
现代助听器的降噪技术(单麦克风类)和性能(1)
2014-06-12 02:28张戌宝
听力学及言语疾病杂志 2014年5期
张戌宝
助听器技术面临的最大挑战之一是解决输出噪声问题。大多数听力受损者患有感音神经性听力损失,系外毛细胞功能受损所致[1],当听音环境存在噪声时,他们比听力正常者更加感到语音模糊,严重影响其对语意的理解。长期以来,助听器的这一噪声问题受到听力康复工作者的高度关注。助听器的降噪技术分两大类:单麦克风的频域处理和多麦克风的波束形成。在多数听音环境中,后者的降噪效果优于前者,但并不能代替前者,因此,主流助听器厂家一直在对助听器单麦克风降噪技术进行研究并付诸应用。Hamacher等[2]较早而又全面地提出了高档助听器中的多种降噪技术。Josef等[3]将瞬态降噪器、维纳(Wiener)滤波器和基于调制检测的平稳降噪器组合于一体,互补地降低多种不同环境的噪声。Francis等[4]提出了语音增强(speech enhancement,SE)技术,将噪声掩蔽和患者听力损失同时考虑以使语音的可听谱域最大化。Mark[5]提出了助听器听音环境中语音优先处理(voice-priority processing,VPP)的哲理:语音存在时,增加理解度,语音不存在时,确保听音舒适,其中的三态噪声管理使降噪技术上了一个台阶。Phonak[6]介绍了助听器双侧无线连通(binaural wireless link)技术及其在非对称噪声环境中的性能改善。Ricketts等[7]对组合的数字降噪在助听器中的性能进行了评估,表明该DNR对语音识别没有明显改善,但可改进声音的舒适度。Elberling[8]较详细地介绍了在三态噪声管理系统中使用的语音寻找器(voice finder)的语音检测原理和效果。Ruth等[9]较全面地总结了当前各种降噪算法的理念并对比它们在实际环境中的性能。Nicole等[10]评估了众多试听者使用的助听器在聚会噪声中的降噪性能,涉及多种因数的相互作用,如听力损失、助听器类型、混响特性和选择的听音目标。Anastasios等[11]提出了一种评估助听器降噪性能的新方法,对语音的复述响应作记录和对完成指定的视频操作计时,根据这两组数据进行客观评估。基于当代助听器领域出现的这些顶尖成就,本文将有关降噪的单麦克风类的最先进技术进行分类综述和性能评估。
1 组合的数字降噪技术
已有的多种数字降噪(digital noise reduction,DNR)技术各有长处和短处,瞬态降噪器对付极窄的非平稳强噪声(或加语音)极为有效,基于调制检测的多频道DNR对于平稳噪声最为有效,而维纳滤波可与混叠的语音谱加噪声谱匹配,它们是一些特性大为不同的DNR,如果将他们结合起来并行处理,则可在多种较为复杂的噪声环境中互补,实现整体最佳听音的目标。
1.1瞬态降噪器 多数DNR常常采用慢响应的增益下降,对瞬态噪声是无效的。瞬态噪声的时间区间小于数十毫秒,对处理的时间分辨率要求极高,小于1 ms,足以对瞬态噪声有可靠的反应。计算输入信号的包络峰值和长期均方根值,若它们的比值(称作斜率)大于语音包络的斜率(作为检测门限),就判定该输入信号为瞬态噪声。根据瞬态噪声包络斜率的大小决定放大器的增益下降量;瞬态噪声的包络斜率可分为三个等级,相应的增益下降量也有三个等级,在20~40 dB之间,斜率越大,下降量越大;不同频道的增益下降量可能不一样。当输入信号包络的斜率低于检测门限时,就判定输入信号为非瞬态噪声或瞬态噪声不存在,增益下降量为零。这种信号可能含有很轻的瞬态噪声,仍然可听见但不是烦人的。瞬态降噪器仅仅降低含有瞬态噪声的那些频道的增益,这样处理能保留更多的语音提示信息。在最后的处理级,各频道的输出信号被重新合成,如语音存在则使输出的语音失真降至最低,Josef称这样的技术为声音平滑处理(sound smoothing)[3]。

图1 声音平滑器对碟子声信号处理前后的波形
图1上图显示碟子发出的咯咯声波形,它记录了许多瞬态噪声,被试听者称为最烦人的噪声;图1下图显示该碟子声经声音平滑器处理后的输出波形,这些输出峰值下降达40 dB,得到的声音烦人感很弱。这种声音平滑技术在现代助听器中是一种响应最快的、应对瞬态噪声十分有效的降噪技术。
1.2维纳滤波器 助听器的环境噪声和语音在谱域上往往是混叠的,时域上往往是不平稳的。维纳滤波是自适应信号处理中常见的最佳滤波,它要求谱平稳的噪声和语音,但与两者是否混叠无关。为了应用于助听器中,应要求噪声和语音具有短期平稳的统计特性并且以噪声的最小均方误差为准则[9]。维纳滤波处理需借助调制检测器来确定噪声的存在性,在说话暂停时或语句的间隙估计噪声,在语音加噪声时减去这一估计噪声而保留原语音信号。显然,估计噪声的误差就是输出语音信号的误差。当信噪比(SNR)大于0 dB时,该算法较为稳健,复杂的实际环境中,准确估计噪声的平稳条件很难满足,维纳滤波的降噪性能往往不是最佳的。传统的谱相减法是用噪声谱的逆滤波器去过滤语音加噪声的信号,这是维纳滤波的特例,仅与噪声谱匹配。该法对语音的影响取决于噪声的谱宽,噪声谱越窄,对语音的影响越小,例如,蒸汽牛奶机的咝咝噪声中心频率约3.2 kHz,为窄带,如果所在频道的增益下降30 dB,则可以除掉该牛奶机噪声。这样的增益下降对整体语音信息损失很少,但若是宽带噪声则会降低语音可懂度。
1.3数字的平稳降噪器 语音信号和平稳噪声信号的调制包络特性不相同,即它们的调制指数和调制包络频率都相差较远。Ruth表明[9],语音的调制包络频率范围从0.1到40 Hz,大多数情况下约为数Hz,调制指数大于0.9,峰-峰值声压级大于30 dB。平稳噪声的调制包络频率范围较宽,但多数情况下接近0,少数大于数十Hz;噪声的峰-峰值声压级范围宽,从数dB到数十dB;语音加噪声的信号的调制指数、调制包络频率分别在语音和噪声的调制指数和调制包络频率之间。根据这些知识,分类信号的调制检测器的设计和判定规则应是:①设置一个调制包络频率门限,如1到10 Hz,此范围之外判定输入为噪声,反之亦反;②设置一个调制指数门限,如0.9,大于此值判定输入为语音,反之亦反。若此两个判定不一致,则要根据更多的记录或双侧助听器对侧的判定作进一步判定[2],也可判定为语音加噪声。噪声门限设置是一个棘手的问题,如果门限设置不当,则限制了可听度或者允许较多的噪声输出,还要指出的是,该判定需要在各频道上进行,且各频道的判定门限不尽相同。该调制检测器对平稳噪声的检测较为敏感而且准确,根据估计的噪声声级,分档降低所在频道的增益,如,6、12或18 dB。在实际中,它们还需要调整以满足用户的最佳舒适感。
调制检测器对语音加噪声的分类与信噪比(SNR)相关联,当语音低于噪声5~10 dB时,就判定该信号为噪声。语音在高频道的调制比低频道的弱,也有可能判定高频道的语音为噪声,而造成语音高频成分的损失。此外,降低增益要有足够长的时间特性,以确保语音的时域特性不失真。 该技术的启动时间约2.5秒,释放时间小于0.5秒。
2 数字助听器的语音增强技术
传统的降噪处理以噪声环境中语音的可听度和听音舒适作为目标。SE技术把宽带噪声中用户个人的语音理解度指数(speech intelligibility index,SII)最大化作为设计目标。Francis等[4]在助听器的频率声压曲线图中,加上患者的听力阈值曲线和噪声掩蔽曲线而得到可听语音的频谱区域,作为估计SII的基础。先假设助听器工作符合线性运算,且已知语音谱和噪声谱的声压曲线,则SII可通过下列代数求和式计算:
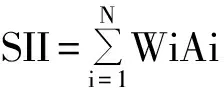
i=1, 2, …, N(N频道数)
Wi为频道i中的语音提示权重, Ai为频道i中的可听度。图2显示了一助听器的频率声压图,频道的划分未在图中显示,该助听器未使用SE技术,而用了均匀12 dB增益下降的多频道。实线代表个人的听力阈值,长虚线代表掩蔽噪声的声压,双点划线代表放大后的最低语音谱,即恰能听见的语音谱;短虚线代表放大后的最高语音谱,超过最低语音谱+30 dB的谱对语音理解没有更多的提示。在掩蔽噪声线和听力阈值线(更高的那段线)之上且在最高语音谱之下的谱域是可听语音谱域,用散点区域表示。在该区域,频道i中的语音声压差值为Ai。单纯根据输入噪声的声级来均匀地下降增益会造成患者的可听谱域减少,而导致SII降低;各频道不同的增益设置将形成不同的SII值。本处理策略不需对SII做归一化处理,SII越大,越多的语音成分可被试听者利用。最高SII对应的各频道增益是SE的最佳解值。该N维方程的最佳求解在运算中工作量极大,几乎不可能实时进行;为此,Francis还介绍了一种实时而可靠的SII比较算法,以使计算量降至最小。实际中,平均语音频谱随当前环境的语音谱而变化,与个人的语音音调和语声努力(vocal effort,言语者控制的声量)有关;因此,采集合格的、不断更新的语音样本和噪声样本要求非常高速的芯片处理器和精细的人工智能算法。SE利用语音噪声跟踪器(speech and noise tracer)来完成语音谱和噪声谱的估计,噪声谱用输入的信号来估计,语音谱则是在当前语音的平均声压谱上外推。该法对已知背景噪声的情况是适合的,逼近当前的噪声谱和语音谱,这样,SII优化的效果不可避免地要依赖听音环境的特性。
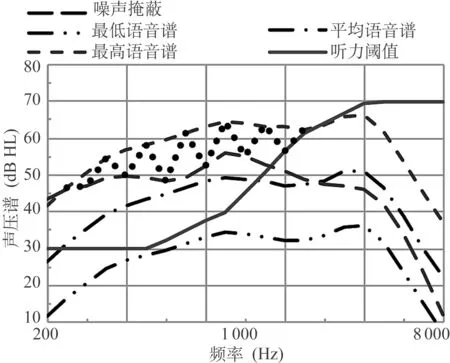
图2 采用均匀12 dB增益下降后的频率声压图
图3显示了与图2相同的条件下使用了SE后的频率声压曲线图,各条曲线的含义与图2中的相同,可以看出,在较高频率端(>2 kHz)的可听语音谱域甚大于图2均匀增益下降得到的。在噪声谱和助听器的初始(默认)增益的基础上,SE的增益控制取决于用户的听力阈值。初始增益是对多数听音环境的最佳选择,最佳增益下降量依赖于听力损失。通常,听力损失越大,SE的增益下降就越少;当输入是由噪声主控或SNR很差时,SE使用较大的增益下降,但最多12 dB;SE的增益也与噪声谱有关,噪声谱越宽,增益下降越多。增益的优化过程需要约20秒以适应新的噪声环境;但是当需要增加增益以提高SII时,SE可用快速处理来完成。显然,SE对瞬态噪声的抑制基本上没有作用。
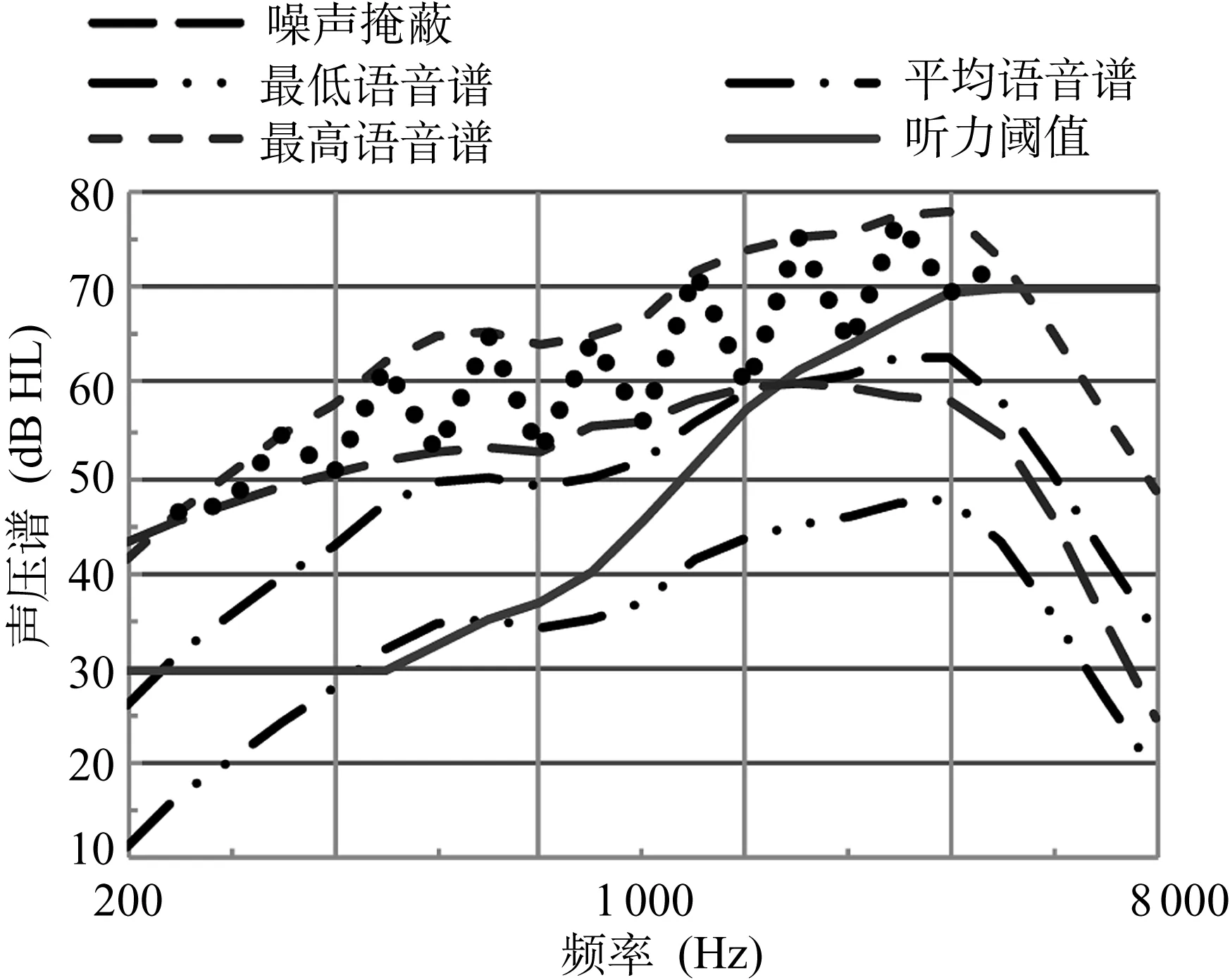
图3 与图2相同条件下使用语音增强器后的频率声压图
3 三态噪声管理技术
Mark[5]认为,听音环境的最佳噪声管理就是要精确检测语音的存在性和对不同特性的噪声给以不同的处理策略,任何算法事前都很难精确得知听音环境的具体状态而选用相应的最佳处理。为此,他将广泛的听音环境分为三种状态:①仅语音或语音加弱噪声;②语音加噪声;③仅噪声。应对这种分类环境的技术称为三态噪声管理(tristate noise management),它是VPP系统的一部分。VPP系统对实际的环境噪声同时使用三种不同的方向性麦克风极性图作并行处理,最后对它们的全部输出进行语噪比(voice-noise ratio,VNR)计算和比较,将最佳VNR对应的麦克风极性图作为最佳模型而选用,为三态噪声管理的稳健实现创造了条件 。
3.1三态噪声管理的策略 应对第一种环境状态:管理系统的放大提供足够的增益,确保对输入的宽动态语音理解更好;应对第二种环境状态:增益的下降量取决于调制指数和噪声声级,调制指数越高,而输入声级越弱,则增益下降越少。VNR范围在-3~-6 dB时,该系统仍能检测出语音[8],这时只降低低频和高频的增益,再将输出送至多频道压缩器,以产生清晰度指数(articulation index)尽可能高而又舒适的声音。应对第三种环境状态:当调制指数最低而噪声声级最强时,所在频道的增益下降取最大值以用户感到最舒适为目标;不过,随着调制指数升高和噪声声级减弱,增益下降需减少。与第二种环境状态相比,同样的调制指数和噪声声级下,该环境状态需更多的增益下降。这三种状态的处理是并行的且能快速转换,确保能跟上环境的变化。
语音环境的均衡处理是要使三态管理的状态控制按优先顺序进行:在复杂的听音环境中,语音信息的维护在先,听音舒适在后,因此, 同步检测的判定具有优先权:只要语音被检测到,三态管理系统就迅速进入“仅语音”或“语音加噪声”的状态中;反之,当调制检测器判断为“仅噪声”存在时,三态管理的目标才是用户的听音舒适。只要判定噪声存在,增益控制就启动,增益下降量可以分多个等级以接近最佳的语音理解度和舒适感。
3.2同步检测和调制检测的组合 三态噪声管理的挑战之一是要准确地知道听音环境的状态。调制检测器在仅噪声或仅语音存在时,其判断准确度和效率都高;但是,如果输入信号由语音加噪声构成时,特别是VNR低时,调制检测器难于分辨出语音的存在。因此,单纯地使用调制检测器来分类听音环境信号可能牺牲语音的可听范围。Mark指出,语音的能量分布在全部频道上,不同频道的能量模型紧密地与声带的周期活动合拍,即基频的倍频特性。此外,低、中频道间的语音波形相关性较强。一组带宽较宽(如一个倍频程)的滤波器可以用来分裂输入的语音信号并检测它们之间的同步特性,这类似于耳蜗的滤波处理。图4显示了元音/U/在五个频道中的波形,最上一条曲线代表基波,其下的曲线代表谐波;可以看出,这些波形包络之间的相关性较强。
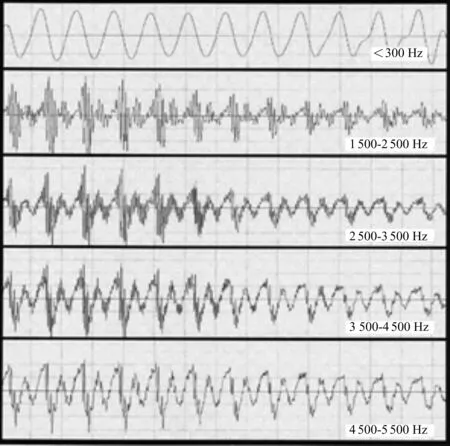
图4 元音/U/在五个频道中的波形
通过计算同时出现在相邻频道上的包络波形间的相关系数,同步检测器可以搜索较高频道中紧密合拍的同步能量模型。实际应用中,这个语音检测系统已显示出对宽带噪声中语音的敏感,VNR下降至0~-2 dB 时,该检测器效率仍然高;当VNR低于此范围时,它仍可检测出语音的存在;相反,环境的噪声信号是随机的,它在较高频道不具有像语音那样的谐波同步特性。当同步检测器判定语音不存在且调制检测器判定噪声存在时,管理系统确定噪声的存在而响应;这两个检测器并行工作,执行上述的环境均衡处理策略,它们的组合能更好地适配三态环境信号各自的特殊性。此外,根据同步检测中的语音警旗计数(speech flag-signal,是同步检测器的中间统计数据,1代表语音,0代表噪声)还可估计VNR的大小,为多带自适应方向性处理提供判断的依据。
某些音乐信号也会激活同步检测器。具有特色音质的乐器发出的声音是由某些泛音的特定模型形成,相当于谐波序列。根据统计数据[5],说话时语音信号的同步度可达30%到50%;而音乐演奏时,信号同步度高达50%。如果同步度不是很高,语音或音乐就不是输入信号中的主控成分。同步检测器的缺点是有时会将音乐、瞬态干扰或高频范围的宽带声音误判为语音,因此,使用判定结果之前,需先辨别其真伪。图5显示了一个使用三态噪声管理的助听器的增益特性,频道增益随环境信号类别而变化[9],可以看出,同步检测器确有语音、音乐优先的效果。只要这两类信号存在,助听器的增益基本不下降,仅在随机噪声输入时,增益下降了9 dB。
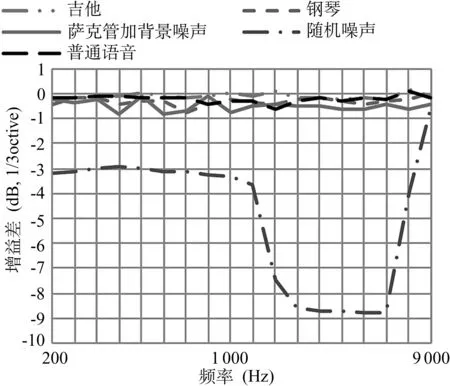
图5 使用三态噪声管理的助听器增益下降特性
猜你喜欢
现代特殊教育(2022年10期)2022-10-13
新作文·小学低年级版(2022年6期)2022-08-30
青年文学家(2022年3期)2022-03-16
中老年保健(2021年7期)2021-08-22
防爆电机(2020年3期)2020-11-06
电声技术(2020年6期)2020-10-27
汉字汉语研究(2019年2期)2019-08-27
中华诗词(2018年11期)2018-03-26
发明与创新·中学生(2016年7期)2016-05-14
中国光学(2015年5期)2015-12-09
