
一种内核级多进程负载均衡会话保持方法
2014-06-02 06:34张颖楠顾乃杰彭建章王国澎魏振伟
计算机工程 2014年3期
张颖楠,顾乃杰,彭建章,王国澎,魏振伟
一种内核级多进程负载均衡会话保持方法
张颖楠1a,1b,1c,顾乃杰1a,1b,1c,彭建章1a,1b,1c,王国澎2,魏振伟1a,1b,1c
(1. 中国科学技术大学 a. 计算机科学与技术学院;b. 安徽省计算与通讯软件重点实验室; c. 中国科学技术大学中科院沈阳计算所网络与通信联合实验室,合肥 230027;2. 国家高性能集成电路设计中心,上海 201204)
针对多进程负载均衡无法保持会话的问题,提出一个基于epoll机制的内核级高效解决方法。对于每个新建立的连接,在epoll的通知机制中使用源地址哈希算法,由epoll通知哈希选出的进程接收此连接,期望通过为同一个IP地址的请求选择同一个负载均衡服务进程,保证该进程依据自身记录的会话信息将同一个客户的请求转发给同一个后端服务器。此外,通过分析多队列网卡的特性,给出维持收包发包中断、软中断、协议栈处理、用户态处理都在同一个核上的优化方法,以提高cache性能。实验结果表明,该方法能解决基于epoll的多进程负载均衡服务器的会话保持问题,并且在多核处理器多队列网卡环境下通过优化使cps提高12%,数据吞吐量提高4.6%。
多队列网卡;多核;epoll机制;源地址哈希;会话保持
1 概述
网络负载均衡[1]作为一种满足大规模并发访问服务的有效解决方案被广泛使用。会话保持是网络负载均衡服务器需要提供的重要功能,要求负载均衡服务器将携带相同会话信息的请求交给同一服务器处理。
为了充分利用多核处理器,现今的网络负载均衡服务器一般采用多进程并发模式。对于基于socket的负载均衡服务器,在多进程服务模式下,多个进程共享同一个socket,与该socket建立的连接被哪个进程接收具有不确定性,客户携带相同会话信息的多次请求被交由不同的进程处理,由于每个负载均衡服务进程分别保存各自的会话保持信息表,不能保证为同一客户的请求选择同一个后端服务器,因此无法做到会话保持。
由于携带同样会话信息的请求来自同一客户,本文提出了一种内核级的解决方案,旨在通过为同一客户请求选择同一用户态服务进程处理来实现会话保持,在epoll[2]机制中基于源地址哈希选择性地唤醒一个进程服务,以实现同一IP的请求交给同一进程处理,同时充分利用中断亲和性和进程亲和性对内核协议栈及网卡的发包收包过程进行优化。
2 相关工作
针对多进程并发负载均衡服务器的会话保持问题,一种很普遍的解决方案是多个进程之间共享会话信息表,这种方式并发访问的锁操作会带来较大的性能开销,并且从单进程向多进程升级时需要修改程序框架。文献[3]提出了一种方式,通过修改从内核空间到用户空间传递请求部分的逻辑,从侦听状态的socket请求接收等待队列上选择一个进程,将连接请求传递到用户空间,并保证同一个客户的请求发给同一个用户态服务进程。这种方法可以实现会话保持,也不存在锁操作,但现在大多数基于Linux的负载均衡服务器都是利用epoll机制高效地管理网络I/O事件的,这种基于Linux epoll机制的服务器程序在多进程模式下多会遇到惊群现象[4],当注册事件发生时唤醒所有进程竞争,最终结果也只有一个进程成功,造成资源浪费。而文献[3]并没有解决这种惊群问题。
针对Linux操作系统内核中数据包接收和发送过程,有以下优化手段:
针对单队列网卡,谷歌公司提出了Linux内核补丁RPS(Receive Packet Steering)[5],用软件模拟的方式实现了多队列网卡所提供的功能。对数据流通过hash进行归类,将多核系统中数据接收时的负载分布在不同的核上,充分利用多核,提高网络性能。
但RPS仅仅是把同一流的数据包分发给同一个核处理,这就有可能出现给该数据流分配执行软中断的核与操作该数据流的用户态程序所在的处理器核不一致,仍会对cache性能造成影响,因此在RPS的基础上谷歌公司又提出了RFS(Receive Flow Steering)[6]配合RPS使用,确保操作该数据流的应用程序与处理软中断在同一个核上,更加充分地利用cache。但RPS和RFS最适合在单队列网卡环境下 使用。
除了对数据包接收过程性能的优化,谷歌又提出了针对多队列网卡数据包发送过程的优化XPS(Transmit Packet Steering)[7]。
在发送数据包时,XPS会根据当前发送过程所在的核来选择对应的硬件发送队列,使得处理过程在同一个核上的数据包选择相同的发送队列,提高了cache的效率。但这种方法仍然会引起其他方面的cache行震荡,也就是说,网卡发送完数据包向其中一个核发出中断,这个核并不一定是处理数据包发送流程所在的核。
3 基于epoll的多进程负载均衡器会话保持
3.1 Linux内核的epoll机制
epoll[2]是一个异步事件的通知机制,可通知某个就绪的文件描述符事件,常用于网络I/O事件管理。
用户态程序通过epoll_create()创建epoll的句柄,即一个epoll监控容器,维护需要监控的socket事件;使用epoll_ctl()系统调用可以向容器中注册某个sock上的监控事件并设置回调函数;系统调用epoll_wait()将当前进程挂载在当前容器的等待队列上并进入可中断挂起状态,等待已注册事件发生后被唤醒。
在基于epoll机制的多进程服务器模型中,多个进程间共享侦听状态的socket,这些进程都把该socket加入到epoll关注事件中,并阻塞在epoll_wait上等待监控事件发生。
当设备就绪即socket注册事件发生时,调用设备等待节点上注册的唤醒回调函数,把就绪事件加入到就绪队列,并唤醒所有等待进程,这些进程在用户态竞争后续accept操作,但最终只有一个进程成功,这样便会发生惊群现象[4],造成资源浪费。而且所有共享此侦听状态socket的进程都被唤醒竞争此连接,最终成功建立连接的进程并不确定,无法做到同一个客户的请求交由同一个进程处理。基于以上分析和考虑,本文设计了在epoll唤醒回调机制中基于源地址哈希算法选择性地唤醒一个服务进程的方案。
3.2 基于源地址哈希的会话保持方案
本文期望可以按某种规则有选择地唤醒其中一个进程,而非全部,这样既可以避免惊群现象,也可以在规则设计合适的情况下实现来自同一个客户的请求交给同一个进程处理的会话保持需求。
如图1所示,本文采取对数据包源地址哈希来选择进程,在唤醒回调函数中进行规则判断,源地址哈希值落在某个等待进程上,就会将就绪事件插入到该进程的epoll就绪队列中,并唤醒该进程进行后续的操作。采用数据包源地址哈希的方法选择处理进程使得来自同一个客户的请求都交由同一个进程处理,从而满足会话保持的要求。
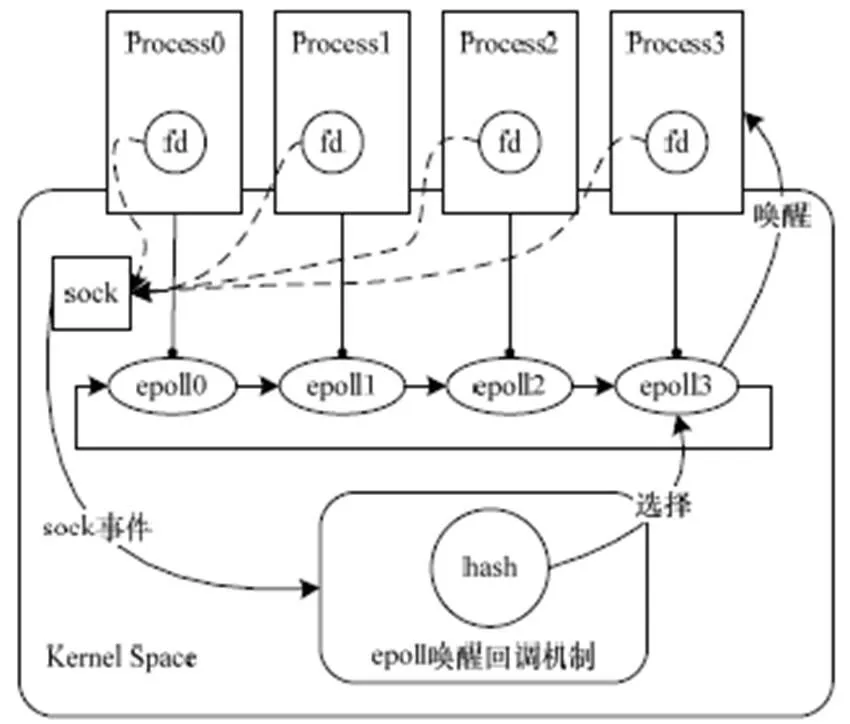
图1 epoll机制中源地址哈希选择唤醒进程
对于存在某个进程退出或者加入新的进程共享同一个socket的情况,本文加入一致性哈希算法[8]来减弱这种情况发生时对会话保持的影响。
因此,根据一致性哈希算法,整个会话保持方案如下:
(1)构造一致性哈希桶:对于同一个共享的socket,当每个进程向epoll容器中注册该socket的关注事件时,由于每个进程都拥有各自不同的epoll容器对象,因此将容器对象的地址值通过哈希映射到一个32位的键值上,也就是0~232-1次方的数值,可以把这个数值空间映射到一个首(0)尾(232-1)相接的圆环,如图2所示。

图2 一致性哈希算法在选择进程时的应用场景
(2)源地址哈希映射数据包:当有数据包到达时,根据数据包的源IP地址作哈希映射到同一个哈希数值空间中,即图2圆环。
(3)选择处理进程:在为数据包选择处理进程时,从数据包计算所得哈希值出发,在环形空间中按顺时针方向遇到的第一个进程哈希节点所对应的进程即处理该数据包的进程,如图2虚线箭头所指。
当有新进程加入或进程退出时,影响范围仅是很少部分,而非整个范围的震荡。
该方案包括2个哈希函数,分别为对进程节点的哈希和对数据包源地址哈希,为了尽可能将进程节点及数据包的哈希值分散到232即32位数值空间中,本文选择如下RSS哈希[9]算法:
ComputeHash(input[], N);
其中,input[]为epoll容器对象的地址值或数据包的源IP地址;N为输入数据的字节数。算法描述如下:
(1)当系统启动时,随机生成一个320比特位的K,存 储在数组中,数组每一个成员为一个字节,即K[0]K[1] K[2]…K[39]。
(2)初始化哈希结果值为0。
(3)对输入的每一比特位循环,如果该位为1,则将结果值异或K最左边的32位。
(4)左移一位K,进入步骤(3)的下一轮循环。
4 性能优化
本节针对多队列网卡和多核环境对会话保持方案从收包发包流程方面做了优化。
4.1 从网卡到用户态程序接收数据包流程的优化
多队列网卡有多个硬件接收队列,网卡在硬件层次直接对数据包使用哈希部件分流,放在不同的队列中,多队列网卡的哈希函数可以配置。既可以选择对源目的IP地址和源目的端口作哈希,也可以配置为仅依据源目的IP地址计算哈希值的方式,比如intel82580网卡[9]。
在接收数据包的过程中,为了充分利用局部性原理,降低cache刷新频率,提高其命中率,需要尽可能满足如下条件:
(1)将特征相似的数据包分配给同一个CPU处理。
(2)同一个数据包的硬件中断处理过程、软中断处理过程以及用户态应用程序接收处理数据包的过程在同一个核上。
基于上述条件,期望在多队列网卡多核环境下,网卡硬件哈希为数据包选择的接收队列绑定的核与epoll的唤醒回调函数中源地址哈希选择的处理进程绑定的核是同 一个。
配置网卡使用仅对数据包源目的地址哈希的函数选择队列时,由于数据包目的地址不变,相当于在网卡硬件层对数据包做源地址哈希,交给不同的硬件队列。在这种配置下,将用户态进程绑定于固定的处理器核,利用中断亲和性为每个硬件队列绑定唯一的处理器核,只需记录下数据包硬中断处理过程所在的核,向上传递,在epoll层次选择同样处理器核上的进程唤醒,如图3所示,这个进程已然是源地址哈希选择的结果,满足会话保持的要求。

图3 数据包接收过程中期望的接收队列、CPU、进程间状态
本文结合第3节中的会话保持方案将数据包接收流程修改如下:
(1)网卡接收数据包经过哈希落在某个硬件队列上。
(2)网卡发出硬中断给该队列所绑定的CPU核,将数据包挂在该CPU的处理队列上。
(3)记录下处理硬中断的CPU核存储于skbuff(数据包在内核态的存储形式),并触发软中断过程执行内核协议栈的解析与处理。
(4)当该数据包为SYN包并且sock处于LISTEN状态时,拷贝数据包的CPU核到sock中,向上层传递此记录,并触发sock上挂载的设备等待队列调用唤醒回调函数。
(5)在使用epoll机制的情况下,唤醒回调函数的主要工作是挂载就绪事件到就绪队列并唤醒等待进程。在选择用户态进程唤醒时,根据下层记录的处理器核,选择性地只唤醒绑定在该核上的用户态进程。
(6)判断当前处理器核绑定的进程:如果当前处理器核上绑定了唯一的进程,则唤醒该进程;如果当前处理器核绑定了不止一个进程,则获取数据包的源IP地址作哈希,根据哈希值从该处理器核绑定的所有进程中选择一个唤醒;如果当前处理器核没有绑定进程,则将下一个处理器核作为当前处理器核,重新执行操作(6)。
4.2 从用户态程序到网卡发送数据包流程的优化
数据包发送过程包括:应用程序将响应数据包递交给内核;内核网络协议栈封装数据包向下层递送;选择发送队列;网卡发送队列中断处理。其中,网卡发送中断处理的主要工作是删除数据包或重发数据包,该中断在网卡发送数据完数据包时触发。
为了在发送数据包过程中充分利用多队列网卡和多核环境,提高发送数据的局部性,最理想的情况是将上述一系列发送数据包的流程都放在同一个处理器核上,如图4所示。关键就是要为数据包选择合适的硬件发送队列,使得硬件发送队列中断绑定的处理器核与数据包在内核协议栈中处理过程所在的核为同一个。

图4 数据包发送过程中期望的进程、CPU、发送队列间的状态
使用中断亲和性绑定发送队列到唯一的处理器核上,在此前提下,本节设计的发送队列选择方法如下:
(1)获取当前数据包内核协议栈处理过程所在的 CPU核。
(2)判断该CPU核上绑定的发送队列个数。
(3)如果处理器核对应唯一的发送队列,则返回此队列号——在这种情况下,硬件发送队列发送成功或失败后触发中断,中断处理过程删除数据包或重发数据包等操作都集中在之前发送过程的同一个核上完成。
(4)如果处理器核上绑定的队列数大于1,则依据数据包的哈希值从绑定的队列集合中选择。
(5)如果处理器核上绑定的队列数等于0,则依据数据包的哈希值从网卡所有可用队列中选择。
5 实验结果与分析
5.1 实验环境
为应对压力测试,需要提供高性能的服务器作为测试机,以使负载均衡处理不会成为瓶颈;选用多队列网卡使数据包收发流程充分利用优化特性。测试环境如表1所示。

表1 测试环境
5.2 会话保持测试
HAProxy为基于epoll的负载均衡软件,存在多进程会话不能保持的问题,本节选择该软件作为测试例程。在不同的客户端上使用curl工具向HAProxy监听的地址发送http请求,发现同一个客户发送的请求交给了同一个进程处理,表明实现了多进程会话保持的目的。
同时利用测试仪环境测试请求处理转发的正确性,图5所示的测试结果表明,在压力测试下,数据包处理的正确率为100%。

图5 基于修改后内核的数据包处理结果
5.3 性能测试
5.3.1 实验方法
为测试本文方法在大规模访问压力下并未限制整体性能相反有所提高,采用了如下实验方法:(1)关闭中断负载均衡irqbalance服务;(2)内核关闭RPS;(3)设置网卡中断亲和性:使网卡队列与处理器核绑定;(4)设置进程亲和性:进程分别绑定在不同的处理器核上;(5)测试仪配置:模拟100个客户端,6个服务器端,1个负载均衡代理服务器HAProxy。客户端同时向HAProxy发送请求,测试HAProxy的响应速度和吞吐量。
5.3.2 结果分析
每秒处理连接数(cps)反映测试程序HAProxy在当前内核及硬件平台下处理请求的速度。图6和图7为cps的测试结果,纵轴表示每秒新增连接个数,横轴为时间轴,基于本文修改后的内核运行HAProxy每秒处理请求数平均在93 000左右,而未修改2.6.35内核下cps平均在83 000左右,表明修改后的内核处理速度有12%的提升,更能充分利用多核和多队列网卡硬件环境。吞吐量(throughout)表示每秒处理的数据总量。利用IxLoad测试仪模拟100个客户端,向HAProxy请求大小为1 MB的数据。测试结果如 图8和图9所示,纵轴表示每秒处理的数据总量,横轴为时间轴,在一段时间的试探期后数据会稳定在一定范围内。修改前的内核运行HAProxy吞吐量基本都维持在2.2 Gb左右,修改后平均维持在2.3 Gb,提升在4.6%左右。
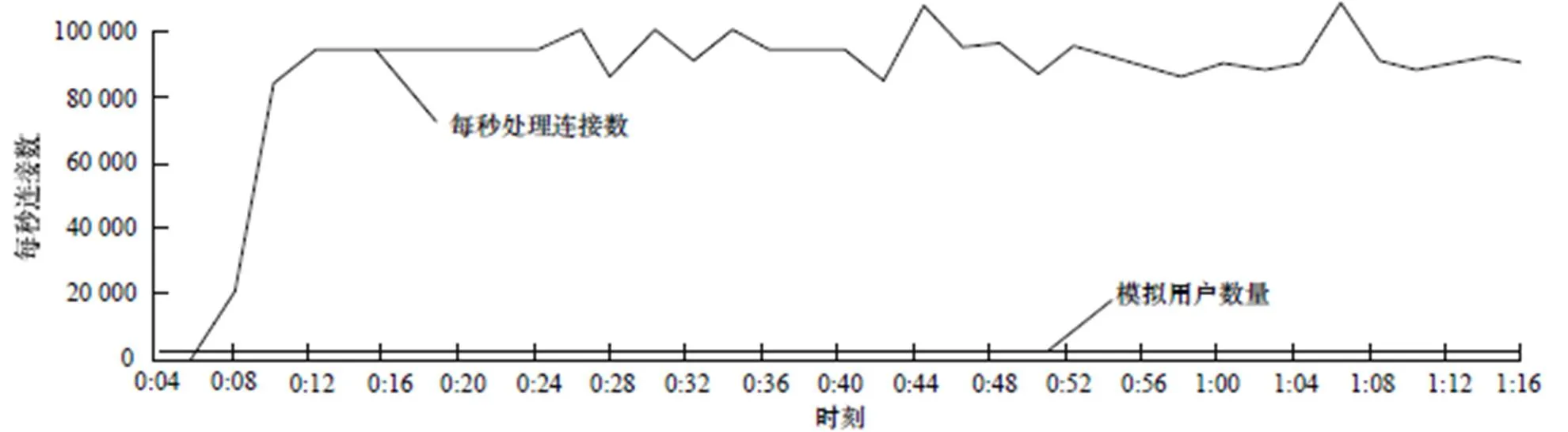
图6 基于修改后内核的每秒处理连接数
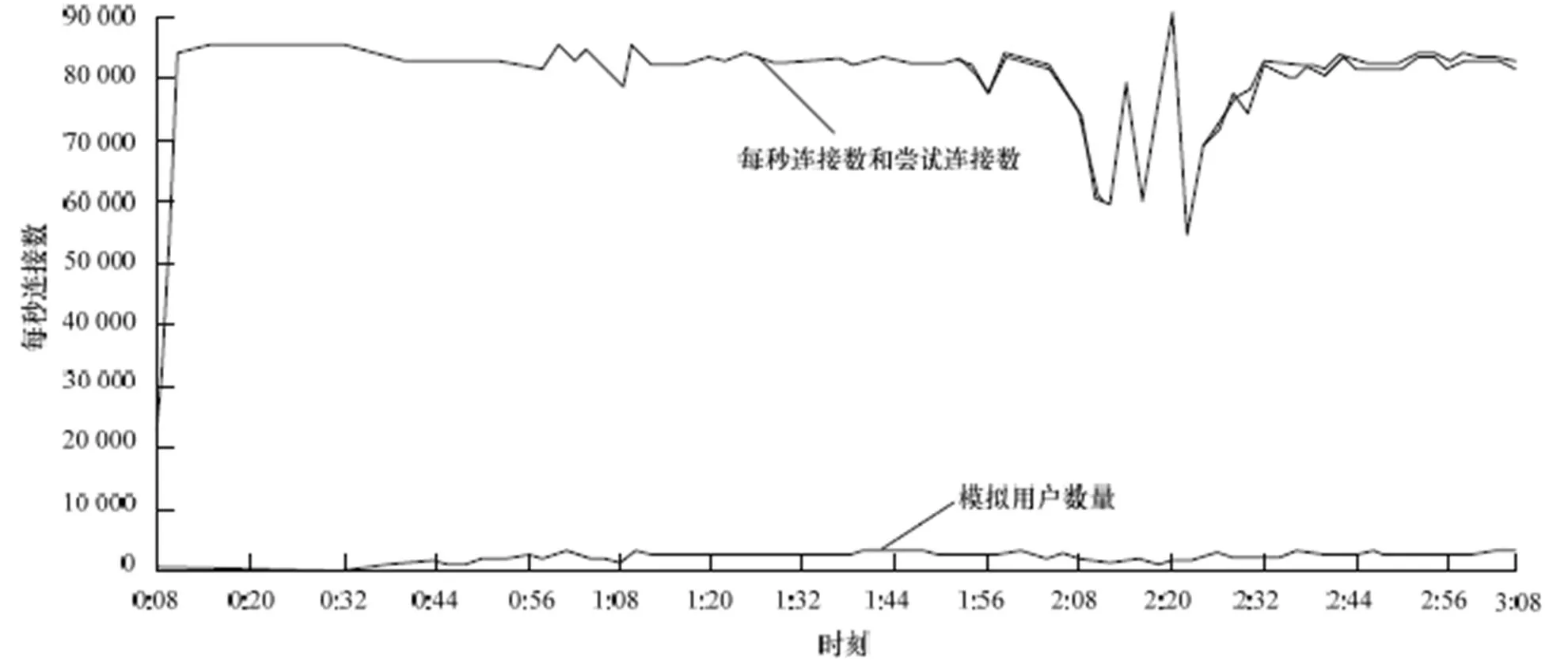
图7 基于原2.6.35内核的每秒处理连接数
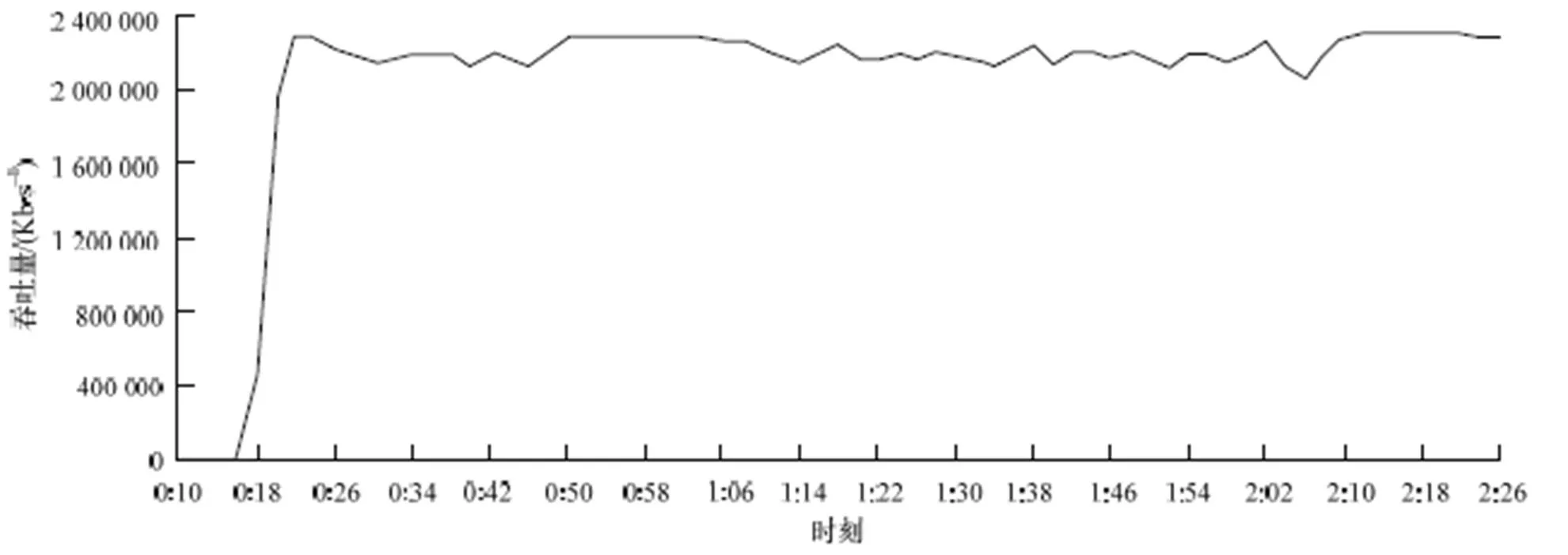
图8 基于修改后内核的吞吐量
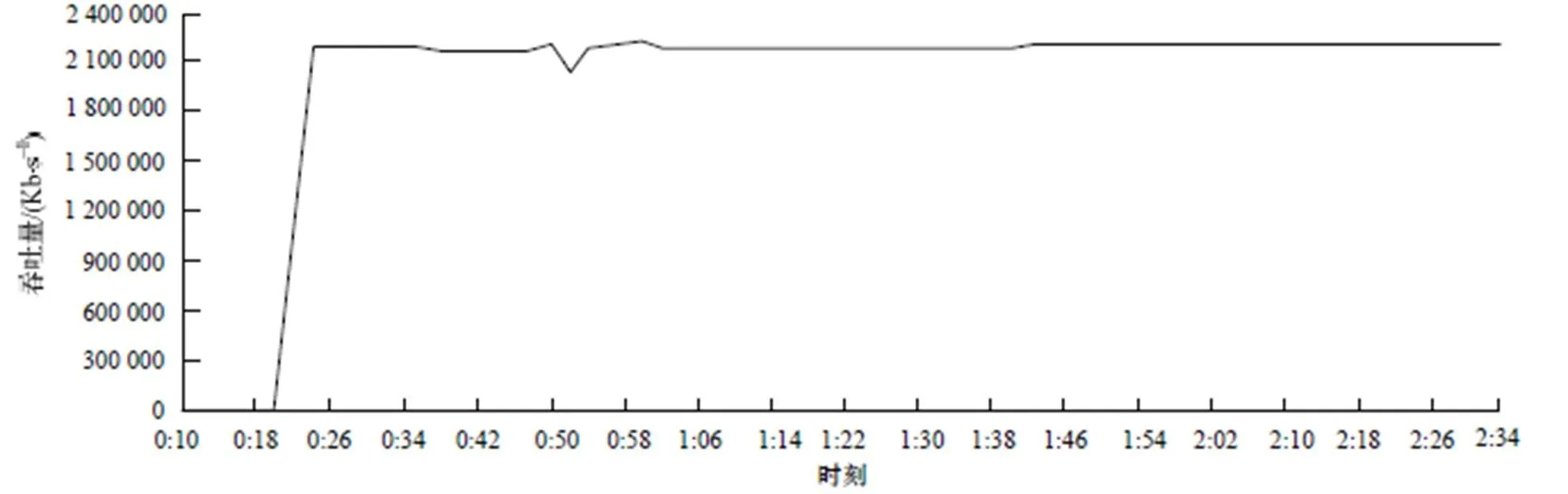
图9 基于原2.6.35内核的吞吐量
6 结束语
本文提出一种在epoll机制中根据数据包源地址哈希结果选择性唤醒处理进程的方法,有效地解决了基于epoll的多进程负载均衡服务器的会话保持问题。与以往的研究工作相比,在满足会话保持要求的同时解决了epoll机制在多进程环境下多出现惊群现象的问题,而且基于修改后的内核将单进程的负载均衡服务向多进程扩展时也不需要大规模修改用户态服务程序。此外,对多队列网卡和多核处理器环境下的会话保持方案做了针对性优化,实验结果显示,优化方案对于上述网络环境有很好的性能提升。但本文的解决方法仍然基于共享的sock,在内核态中共享的sock依旧会带来互斥锁的开销,不利于网络性能的进一步提升。下一步工作的主要方向是期望解决多进程侦听在同一个地址上提供相同的服务时,如何能够更有效地利用多核,减少内核中锁的开销,提高并行性。
[1] 李 辉. 网络服务器负载均衡的研究与实现[D]. 大连: 大连海事大学, 2003.
[2] Libenzi D. Improving (Network) I/O Performance[EB/OL]. (2002-10-30). http://www.xmailserver.org/Linux-patches/nio- improve.html.
[3] Liu Xi, Pan Lei, Wang Chongjun, et al. A Lock-free Solution for Load Balancing in Multi-core Environment[C]//Proc. of the 3rd International Workshop on Intelligent Systems and Applications. Wuhan, China: [s. n.], 2011: 1-4.
[4] Molloy S P, Lever C. Accept() Scalability on Linux[C]//Proc. of USENIX Annual Technical Conference. San Diego, USA: [s. n.], 2000: 121-128.
[5] Herbert T. RPS: Receive Packet Steering[EB/OL]. (2010-09- 01). http://1wn.net/Articles/361440.
[6] Herbert T. RFS: Receive Flow Steering[EB/OL]. (2010-09-01). http://1wn.net/Articles/381955.
[7] Herbert T. XPS: Transmit Packet Steering[EB/OL]. (2010-10- 26). http://1wn.net/Articles/412062.
[8] Karger D, Lehman E, Leighton T, et al. Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web[C]//Proc. of the 29th Annual ACM Symposium on Theory of Computing. New York, USA: ACM Press, 1997: 654-663.
[9] Intel Corporation. Intel 82580EB/82580DB Gigabit Ethernet Controller Datasheet[EB/OL]. (2012-09-07). http://www.intel. com/content/www/us/en/ethernet-controllers/82580-eb-db-gbe-controller-datasheet.html.
[10] Ixia Corporation. IxLoad[EB/OL]. (2011-07-07). http://www. ixiacom.cn/products/applications/ixload.
[11] Tarreau W. HAProxy: The Reliable, High Performance TCP/ HTTP Load Balancer[EB/OL]. (2011-09-10). http://haproxy. 1wt.eu.
[12] 周少涛. 基于HAProxy的TCP长连接复用的研究与实 现[D]. 广州: 华南理工大学, 2011.
编辑 任吉慧
A Kernel Level Session-persistence Method for Multi-process Load Balancing
ZHANG Ying-nan1a,1b,1c, GU Nai-jie1a,1b,1c, PENG Jian-zhang1a,1b,1c, WANG Guo-peng2, WEI Zhen-wei1a,1b,1c
(1a. School of Computer Science and Technology; 1b. Anhui Province Key Laboratory of Computing and Communication Software; 1c. USTC&SICT Network and Communication Joint Laboratory, University of Science and Technology of China, Hefei 230027, China; 2. National High Performance IC Design Center, Shanghai 201204, China)
This paper proposes an efficient method at the kernel level to solve the problem how to maintain the session in multi-process load balancing. In the wakeup-callback mechanism of epoll, this method wakes up a certain service process selectively to process the packet and accept this connection according to the source address hash algorithm. It hopes that the requests sharing the same IP address are responded by the same service process. So the requests from the same client are forwarding to the same backend server according to the session information kept in this load balancing process. This paper also devotes to optimize the performance of the procedure of receiving and sending packets. It is an intended way to keep this whole process on the same CPU core to reduce the refresh rate of the CPU cache. Experimental results reflect that the method in this paper achieves the objective to keep the session and also increases cps by 12% and throughput by 4.6% which is based on multi-queue NIC and multi-core processor.
multi-queue network card; multi-core; epoll mechanism; source address hash; session-persistence
1000-3428(2014)03-0076-06
A
TP393.03
“核高基”重大专项(2009ZX01028-002-003-005);高等学校学科创新引智计划基金资助项目(B07033)。
张颖楠(1988-),女,硕士、CCF会员,主研方向:网络负载均衡;顾乃杰,博士、博士生导师;彭建章,博士;王国澎、魏振伟,硕士。
2013-03-19
2013-04-23 E-mail:zyn@mail.ustc.edu.cn
10.3969/j.issn.1000-3428.2014.03.016
猜你喜欢
电脑爱好者(2020年20期)2020-10-22
网络安全和信息化(2019年1期)2019-02-15
疯狂英语(双语世界)(2017年4期)2017-04-28
海外华文教育(2016年3期)2017-01-20
工业设计(2016年8期)2016-04-16
电脑爱好者(2015年15期)2015-09-10
电脑爱好者(2015年13期)2015-09-10
电子设计工程(2014年12期)2014-02-27
山西大同大学学报(社会科学版)(2014年5期)2014-01-23
海外华文教育(2014年4期)2014-01-20
