
一种高效的多模式字符串匹配算法
2014-06-02 07:49许家铭李晓东键1
计算机工程 2014年3期
许家铭,李晓东,金 键1,,马 盈
一种高效的多模式字符串匹配算法
许家铭1,2,3,李晓东2,金 键1,2,马 盈4
(1. 中国互联网络信息中心,北京 100190;2. 中国科学院计算机网络信息中心,北京 100190;3. 中国科学院大学,北京 100190;4. 东北师范大学理想信息技术研究院,长春 130117)
在Fan-Su(FS)多模式字符串匹配算法基础上,结合BM-Horspool(BMH)算法和Quick Search(QS)算法的优点,提出一种高效的多模式字符串匹配算法。该算法能够充分利用本次匹配失败和部分匹配成功的信息,一方面增加模式树根节点失配的概率,提高匹配过程中失配时的跳跃距离。另一方面避免不必要的状态转移,实现不匹配时的连续跳转。分析指出,在最好情况和平均情况下,时间复杂度均优于ACBM算法和FS算法。实验结果表明,一般情况下该算法的查找时间仅为AC算法的10%~35%, ACBM算法的50%~60%,FS算法的70%左右,FSQB算法的65%左右。
字符串匹配;多模式匹配;有限自动状态机;算法复杂度;网络安全;信息检索
1 概述
模式匹配算法在文本挖掘、信息检索、模式识别、图像处理以及网络安全等领域中被普遍采用。随着互联网的迅猛发展,巨大的流量承载着各种信息充斥着网络,如何高效地实现针对信息内容的检测过滤,成为网络安全领域的一个关键问题,模式匹配算法正是内容检测的一项关键技术。
经典的单模匹配算法主要包括KMP算法[1]、Boyer- Moore(BM)算法[2]、BM-Horspool(BMH)算法[3]以及Quick- Search(QS)算法[4]。其中,KMP算法利用已匹配信息,实现了无回溯的比较,时间复杂度为()(和分别为文本串和模式串的长度)。BM算法是一种经典的跳跃式匹配算法,平均情况下比KMP更快,最好情况下时间复杂度为(/)。BMH算法是对BM算法的简化实现。QS算法则在BMH算法基础上进行改进,最好情况下时间复杂度为(/(+1))。
多模式匹配是从文本串[1:]中一次查找多个模式串1,2,…,P,所有模式串构成集合{}。其中,为{}中模式串的数目;为所有模式串长度之和;m为模式串P的长度;为最短模式串的长度;为最长模式串的长度;是字符集;是字符集大小。多模匹配的经典算法主要包括:Aho-Corasick(AC)算法[5],ACBM算法[6],FS算法[7]以及FSQB算法[8]。其中,AC算法通过预处理,将多个模式串转换为树型有限自动状态机(DFSA),对文本串扫描一次就可完成所有模式串匹配,匹配时间复杂度为()。ACBM算法融合了AC算法和BM算法思想,并在开源入侵检测系统Snort上实现[9],平均情况下效率优于AC算法,最好情况下时间复杂度为(/)。FS算法将BM算法与DFSA结合并改进,平均情况下效率优于ACBM算法,最好情况下时间复杂度为(/)。FSQB算法则将QS算法与DFSA结合并改进,最好情况下时间复杂度为(/(1))。
虽然ACBM算法、FS算法和FSQB算法在实际应用中表现优异,但仍未能充分利用匹配不成功的信息,导致跳跃距离有限,匹配效率受模式串数目影响较大。本文在FS算法的基础上,汲取BMH算法和QS算法思想,并提出进一步的改进,充分利用匹配失败的信息,跳过更多无需比较的字符,避免无用的状态转移。
2 相关算法
2.1 BM算法
BM算法的基本思想是从右向左进行逆向匹配。在预处理时构造坏字符表和好后缀表;在匹配时利用坏字符和好后缀启发性规则,跳过尽量多的字符。算法基本流程如下:首先从0开始,将文本串的第个字符与模式串的左端对齐。然后从与的最右端字符开始匹配,若匹配则向左依次匹配下一字符,直到匹配成功或发生失配。发生失配时,根据情况将向右移动,若失配发生在的最右端字符,则使用坏字符表跳转,使字符[]与其在中出现的下一位置对齐;若已匹配部分子串并在[]和[]处失配,则使用好后缀表跳转,使已匹配子串与其在中出现的下一位置对齐。
坏字符表记录字符在中出现的最靠右位置,定义为:

好后缀表记录各后缀在中重复出现的最靠右位置,定义如下:

2.2 BMH算法和QS算法
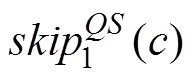
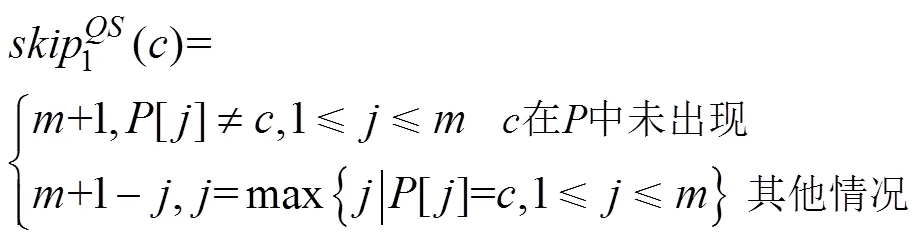
2.3 FS算法
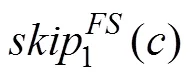
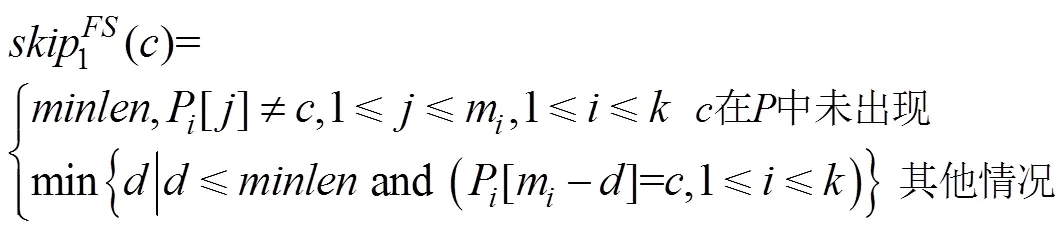

在匹配时采用改进的启发规则,匹配算法描述如下[7]:
算法1 FS多模匹配算法
输入文本串[1:],,,1和2函数
输出模式串在文本中匹配的位置
i = minlen;
state = 0;
while i ≤ n do
begin
if goto(state, T[i]) == 0 then
begin
if state == 0 then
i = i + skip1(T[i]);
else
i = i + skip2(state, T[i]);
state = 0;
end
else
begin
state = goto(state, T[i]);
if output(state) != NULL then
print i;
i = i–1;
end
end
3 改进的快速多模匹配算法
3.1 坏字符规则的改进
在匹配过程中发生失配时,充分利用失配信息,增加模式串跳跃距离,是进一步提高多模式匹配算法效率的关键。分析和实验表明:模式串数目很少时,坏字符规则起主要加速作用,好后缀规则优化效果不明显;随着模式串数目的增加,好后缀和单个字符出现的概率逐渐增加,好后缀规则优化效果逐渐增强,坏字符规则优化效果虽明显减弱,但仍起主要加速作用,如图1~图4所示。
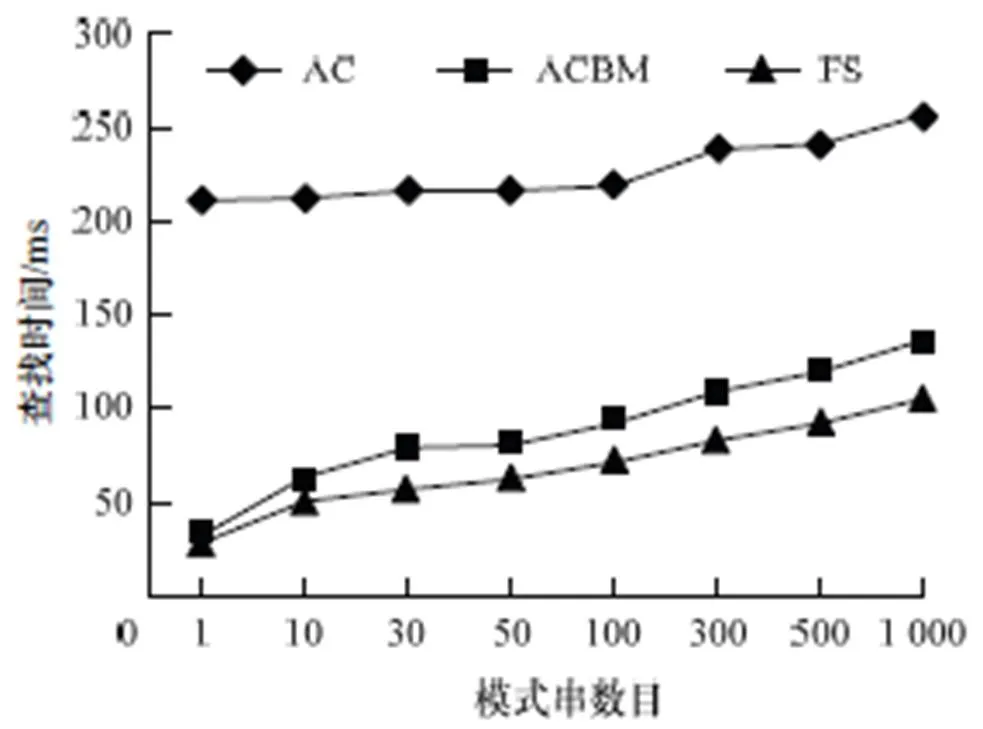
图1 查找时间随模式串数目变化的情况

图2 平均比较数随模式串数目变化的情况

图3 函数调用随模式串数目变化的情况

图4 函数跳转距离随模式串数目变化的情况
在图1~图4中,文本串为Reuters-21578[11],模式串选自Wordfrequency网站[12],模式串长度在11~15之间。
BMH算法和QS算法仅使用坏字符规则,就获得了很好的效果。但在失配时,BMH算法仅使用字符[]决定右移量,最大为;QS算法仅使用字符[1]决定右移量,最大为1。但随着{}的增大,各字符在模式串尾部出现的概率也随之增加,导致2个算法都很难达到最大的右移距离,优化效果有限。
本文在FS算法的基础上,吸收BMH算法和QS算法思想,对坏字符规则进行改进,使用双字符[:1]构造坏字符表,同时增加发现坏字符的概率和达到最大右移距离的概率。但只使用双字符进行跳转,会使最大右移距离仅为。
具体分析如下:为保证不遗漏任何可能的匹配,固定匹配窗口大小为,当[:1]在{}中出现时,最大右移距离为;当[:1]未在{}中出现时,分为如下2种情况:
(1)字符[1]未在所有模式串靠右端的第个字符中出现时,模式树可向右移1个字符,使匹配窗口左端与[2]对齐,右端与[1]对齐。
(2)字符[1]出现在某个模式P的最左端,且P的长度为时,模式树仅能向右移个字符,使匹配窗口左端与[1]对齐,右端与[]对齐。
基于以上分析,改进的坏字符规则将使用单字符[1]和双字符[:1]共同决定模式树右移距离,在增加发现坏字符概率和达到最大右移距离概率的同时,使得最大右移距离为1,增加了失配时的平均右移距离,跳过更多无需比较的字符,进一步减少了匹配过程中的比较次数。定义如下:

可分为如下3种情况,其中,12=[:1]:
(1)当2未在模式串集合中出现时,模式树可右移1,使匹配窗口左端与[2]对齐,右端与[1]对齐。
(2)当2出现在最短模式串集合的最左端时,模式树可右移,使匹配窗口左端与[1]对齐,右端与[]对齐。

这样,既保证了右移过程中不会遗漏任何可能的匹配,又提高了发现坏字符和达到最大跳跃距离的概率,获得了更大的跳跃距离。实际上还可同时考虑更多字符,进一步增加跳跃距离和达到最大跳跃距离的概率。但同时考虑的字符越多,坏字符表所占空间也越大。可使用哈希技术对坏字符表进行压缩,以降低空间复杂度。
3.2 坏前缀规则
FS算法在某些特殊情况下,效率会迅速下降[2,7]。本文针对其中一种特殊情况进行优化,并结合入侵检测系统中对报文内容的匹配和过滤进行说明。
对URL和邮箱地址中域名[13]关键字的检索和过滤,是入侵检测系统的一项主要工作。由于域名命名空间呈倒置的树形结构,域名字串具有从右到左的层次结构,其不同后缀的数目有限,而不同前缀和主体的数目则很大。具有类似特征的文本和模式集合,将导致算法在发现失配之前,进行许多无用的比较;在发现失配之后,右移跳跃很小的距离;在匹配过程中,对同一字符重复比较多次,导致效率迅速下降。
本文引入坏前缀规则,在发现匹配窗口[1:]内包含长度为的坏前缀时,启用改进的坏字符规则,跳过更多无需比较的字符。坏前缀表标记集合{}中,所有满足条件的字符串为true,定义如下:

3.3 改进的匹配算法
由于改进的坏字符规则,考察了当前匹配窗口的下一个字符[1],因此在匹配部分模式后再发生失配时,坏字符表的跳跃距离就有可能大于好后缀表的跳跃距离,此时应选择两者中较大的值作为跳跃距离。另外,在发生失配并跳转后,当前状态为模式树根节点,此时可以利用坏前缀和坏字符表进行连续跳转,避免不必要的状态转移。匹配算法描述如下:
算法2 FSA改进的多模匹配算法
输入文本串[1:],,,1,2和函数
输出模式串在文本中匹配的位置
i = minlen;
state = 0;
while !ispref(T[i–minlen+1:i–minlen+d]) || goto(state, T[i]) == 0 do
i = i + skip1(T[i], T[i+1]);
while i ≤ n do
begin
if goto(state, T[i]) == 0 then
begin
if state == 0 then
i = i + skip1(T[i], T[i+1]);
else
begin
t = i + state.depth;
i = i + max{skip1(T[t], T[t +1])+ state.depth, skip2(state, T[i])};
end
state = 0;
while !ispref(T[i–minlen+1:i–minlen+d])||goto (state, T[i]) == 0 do
i = i + skip1(T[i], T[i+1]);
end
else
begin
state = goto(state, T[i]);
if output(state) != NULL then
print i;
i = i – 1;
end
end
示例说明:文本串[1:]为"toldsheignorehererrors",模式串集合{}为{,,,},=3,取=2。函数转移图如图5所示。
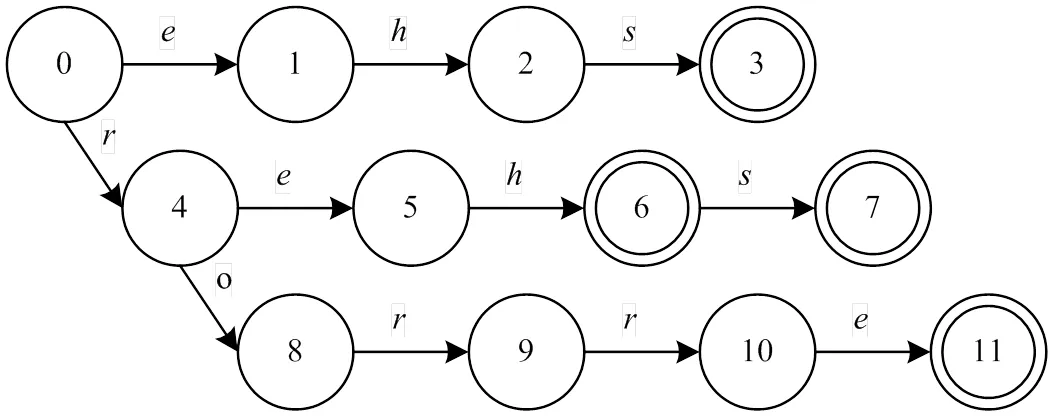
图5 反向自动机goto函数转移
各个函数表如表1~表4所示。匹配过程如表5所示,其中,每一行表示在匹配过程中,当前状态有输出或输入字符失配;方括号内为当前匹配窗口,加粗带下划线字符为当前比较字符,斜线表示无值。

表1 output函数表

表2 ispref函数表(d=2)
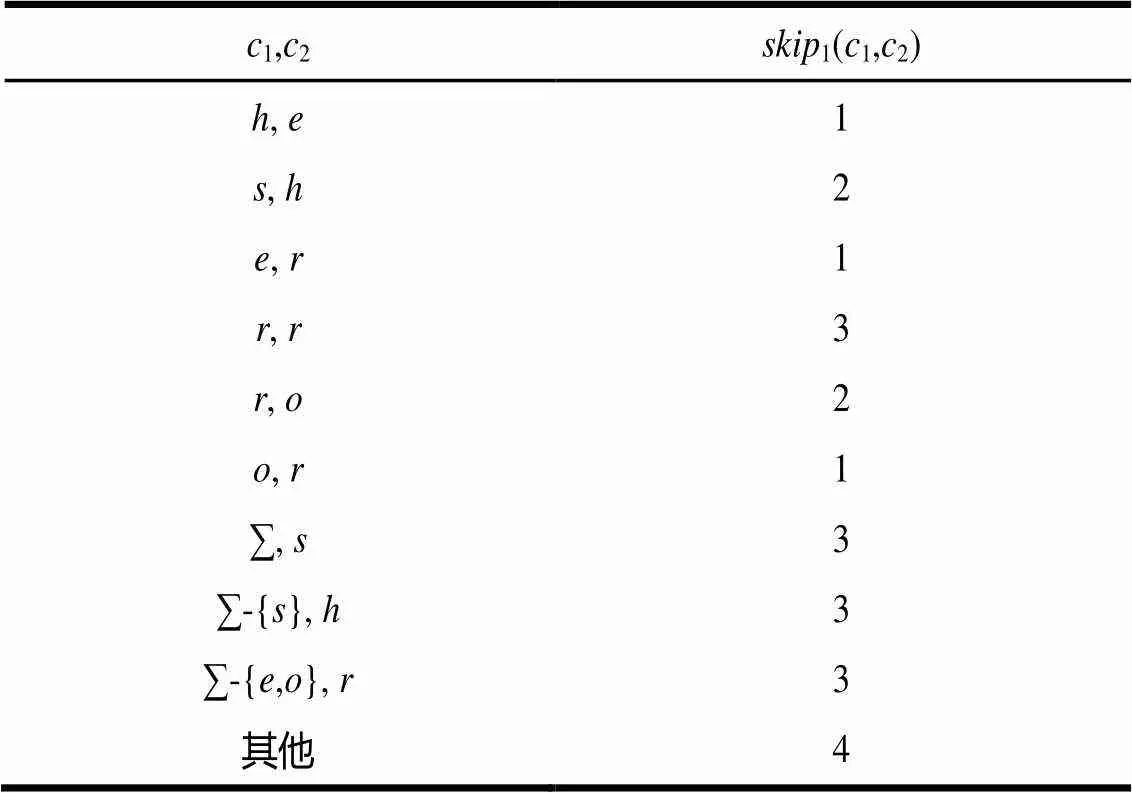
表3 skip1函数表
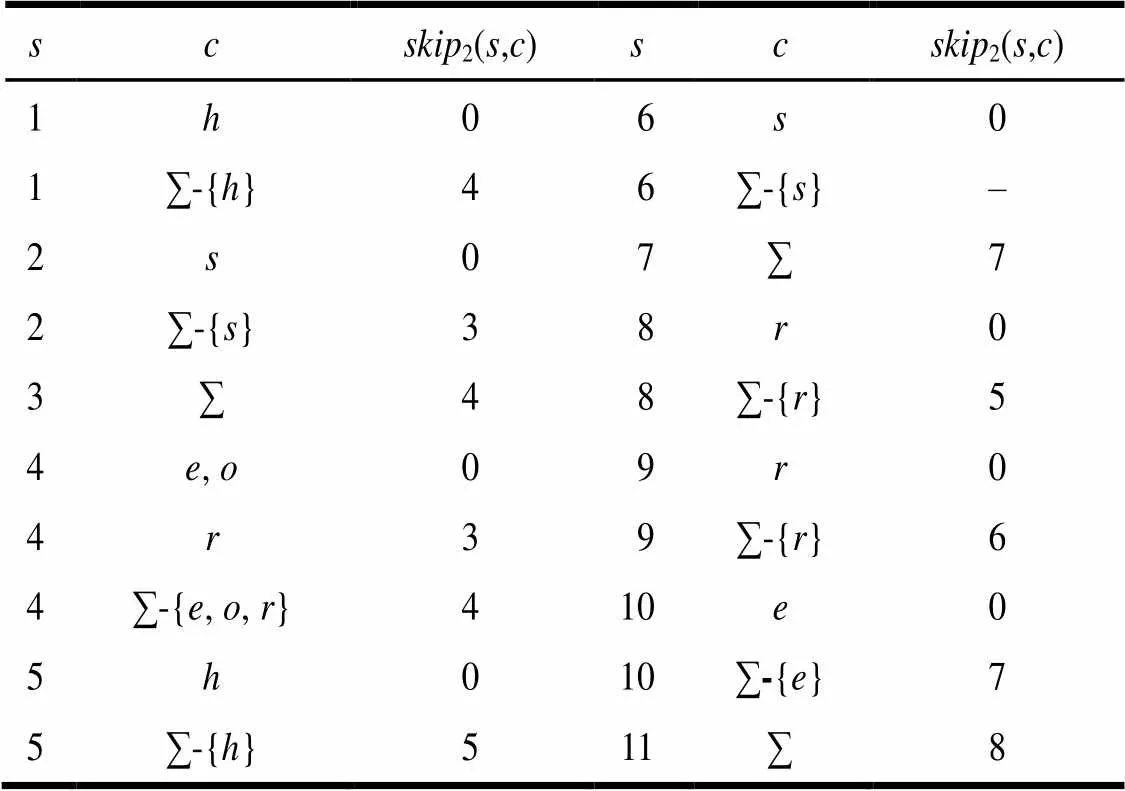
表4 skip2函数表(minlen=3)
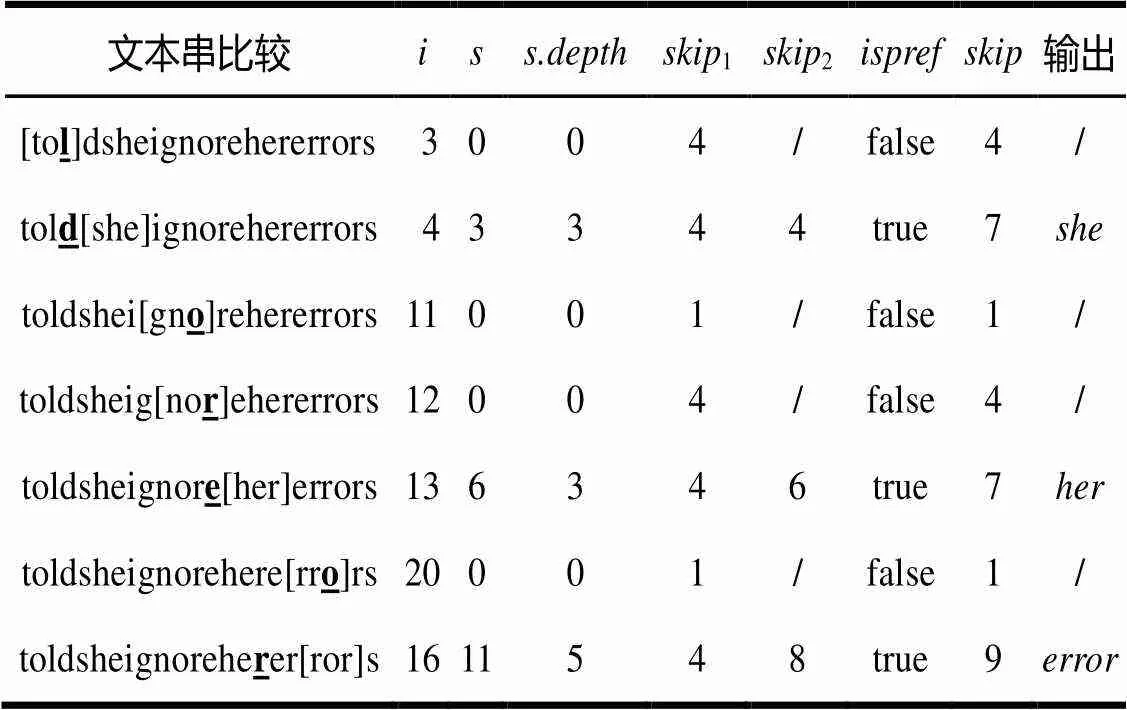
表5 匹配过程
4 时间复杂度分析
4.1 预处理阶段
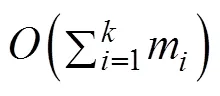

4.2 匹配阶段

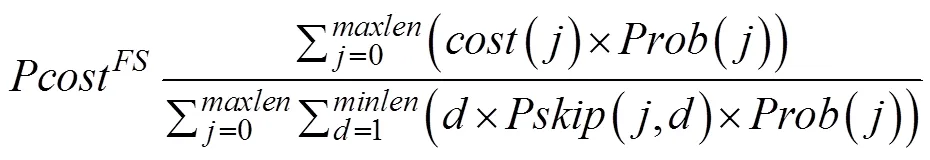
其中,()为匹配1个字符所花费的代价;()为从右向左匹配到第1个字符才发生失配的概率;(,)为此时右移距离为的概率。
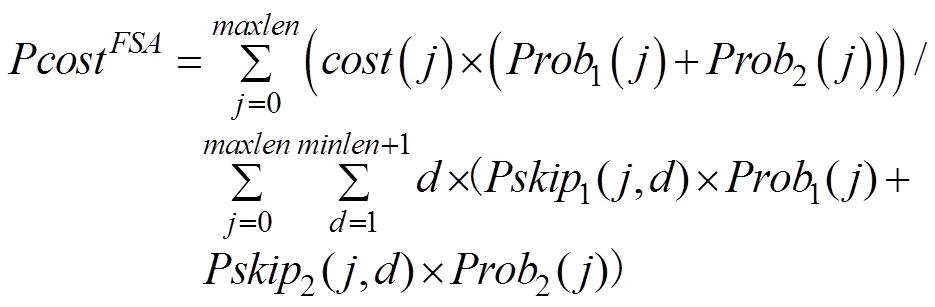
其中,()意义同上;1()和2()分别为此时使用函数1和2跳转的概率;1(,)和2(,)分别为此时调用函数1和2右移距离为的概率。
本文算法通过改进坏字符规则,引入坏前缀规则,提高了发现坏字符的概率,减少了发现失配所花费的代价,并在失配时提高了使用1函数跳转的概率1()和取较大值的概率,向右跳过更多无需比较的字符,使最大右移距离达到1。通过改进匹配算法,在失配时避免不必要的状态转移,实现了失配时的连续跳转,在花费相同的代价下,获得更多的跳转。总之,本文算法使代价函数的分子减小分母增大。平均情况下,本文算法较ACBM算法、FS算法和FSQB算法的时间复杂度更优。
5 实验分析
为测试本文FSA算法的性能,并与AC算法、ACBM算法、FS算法和FSQB算法进行横向对比,选取以下6个评价指标进行考察:(1)查找时间。(2)文中单个字符平均比较次数,即算法执行字符比较操作总数除以文本长度。 (3)跳转函数调用次数,即分别调用函数1和2的次数。(4)跳转函数跳跃距离,即分别调用函数1和2跳过的总字符数。(5)平均收益,即跳跃距离之和除以比较操作数之和。(6)平均代价,即发现失配所花的代价之和除以跳跃距离之和。
实验环境如下:Windows 7操作系统,Core i7 3.40 GHz CPU,4 GB内存;AC算法和ACBM算法均选用开源软件Snort中的实现版本,FS算法、FSQB算法和本文算法均采用C++语言实现。
待匹配文本由路透社的Reuters-21578新闻文本数据集组成,共约28 MB。待匹配模式串集合,从Wordfrequency网站提供的高频词汇表中随机选取。为考察模式串长度和数目对算法性能的影响,模式串按长度分为4个部分,各部分再按照串数目分为8组,各组模式串数目从10~150以20为单位递增。
表6显示了不同模式串长度和数目下,FSA算法较其他算法都有更好的性能。
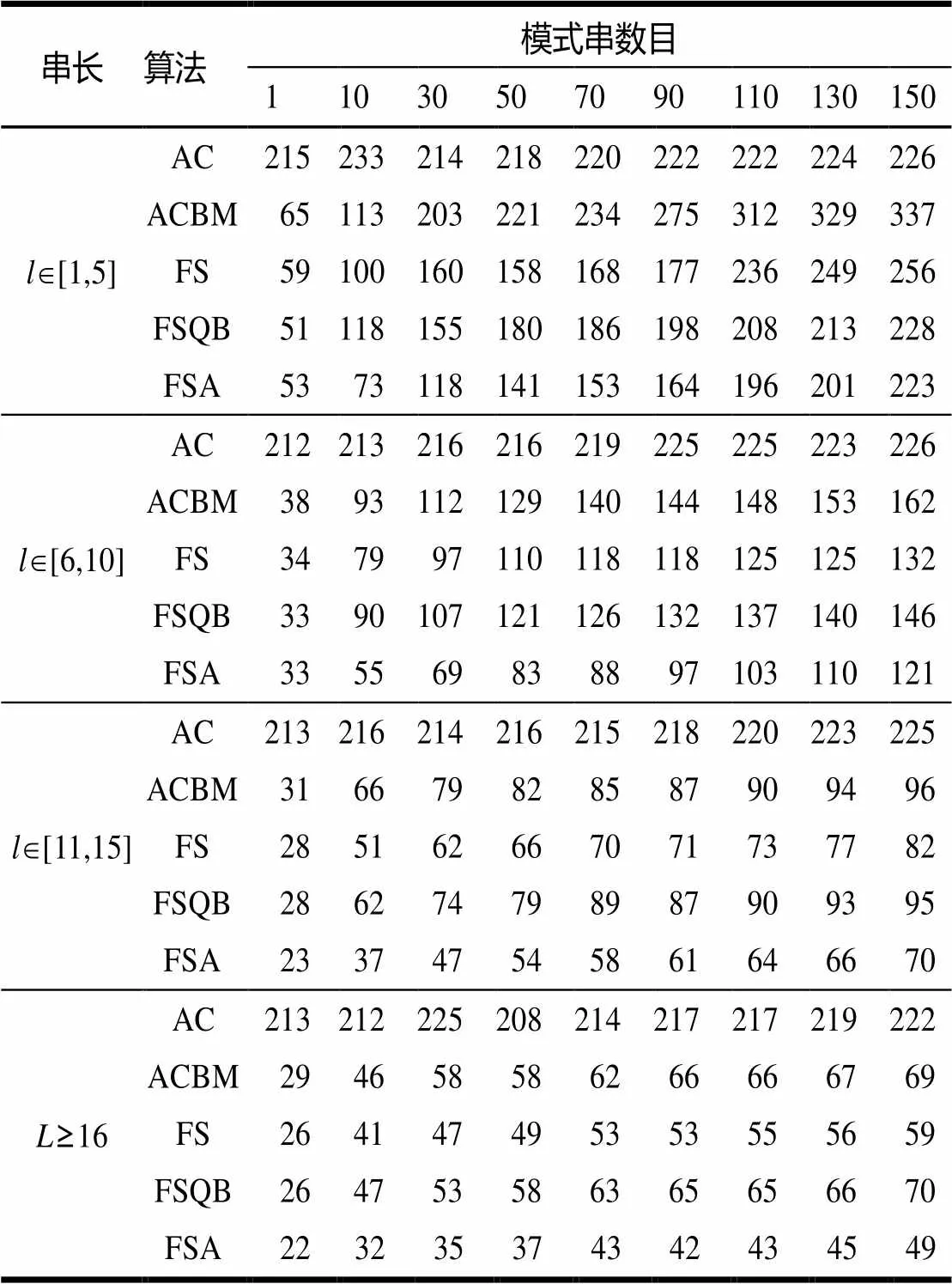
表6 查找时间 ms
与FS算法和FSQB算法相比,FSA算法在模式串较长和模式数较少时,性能改进更多。当模式串长度在1~5之间且模式较少时,FSA算法查找时间仅为AC算法的25%~50%,ACBM算法的60%左右,FS算法的75%左右,FSQB算法的60%~80%。当模式串长度大于6时,FSA算法对性能的改进更大。
在实际应用中,大部分模式串的长度都在6以上[7]。为比较一般情况下算法的平均性能,随机选取长度在6以上模式串进行实验测试。
图6中数据显示,随着模式串数目增加,AC算法的查找时间基本稳定,其余算法的查找时间和平均比较操作数,均呈亚线性增长,且增长速率逐渐放缓。其中,模式串长度≥6;FSA算法的查找时间是AC算法的10%~35%,ACBM算法的50%~60%,FS算法的70%左右,FSQB算法的65%左右;平均比较操作数是AC算法的10%~17%,ACBM算法的45%~50%,FS算法的55%左右,FSQB算法的65%左右。
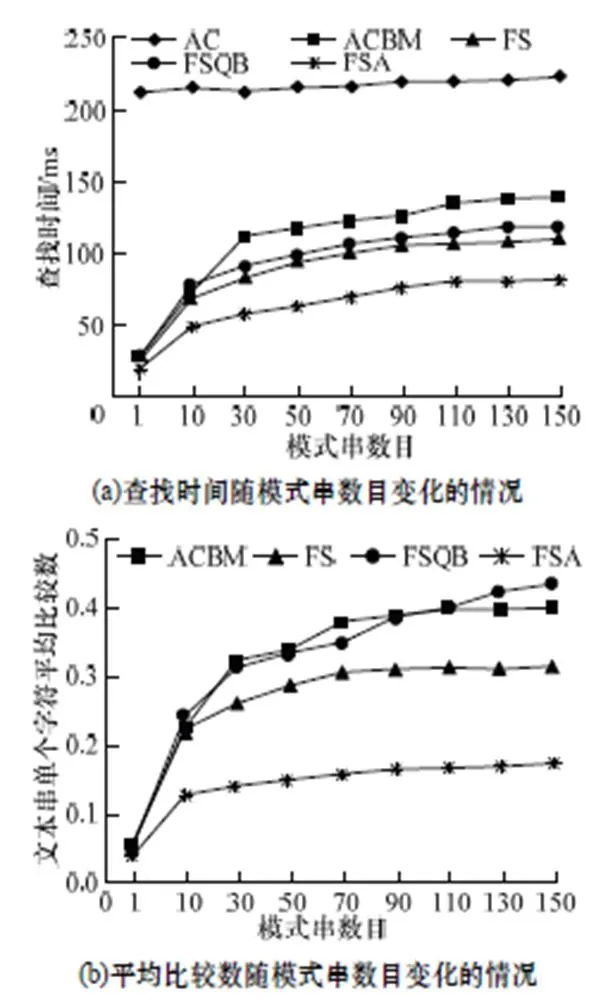
图6 查找时间和平均比较操作数
在算法执行的过程中,比较操作和状态转移是十分耗时的。与FS算法和FSQB算法相比,FSA算法进一步减少了比较操作和状态转移,进而在性能上获得了明显提升,如图7、图8所示,其中,模式串长度≥6。
可以看出,在模式串较少时,FS算法、FSQB算法和FSA算法都有较好的性能,但FSA算法平均代价更低,性能也更加稳定。这是因为在模式串较少时,模式串集合中出现的字符较少,FS算法和FSQB算法跳转函数的值较大,发现坏字符的概率也较大,1函数的优化作用十分明显;但随着模式串数的增加,单个字符出现的概率迅速升高,好后缀出现的概率不断增加,跳转函数的值和发现坏字符的概率则迅速减小,1函数的优化作用明显减弱。然而双字符出现的概率,及其随模式串数增加而增加的速率,都要比单字符小得多。因此,FSA算法使用改进的坏字符和坏前缀规则,增加了调用1函数的概率,使1函数在模式串较多时仍具有较大的值,且始终起绝大部分的优化作用,大幅减少了比较操作数。

图7 坏字符规则和好后缀规则优化效果对比

图8 平均收益和平均代价
6 结束语
本文将BMH算法和QS算法与FS算法相结合,提出了一种快速的多模式匹配算法。在匹配过程中能够尽可能多地跳过无需比较的字符,实现了不匹配时的连续跳转,使匹配效率大幅提高。实验结果表明,平均情况下本文算法有较好的性能,在各项评价指标上均优于ACBM算法、FS算法和FSQB算法,且对模式串数目的增加不敏感,性能更加稳定。本文算法可应用于多种领域,如入侵检测、信息检索等。后续研究工作将在提高匹配效率的基础上,对算法进行改进,以降低最坏情况下的时间复杂度。
[1] Knuth D E, Morris J H, Pratt V R. Fast Pattern Matching in Strings[J]. SIAM Journal on Computing, 1977, 6(2): 323-350.
[2] Boyer R S, Moore J S. A Fast String Searching Algorithm[J]. Communications of the ACM, 1977, 20(10): 762-772.
[3] Horspool R N. Practical Fast Searching in Strings[J]. Software Practice & Experience, 1980, 10(6): 501-506.
[4] Sunday D M. A Very Fast Substring Searching Algorithm[J]. Communications of the ACM, 1990, 33(8): 132-142.
[5] Aho A V, Corasick M J. Efficient String Matching: An Aid to Bibliographic Search[J]. Communications of the ACM, 1975, 18(6): 333-340.
[6] Walter B C. A String Matching Algorithm Fast on the Ave- rage[C]//Proc. of the 6th International Colloquium on Automata, Languages, and Programming. Graz, Austria: [s. n.], 1979.
[7] Fan Jang-Jong, Su Keh-Yih. An Efficient Algorithm for Matching Multiple Patterns[J]. IEEE Transactions on Knowledge and Data Engineering, 1993, 5(2): 339-351.
[8] 王永成, 沈 州, 许一震. 改进的多模式匹配算法[J]. 计算机研究与发展, 2002, 39(1): 55-60.
[9] Coit C J, Staniford S, McAlerney J. Towards Faster String Matching for Intrusion Detection or Exceeding the Speed of Snort[C]//Proc. of DARPA Information Survivability Conference. [S. l.]: IEEE Press, 2001.
[10]Lecroq T. Experimental Results on String Matching Algorithms[J]. Software Practice & Experience, 1995, 25(7): 727-765.
[11]Lewis D. Reuters-21578 Text Categorization Collection[EB/OL]. (1999-02-16). http://kdd.ics.uci.edu/databases/reuters21578/ reuters21578.html.
[12] Davies M. Word Frequency and Collocates Data[EB/OL]. (2012-04-20). http://www.wordfrequency.info.
[13] Albitz P, Liu C. DNS and BIND[M]. 5th ed. [S. l.]: O’Reilly Media, 2006.
编辑 顾逸斐
An Efficient Multiple Patterns String Matching Algorithm
XU Jia-ming1,2,3, LI Xiao-dong2, JIN Jian1,2, MA Ying4
(1. China Internet Network Information Center, Beijing 100190, China; 2. Computer Network Information Center, Chinese Academy of Sciences, Beijing 100190, China; 3. University of Chinese Academy of Sciences, Beijing 100190, China; 4. Ideal Research Institute of Information Technology, Northeast Normal University, Changchun 130117, China)
Combined with the advantages of BM-Horspool(BMH) algorithm and Quick-Search(QS) algorithm, an effective algorithm to perform multiple patterns matching in a string is proposed on the concept of Fan-Su(FS) algorithm. To reduce the number of comparisons, and improve the efficiency of matching, the proposed algorithm skips as many characters as possible and avoids useless state transitions, by making full use of the successful and failing information during the matching. Experimental results show that the proposed algorithm can achieve more excellent performance than the ACBM algorithm and FS algorithm. The time it takes for the proposed algorithm to search a string is only 10%~35% of the AC algorithm, 50%~60% of the ACBM algorithm, 70% of the FS algorithm, and 65% of the FSQB algorithm.
string matching; multiple patterns matching; finite state automata; algorithm complexity; network security; information retrieval
1000-3428(2014)03-0315-07
A
TP301.6
国家自然科学基金资助项目“多模态Web作弊间的统计机器学习方法研究”(61005029)。
许家铭(1987-),男,硕士研究生,主研方向:网络安全,下一代互联网技术;李晓东,研究员;金 键,高级工程师;马 盈,硕士研究生。
2013-01-15
2013-03-13 E-mail:xujiaming@cnnic.cn
10.3969/j.issn.1000-3428.2014.03.067
猜你喜欢
电机与控制应用(2022年4期)2022-06-27
学苑创造·B版(2022年3期)2022-04-02
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
数学大王·中高年级(2018年11期)2018-12-17
少儿美术(快乐历史地理)(2018年7期)2018-11-16
少林与太极(2018年8期)2018-08-26
雷达学报(2018年3期)2018-07-18
电源技术(2015年5期)2015-08-22
