
基于CUDA的AES并行算法优化
2014-06-06 10:46费雄伟李肯立阳王东
计算机工程 2014年9期
费雄伟,李肯立,阳王东
(1.湖南城市学院信息科学与工程学院,湖南益阳413000;2.湖南大学信息科学与工程学院,长沙410008)
基于CUDA的AES并行算法优化
费雄伟1,2,李肯立2,阳王东1,2
(1.湖南城市学院信息科学与工程学院,湖南益阳413000;2.湖南大学信息科学与工程学院,长沙410008)
为提升高级加密标准(AES)的加密性能,利用显卡的通用计算能力,在统一计算设备架构(CUDA)平台上实现AES的128位、192位和256位3个版本的GPU并行算法,并提出优化的AES并行算法。在考虑块内线程数量、共享存储器容量和总块数的基础上,根据分块最优值的经验数据指导AES算法在GPU上的最优分块。实验结果表明,与未优化的AES并行算法相比,该算法的3个版本在Nvidia Geforce G210显卡上的加密速度分别提高5.28%,14.55%和12.53%,而在 Nvidia Geforce GTX460显卡上的加密速度分别提高 12.48%,15.40%和15.84%,且能更好地对SSL数据进行加密。
分块;经验数据;并行算法;优化;高级加密标准;统一计算设备架构
1 概述
随着电子商务和电子金融的用户群体扩大和对安全的要求更高,加密及其加密性能成为亟待处理的问题。对加密算法,首先要考虑的是它的安全性能,但在实际应用时还需考虑它的性能和成本。高级加密标准(Advanced Encryption Standard,AES)算法在大量需要安全通信的应用中担当加密、解密任务,很好地协调了安全、高效和简明等特性。但随着网络用户的迅速增加,对大规模加密任务应用服务器(如电子商务或电子金融)的加密性能提出了更高的要求。为了提升AES的加密性能,最近许多基于FPGA和基于GPU加速的AES算法被提出。基于FPGA的加速AES主要应用于无线和蓝牙通信环境的加速加密,需要考虑能耗和大小等问题。比如文献[1]在Xilinx Spartan-III和Xilinx Spartan-II这2类设备上对AES进行了速度和面积大小方面的对比研究;文献[2]提出了适应无线局域网环境的AES高速FPGA实现;文献[3]在FPGA上实现了AES-128、AES-192和AES-256,并进行优化,达到了节能的要求,适合于移动的设备;文献[4]提出了高吞吐量的AES引擎,采用FPGA实现了面积优化36.2%的AES算法。但采用FPGA这类专用硬件设计的AES算法实现不够灵活、难以升级维护,而且开发周期长、开发成本高,还存在扩展性差等缺点,并不适合于电子银行或者电子金融这类应用。最近的显卡设备(如NVIDIA Geforce G210)提供了通用计算能力,支持整数和异或运算,可实现密集的并行加密计算,可以满足AES高强度的加解密需求,同时也提供了通用的软件开发环境——CUDA,降低开发的难度。基于GPU的加速AES可弥补FPGA的不足,有低成本(不需额外增加设备)、易开发(提供CUDA平台)等优良特性,特别适用于服务器执行高密度的加密任务。比如文献[5]探索了利用GPU设备进行并行的数据加密;文献[6]在AVR微控制器和NVIDIA显卡等多个平台上实现了AES,实验显示GPU并行的AES算法速度更快且代码更短;文献[7]在GPU上对小型内存文件和大型硬盘文件均进行了并行AES加速,得到了很好的加速比;文献[8]使用CUDA、OpenMP、OpenCL对AES进行并行加速,结果显示CUDA获得的加速性能最好,其次是OpenCL,最差的是OpenMP;文献[9]在配置了一个多核处理器和一个GPU设备的计算平台上,采用扩展一次加密数据块大小的方法对AES的CTR模式进行加速处理。
基于CUDA的并行AES算法的优化有如下进展:文献[10]提出适当地在不同的GPU存储器空间安排数据能带来性能提升,在GeForce 9200MGS显卡上能达到6.4 GB/s的吞吐量。文献[11]采用字节分片(byte-sliced)的方法在ARM微处理器和Nvidia显示卡对AES-128的加密及解密同时进行优化处理,并采用平台相关的技术来提升AES-128的性能,在NVIDIA 8800 GTX显卡上运行的优化AES-128能达到8.8 GB/S的吞吐量。文献[12]将线程块的明文和轮密钥存储在共享存储区来优化AES,但没有与未优化的AES进行对比。文献[13]主要对4种不同的并行粒度(分别按明文1字节/线程、4字节/线程、8字节/线程和16字节/线程的粒度)进行了对比研究,得出在CUDA上16字节/线程的AES并行算法的性能最好,此外也从内存分配方面对AES并行算法进行了优化,提升了2%~20%的性能。
国内学者在AES算法优化方面的进展有:文献[14]利用流水线、并行处理和可重构技术,提出了一种可重构体系结构,实现的AES吞吐率在110 MHz工作频率下分别可达到1.4 Gb/s。文献[15]采用指令集架构(ISA)扩展的方式对AES密码算法进行优化,提出一个高效AES专用指令处理器(AES-ASIP)模型,最终实现于FPGA中。对比ARM处理器指令集架构,AES-ASIP以增加少许硬件资源为代价,提高了算法58.4%的执行效率,并节省了47.4%的指令代码存储空间。
基于以上背景,为了提升加密性能,本文在统一计算设备架构(Compute Unified Device Architecture, CUDA)平台上实现AES 3个版本的GPU并行算法,并对不同的分块大小进行性能比较,得到分块最优值的经验数据。在实际中能根据明文大小选择最优的分块来执行AES加密,分别在NVIDIA Geforce G210和Geforce GTX 460显卡上运行,对比分块优化的并行AES和未经过优化的并行AES的性能。
2 AES算法
AES也叫Rijndael密码,1998年由Daemen J和Rijmen V提出,2001被美国标准技术局(NIST)选为新一代对称密码标准。它是一个分组对称密码,以128位为一分组,加密、解密使用同一密钥,密钥可以使用128位、192位或256位密钥。AES采用完全对称的结构,主要有异或、查找表和移位等操作,能够高效执行。AES安全性强,能对抗差分攻击、线性攻击和序列等已知明文攻击。
AES通过对明文分组进行若干轮与密钥的运算得到密文分组。每轮包括轮密钥加、字节替换、行移位和列混淆4个阶段。AES-128、AES-192和AES-256均可以128位为一分组,分别使用128位、192位或256位密钥进行多轮迭代转换得到128位的密文。轮数由密钥位数决定:128位密钥需10轮,192位密钥需12轮,而256位密钥需14轮。除了首轮有一次轮密钥相加和最后一轮少一次列混淆外,其余每轮处理方式相同。每轮加密的对象为一个16 Byte(128位)的分组,可以看做1个4×4大小的二维数组(表),称为状态(state)。每轮的加密处理可分为4个阶段:轮密钥加(AddRoundKey,对轮密钥和状态进行异或运算,进行盲化),字节替换(SubBytes,使用S盒进行非线性替换),行移位(ShiftRows,对每行分别进行0, 1 Byte,2 Byte,3 Byte的循环移位,以在字内混淆),列混淆(MixColumns,线性变换每列以混淆数据)。整个AES-192的加密流程如图1所示。
在图1中,AES-192的192位(24 Byte)密钥需扩展为13个16 Byte(共208 Byte)的密钥分组。第1轮之前的轮密钥加时使用的是密钥的本身值w[0..3],表示密钥的前4个字。接下来的12轮过程都一样,包括字节替换、行移位、列混淆和轮密钥加4个阶段,使用的轮密钥是由原密钥扩展成的4字组,分别为w[4..7]~w[48..51]。特别注意第12轮少了一个列混淆的阶段。密钥扩展只需执行一次,故无需并行处理,设计为在CPU上串行执行1次。这样每轮访问密钥都没有数据依赖关系。置换表(S盒,Sbox)为16×16 Byte的二维表,值保持不变,每轮均按此表进行替换。行移位对第i行循环左移i个字节(0≤i<4)。列混淆采用的是有限域GF(28)上的乘法,数据针对的是状态。可见密钥扩展后,每个分组之间的加密过程都不存在数据依赖,能够以并行方式设计和实现AES-192。AES-128和AES-256的不同体现在:加密的轮数分别为10轮和14轮,相应的密钥位数和密钥扩展有所不同,密钥位数分别为128位和256位,密钥扩展后的长度分别为44 Byte和60 Byte。AES-128与AES-256的密钥扩展方法相同,但与AES-256的密钥扩展算法有细微差别。由于密钥扩展串行执行一次,因此并不影响AES不同位数版本的并行算法的设计和实现。
3 统一计算设备架构
3.1 统一计算设备架构模型
统一计算设备架构(CUDA)由NVIDIA公司为它的G80、G92和GT200等图形处理器提出的通用计算平台。CUDA的编程模型能集成主机和GPU代码到同一个C/C++源文件中,降低了开发的难度。模型的结构如图2所示。
CUDA通过调用一个函数,称之为核函数(kernel)来支持并行计算。核函数由CPU调用而由设备(GPU)执行。CUDA使用块(block)和线程(thread)的概念来表示算法的并行性。块是一组并发的线程单位,能独立执行。块与块之间的执行顺序可以是串行的,也可以是并行的。块内线程是并行执行的。同一块线程需要同步时,调用__syncthreads来实现。同一块线程通信时,可以使用共享存储器(shared memory),共享存储器只对一个线程块内部的线程提供访问功能。一块与另一块线程通信则必须使用全局存储器(global memory)。
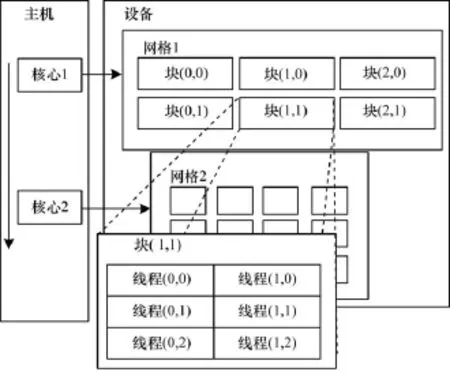
图2 CUDA模型
块的大小由程序员指定,通过一个三维结构(dim3)表示,分成了x,y,z3个坐标。多个块组成了一个更大的单位——网格(Grid)。网格的大小也由1个三维结构(dim3)表示,分成了x,y,z3个坐标(对NVIDIA Geforce G210z=1)。如图2中,网格1 (Grid1)具有维度(x,y)=(3,2),第三维缺省为1,即z=1。网格1具有6个块,分别编号为(0,0),(0, 1),…,(2,1)。这些块都具有相同的大小,对块(1, 1)而言,它的维度为(x,y)=(2,3),z缺省为1。所以具有 6线程,分别编号为(0,0),(0,1),…, (1,2)。
核函数通过kernel<<<blocks,threads>>>(parameters)修饰符的方式调用,即在普通C++函数调用格式中增加块数量(blocks)和每块的线程数(threads)这样的参数。CUDA的执行模型如图3所示。线程由线程处理器执行,但不是独立执行的,而是以线程块的形式在流多处理器上执行。如果多个线程块运行时所需的共享存储器和寄存器等流多处理器的资源能满足,那么一个流多处理器可安排多个线程块。流多处理器执行一个线程块时,按照线程束为单位执行。线程束的大小为32线程,所以一个线程块可以包含多个线程束。由线程束调度器选择准备好的线程束执行。线程束按单指令多数据流(SIMD)的方式执行,一个线程束中的所有线程同时执行相同的指令。核函数以一个线程网格的形式启动,对GPU设备而言一次只允许一个核函数执行。

图3 CUDA执行模型
3.2 不同分块的并行AES算法设计
在设计不同分块的并行AES的核函数时,采用了如下设计原则:
(1)每个块中线程数量是32的整数倍;
(2)考虑共享存储器容量的限制;
(3)考虑总块数的限制。
原则(1)的理由是充分利用流多处理器的并行能力。因为流多处理器以线程束为单位执行线块。如果块大小不是32的整数倍,则存在某些线程束少于32个线程(缺少的线程不执行),这样的线程束执行时占用与一个完整的线程束同样的计算时间,从而造成任务没有满载。
原则(2)与具体的算法执行时所需的共享存储器多少有关。对AES算法而言,共享存储器容量能达到同块所有线程执行AES的需要。
原则(3)说明CUDA程序运行的总块数受限于计算能力,总块数必须小于或等于最大支持的块数。
根据以上3条原则,AES算法的分块方案设计为:分别对AES-128、AES-192、AES-256设计了分块分别为64线程/块、96线程/块、128线程/块、160线程/块、192线程/块、224线程/块、256线程/块、288线程/块、320线程/块、352线程/块、384线程/块等11种分块方法。当块大于384线程/块时,由于Geforce G210的共享存储器受到64 KB容量的限制,无法满足执行AES算法的需要。当明文大于16 MB时,若采用32线程/块的分块方法,会超过Geforce G210的总块数的限制,因此也不能采用32线程/块的分块方法。其他的11种分块方法包括了所有大于32且小于等于384的所有32倍的分块大小。
3.3 基于分块优化的并行AES算法
由于AES算法本身的特点、明文块的大小、线程束的调度、显卡寄存器等硬件特点决定了不同的分块大小对并行AES算法的性能有着显著的影响,因此基于3.2节提出的分块方法,对不同的明文和显卡,按分块方法执行,对执行结果进行分析,得到特定的算法对特定的明文大小、最优的分块大小的经验数据。以此经验数据在实际处理时,自适应地根据明文大小和加密强度的要求,选择合适的分块来提升并行AES加密算法的性能。
基于分块优化并行AES算法,根据显卡环境首先需要执行一次以获取该环境的优化分块信息。然后下次在该环境执行并行AES加密处理时,根据加密服务要求(明文大小和加密强度),依据经验数据选择优化的分块进行加密,从而得到加密速度的提升。算法的具体情况见算法1。
算法1 基于分块优化的并行AES算法
功能 按照分块对并行AES-128、AES-192和AES-256进行优化
输入 明文plainText,密钥key,AES算法版本version,分块经验数据experience,执行次数times
输出 密文cipherText

4 实验结果与分析
4.1 实验环境
实验设计在2个不同的实验平台上进行,实验平台1和实验平台2的主要环境参数如表1和表2所示。

表1 实验平台1的主要环境参数
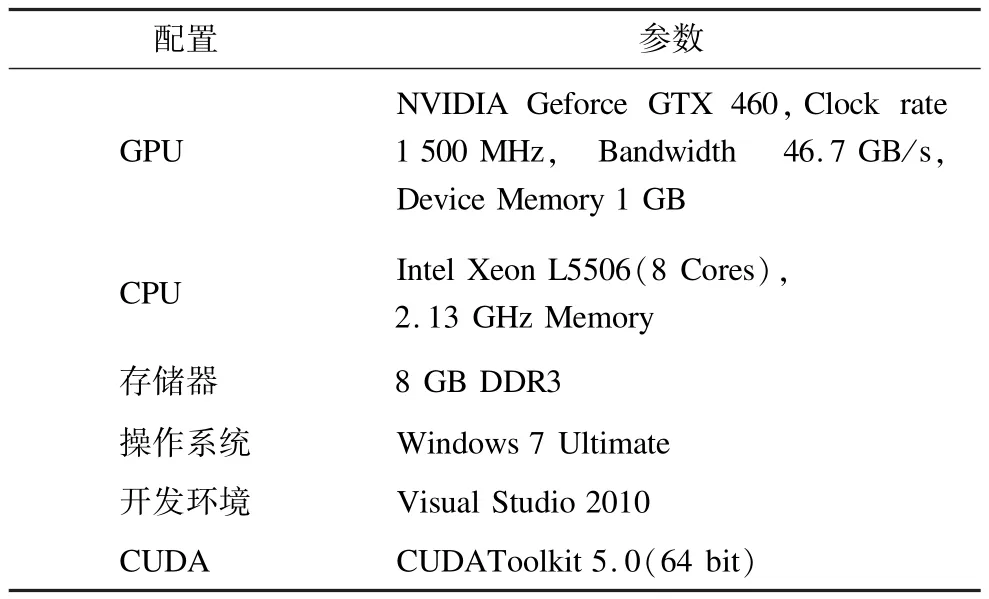
表2 实验平台2的主要环境参数
4.2 实验结果
实验分别在实验平台1和实验平台2上进行。每个平台的实验分3组进行,每组针对不同版本(AES-128,AES-192和AES-256)的AES算法。每组执行11种不同分块的AES并行程序各1次,分块大小由3.2节的分块方案确定。每种分块方案的AES算法执行时都对大小从64 Byte~16 MB的明文并行加密,统计每次实际运行时间。平台1的3组实验结果分别如图4、图5和图6所示。由于明文从64 Byte~16 MB变化,跨度比较大,每组实验的结果分成64 Byte~16 KB明文和32 KB~16 MB这2个图表分别展示。图4(a)是不同分块的AES-128在明文从64 Byte~16 KB区间的运行时间对比,图4(b)则是不同分块的AES-128在明文从32 KB~16 MB区间的运行时间对比。横坐标轴按64T/B,96T/B,128T/B,…, 384T/B从左到右依次排列,其中,64T/B表示的是分块大小为64线程/块,其余类似,。图5和图6的含义同图4,对比了AES-192和AES-256在不同分块情况下的运行时间。平台2的3组实验结果分别如图7~图9所示。这3个图对比了平台2上AES-192、AES-128和AES-256在不同分块情况下的运行时间。

图4 平台1上并行AES-128不同分块的运行时间

图5 平台1上并行AES-192不同分块的运行时间

图6 平台1上并行AES-256不同分块的运行时间

图7 平台2上并行AES-128不同分块的运行时间
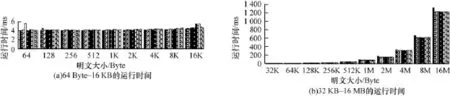
图8 平台2上并行AES-192不同分块的运行时间

图9 平台2上并行AES-256不同分块的运行时间
4.3 分析和讨论
考虑没有优化的AES算法,可能选择64线程/块~384线程/块的任意一种分块方法。因此,对没有优化的AES算法采用的是对这11种分块方案的平均来度量。经过数据分析,优化的AES算法带来的性能情况如表3所示。
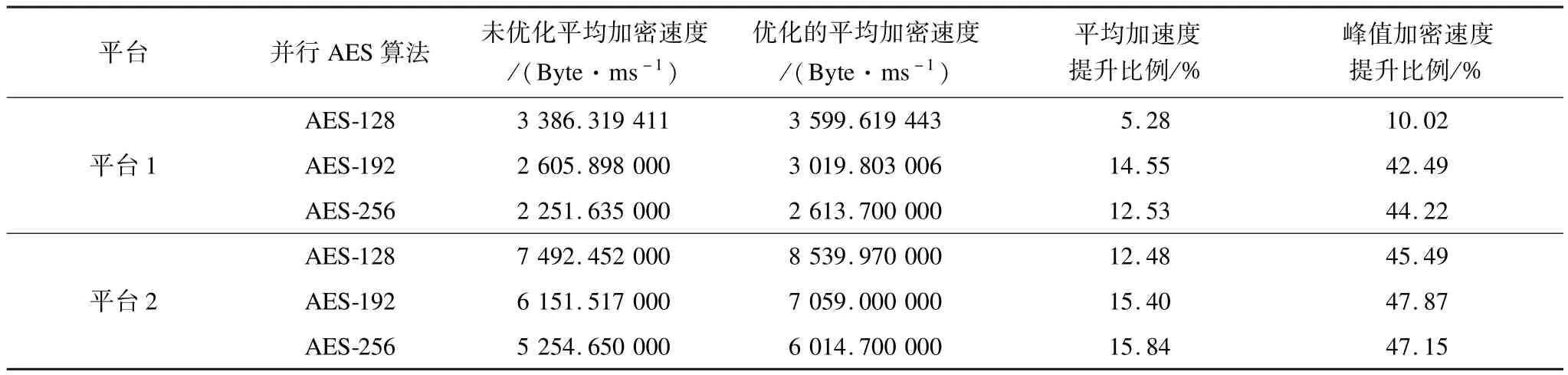
表3 优化的AES并行算法与未优化的AES并行算法性能比较
在平台1上,优化的AES算法的加密速度提升比例按照AES-128、AES-256和AES-192增加,并且AES-192和AES-256的提升比例非常接近。这是由于AES-192和 AES-256比 AES-128算法更复杂。优化的AES-256或AES-192获得的加密速度的峰值提升比例也很接近,均比优化的AES-128多提升了30%以上。
在平台2上,优化的AES算法的加密速度提升比例按照AES-128、AES-192和AES-256增加,并且AES-192和AES-256的提升比例非常接近。这是由于AES-192和 AES-256比 AES-128算法更复杂。优化的AES-256或AES-192获得的加密速度的峰值提升比例也很接近,比优化的AES-128提升了2%左右。
从表3中可以看出,采用优化的AES算法在不同的平台上均有加密平均速度提升和更高比例的加密峰值速度提升。由于平台2采用的显卡为Nvidia Geforce GTX460,相比平台1采用的显卡 Nvidia Geforce G210性能有很大提升,因此平台2的并行AES加密速度平均和峰值提升比例均优于平台1的并行AES算法。
为了分析不同分块在不同算法和明文大小下的性能提升情况,给出了优化的AES算法提升比例,如图10所示。其中,AES-128 pf1表示在平台1上优化的AES-128算法相比未优化的AES-128算法的性能提升比例,其余类似;而AES-128 pf2表示在平台2上优化的AES-128算法相比未优化的AES-128算法的性能提高比例,其余类似。优化的AES算法性能提升较大的区域主要有 2块,其中,1块是64 Byte~256 Byte的明文大小区间,另 1块是16 KB~256 KB之间。16 KB~256 KB明文大小的加速性能更是优于64 Byte~256 Byte这块的加密性能,且具有很好的现实意义。因为一次典型的只含HTML内容的SSL会话的传输数据量约为35 KB,而既有文本内容又有图像内容的SSL会话的数据量约为150 KB[16]。这说明优化的AES算法使用当前普通的或者高端的显卡对SSL加密提供了较好的性能提升。

图10 AES优化算法性能提升比例
5 结束语
为了应对服务器上加密瓶颈问题,采用了基于CUDA的并行AES算法来提升AES的加密性能。由于AES算法特征(AES版本和需要的计算资源)、显卡的硬件特征(寄存器数量,分块总数和线程束的调度等)和任务情况(明文大小)的原因,造成了不同的分块大小对并行AES性能有着较大的影响。因此,本文依据分块大小的经验数据,设计和提出了基于分块优化的 AES并行算法,包括 AES-128、AES-192和 AES-256 3个版本。通过在平台 1 (Nvidia Geforce G210)和平台 2(Nvidia Geforce GTX460)2个平台的实验运行,结果显示优化的AES算法带来了很大的性能提升。在平台1上,优化的 AES-128、AES-192和 AES-256分别达到了5.28%、14.55%和12.53%的加密速度平均提升比例和10.02%、42.49%和44.22%的加密速度峰值提升比例。在平台2上,优化的AES-128、AES-192和AES-256分别达到了12.48%、15.40%和15.84%的加密速度平均提升比例和 45.49%、47.87%和47.15%的加密速度峰值提升比例。优化的AES算法性能提升较大的明文区域主要有2块,其中一块是64 Byte~256 Byte的明文大小区间,另外一块在16 KB~256 KB之间,且16 KB~256 KB明文大小的加速性能优于64 Byte~256 Byte这块的加密性能,非常适合于对SSL加密的性能提升。
[1] Good T,Benaissa M.AES on FPGA from the Fastest to the Smallest[C]//Proc.of CHES'05.Berlin,Germany: Springer,2005:427-440.
[2] Sivakumar C,Velmurugan A.HighSpeed VLSI Design CCMP AES Cipher for WLAN(IEEE 802.11 i)[C]// Proc.of International Conference on Signal Processing, Communications and Networking.[S.l.]:IEEE Press, 2007:398-403.
[3] Thulasimani L,Madheswaran M.A Single Chip Design and Implementation of AES-128/192/256 Encryption Alogorithms[J].International Journal of Engineering Science and Technology,2010,2(5):1052-1059.
[4] Wang Yi,Ha Yajun.FPGA-based 40.9-Gbits/s Masked AES with Area Optimization for Storage Area Network [J].IEEE Transactions on Circuits and Systems,2013, 60(1):36-40.
[5] Cook D,KeromytisA D.Cryptographics:Exploiting Graphics Cards for Security[M].[S.l.]:Springer,2006.
[6] Bos J W,Osvik D A,Stefan D.Fast Implementations of AES on Various Platforms[C]//Proc.of IACR'09. Taormina,Italy:[s.n.],2009:501-515.
[7] Tomoiagaa R D,Stratulat M. Accelerating Solution Proposal of AES Using a Graphic Processor[J].Advances in Electrical and Computer Engineering,2011,11(4): 99-104.
[8] Duta C L,Michiu G,StoicaS,etal.Accelerating Encryption Alogorithms Using Parallelism[C]//Proc.of IEEE International Conference on Control Systems and Computer Science.[S.l.]:IEEE Press,2013:549-554.
[9] Nhat-Phuong T,Myungho L E E,Sugwon H,et al.High Throughput Parallelization of AES-CTR Alogorithm[J]. IEICE Transactions on Information and Systems,2013, 96(8):1685-1695.
[10] Mei Chonglei,Jiang Hai,Jenness J.CUDA-based AES Parallelization with Fine-tuned GPU Memory Utilization [C]//Proc.of IPDPSW'10.[S.l.]:IEEE Press,2010:1-7.
[11] Osvik D A,Bos J W,Stefan D,et al.FastSoftware AES Encryption[C]//Proc.of the 17th International Workshop on Fast Software Encryption.Berlin,Germany:Springer, 2010:75-93.
[12] Le Deguang,Chang Jinyi,Gou Xingdou,et al.Parallel AES Alogorithm for Fast Data Encryption on GPU [C]//Proc.of the 2nd International Conference on Computer Engineering and Technology.[S.l.]:IEEE Press,2010:61-66.
[13] Iwai K,Nishikaw N,Kurokawa T.Acceleration of AES encryption on CUDA GPU[J].International Journal of Networking and Computing,2012,2(1):131-145.
[14] 高娜娜,李占才,王 沁.一种可重构体系结构用于高速实现DES,3DES和AES[J].电子学报,2006,34 (8):1386-1390.
[15] 夏 辉,贾智平,张 峰,等.AES专用指令处理器的研究与实现[J].计算机研究与发展,2011,48(8):1554-1562.
[16] Levering R,Cutler M.ThePortrait of a Common HTML Web Page[C]//Proc.of ACM Symposium on Document Engineering.New York,USA:ACM Press,2006:198-204.
编辑 任吉慧
Optimization of AES Parallel Alogorithm Based on CUDA
FEI Xiong-wei1,2,LI Ken-li2,YANG Wang-dong1,2
(1.Department of Information Science and Engineering,Hunan City University,Yiyang 413000,China;
2.College of Computer Science and Electronic Engineering,Hunan University,Changsha 410008,China)
In order to enhance the efficiency of Advanced Encryption Standard(AES)and make use of general computing ability of Graphics Processing Unit(GPU),all the three versions of GPU parallel AES,namely 128 bit version,192 bit version and 256 bit version,are implemented on Compute Unified Device Architecture(CUDA).Then,it proposes optimization alogorithms of parallel AES with 3 versions.These alogorithms first consider threads amount in a block,shared memory size and total blocks,then use the experience data of optimal value of block size to guide AES alogorithm's optimal block on GPU.Experimental results show that compared with unoptimized parral AES,these alogorithms can obtain encryption mean speedup by 5.28%,14.55%and 12.53%respectively on Nvidia Geforce G210 graphics card,while by 12.48%,15.40% and 15.84% on Nvidia Geforce GTX460 graphics card.In addition,these alogorithms are better at improving encrypting of Secure Socket Layer(SSL).
block;experiential data;parallel alogorithm;optimization;Advanced Encryption Standard(AES);Compute Unified Device Architecture(CUDA)
1000-3428(2014)09-0006-07
A
TP301.6
10.3969/j.issn.1000-3428.2014.09.002
国家自然科学基金资助重点项目(61133005);国家自然科学基金资助项目(90715029,61070057,60603053)。
费雄伟(1980-),男,讲师、硕士,主研方向:网络与信息安全,并行计算;李肯立,教授、博士生导师;阳王东,教授、博士研究生。
2014-01-16
2014-02-21E-mail:25616235@qq.com
猜你喜欢
科技创新导报(2021年31期)2021-05-10
山东农业工程学院学报(2020年12期)2020-03-19
民间故事选刊·上(2018年1期)2018-01-02
现代电子技术(2016年15期)2016-12-01
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
湖州师范学院学报(2016年2期)2016-08-21
小小说月刊·下半月(2016年6期)2016-05-14
山西大同大学学报(自然科学版)(2016年6期)2016-01-30
中国资源综合利用(2016年11期)2016-01-22
地理与地理信息科学(2015年4期)2015-10-13
