
基于多维度权重动态更新的用户兴趣模型
2014-06-06 10:46任保宁梁永全赵建立廉文娟李玉军
计算机工程 2014年9期
任保宁,梁永全,赵建立,廉文娟,李玉军
(1.山东科技大学信息科学与工程学院,山东青岛266500;
2.海信集团有限公司数字多媒体技术国家重点实验室,山东青岛266071)
基于多维度权重动态更新的用户兴趣模型
任保宁1,梁永全1,赵建立1,廉文娟1,李玉军2
(1.山东科技大学信息科学与工程学院,山东青岛266500;
2.海信集团有限公司数字多媒体技术国家重点实验室,山东青岛266071)
面向个性化电影推荐领域,提出一种基于多维度权重动态更新的用户兴趣模型。将电影分成演员、导演、类别、地区和时间5个维度,分别计算电影在这些维度上的相似度。采用归一化方法将电影之间的相似度转化为用户兴趣模型中的多维度权重,并应用TF-IDF算法计算各维度中特征词的权重,从而实现电影各维度权重及其特征词权重的动态更新。利用基于内容的推荐算法,在MovieLens数据集进行实验,结果表明,该模型具有较高的推荐准确率和召回率,并且能够发现用户对电影维度的偏好,解决用户兴趣漂移问题。
用户兴趣模型;个性化推荐;动态权重更新;多维度;维度相似度;兴趣漂移
1 概述
随着通信技术和互联网的发展,信息量呈几何级数增长,面对海量的信息,为使人们能找到自己需要的信息,搜索和推荐应运产生,搜索是系统根据人们输入的查询条件检索信息,推荐是系统根据人们的喜好,自动地为人们呈现信息,大大满足了用户的需求。
个性化推荐就是根据用户的个人喜好进行推荐,成为一个越来越受关注的领域。在个性化推荐系统中,用户兴趣模型是基础、推荐算法的核心。用户兴趣模型[1]的表示方法有:主题表示法[2],关键词列表向量法,书签表示法,基于本体的表示法,兴趣粒度表示法,向量空间模型的表示法[3],其中,向量空间模型表示法的应用较广泛。
用户兴趣模型[4]用向量空间模型表示为:V= {PK:PW},其中,PK表示用户兴趣词集;PW表示兴趣词对应的权重集。在个性化电影推荐系统中,用一组关键词表示一个电影,电影 M:{导演:导演名…;演员:演员名…;类别:类别名…;地区:地区名…;上映时间:时间}。如果用向量空间模型表示用户对电影的兴趣模型,在PK中包含导演、演员、类别、地区等用户感兴趣的关键词,可以用TF-IDF来统计各个词的权重。
文献[5]提出针对不同应用领域特征,建立不同的用户兴趣模型,对于电影这种特殊的资源,含有明确的维度区分(演员、类别等),但是使用向量空间模型的表示方法只能体现用户对哪个特征词感兴趣,不能体现出用户对哪个维度比较感兴趣。
针对该问题,本文建立了两层用户兴趣模型,在此基础上设计电影维度权重更新算法。由于用户兴趣模型是两层的,因此在模型更新时,主要分成两步:各维度中兴趣词及其权重的更新和各维度权重的更新,并给出经过改进的用户兴趣模型与未改进的用户兴趣模型在基于内容推荐算法中的对比结果。
2 用户兴趣模型
用户对电影的兴趣不能简单地分成喜欢和不喜欢,对一部喜欢的电影,不同的用户对于该电影的喜欢程度不同、维度不同。一个电影可以分为导演、演员、类型、地区、时间5个维度,每个维度都有自己的特征值,比如类型维度,类型维度中的特征值为喜剧、爱情、惊悚、动作等。假设2个用户喜欢同一部电影,但是他们可能对这部电影的维度侧重不同,一个可能因为这个电影的演员而喜欢,另一个可能因为这个电影的导演而喜欢。
基于以上分析,本文建立的用户对电影的兴趣模型是一个两层模型[6],如图1所示,中间层表示电影的维度,底层表示电影各维度上的特征值。

图1 用户-电影兴趣模型

用户i对某个特征值j的兴趣度为:

其中,对于Wij可以用该特征值的个数占该维度中所有特征值个数的比值来计算,也可以用TF-IDF来计算权重[7]。对于wi,应该随着用户观看电影的不同不断变化。本文根据用户看过的电影,设计一个算法来动态更新wi。
3 多维度权重动态更新算法
3.1 算法思想
用户看过的电影能够反映用户对电影的喜好,假设用户看过《功夫熊猫1》,并且评价还不错,那么他看《功夫熊猫2》的概率是较大的;用户看过周星驰演的电影并且评价不错,那么他以后看周星驰演的电影的概率较大。
基于以上2点考虑,在用户看过的电影记录中取出用户评价较高的N部电影,并且这N部电影是有顺序的。用户看第i部电影,与前i-1部电影有关。这些电影中不是在演员维度上是相似的、就是在类别维度上是相似的,又或者是在多个维度上是相似的。利用电影之间在各个维度上的相似度来调整用户在各个维度上的权重[8]。
假设用户看过第i-1部电影后,用户对电影各维度上的权重为Wi-1,他因为看过第i-1部电影,才看第i部电影,那么这2部电影肯定存在一定的关系。
通过计算这2部电影在各个维度上的相似度,就可以找到这2部电影之间的关系。假设这2部用户在导演这个维度上相似度比较大,则说明该用户当时看这2部电影时是因为导演这个维度所致,那么该用户在导演这个维度上权重就要增加。
本文将这2部电影在各个维度上的相似度表示为:

其中,Si表示各个维度相似度的值,它是一个[0,1]之间的数。然后把各个维度上的相似度,转为单个维度上相似度占整个维度相似度之和的比值,即:

经过转化,可以把相似度转化为用户对这2部电影在各个维度上的偏好,表示为:


其中,λ表示Wi-1所占的比率;1-λ表示P(Mi-1, Mi)所占的比率。
3.2 电影各维度的相似度计算
在用户兴趣模型中,把电影分成演员、导演、类别、地区和时间5个维度[9],分别计算电影在这些维度上的相似度。电影可以用向量M来表示,M= {M1,M2,M3,M4,M5},Mi表示电影维度。
每个维度的Mi可以表示为Mi={Mi1,Mi2,…, Min},Min表示该维度上的特征值,是有顺序的。比如《大话西游之月光宝盒》,演员有周星驰、莫文蔚、吴孟达等。显然,要计算电影的相似度,在演员这个维度上周星驰的权重是比后面2位演员的权重大。
因此,将电影在演员、导演、类别、地区这4个维度上的Mi表示为:

电影A和电影 B的在这4个维度上的相似度为:

其中,i表示电影的4个维度;j表示维度上的特征值;wij表示电影在第i个维度上、第j个特征值的权重。
电影在时间维度上一般只有一个值,电影A和电影B在时间维度上的相似度式为:
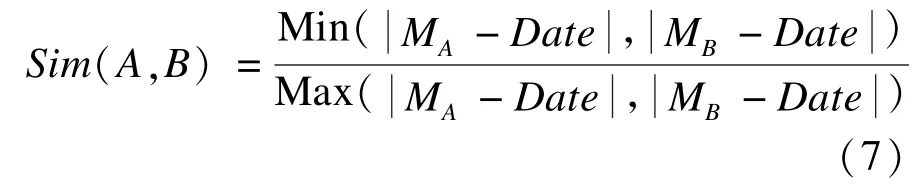
其中,Mi表示电影i的时间;Date表示当前时间;
Min()表示取最小值;Max()表示取最大值。
3.3 算法步骤
多维度权重动态更新算法步骤具体如下:
输入 用户看过且评分较好的电影列表 List<M>,初始值W1={0.2,0.2,0.2,0.2,0.2},λ表示式(8)中的阈值
输出 Wi表示更新后的用户兴趣模型的权重,i表示电影列表List<M>的长度
(1)计算电影列表List<M>的长度,记为i;
(2)根据式(6)、式(7)计算第 i部电影与前i-1部电影在各个维度上的相似度,记为:Sim(Mj, Mi),其中,1<j<i;
(3)根据式(3)将Sim(Mj,Mi)转化为P(Mj, Mi),其中,1<j<i;
(4)得到P(Mj,Mi)后,就能够计算Wi,计算如下:

(5)输出Wi。
多维度权重动态更新算法,是根据用户的观看记录的顺序以及电影之间的相似度进行动态更新。首先,设置各个维度的初值,这对所有用户是一样的。然后,通过式(3)把用户观看的电影之间的相似度转化为用户兴趣模型中各维度的权重,这样能够体现用户的个性化。另外,动态更新各维度的权重,能够捕捉用户的兴趣漂移。
该算法的时间复杂度较高,对于观看的N部电影,算法的时间复杂度为O(n2),需要进一步进行改进。
4 用户兴趣模型更新
一个好的兴趣模型是需要用户与系统之间进行不断的学习与更新,因为用户兴趣是不断变化的,所以用户兴趣模型也应该是不断变化的[10]。用户兴趣模型中的信息源是用户看过的电影信息。用户兴趣模型更新算法为:
输入 当前的用户兴趣模型Vi-1,刚看过的电影i,阈值∂
输出 用户兴趣模型Vi
(1)计算电影i与前前i-1部电影的相似度,得到相似度集合S;
(2)根据相似度集合S与Vi-1中的各维度的权重wi-1,利用式(8),计算出wi;
(3)统计从1部 ~i部电影在各维度上的特征词;
(4)利用TF-IDF计算特征词的权重,得到的权重如果大于阈值∂,则把该特征词加入模型中,否则不加入;
(5)得到Vi。
用户兴趣模型更新算法,主要是包括电影各维度权重更新、各维度中特征词及其权重的更新。
电影各维度权重更新主要是应用多维度权重动态更新算法。各维度中特征词及其权重的更新主要是应用TF-IDF算法计算各维度中特征词的权重,并通过设置阈值过滤掉不符合情况的特征词。该算法的时间复杂度为O(n2)。
5 实验结果与分析
5.1 实验数据
为验证本文改进的用户兴趣模型在推荐算法中的有效性,采用推荐系统评测数据集MovieLens[11]。
该数据集中,包含943个用户、1 682部电影及100 000条用户对电影的评价记录。用户对电影的评价分为1个~5个等级。其中,80%的数据用于训练;20%数据用户测试。在该数据集中,电影的信息主要为类别、上映时间、电影名称。因此,本文对该数据集中的电影主要是在类别、时间这2个维度上进行实验。
5.2 评价指标
本文采用基于内容的推荐算法来进行验证改进的用户兴趣模型的有效性,因此评价指标选取准确率和召回率。
准确率定义为推荐列表中与用户测试集合同时存在的商品数目与推荐列表中所有商品的比率[12]:


其中,B表示测试集合中用户喜欢的所有商品的数目;Ntp表示同时出现在用户测试集合和推荐列表中的商品数目。
5.3 结果分析
在本文实验中,分别利用用户观看的电影记录构建本文提出的用户兴趣模型,并将其与文献[4]的用户兴趣模型(记为未改进的用户兴趣模型)进行比较。根据基于内容推荐算法来进行推荐。推荐列表的长度分别为10,15,20,25,30。实验结果如图2、图3所示。
其中,L表示推荐列表的长度;Ntp表示同时出现在用户测试集合和推荐列表中的商品数目。
召回率定义为推荐列表中的用户喜欢的商品与测试集合中用户喜欢的所有商品的比率[12]:

图2 准确率实验结果

图3 召回率实验结果
通过实验结果可以看出,经过改进的用户兴趣模型在基于内容推荐算法中的推荐准确率和召回率都有提高。
6 结束语
随着信息的快速增长,个性化服务已经越来越多的应用到很多领域。面向个性化电影推荐领域,本文提出一种多维度权重动态更新的用户电影兴趣模型。该模型主要通过研究用户的观看记录以及观看电影之间的相似度,发现用户对电影中维度的偏好,并且能够较好地处理用户兴趣漂移问题。但是,该模型需要用户的观看记录,并且时间复杂度较高,需要进一步优化。
[1] 宋艳娟,陈振标.个性化检索系统中用户兴趣模型的研究[J].计算机与数字工程,2013,(2):271-274.
[2] 顾雅枫.基于用户兴趣模型的信息检索研究[D].兰州:兰州大学,2009.
[3] 韩 旭.个性化推荐系统用户兴趣建模方式的研究[J].数字技术与应用,2010,(11):44-46.
[4] 薄 阳.基于用户兴趣模型的个性化推荐与搜索系统的研究[D].北京:华北电力大学,2010.
[5] 靳玉红,李家会.个性化服务中用户兴趣的建模研究[D].绵阳:西南科技大学,2011.
[6] Zheng Nan,Li Qiudan.A Recommender System Based on Tag and Time Information for Social Tagging Systems [J].Expert Systems with Applications,2011,38(4): 4575-4587.
[7] Mojtaba S,Mohammad P,Seyed A R.Hybrid Attributebased Recommender System for Learning Material Using Genetic Algorithm and a Multidimensional Information Model[J].Egyptian Informatics Journal,2013,14(1):67-78.
[8] Lakiotaki K,Matsatsinis N F.Multi-criteria User Modeling in Recommender Systems[J].Intelligent Systems,2011,26(2):1541-1672.
[9] Adomavicius G,Tuzhilin A.Multidimensional Recommender Systems:A Data Warehousing Approach[C]// Proceedings ofthe 2nd InternationalWorkshop on Electronic Commerce.London,UK:Springer-Verlag, 2007:180-192.
[10] Manouselis N,Costopoulou C.Analysis and Classification of Multi-criteria Recommender Systems[J]. World Wide Web,2007,10(4):415-441.
[11] Grouplens[EB/OL].[2012-11-16].http://www. grouplens.org/node/73.
[12] 朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(2):163-175.
编辑 陆燕菲
User Interest Model Based on Dynamic Update of Multi-dimensional Weight
REN Bao-ning1,LIANG Yong-quan1,ZHAO Jian-li1,LIAN Wen-juan1,LI Yu-jun2
(1.College of Information Science and Engineering,Shandong University of Science and Technology,Qingdao 266500,China;
2.State Key Laboratory of Digital Multi-media Technology,Hisense Group Co.,Ltd.,Qingdao 266071,China)
For personalized movie recommendation domain,this paper proposes a user interest model based on dynamic update for multi-dimensional weight.It divides the movie into five dimensions of actor,director,categories,area and time,respectively to calculate the similarity among these dimensions of film.It uses the normalization method to change the similarity of film into multi dimension weight of the user interest model,and calculates the weights of features of each dimension in the application of TF-IDF algorithm,in order to achieve dynamic update of the film weight and dimensions of feature weight by using content-based recommendation algorithm.In the MovieLens data set for experiment,results show that,the model has higher recommendation accuracy rate and recall rate,and can find user preferences on the film dimensions,solve the problems of user interest drift.
user interest model;personalized recommendation;dynamic update of weight;multi-dimension;similarity of dimension;interest drift
1000-3428(2014)09-0042-04
A
TP183
10.3969/j.issn.1000-3428.2014.09.009
国家“973”计划基金资助项目“云服务多媒体应用平台的基础架构研究与应用研究”(2012CB724106);国家自然科学基金资助项目(71240003);山东省自然科学基金资助项目(ZR2012FM003);青岛市科技计划基础研究基金资助项目(KJZD-13-29-JCH);青岛市开发区重点科技计划基金资助项目(2013-1-25)。
任保宁(1988-),男,硕士研究生,主研方向:数据挖掘,智能推荐;梁永全,教授、博士生导师;赵建立(通讯作者),副教授;廉文娟,博士;李玉军,研究员。
2013-05-20
2013-09-23E-mail:renbaoning2007@126.com
猜你喜欢
当代陕西(2020年17期)2020-10-28
作文成功之路·小学版(2020年9期)2020-10-28
计算机技术与发展(2018年8期)2018-08-21
人大建设(2018年5期)2018-08-16
中国机械工程(2017年22期)2017-12-02
商周刊(2017年7期)2017-08-22
电信科学(2017年6期)2017-07-01
中文信息学报(2015年4期)2015-04-21
河南科技(2014年15期)2014-02-27
体育师友(2012年4期)2012-03-20
