似度时,由于两用户共同评分的项目数或同时给两个项目共同评分的用户数达不到一定的数量导致计算结果不准确,为减少这部分数据对计算结果造成的负面影响,本文为用户和项目的相似度计算设置一个阈值,当低于这个阈值时用户或项目的相似度为0,高于该阈值时再使用Pearson相关性计算公式计算相似度;但另一方面,该阈值的设置可能会导致用户或项目的近邻数量减少,降低评分预测值的准确性.采用将基于用户和基于项目的评分预测值加权平均的方法,并通过用户近邻数量和项目近邻数量动态调整权重的方法,能够有效提高预测的准确性.
〔1〕王洁,汤小春.基于社区网络内容的个性化推荐算法研究[J].计算机应用研究,2011,28(4):1248-1250.
〔2〕谢芳,王波.基于关联规则的个性化推荐的改进算法[J].计算机应用,2006(26):149-151.
〔3〕罗辛,欧阳元新,熊璋,袁满.通过相似度支持度优化基于K近邻的协同过滤算法[J].计算机学报, 2010(8):1437-1444.
〔4〕曾春,邢春晓,周立柱.个性化服务技术综述[J].软件学报,2002,13(10):1952-1961.
〔5〕Herlocker L J,Konstan A J,Riedl T J. Empirical analysis of design choices in neighborhood -based collaborative filtering algorithms[J].Information Retrieval,2002,5(4): 287-310.
TP301.6
A
1673-260X(2014)10-0028-03
合肥学院自然科学基金一般项目(14KY11ZR)
猜你喜欢
数学物理学报(2022年5期)2022-10-09
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
河北画报(2020年8期)2020-10-27
数学年刊A辑(中文版)(2019年3期)2019-10-08
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
河北遥感(2017年2期)2017-08-07
衡阳师范学院学报(2016年3期)2016-07-10
浙江大学学报(工学版)(2016年2期)2016-06-05
