
大数据分区管理模型及其应用研究
2014-06-15 17:01张文燚项连志王小芳
哈尔滨工程大学学报 2014年3期
张文燚,项连志,王小芳
(1.哈尔滨工程大学电子政务建模仿真国家工程实验室,北京100037;2.哈尔滨工程大学 计算机科学与技术学院,黑龙江哈尔滨150001)
大数据分区管理模型及其应用研究
张文燚1,项连志2,王小芳1
(1.哈尔滨工程大学电子政务建模仿真国家工程实验室,北京100037;2.哈尔滨工程大学 计算机科学与技术学院,黑龙江哈尔滨150001)
针对大数据分区管理技术缺乏普遍适用的形式化数据分区模型的问题,引入一个包含痕迹代数系统、结构化状态关系代数系统、多结构化状态关系代数系统的大数据范畴,作为支持大数据分区管理及其相关应用研究的基础理论模型;在此基础上,给出了以满足“本地充足”为目标的,由基于活动场景和实体实例标识的大数据切片规则,以及面向活动场景的切片分配规则构成的,支持大数据分区管理和快速查询响应的形式化数据分区模型TSEI-PS。TSEI-PS已经在住房和城乡建设部的信息资源统一规划和国家住房信息系统建设中得到了应用。
大数据;形式化数据分区;本地充足;痕迹代数;结构化状态关系代数;多结构化状态关系代数;范畴
分区管理技术是大数据应用的基础性技术。与小数据所采用的记录事物属性的样本数据模式不同,大数据采用全面记录场景活动的全体数据模式[1]。大数据呈现出大量、多样、生成快速的明显特征[2]。大数据应用对于分区管理、分类认知和高速处理的计算技术有强烈的需求。普遍适用的大数据分区管理模型,对大数据应用相关技术发展具有重要意义。
目前,已有的大数据应用研究主要集中在2个方面[3]:Shared Nothing架构下的大规模并行处理MPP技术和构建在分布式文件系统(GFS)上的MapReduce+Bigtable技术。
MPP依赖基于关系数据库的数据分区技术,主要的相关研究分别从冗余数据最少和检索成本最低2个方向展开。一方面是以寻求综合检索成本最低的数据分区策略为目标的研究。1983年,Sacca D等证明,基于关系数据库的数据分区问题是一个NP难问题[4]。1990年,Shahram等通过分析查询的资源需求、系统处理能力、增加额外节点用于执行查询的成本和搜索范围表的成本,给出了一种为每个查询求得合适并行度的实用分区策略HRPS[5]。该策略先测算出使查询响应时间最小化的每个数据分区的元组数,再依据该元组数用Range方法形成数据切片,最后使用round-robin方法将这些切片顺序地分配到处理节点上。2010年,Carlo等关于事务工作负载驱动的数据分区方法的研究最终证明,使得分布处理事务数量最小的数据分区问题也是NP难问题[6]。另一方面,E.Wong等在1983年就指出,由于操作频率不易获取和不稳定、成本函数不易预估,以及成本最小化策略不易获取等因素,以检索和更新操作成本最低为目标的数据分区问题研究并不是特别有用[7]。E.Wong等认为高度并行化是操作高效性的基础,而本地数据资源充足和最小冗余是高度并行化中令人满意的性质,因此建议,数据分区应以检索和更新操作的快速查询响应(高效性)为目标,从满足查询的本地数据资源充足和分区管理的数据资源最小冗余出发,研究关系数据库的分区问题。E.Wong等给出了把数据库语义模式图作为可划分森林,通过划分森林中每一棵树的根节点,诱导出其他非根节点划分的数据分区策略。但是,E.Wong等并没有给出一个普适性的支持本地充足和最小冗余的数据分区模型,从而限制了这种数据分区策略的推广应用。
Fay Chang等以支持分区数据快速查询响应为目标,在2006年提出了构建在分布式文件系统之上的多维有序数据映射模型[8],该模型通过引入未经解释的字节数组和由行键、列键、时间戳构成的三维索引,给出了一种按行键字典序组织数据、以多个邻行(tablet)为逻辑管理单元和组成tablet的(多个)SSTable为物理存储单元的,统一支持面向结构化、半结构化和非结构化数据的,数据分区管理和分布查询策略。基于多维有序数据映射模型实现的Bigtable,借助MapReduce技术[9]实现对tablets的并行处理和结果返回,借助分布式文件系统(GFS[10])支持数据及日志文件的分布式高效存取和集群式高可用性,从而形成了一个面向大数据处理的相对完整的技术架构。但是,多维有序数据映射模型没有给出确定tablet和SSTable形式化规则,相应的技术体系架构缺乏完备一致的理论支持。
显然,以支持分区数据快速查询响应为目标的大数据分区技术研究具有重要的现实意义,统一支持结构化、半结构化、非结构化和多结构化数据分区管理和快速查询响应的形式化数据分区模型,在大数据分区技术研究中处于基础地位。本文在将大数据还原为场景活动痕迹的基础上,构造一个包含痕迹代数系统、结构化状态关系代数系统、多结构化状态关系代数系统的大数据范畴,作为支持大数据分区管理及其相关应用研究的基础理论模型。
1 刻画场景活动的痕迹代数
John H.Holland在复杂适应系统(complex adaptive system,CAS)相关的研究中,给出了一个由适应性主体和环境构成的场景活动模型,用于表达复杂的自然系统或社会系统活动。场景活动的过程形式是:适应主体的基本交互方式为通过探测器感知环境变化形成刺激消息,驱动内部规则执行行为决策过程,最终产生效应消息激活效应器,驱动主体行为落实[11]。这使得我们可以把全面记录场景活动的大数据等同于CAS场景活动消息集。
注意到CAS系统中的适应主体和环境对象均可视为实体存在实例,任何实体实例都可以是系统观察者,于是本文称系统观察者产生的与实体实例关联的状态变化为实体实例消息,称观察者为实体实例消息的宿主,且任意实体实例消息中都包含有实体实例的唯一标识。
1.1 实体实例消息的定义
定义1(有限符号分类集合空间SQ) 给定一个有限符号分类集合空间SQ={S1,S2,…,Sn},其中Si为符号集合。
序列化的符号集是描述信息的基本单元,称之为项,如2013-07-25,这是一个由数字和符号组成的序列。
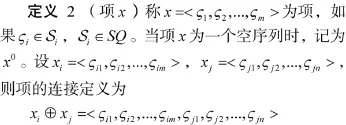
定义3(消息m(o)) 称形如m(o)=(id,l,o,的四元组为消息,其中id代表消息编号,l代表消息的出生地,o代表产生消息的宿主,x~=(X,f)为扩展项,代表消息的内容,其中:
扩展项存在3种情况:
定义4(实体实例消息me(o))称形如me(o)=为实体实例的消息,其中代表实体实例标识,其中I= <i1,i2,… >为名称项脚标序列,m(o)为消息。
当实体实例为适应主体时,实体实例消息可能包括主体内部活动消息。
1.2 活动痕迹与场景
基于实体实例消息,可以形式化地定义活动场景及其痕迹。
约定:x·y代表y是x的一个分量。
定义5(活动痕迹st) 称st=(t,Me(O))为活动痕迹,其中t是实体实例消息的产生时刻,Me(O)=是t时刻所有宿主产生的实体实例消息集合,O代表宿主集合,IDj代表消息编号集合,ID为消息编号全集。
当实体实例为适应主体时,活动痕迹可能包括主体内部活动痕迹。
定义6(场景sT) 称sT={st1,st2,…|t1,t2,…∈T}为场景。显然每个时刻的活动痕迹为当前时刻场景与上一刻场景之间的变化,即sti=sTi-sTi-1,其中Ti=Ti-1∪{ti}。
主体内部活动痕迹构成内部场景,其他活动痕迹构成外部场景,本文将内部场景和外部场景视为统一场景。
1.3 痕迹代数
注意到CAS中用一个(可标识的)效应器组合来描述主体的活动,其过程是:先由环境通过一组感应器将(认知)信息以消息的形式传递给主体,一旦被(条件)合适的消息所激活,效应器将(按规则)对环境中的具体(锁定)部分落实具体行为[11]。其中,一个隐含的事实是,锁定就意味着行为必然落实。
本文把CAS中的主体活动表达为场景中的痕迹(消息)运算组合,进而可以把CAS表达为一个痕迹代数系统。这使得我们可以用痕迹代数系统表达复杂的自然系统或社会系统,从而真实完整地记录自然系统或社会系统运行和演化过程的原始痕迹。
定义7(主体a) 称形如a=(tag,P,R,L,B)的五元组为主体,其中:
1)tag代表标识,标识是 n元项 tag={tag1,tag2,…,tagn},其中tagi是项,本文称之为标识项。
4)称形如ℓ=(fℓ,L)的二元组为锁定ℓ,其中fℓ∈F为被锁定对象的消息结构,F为结构集合,L={αk,k=1,2,…}为被锁定的名称项集合。 记所有锁定ℓ的集合为L。
5)称形如b=(fb,Δ)的二元组为行为落实b,其中fb∈F为行为落实对象的消息结构,F为结构集合,为行为落实对象的状态变化,变化后所达到的值项和编码。记所有行为落实b的集合为B。
定义8(认知运算opp) 设sT为场景,st∈sT为活动痕迹,opp为sT上的一元运算,p=(fp,c^),认知运算定义如下:
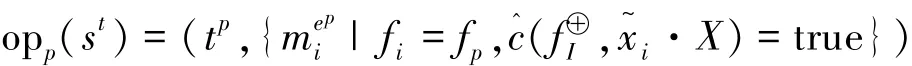
其中:
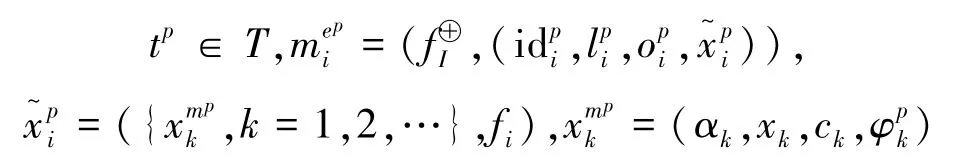
定义9(规则运算opr) 设sT为场景,给定任意st1,st2∈sT为活动痕迹,opr为sT上的二元运算,,规则运算定义如下:
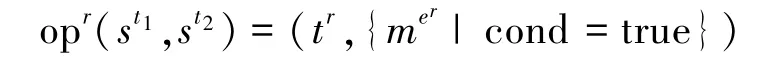
其中:
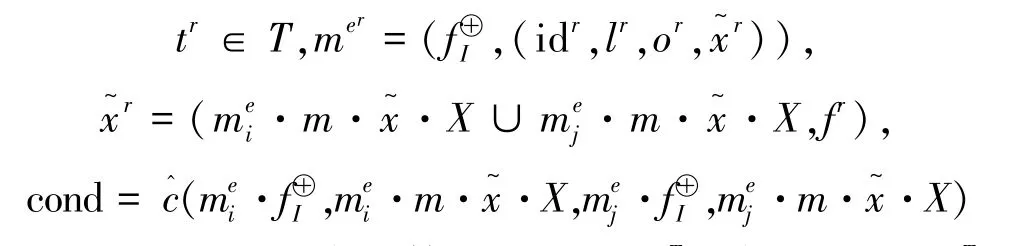
定义10(锁定运算opℓ) 设sT为场景,st∈sT为活动痕迹,opℓ为sT上的一元运算,ℓ=(fℓ,L),锁定运算定义如下:
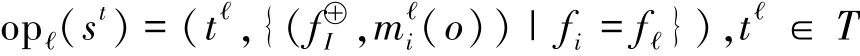
其中:
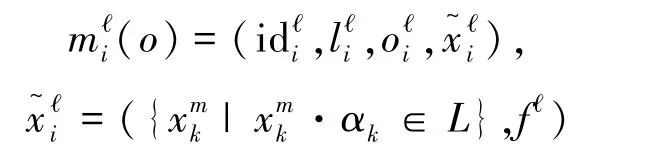
定义11(行为落实运算opb) 设sT为场景,st∈sT为活动痕迹,opb为 sT上的一元运算,b=,行为落实运算定为
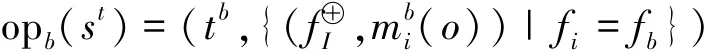
其中:
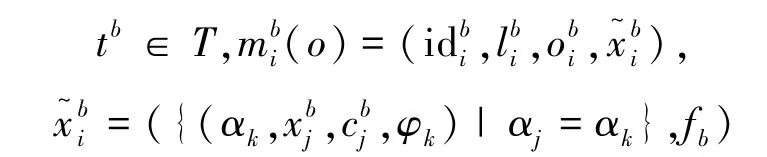
定理1(痕迹代数) 设sT为场景,则S=<sT,opp,opr,opℓ,opb>是一个代数,本文称之为痕迹代数。
证:显然,opp,opr,opℓ,opb为sT上的运算,则S是痕迹代数。
2 状态关系代数
上节中,大数据是以原始痕迹记录的形式存在的,这种形式能够充分完整地表达大数据所包含的语义,但不方便对大数据进行管理。本节通过在关系代数[12]上引入时间元素表达属性状态,扩展构造状态关系代数,以支持建立大数据管理形式化模型。
2.1 结构化状态关系代数
定义12(结构化状态关系Rt) 称形如Rt=的集合为结构化状态关系,其中idk为结构化状态关系元组标识,为结构化状态关系元组的诞生时刻,为结构化状态关系元组的记录时刻,τk={(Ai,vki),i=1,2,…}是结构化状态关系元组,Ai为属性名,vki为属性值,与的消息扩展项中的αi和xi相对应。 记attr(Rt)={Ai,i=1,2,…}为结构化状态关系属性集。
注释idk可以是由一组属性值按指定顺序连接而成,即,其中I=< i1,i2,… > 为属性脚标序列。
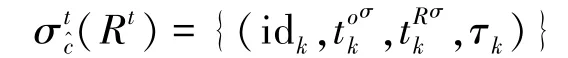
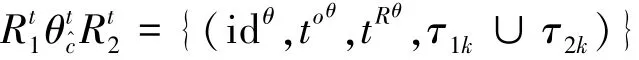
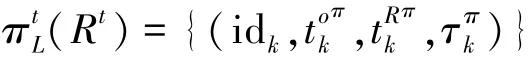
定理2 设 Ωt为结构化状态关系集合,则为一个代数,本文称之为结
2.2 多结构化状态关系代数
结构化状态关系代数充分表达了大数据中的结构化数据,但未能支持半结构化和非结构化数据的表达。本节通过引入符号序列组成的项表达多种结构,改造结构化状态关系,以支持建立结构化、半结构化和非结构化的多结构化数据管理形式化模型。
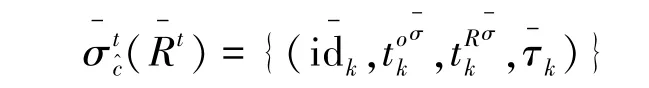
定理3 设Ωt为多结构化状态关系的集合,则是一个代数,本文称之为多结构化状态关系代数。
3 大数据范畴
本文将以痕迹代数系统S,结构化状态关系代数系统Ω和多结构化状态关系代数系统三个对象,以及从S到Ω的态射g:S→Ω,从S到的态射和从Ω到的态射h:建立大数据范畴。阅读本节内容需要了解相关的代数和范畴的基础理论知识,未说明的相关概念和理论请参考文献[13-15]。
定理4(大数据范畴C) C由以下内容组成(见图1):

那么C为范畴[15],称之为大数据范畴。
证明略。
定理5 设C为大数据范畴,对于对象S和Ω,态射g:S→Ω,有:
1)对任意ξ={st|st∈sT,me∈st,me·m·id∈IDq},,必然存在,使得
2)对任意ξ={st|st∈sT,me∈st,me·m·id∈ID1∪ID2},,必然存在使得
3)对任意ξ={st|st∈sT,me∈st,me·m·id∈ IDq},ℓ = (fℓ,Lℓ),必然存在,使得
证明略。
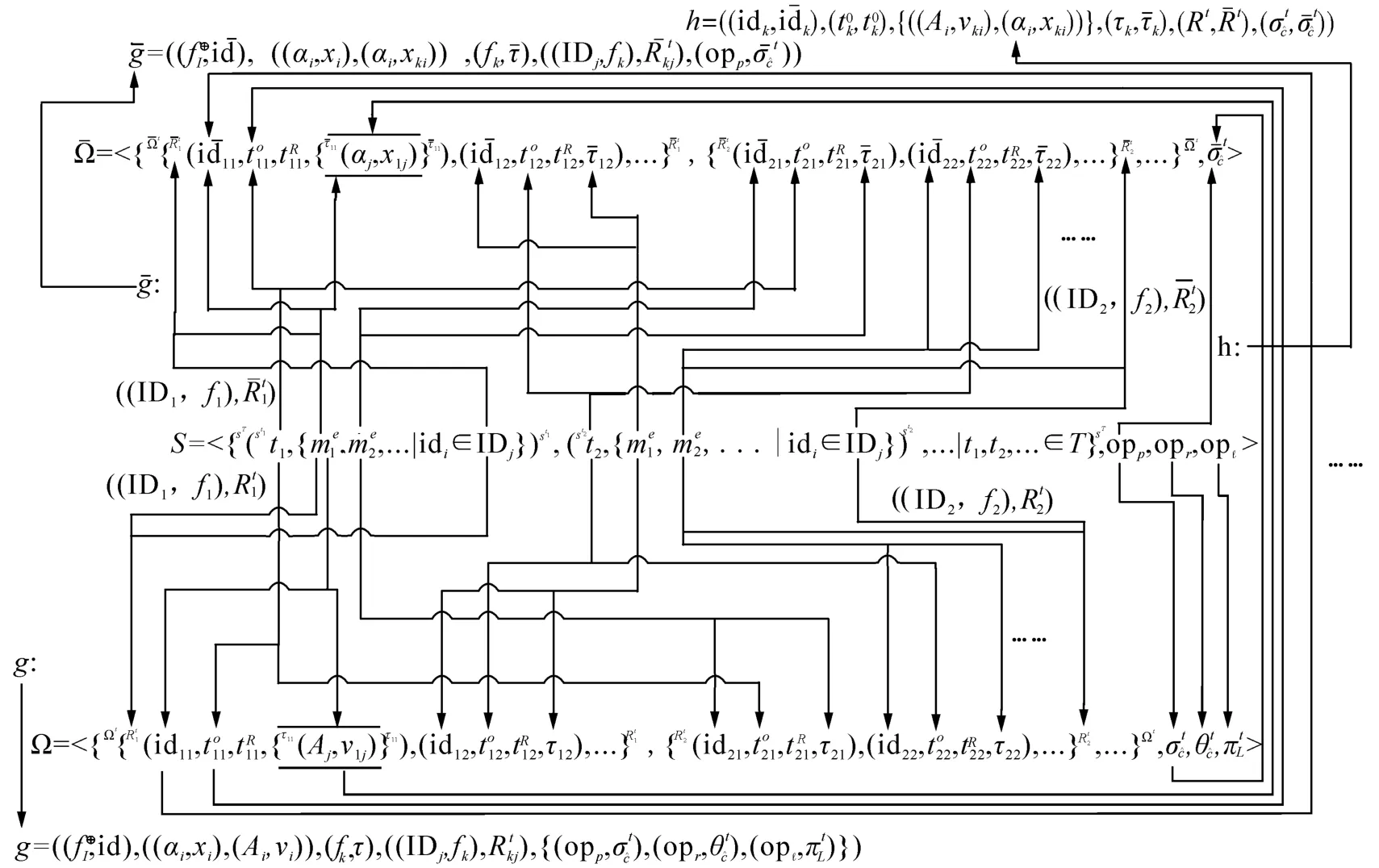
图1 大数据范畴态射图Fig.1 Big data category morphism figure
上述定理证明了痕迹代数中的认知、规则、锁定与状态关系代数中的约束、关联、投影的运算可保持性,说明了认知、规则、锁定构成的运算模式可态射为结构化状态关系中的约束、关联、投影构成的运算模式。尽管痕迹代数的行为落实运算没有与状态关系保持运算,但锁定意味着行为必然落实,说明了在发生锁定时,场景中必然会存在行为落实运算的结果,因此,行为落实运算对于其他3个运算并无影响。
对任意ξ= {st|st∈sT,me∈st,me·m·id∈,必然存在使得
证明略。
证明略。
痕迹代数到结构化状态关系代数,痕迹代数到多结构化状态关系代数,以及结构化状态关系代数到多结构化状态关系代数的态射的运算可保持性,说明了痕迹代数与状态关系代数的数据域是可对应的,即痕迹代数中的实体实例消息可对应到状态关系中的元组。
4 数据分区管理
注意到对于单变量类的语义查询,横向数据分区总是能够满足本地充足的要求[7],故假设每个结构化/多结构化状态关系都进行横向划分。则接下来的问题是在结构化/多结构化状态关系数据库上如何实施数据横向分区:本文采取基于实体实例标识和场景的数据切片规则,和面向实际场景的切片分配规则,即对于给定的子场景集合,首先确定结构化/多结构化状态关系中每一个结构化/多结构化状态关系元组对应的实体实例消息,及实体实例消息的实体实例标识和所在子场景,然后基于场景和实体实例标识进行两级数据划分形成数据切片;按子场景将切片汇聚成切片集合,并分配到处理节点上,本文称这种方法为TSEI-PS(trace-scene and entityinstance based partitioning strategy)。
4.1 结构化状态关系形式化数据分区模型
设结构化状态关系Rt的集合为Ωt,其对应的场景活动痕迹st的集合为sT,即g(sT)=Ωt,由态射g:S→Ω的定义可知,对Rt中任意的元组τk,存在实体实例消息({(αi,xi,ci)},f))),使得g me·m( )=τk。
记 Lj= {lj1,lj2,…,ljnj}为实体实例消息的出生地的集合,j=1,2,…,m,k= 1,2,…,nj。所有实体实例消息me(o)出生地的集合记为L L。
对于任意实体实例消息me∈sT,若me·m·l∈ Lj,则
定义19 称 PP1j是结构化状态关系Rt基于子场景的一个数据切片,如果满足以下条件:
定义20 给定结构化状态关系Rt,和基于结构化状态关系元组标识的约束条件,称是 Rt关于的一个数据切片。
对任意结构化状态关系Rt,给定子场景1,2,…,m,基于实体实例标识的约束条件1,2,…,n,且,那么Rt的数据切片规则为:
对于任意结构化状态关系Rt,给定由上述切片规则生成的数据切片集合,j=1,2,…,m,i=1,2,…,n,和与场景对应的处理节点j,j=1,2,…,m,令,则有序对为面向子场景的一个分配,那么切片集合 PP1⊗2面向子场景,j=1,2,…,m的切片分配规则为
4.2 多结构化状态关系形式化数据分区模型
与结构化状态关系数据分区类似,多结构化状态关系同样采用基于场景和实体实例标识的切片规则,以及面向场景的切片分配规则。类似地可以给出多结构化状态关系的数据切片规则和切片分配规则。
下面对结构化/多结构化状态关系数据分区是否满足本地充足的问题进行讨论。E.Wong定义数据分区(物化)M的本地充足是指处理给定的语义查询类Q中的每一个查询都无需在处理节点之间移动数据[7]。自然语义查询是场景中用户为完成活动目标,在状态关系数据库上发起的数据访问操作,则该自然语义查询类等价于场景活动,而每一个结构化/多结构化状态关系分区是按场景汇聚的,显然自然语义查询所涉及的数据资源包含在结构化/多结构化状态关系分区之内,那么结构化/多结构化状态关系分区关于自然语义查询类是本地充足的。另外,由于存储等硬件设施的快速发展,实际应用技术对数据冗余的约束不强,故本文忽略该因素。
5 应用
作为TSEI-PS的应用描述,本节简要讨论文献[7]中对于给定的语义查询类,如何划分“公司”数据库使其满足本地充足的数据分区问题。“公司”状态关系数据库包含雇员(emp),部门(dept),工作(job),授权(qualified)和经理(mgr)等结构化状态关系,具体描述如下:

其中:
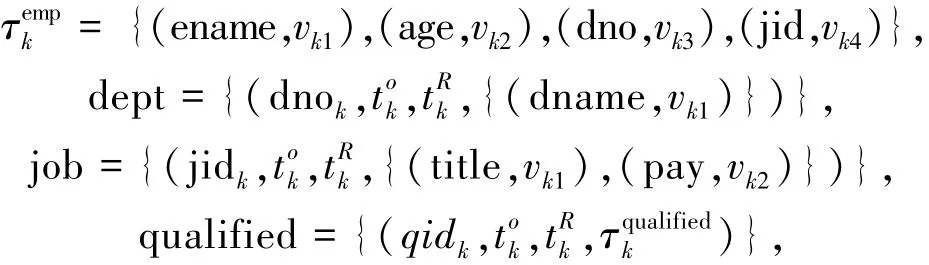
其中:
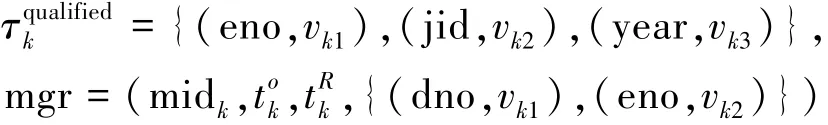
设该结构化状态关系数据库对应的场景sT为一个带有分公司的全国性公司,分布在全国m个城市,与结构化状态关系元组对应的实体实例消息可描述如下:
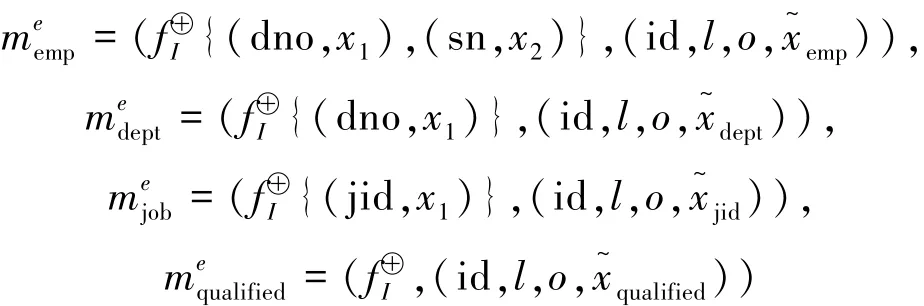
其中:

对于给定的m个与城市场景对应的处理节点j,j=1,2,…,m,则雇员的切片分配规则为,其中,为面向城市j场景的切片集合,并被分配到节点j上。
其余结构化状态关系的数据分区方法与雇员的类似,这里不再重复论述。显然,数据分区关于单变量的语义查询是本地充足的。此外,一个城市场景中的雇员(emp),部门(dept),工作(job),授权(qualified)和经理(mgr)等结构化状态关系均分布在相同的城市场景处理节点上,因此对作用于结构化状态关系雇员与部门、雇员与经理、部门与经理,及经理与雇员之上的关联操作都是在同一个城市的状态关系分区上进行的。因此全国性公司形成的数据分区关于自然语义查询是本地充足的。
6 结论
首先,本文基于对 CAS场景活动痕迹的刻画,以及对经典关系代数系统的扩展和改造,建立了由痕迹代数系统S,结构化状态关系代数系统Ω和多结构化状态关系代数Ω三个对象,以及从S到Ω的态射g:S→Ω,从S到Ω的态射g-:S→Ω和从Ω到Ω的态射h:Ω→Ω构成的大数据范畴,作为支持大数据分区管理及其相关应用研究的基础理论模型。其次,本文给出了以满足“本地充足”为目标的,基于活动场景和实体实例标识的大数据切片规则的形式化表达,以及面向活动场景的切片分配规则的形式化表达,并由此形成了一种支持大数据分区管理和快速查询响应的形式化数据分区模型 TSEI-PS。最后,本文把TSEI-PS应用于文献[7]提出的基于语义模型的数据分区讨论,有效地降低了数据分区讨论的复杂度,并且使数据分区讨论更具有形式一般性和普适可操作性。
[1]维克托·迈尔-舍恩伯格,肯尼思·库克.大数据时代——生活、工作与思维的大变革[M].杭州:浙江人民出版社,2012:30-37.
[2]DUMBILL E.Planning for big data[M].Sebastopol:O’Reilly Media,Inc.,2012:9-16.
[3]MADDEN S.From databases to big data[J].IEEE Internet Computing,2012,16(3):4-6.
[4]SACCA D,WIEDERHOLD G.Database partitioning in a cluster of processors[J].VLDB,1983:242-247.
[5]GHANDEHARIZADEH S,DEWITT D J.Hybrid-range partitioning strategy:a new declustering strategy for multiprocessor database machines[C]//Proceedings of the 16th International Conference on Very Large Data Bases.San Francisco:Morgan Kaufmann Publishers Inc.,1990:481-492.
[6]CURINO C,JONES E,ZHANG Y,et al.Schism:a workload-driven approach to database replication and partitioning[J].VLDB Endowment,2010,3(1/2):48-57.
[7]WONG E,KATZ R H.Distributing a database for parallelism[J].ACM SIGMOD Record,1983,13(4):23-29.
[8]CHANG F,JEFFREY D,GHEMAWAT S,et al.Bigtable:a distributed structured data storage system[C]//7th OSDI.Berkeley:USENIX Association,2006:305-314.
[9]DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[10]GHEMAWAT S,GOBIOFF H,LEUNG S T.The Google file system[J].ACM SIGOPS Operating Systems Review,2003,37(5):29-43.
[11]约翰·H·霍兰.隐秩序——适应性造就复杂性[M].上海:上海科技教育出版社,2000.
[12]CODD E F.A relational model of data for large shared data banks[J].Communications of the ACM,1970,13(6):377-387.
[13]贺伟.范畴论[M].北京:科学出版社,2006:1-22.
[14]ASPERTI A,LONGO G.Categories,types,and structures[M].Cambridge:MIT Press,1991:1-9.
[15]AWODEY S.Category theory[M].2nd ed.New York:Oxford University Press,2010:1-28.
Big data partition management model and its application research
ZHANG Wenyi1,XIANG Lianzhi2,WANG Xiaofang1
(1.Modeling and Emulation in E-government National Engineering Laboratory,Harbin Engineering University,Beijing 100037,China;2.College of Computer Science and Technology,Harbin Engineering University,Harbin 150001,China)
Because of the big data partition management technique's lack of a universally applicable formalized data partition model,this paper introduces a big data category that contains a trace algebra system,structural state relational algebra system and multi-structural state relational algebra system,as the basic theoretical model for supporting partition management and its application research.On this basis,this paper details a formalized data partition model known as trace-scene and entity-instance based partitioning strategy(TESI-PS)that supports big data partition management and rapid query response,with the goal of meeting"local sufficiency".It is made up of the big data partitioning rules based on the activity-scenes and the identification of entity instances and the activity-scene-oriented partition allocating rules.So far,TSEI-PS has achieved success with unified information resource planning and national housing information system construction of the Ministry of Housing and Urban-Rural Development.
big data;formalized data partition;local sufficiency;trace algebra;structural state relational algebra;multi-structural state relational algebra;category
10.3969/j.issn.1006-7043.201312105
TP311.5
A
1006-7043(2014)03-0353-08
http://www.cnki.net/kcms/doi/10.3969/j.issn.10067043.201312105.html
2013-12-30. 网络出版时间:2014-3-21 14:11:50
张文燚(1968-),男,教授,博士生导师;项连志(1983-),男,讲师,博士研究生.
项连志,E-mail:xlz_work@126.com.
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19
河北理科教学研究(2021年4期)2021-04-19
数学年刊A辑(中文版)(2021年4期)2021-02-12
科学(2020年1期)2020-08-24
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
小猕猴智力画刊(2019年3期)2019-04-19
文苑(2018年18期)2018-11-08
应用数学与计算数学学报(2015年1期)2015-07-20
华东理工大学学报(自然科学版)(2014年5期)2014-02-27
