
动态时间规整优化局部分块匹配的人脸识别
2014-07-07 01:49徐屹
计算机工程与应用 2014年6期
徐屹
湖南工业职业技术学院信息工程系,长沙 410208
动态时间规整优化局部分块匹配的人脸识别
徐屹
湖南工业职业技术学院信息工程系,长沙 410208
针对现实人脸识别中姿势、光照、表情变化及遮挡等严重影响识别性能的问题,提出了一种基于动态时间规整优化局部分块匹配的户外人脸识别算法。将人脸图像划分成若干大小相等且互不重叠的局部小块;借助于光栅扫描顺序将各个小块按照前额、眼睛、鼻子、嘴巴和下巴的顺序连接成一个单一序列;计算查询人脸与注册人脸之间图像到类的距离,利用动态时间规整的设计思想寻找查询序列与所有注册序列之间的最佳对齐方式。在三个公开人脸数据库LFW、AR及YouTube上的实验验证了该方法的有效性及可靠性,实验结果表明,相比其他几种较为先进的人脸识别方法,该方法取得了更高的识别率,此外,该方法无需任何训练过程,计算成本低。
人脸识别;动态时间规整;局部分块匹配;查询人脸;探针图像
近年来,非约束条件下的人脸识别(FR)[1]引起了学者们广泛的兴趣,许多人脸识别方法在处理约束条件人脸识别时取得了很好的识别效果,然而,由于姿势、光照、表情变化或遮挡常有发生,这种非限制条件人脸识别已成为一项更具挑战的任务[2]。
户外标记人脸(Labeled Face of Wild,LFW)数据集[3]公开后,学者们提出了一些新的用于提高非限制条件下人脸识别性能的方法,例如,文献[4]提出利用三块局部二值模式(Local Binary Pattern,LBP)和四块LBP特征对中心像素周围的相邻图像块之间的相似性进行编码,从而采集到互补于LBP特征的信息,文献[5]将每个人脸图像描述成可视化的多区域概率直方图,有效地改进了光照变化人脸识别问题。为了解决光照、表情、姿态变化人脸识别问题,文献[6]提出使用无监督学习方法对每个人脸图像的微观结构进行编码。针对在剧烈光照变化情况下无法获得足够的特征描述信息的问题,基于梯度幅值自相似性,文献[7]提出了称为梯度边缘幅值模式(Pattern of Edge Gradient,POEM)的判别性特征描述符,取得了很好的识别效果,但是,一定程度上增加了计算开销。为了更好地改善姿态、表情变化对识别的影响,文献[8]采用了生物激发视觉表示,文献[9]提出使用属性和相似分类器输出作为人脸识别的中层特征,文献[10]使用最接近给定查询图像的秩作为这个查询图像的描述符。文献[11]提出了基于距离的逻辑判别和基于距离的最近邻度量方法,文献[12]提出了余弦相似性度量学习方法,最近,文献[13]提出了“关联预测”模型,利用带有较大个人内部变化的附加通用数据集来测量两幅图像之间的相似性,缓解了场景变化对识别效果的影响。上述各方法均取得了良好的识别效果,但是,当应用于带有较大的姿势、光照、表情及场景变化的户外人脸识别中时,各方法并不能取得令人满意的结果[14]。
基于上述分析,为了更好地解决带有光照、表情、姿态变化及面部遮挡的人脸识别问题,提出了一种基于动态时间规整(DTW)[15]的局部分块匹配人脸识别方法。首先将图像划分成子块,然后以光栅扫描顺序重新形成一个序列,在这种方式下,人脸由包含脸部特征顺序信息的块序列表示,本文方法计算查询人脸和注册人脸之间图像到类的距离,寻找查询序列和所有注册序列之间的最佳对齐方式。实验结果验证了本文方法的有效性及可靠性。该研究为FR应用提供了一种有效的候选方法,所提模型与现实世界FR应用的各种图像描述符和特征提取方法均兼容。
1 方法提出
1.1 图像表示
将图像划分成M个不重叠子块,大小为d像素× d′像素,然后依光栅扫描顺序重新将这些子块联接成一个单一序列。人脸由前额、眼睛、鼻子、嘴巴和下巴这样的自然顺序组成,尽管有遮挡和不精确注册,这个顺序是不变的。人脸图像以块序列表示,其中块位置顺序(即人脸特征的顺序)可作为时间信息,因此,处理FR问题可以使用时间序列分析技术。
Fi表示第i块,通过相邻两个块对应像素的值相减计算差异块▽Fi,即
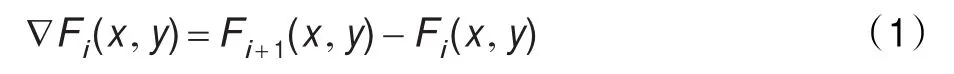
其中,(x,y)是一个像素点的坐标。
这些由空间连续块产生的差异块能增强人脸序列内的顺序信息,这与所提模型是兼容的。此外,从宏观角度来讲,当每个块的大小非常小时,每个块就是一个像素点,差异块▽Fi实际上可以认为是相邻像素Fi+1与Fi的近似一阶导数,因为一阶导数操作对边缘敏感,如眼睛、鼻子、嘴巴这些能够表示详细纹理区域的显著脸部特征就会增强。图1所示为本文方法的图像表示框架。本文方法将差异块的灰度值作为特征,相比使用原始块,相同类的距离分布和不同类的距离分布分离更大。
1.2 动态图像类规整

图1 本文方法的图像表示
通过定义序列之间的距离度量来实现人脸匹配,通常,如果两个序列彼此类似,则期望更小的距离。使用DTW计算两个时间序列之间的距离,例如,对于两个序列A=(3,1,10,5,6)和B=(3,2,1,10,5),它们之间的欧氏距离是,对于这两个近似序列来说这个值有些大,然而,如果忽略B中的“2”,用A中“1,10,5”匹配B中“1,10,5”,不使用按位匹配,A和B之间的距离会大幅减小。DTW基于这个思想计算两个序列之间的距离,以最小的整体成本寻找它们之间的最优对齐方式。匹配期间要考虑顺序信息,因此,不允许有交叉匹配(如A中的“3”匹配B中的“2”,而A中的“1”匹配B中的“3”)。对于FR,这非常合理,因为脸部特征的顺序不能逆转。
借助于DTW的设计思想,本文方法试图找到人脸序列之间的最佳对齐方式,降低遮挡块的影响,将两个序列之间的对齐方式扩展成一个序列和给定类序列集之间的对齐方式。包含M个块的探针图像表示为P={p1,…,pm,…,pM},其中,pm是前文提到的差异块,包含K幅图像的给定类的图库集表示为G={G1,…,Gk,…,GK},其中,每个Gk={gk1,…,gkn,…,gkN}是包含N个块的一幅图库图像,gkn指的是类似pm的块向量。DTW和本文方法的对齐方式如图2所示,规整在两个方向上执行:(1)按照时间维度(维持顺序信息)将探针序列P对齐到给定类的图库序列集G;(2)在每个时间步P的每个块沿着类内维度匹配到所有图库序列中最相似的块。其中,箭头指示每个块的对齐方式,虚线标记了图像和图库图像集之间的最佳规整路径。
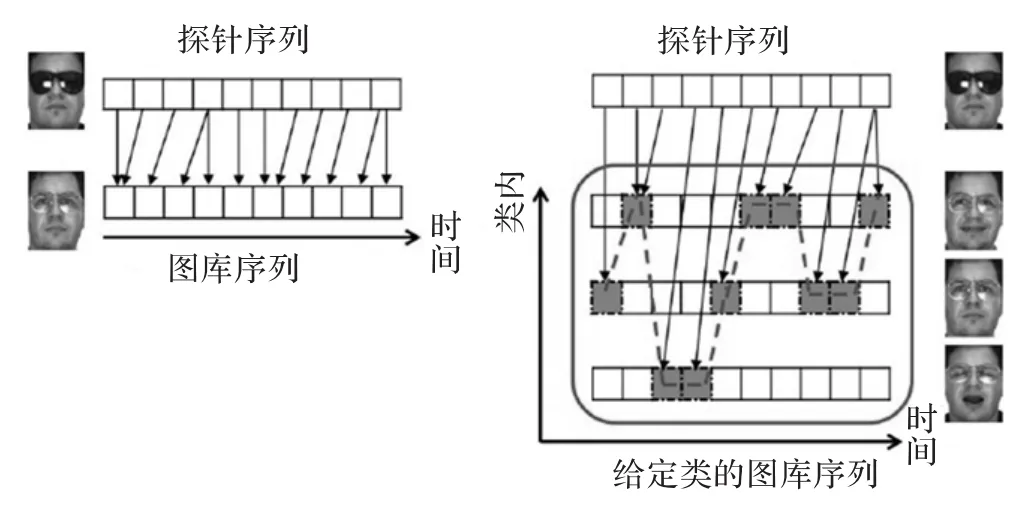
图2 DTW(左)和本文方法(右)的对齐方式说明
规整路径W表示的是T个时间步的P和G之间的对齐方式,定义为W={w1,w2,…,wT}。第t个元素wt是一个索引三元组{mt,nt,kt},表示的是块pmt匹配到块gktnt,其中,mt∈{1,2,…,M},nt∈{1,2,…,N},kt∈{1,2,…,K}。考虑到FR的内容,W满足下列4个约束:
边界约束:m1=1,n1=1,mT=M,nT=N。路径起始于匹配p1到gk11,以匹配pM到gkTN结束,从1到T,k可以是1到K之间的任意值,因为探针块可与图库中任意K幅图像的块匹配。
连续性约束:mt-mt-1≤1,nt-nt-1≤1,每执行一步路径的索引增加1,探针和图库图像中的所有块都会处理到。
单调性约束:mt-1≤mt,nt-1≤nt,路径保存时间顺序,且单调增加。
窗口约束:|mt-nt|≤l,其中,l∈N+是窗口长度,探针块不应该与距离太远的块匹配(如眼睛不能匹配到嘴),长度为l的窗口能限制规整路径在一个合适的范围内。
创建一个局部距离矩阵C∈RM×N×K,其中,每个元素Cm,n,k存储欧氏距离,称为局部成本,pm和gkn之间:Cm,n,k=||pm-gkn||2,W的整体成本定义如下:

最优对齐方式(即最优规整路径)W*是S(W)最小的路径,P和G之间的图像到类之间的距离即为简化的W*整体成本:

计算DDTW(P,G)能够测试所有可能的规整路径,但是计算成本很高,值得庆幸的是,动态规划(DP)可以有效地求解式(3)。创建一个三维累积矩阵C∈RM×N×K,元素Dm,n,k存储子问题的成本,即分配一个m个块的序列到一个有n个块的序列集,匹配第m个块pm到第k个图库图像的块,DDTW(P,G)的计算基于一系列子问题的结果,D可递归计算为:
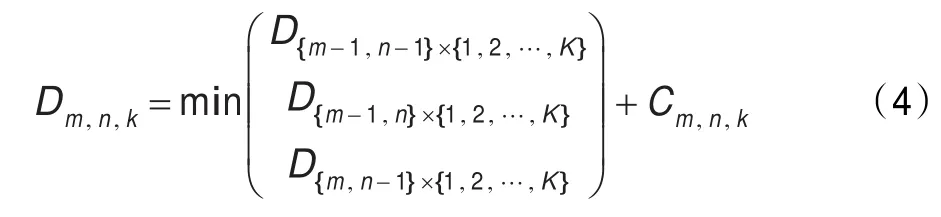
其中,初始化将D扩展为一个(M+1)×(N+1)×K的矩阵,设置D0,0,k=0,D0,n,k=Dm,0,k=∞,×表示笛卡尔积操作,因此,DDTW(P,G)可由下式得到:
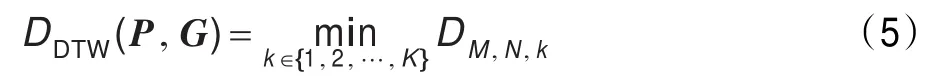
然后探针图像P分类到距离最短的类,未对式(4)的第一项的k作任何约束,因为在每个时间步,探针块可与图库中任意K幅图像的块匹配。
本文方法能从所有可能的规整组合中找到整体成本最小的对齐方式,因此,整体距离主要依赖于人脸最相似的部分,这与视觉感官也是一致的。图3解释了图像到类的规整,图3(a)中,遮挡的人脸属于类2,但当使用图像到图像距离时会被错误分类(最近邻属于类1),尽管图像到图像距离比类2的每个单个图库图像大,但是图像到类距离小,能够产生正确分类。如图3(b)所示,每一步中,探针图像的每个块与图库图像最相似的块匹配,图像到类距离计算主要基于这些成对的最相似的块(匹配的块用相同颜色表示)。
算法1总结了计算探针图像与类之间距离的过程,时间复杂度为O(lmax(M,N)K),其中l<<M(l通常设置为max(M,N)的10%)。当每个类的图库图像数目有限时,K相对较小,因此可以非常有效地获得规整距离。MATLAB实现取平均0.05 s计算一幅图像与类之间的距离,使用大约200个块的序列,相比基于重构的方法,使用所有注册图像表示测试图像,本文方法独立计算探针图像与每个注册类之间的距离。因此,在实际FR应用中,可以并行地产生距离矩阵,还可以增加更新注册数据库。
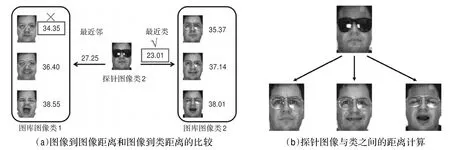
图3 图像到类的规整

2 实验
为了评估本文方法的性能,在三个公开数据库LFW[3]、AR[10]和YouTube数据库[15]上进行了实验。所有的实验均在8 GB内存Intel®CoreTM3.10 GHz Windows XP机器上完成,编程环境为MATLAB 7.0。
2.1 子块大小的影响
这部分研究不同子块大小对本文方法识别性能的影响,从LFW中取400幅未遮挡图像作为图像集,分别包含从0%到50%级别遮挡的6个探针集用于测试,所有图像都裁剪为80×60大小,子块大小从3×3到10×10,划分后,图像剩余的部分忽略不计。简单起见,将探针图像和图库图像划分成相同数目的子块,即M=N,识别结果如图4所示。
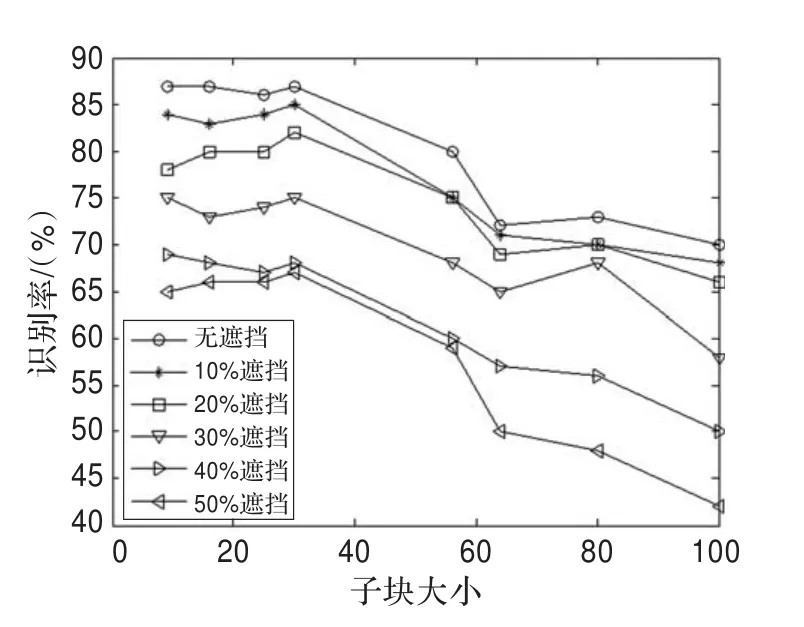
图4 块大小函数的识别率
从图4可以看出,当块大小等于或者小于6×5时,每个识别率曲线都没有大幅波动。尽管存在遮挡比率,本文方法在适当范围内对子块大小的鲁棒性更好。相对较小的块产生的识别率更好,因为它们能比大块提供更灵活的空间信息,然而,如果块太小,计算和内存成本都会增加。根据这一结果,建议使用块大小在4×4至6×5之间。该实验中,根据图像大小,LFW数据库使用的块大小为6×5,AR数据库和YouTube人脸数据库使用的块大小为5×5。
2.2 LFW数据集
将所提基于DTW的局部分块匹配方法与其他几种具有代表性的匹配方法进行了比较,包括使用特征脸作为特征的线性SVM[2](LSVM)、基于稀疏表示的重构(SRC)[16]、基于朴素贝叶斯最近邻的块匹配(NBNN)[11]、基准的最近邻(NN)分类器[4]。NBNN也是一种基于块匹配的方法,分别使用原始块和差异块进行测试,给出了最佳结果。选择LFW数据库的100个对象,每个对象8幅图像,对于每个对象,分别选择K=1,2,3,4幅无遮挡图像作为图库集,另外4幅有合成遮挡的图像作为探针集。每个测试图库集与探针集无重复图像,所有图像均裁剪成90×65大小。各方法的参数设置分别参照各自所在文献,如图5所示为每个人不同图库数目下各个方法的识别率。
从图5可以看出,起始阶段(遮挡水平≤10%)SRC的性能略优于本文方法,然而,当遮挡增加时,性能急剧下降。基于块匹配的方法NBNN和本文方法整体上执行效果优于其他几种方法。当每个人仅有一幅图库图像可用(K=1)时,本文方法中图像到类的距离等于图像到图像的距离,仍能对所有级别的遮挡获得最佳识别率,因为它通过规整并考虑面部特征的顺序,能找到图库和探针图像之间的最优对齐方式。综合4幅图可看出,不论K取何值,本文方法取得的识别效果均优于其他各个方法。
2.3 AR数据集
这部分在有实际伪装的AR数据库上测试本文方法,使用AR数据库的一个包含各种光照条件、表情变化和遮挡的子集(包含50位男性50位女性),使用未遮挡的带有各种表情的正面视图图像作为图库图像(每人8幅图像),对于每个对象,从中分别选择K=1,2,4,6,8幅图像作为图库集,使用包含太阳镜(覆盖图像的30%)和围巾(覆盖图像的50%)的两个分离集作为测试集,所有图像均裁剪为80×60大小,图6所示为各方法的识别结果。
从图6可以看出,当可用的图库图像较少时,识别率呈下降趋势,本文方法的性能稳定且显著优于其他方法,甚至在K=1时,本文方法在太阳镜集和围巾集遮挡情况下的识别率可分别高达90%和83%。
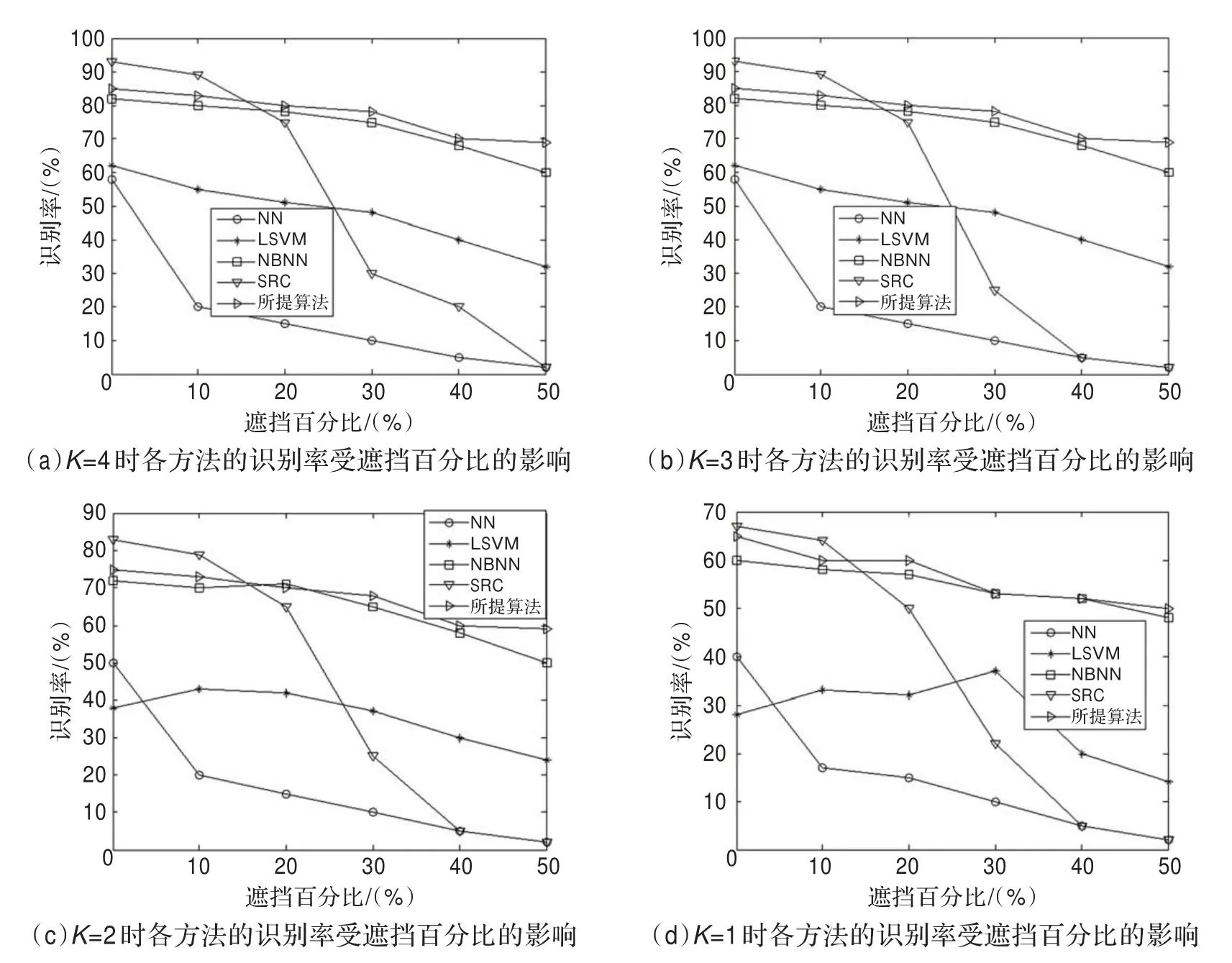
图5 在FRGC数据库上每个人不同图库图像数目的识别率
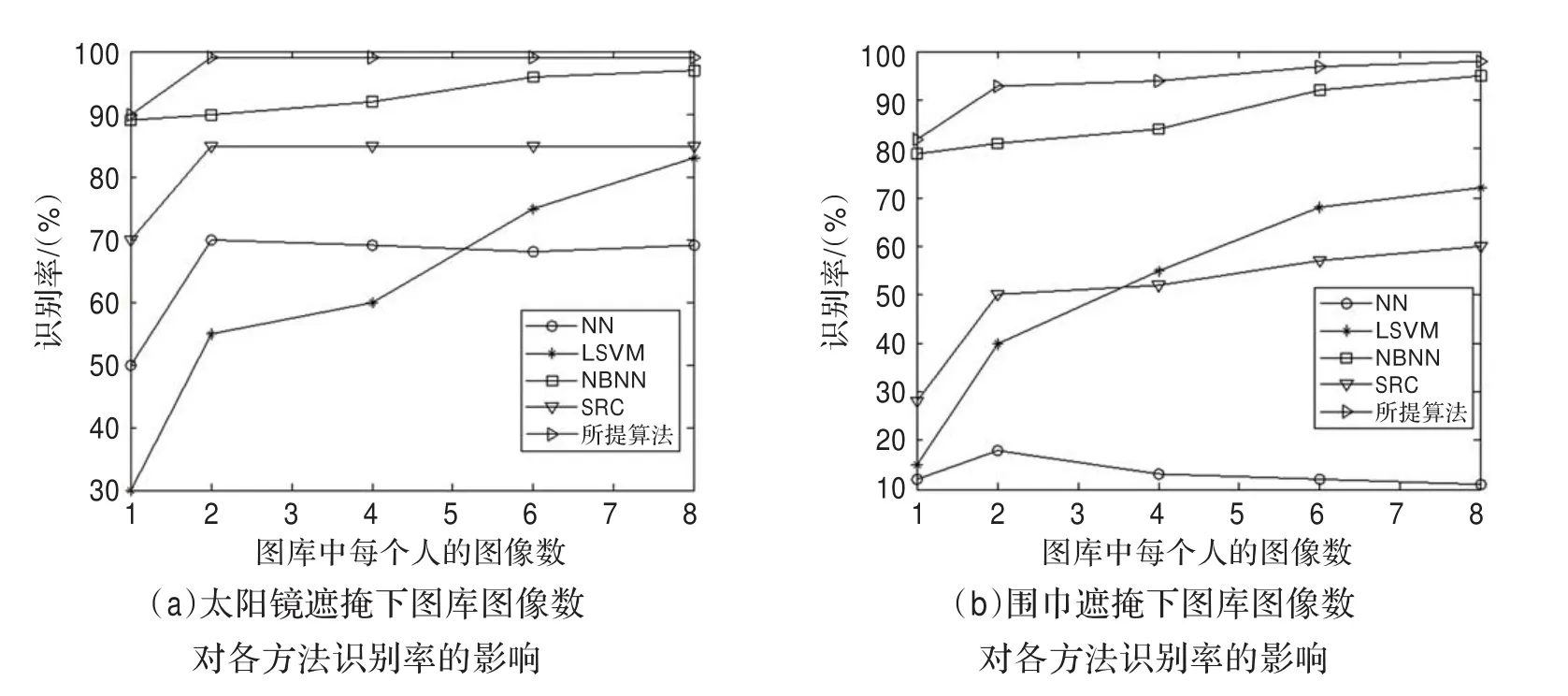
图6 AR数据库上的识别结果
在同样的实验设置下,还使用每人8幅图库图像对本文方法与较为先进的几种人脸识别方法进行了比较,所有方法仅使用灰度值特征,识别结果如表1所示,针对各个方法,自己作了实验,各方法的参数设置均参考各自所在文献。
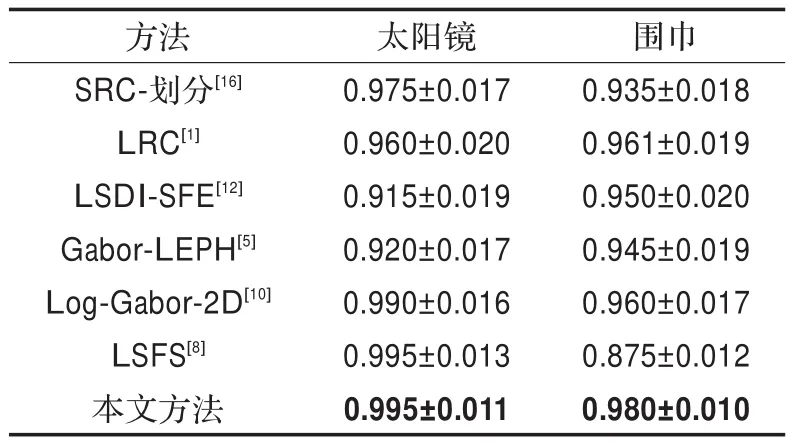
表1 AR数据库上每人有8幅图库图像的识别率
从表1可以看出,相比其他几种方法,本文方法能获得与这些方法相当甚至更好的识别率。而在识别效率上,本文方法的识别速率约为SRC方法的15倍。在围巾集这种几乎遮挡住一半人脸的数据集上,本文方法仅对2%的图像误分类,就目前所知,这是在围巾集上仅使用灰度值作为特征时得到的最好的结果。
表2中列出了各方法在平均精度、标准差、曲线下方面积(AUC)和等差率(EER)方面的数据。
从表2可以看出,在各个方法中,本文方法的平均精度最高,最低的标准差体现了本文方法识别性能的稳定性,曲线下方面积最大,等差率最小,表明本文方法更加优越。
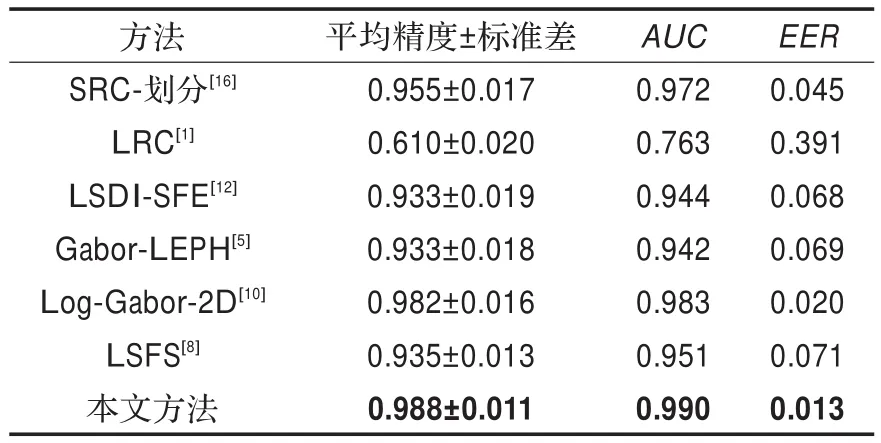
表2 各方法在AR人脸数据集上的识别结果(平均精度±标准差(std)、AUC和EER)
2.4 YouTube数据集
在YouTube数据集上,考虑到所有人脸图像都经固定的检测脸部关键点对齐过,所以将从一个视频剪辑所有帧中提取出的平均特征,图像均剪裁为80×60大小,本文方法的分块大小为5×5,并将本文方法与其他几种较为先进的方法进行了比较,针对各个方法,自己作了实验,各方法的参数设置均参考各自所在文献,表3中列出了各方法在平均精度、标准差、曲线下方面积(AUC)和等差率(EER)方面的数据。
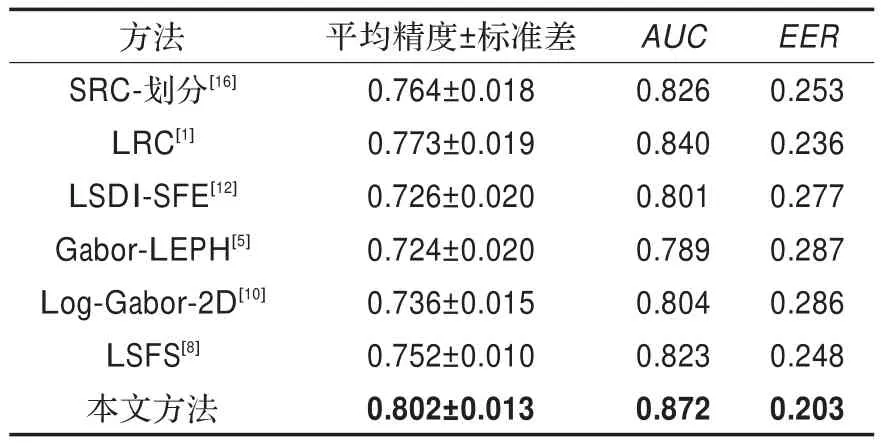
表3 各方法在YouTube人脸数据集上的识别结果(平均精度±标准差(std)、AUC和EER)
从表3可以看出,相比其他几种方法,本文方法在AUC和平均精度方面性能均为最高,且EER最低,再次验证了本文方法的优越性。
3 结论
该文提出了一种基于DTW优化局部分块匹配的人脸识别方法,在三个人脸数据库上的大量实验表明,本文方法能获得比其他方法更好的性能。在每个人仅有一幅图库图像可利用的极端情况下,本文方法仍能得到良好的执行效果。本文方法能直接处理原始数据,不需要任何训练过程,这些优点使其更适用于现实场景。
所提模型非常灵活,可采用如LBP和Gabor之类的其他图像描述符,未来会将所提模型与更复杂的特征提取算法结合,进行大量的实验,进一步提高人脸识别率。
[1]张楠.低秩鉴别分析与回归分类方法研究[D].南京:南京理工大学,2012.
[2]陈长军,詹永照,文传军.支持向量描述鉴别分析及在人脸识别中的应用[J].计算机应用研究,2010,27(2):488-490.
[3]Huang G B,Mattar M,Berg T,et al.Labeled faces in the wild:a database for studying face recognition in unconstrained environments[C]//Workshop on Faces in'Real-Life' Images:Detection,Alignment,and Recognition,2008.
[4]王宪,张彦,慕鑫,等.基于改进的LBP人脸识别算法[J].光电工程,2012,39(7):109-114.
[5]赵海英,冯月萍.应用Gabor滤波器和局部边缘概率直方图的全局纹理方向性度量[J].光学精密工程,2010,18(7):1668-1674.
[6]皋军,孙长银,王士同.具有模糊聚类功能的双向二维无监督特征提取方法[J].自动化学报,2012,38(4):549-562.
[7]杨利平,叶洪伟.人脸识别的相对梯度方向边缘幅值模式[J].光学精密工程,2013,21(4):1101-1109.
[8]Cox D,Pinto N.Beyond simple features:a large-scale feature search approach to unconstrained face recognition[C]// 2011 IEEE International Conference on Automatic Face& Gesture Recognition and Workshops(FG 2011),2011:8-15.
[9]杨传振,朱玉全,陈耿.一种基于粗糙集属性约简的多分类器集成方法[J].计算机应用研究,2012,29(5):1648-1650.
[10]黄荣兵,郎方年,施展.基于Log-Gabor小波和二维半监督判别分析的人脸图像检索[J].计算机应用研究,2012,29(1):393-396.
[11]Guillaumin M,Verbeek J,Schmid C.Is that you?Metric learning approaches for face identification[C]//2009 IEEE 12th International Conference on Computer Vision,2009:498-505.
[12]高全学,谢德燕,徐辉,等.融合局部结构和差异信息的监督特征提取算法[J].自动化学报,2010,36(8):1107-1114.
[13]Yin Q,Tang X,Sun J.An associate-predict model for face recognition[C]//2011 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2011:497-504.
[14]周旭东,陈晓红,陈松灿.半配对半监督场景下的低分辨率人脸识别[J].计算机研究与发展,2012,49(11):2328-2333.
[15]刘广征.基于视频与文本信息的说话者人脸标注[D].哈尔滨:哈尔滨工业大学,2010.
[16]杨荣根,任明武,杨静宇.基于稀疏表示的人脸识别方法[J].计算机科学,2010,37(9):267-269.
XU Yi
Department of Information Engineering,Hunan Industry Polytechnic,Changsha 410208,China
Large variation of pose,illustration,expression and occlusion in truly face recognition will seriously impact recognition performance,for which Local Partition Matching(LPM)algorithm optimized by Dynamic Time Warping(DTW)is proposed.Face image is divided into many non-overlapping patches with same size.All patches are combined to be a unique sequence sorting by forehead,eyes,nose,mouth and chin by using raster scan sequence.Distance from image to class between query face and register faces is calculated,and idea of DTW is used to find the best alignment between query sequence and all register sequences.The effectiveness and reliability of proposed method have been verified by experiments on the three common databases LFW,AR and YouTube.Experimental results show that proposed method has higher recognition accuracy than several advanced face recognition methods.Besides,it has lower cost without any training process.
face recognition;dynamic time warping;local partitioned matching;query face;probe image
A
TP391
10.3778/j.issn.1002-8331.1310-0293
XU Yi.Local partition matching optimized by DTW for face recognition.Computer Engineering and Applications, 2014,50(6):165-170.
徐屹(1980—),男,讲师,主要研究领域为智能控制、模式识别。
2013-10-23
2013-12-13
1002-8331(2014)06-0165-06
猜你喜欢
民族文汇(2022年24期)2022-06-09
美与时代·美术学刊(2022年3期)2022-04-27
计算机工程(2020年3期)2020-03-19
中国化工贸易·下旬刊(2019年5期)2019-10-21
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
中国公共安全(2017年7期)2017-10-13
摄影之友(影像视觉)(2017年1期)2017-07-18
佛山陶瓷(2016年11期)2016-12-23
大观(2016年9期)2016-11-16
