
基于敏感特征选择与流形学习维数约简的故障诊断
2014-05-25 00:34:02苏祖强汤宝平姚金宝
振动与冲击 2014年3期
苏祖强,汤宝平,姚金宝
(重庆大学机械传动国家重点实验室,重庆 400030)
基于敏感特征选择与流形学习维数约简的故障诊断
苏祖强,汤宝平,姚金宝
(重庆大学机械传动国家重点实验室,重庆 400030)
针对故障诊断中特征集包含非敏感特征和维数过高的问题,提出基于特征选择(Feature Selection,FS)与流形学习维数约简的故障诊断方法。提出一种改进的核空间距离测度特征选择方法(Improved Kernel Distance Measurement Feature Selection,IKDM-FS),在核空间中计算样本类间距离和类内散度,优选出使样本类间距大、类内散度小的特征,并根据特征的敏感程度对特征进行加权。通过线性局部切空间排列算法(Linear Local Tangent Space Alignment,LLTSA)对由敏感特征组成的特征子集进行特征融合,提取出对故障分类更加敏感的融合特征,并输入加权k最近邻分类器(Weighted k Nearest Neighbor Classifier,WKNNC)进行故障识别。WKNNC具有比k最近邻分类器(k Nearest Neighbor Classifier,KNNC)更加稳定的识别精度。最后,通过滚动轴承故障模拟实验验证了该方法的有效性。
故障诊断;特征选择;改进的核空间距离测度;线性局部切空间排列;加权k最近邻分类器
要对机械故障进行更加准确、有效地诊断,就必须要提取大量的故障特征,获得尽可能多的、从各个方面反映故障的特征信息。但是,这会造成特征集的维数过高,同时还可能引入非敏感特征,严重地影响了故障诊断精度的进一步提高。
故障特征往往都是非线性的,因此,使用传统的线性降维方法来解决特征集维数过高的问题,不能得到很好的效果。最近,不少专家、学者将非线性流形学习方法引入到故障诊断中,实现对高维故障特征集的维数约简,并取得了很好的效果,如:Li等[1]利用监督局部线性嵌入算法实现故障特征集的维数约简,提高了故障诊断的精度;蒋全胜等[2]利用拉普拉斯特征映射算法进行特征映射,在降维的同时有效地保留了原始特征集全局分布的几何结构信息;李锋等[3]则通过线性局部切空间排列算法对故障特征集进行维数约简,以获得更好的故障诊断效果,等。但是,非线性流形学习算法仍然无法消除非敏感特征的影响,导致故障诊断精度难以进一步提高。
本文提出基于特征选择(FS)与流形学习维数约简相结合的故障诊断方法:首先,采用改进的核空间距离测度特征选取方法(IKMD-FS)优选出特征集中对故障敏感的特征组成敏感特征子集,并根据特征的敏感程度对其进行加权;然后,通过线性局部切空间排列算法(LLTSA)[4]对优选出的敏感特征子集进行降维,以获取对故障更加敏感的融合故障特征。最后,通过加权k最近邻分类器(WKNNC)[5]进行故障模式识别。
1 改进的核空间距离测度特征选择
1.1 核空间距离测度特征选择
对小样本集和线性不可分数集进行特征选择时,基于传统的距离测度特征选择方法难以取得满意的效果。为了克服这一不足,蔡哲元等[6]基于核方法提出基于核空间距离测度的特征选择方法(Kernel Distance Measurement Feature Selection,KDM-FS),将核空间距离作为可分性判据,认为使核空间中不同类样本间距离大的特征具有更好的分类性能。
核方法常用于支持矢量机[7]来对线性不可分数据集进行分类,其基本思想是通过映射函数φ(x)将样本从线性不可分的低维空间非线性地映射到线性可分的高维核空间进行处理,而核空间中向量的点积可由核函数得到:K(x,y)=(φ(x),φ(y))。因此,可根据核函数得到任意两点p1,p2间的核空间距离Dk(p1,p2):

常用的核函数有线性核函数、多项式核函数和高斯径向基核函数等。其中高斯径向基核函数具有单一的对数形式,能够极大地削弱数据集中可能包含的离群点对特征选取的影响,且计算方便、参数较少,因此此处选用高斯径向基核函数[6],其形式如式(2)所示:
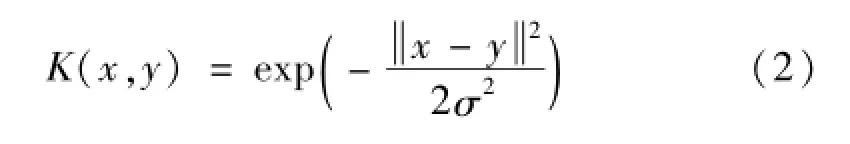
当选用高斯径向基核函数进行计算时,式(1)可进一步化简为如下形式:
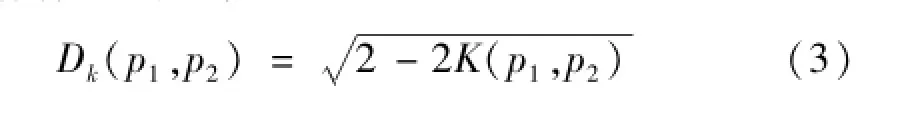
在样本点核空间距离的基础上,可以计算得到第a(a=1,…,C)类样本集和第b(b=1,…,C)类样本集间的平均距Dabk,C为样本类别数:
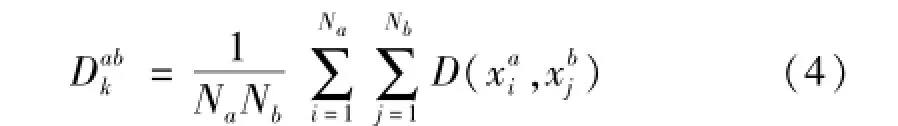
式中:Na,Nb分别表示第a类样本集和第b类样本集的样本数,xai代表第a类样本集中的第i个样本,xbj代表第b类样本集中的第j个样本。而基于核方法的可分性判据Jk,即核空间中不同类样本集间距离的平均值,可由下式计算得到:
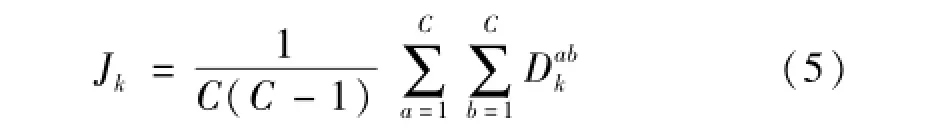
根据蔡哲元等[6]的经验,在对核参数σ进行选取时,可在各类样本集中随机选择10组样本,对每组样本在参数空间[-6,6]中找到使其核空间距离测度最大的值作为核参数,将10组样本核参数的平均值作为最终的核参数。虽然KDM-FS克服了传统方法的一些不足,在选择精度上有了一定程度的提高,但是由于没有考虑样本类内聚集程度对特征可分性的影响,这样可能无法将非敏感特征完全排除。
1.2 改进的核空间距离测度特征选择
针对KDM-FS的不足,本文提出了IKDM-FS,将核空间中样本类间距离与样本类内散度一起作为可分性判据,认为使样本在核空间中类间距大且类内散度小的特征具有更好的分类性能。改进算法中样本类间距离计算方法与1.1节相同,而核空间中样本类内散度的计算过程如下:
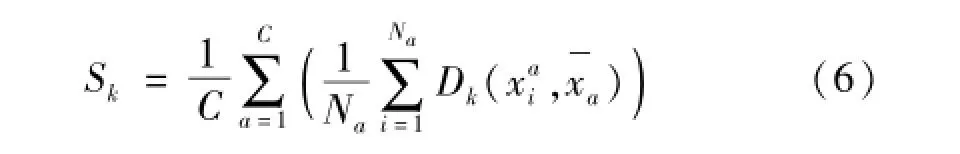
式中:Na和xai的定义与1.1节相同,而为第a类样本集的均值,计算如下:
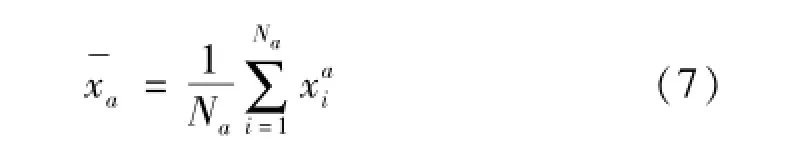
最后,通过计算核空间中类间距离和类内散度的比值来判定特征的敏感程度:

其中:ξl为第l(l=1,…,Nf)个故障特征的特征敏感度,Nf为故障特征个数。为方便进行后续处理,此处对特征敏感度ξl进行了归一化处理,将特征敏感度值转化到值域空间[0,1]上,归一化后的敏感度值仍记为ξl:
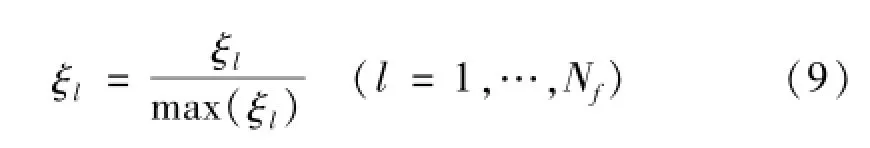
最后,通过归一化的特征敏感度ξl值优选出敏感特征,显然ξl值越大的特征对故障越敏感。
1.3 特征加权
虽然通过特征选择排除了大量的干扰特征和非敏感特征,使得流形学习的降维效果有所改善,但是在使用流形学习算法进行非线性维数约简时,通常给所有特征赋予相同的权值1,即认为所有特征都具有相同的重要程度[1-3],这使得敏感特征的优越性无法得到充分地体现。因此,为了使更加敏感的特征在故障诊断中起更重要的作用,本文提出根据特征的敏感程度对特征进行加权处理,将ξl作为权值给特征进行加权,使得在对数据集进行非线性维数约简时每个特征的重要程度有所不同。本文以所采用的LLTSA为例说明特征加权的作用。LLTSA通过主成分分析[8]算法来获取特征集的局部流形结构,主成分分析算法根据特征方差大小来判定特征包含信息量的多少,而给敏感特征加权能使其方差相对于其它敏感程度较低的特征而言增大,如下式所示:
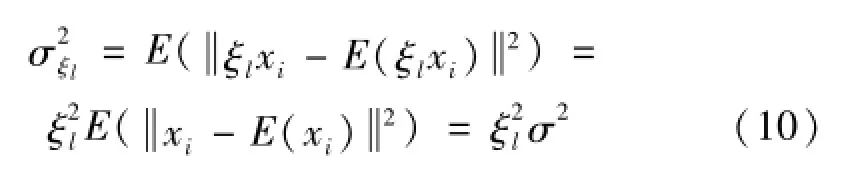
其中:σ2ξl为加权后样本集的方差,σ2=E(xi-E(xi)2),(i=1,…,N)为加权前的方差,xi为
C样本集的第i个样本,N=a∑=1Na为样本集的样本总数。因此对特征进行加权相当于使低维子空间的坐标轴偏向于更敏感的特征,使其在故障诊断中起更加重要的作用。
2 线性局部切空间排列算法
LLTSA是一种十分有效的非线性维数约简方法[4],其基本思想是通过样本点邻域的低维切空间来描述流形局部几何结构,然后将低维切空间进行全局排列得到样本点的低维全局坐标。该方法是对局部切空间排列算法[9]的线性逼近,具有很好的推广和聚类能力,同时具有显性的映射关系,能够将新增样本点直接映射到所属低维子空间。LLTSA的实现主要包含以下几个步骤:
(1)构造邻域:对每个样本点xi(i=1,…,N)确定其k个近邻点Xi=[xi1,xi2,…,xik],N为样本集包含的样本个数。
(2)提取局部信息:为了保证Xi的局部结构,采用切空间来对Xi的结构进行线性逼近,即:
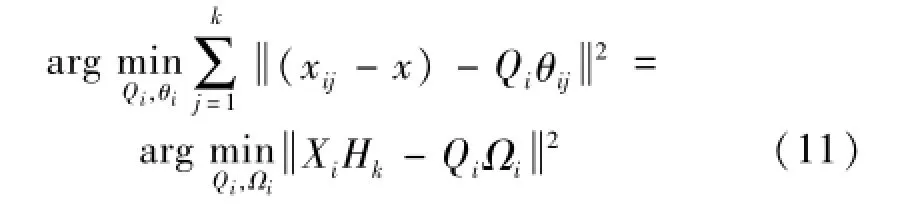
其中:x为局部邻域Xi的中心点,Hk=I-eeT/k为中心化矩阵。最优的局部映射Qi由XiHk的d(d为低维流形子空间的维数)个最大特征值对应的特征向量构成。通过Qi即可得到Xi的局部线性逼近Ωi=[θi1,θi2,…,θik],即Ωi=QTiXiHk,其中θij为xij的局部低维表述。
(3)局部切空间全局排列:局部切空间全局排列的目标是找到一组低维坐标T=[t1,…,tN],使得将所有样本点xi的局部切空间Ωi映射到全局低维坐标Ti=[ti1,…,tik]的误差之和最小,即:
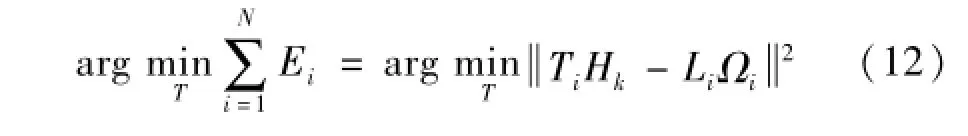
式中:Li为将Ωi映射到Ti的映射矩阵。由上式易得,当Li=TiHk(I-Ω+iΩi)时映射误差最小。其中Ω+i为Ωi的Moore-Penrose广义逆。若令Si(i=1,…,N)为一个0-1选择矩阵则Ti=TSi,记Wi=Hk(I-Ω+iΩi),(i=1,…,N),则式(12)可进一步转化为:
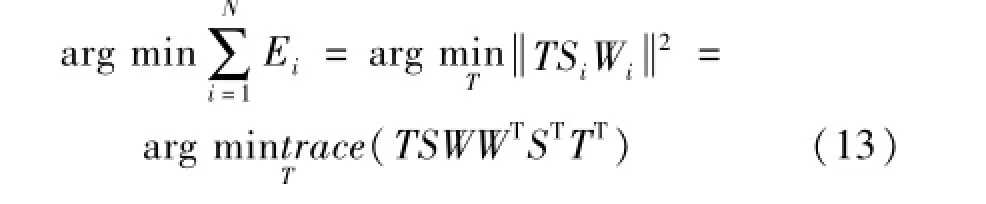
其中:S=[S1,…,SN]、W=dig(W1,…,WN)。为了保证T的唯一性,给其添加了一个约束I=TTT,且考虑到最终需要得到一个显性的映射关系:T=ATXHN,若令B=SWWTST,则可将式(13)的最小化问题转化为广义特征值的求解:
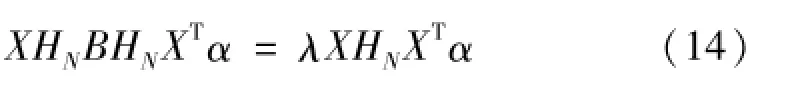
与上式中最小的d个广义特征值相对应的广义特征向量αi,…,αd组成的矩阵即为映射矩阵A。通过映射矩阵A可以将样本集从高维空间映射到低维流形子空间:T=ATXHN,从而实现对高维特征集的维数约简得到低维的融合特征子集。融合特征集比原始高维特征子集更加敏感,且特征间相互独立,具有很好的可分性,将其输入分类器即可识别出故障的类别。
3 加权k最近邻分类器
WKNNC[5]是k最近邻分类器(KNNC)[10]的改进算法。若设Y={(yi,li),yi∈Rd,i=1,…,N}是由N个样本组成的训练样本集,li(i=1,…,Ks)是样本的类别标签,yi为测试样本,Ks为样本类别数,则分类器的目标是识别出测试样本yt的类别lt。
传统KNNC的原理是根据测试样本和训练样本之间的距离,在训练样本集中选取出离测试样本最近的kc个样本yj(j=1,…,kc),而在这kc个训练样本中拥有最多样本的样本类即为测试样本的类别,如下式所示:
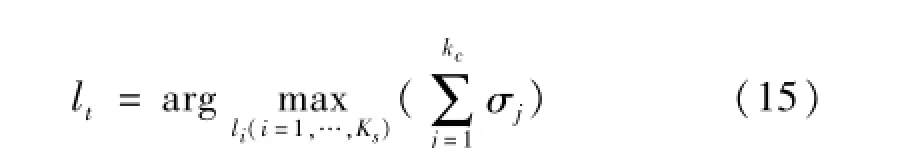
其中:
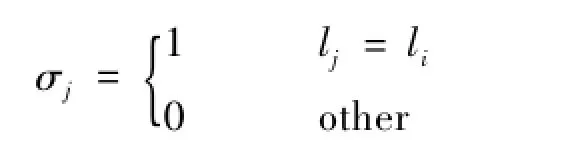
KNNC直接根据训练样本集在测试样本的kc个最近邻样本中所包含的样本个数来确定测试样本的类别,其识别精度容易受到分类器邻域大小kc值的影响,这种影响在样本集分布发散时表现得尤为明显,且分类器的最佳领域大小kc也难以确定。因此,Hechenbichler等[5]提出了WKNNC,对测试样本yt和其近邻训练样本yj同类的概率进行累加,得到yt为类别li(i=1,2,…,K)的后验概率,将后验概率最大的训练样本类作为测试样本的类别:
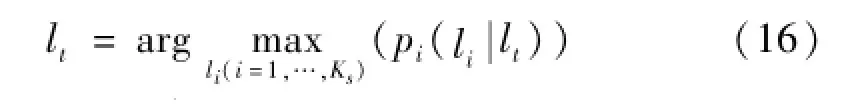
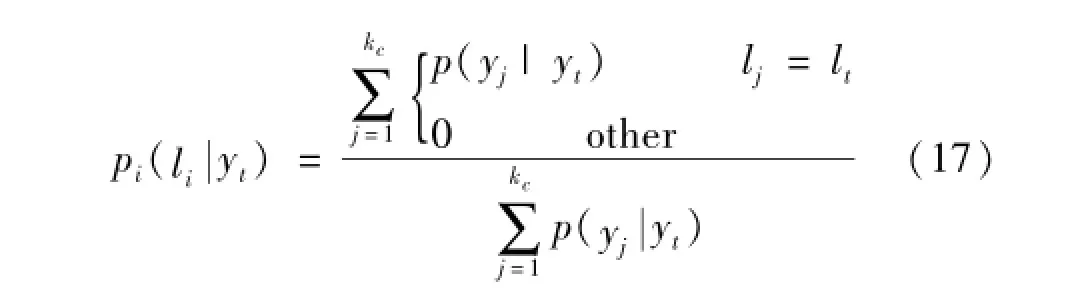
式中:lj(j=1,…,kc)代表yt的第j个近邻样本的类别。而在计算测试样本yt和训练样本yj同类的概率时,选用高斯核函数将标准化后的yt与yj的距离D(yt,yj)转化为样本yt和yJ同类的概率[5,11]:
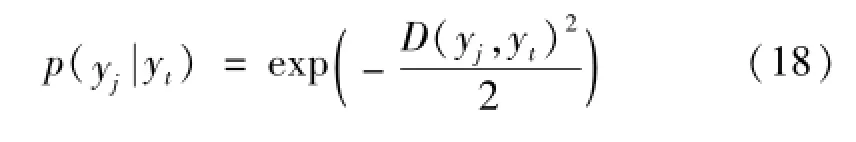
其中:D(yt,yj)为标准化后的yt与yj的距离,其计算过程为:
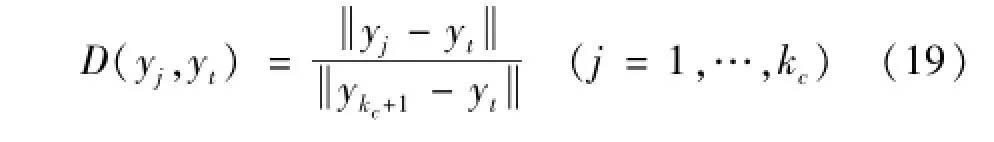
式中yk+1是测试样本yt的第k+1个最近邻样本。由于WKNNC是通过后验概率大小来判断测试样本类别的,因此较KNNC而言具有更加稳定的识别精度,受邻域大小选取的影响小。
4 故障诊断方法实现
本文选取11个时域特征(均值、方差、均方根、峰值、偏态系数等)和13个频域特征(中心频率、频谱均值、频谱均方根、频率方差等)组成原始特征集,特征集详细情况见文献[10]。
本文提出的故障诊断方法实现过程如图1所示。
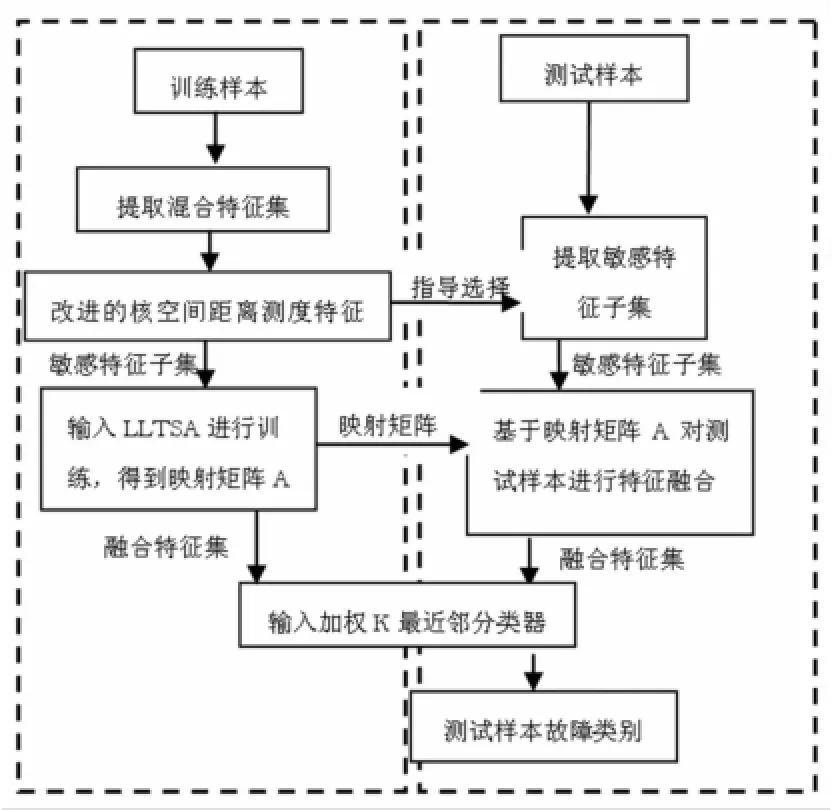
图1 故障诊断算法的实现Fig.1 Flow chart of the fault diagnosismethod
本文方法的实现过程主要有以下几个步骤:
(1)基于IKDM-FS优选出过故障敏感的特征、根据敏感程度对其加权组成敏感特征子集,并得到高维故障样本集X={xi∈RD,i=1,2,…,N},其中xi为由敏感特征组成的故障样本,D为敏感特征的个数。
(2)将高维故障样本集输入LLTSA进行训练,得到映射矩阵A及故障样本的低维全局坐标{yi∈Rd,i=1,2,…,N},其中d为融合特征的个数。而低维的故障样本集及其类别标签则组成了WKNNC的训练样本集{yi,li}。
(3)通过映射矩阵A对测试样本进行特征融合,将结果输入WKNNC得到测试样本的故障类别。
5 实验验证
5.1 实验数据
本文的实验数据来源于凯斯西储大学(Case Western Reserve University)电气工程实验室的滚动轴承实验数据。实验轴承型号为6205-2RS,轴承内径为25 mm,外径为52 mm,厚度为15 mm,节径为39.04 mm。实验台主轴转速为1 750 r/min,采样频率为48 kHz,振动信号由安装在轴承座上的加速度传感器获取。按时间顺序以4 028个采样值为1组,分别测取损伤尺寸为0.355 6 mm的轴承外圈故障、内圈故障、滚动体故障(严重)和故障尺寸为0.177 8 mm的轴承滚动体故障(轻度)及正常状态下的振动信号各50组(共250组),以其中的30组作为训练样本,剩余的20组作为测试样本。图2为轴承各状态下振动信号的时域波形。
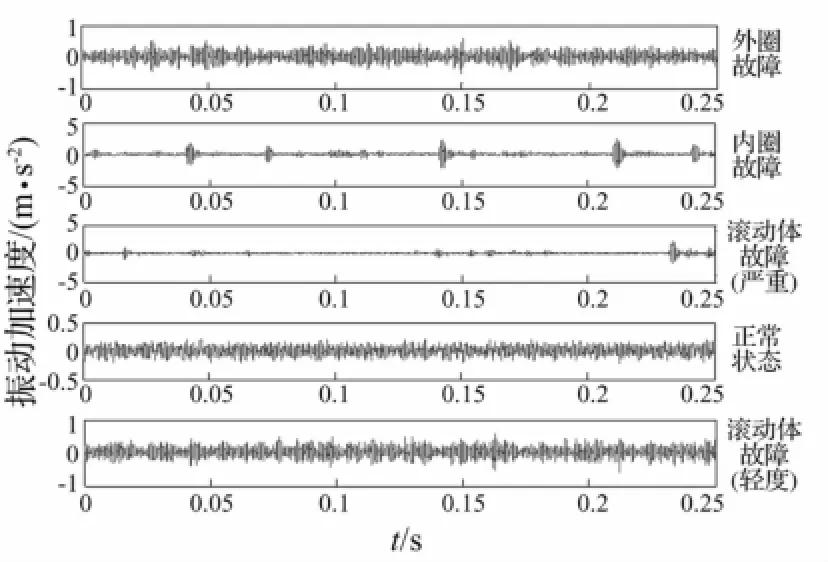
图2 轴承各状态下振动信号的时域波形Fig.2 The time-domain waveform of the 5 kinds of fault signals
5.2 实验结果
图3为两种特征选取方法的计算结果,本文选取敏感程度ξl大于0.5的特征做为敏感特征。从图3的结果可以看出:基KDM-FS优选出的敏感特征为:第2、3、4、5、10、11、12、13、14、23个特征,共10个特征,记为X1;而本文提出的IKDM-FS优选出的敏感特征为:第2、3、4、5、7、9、10、12、13个特征,共9个特征,记为X2。同时,根据特征的敏感程度ξl对特征子集X1、X2中的特征进行加权处理,加权后的特征子集仍记为X1、X2。
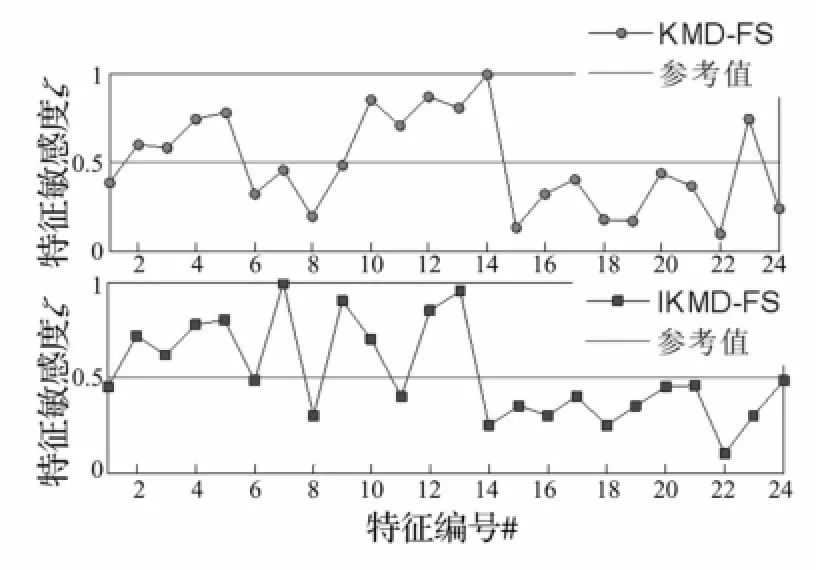
图3 特征选取结果Fig.3 Result of the feature selection
分别将X1,X2和原始特征集(X)输入LLTSA进行特征融合,LLTSA有两个参数需要设置:低维子空间的维数d和邻域大小k。目前关于流形学习参数的选取还没有统一的评价指标,在实际应用中通常将低维子空间的维数d选择为样本类别数C减1[12],因此本文选取低维子空间的维数d=4;而在选择邻域大小k时,如果k值太小无法保证邻域间信息的互通,k值太大则将破坏流形的局部结构,但k值应当满足大于低维子空间的维数d、小于各类样本的样本数Ni(i=1,…,C),即d<k<N[13],针对本文则应当满足4<k<30,本文选取领域大小K=8。
图4所示为原始特征集的非线性将维结果,可以看出,由于原始混合特征集中包含较多的非敏感特征,因此特征融合效果不理想,两种滚动体故障(严重、轻度)仍然没有被有效地分离开。
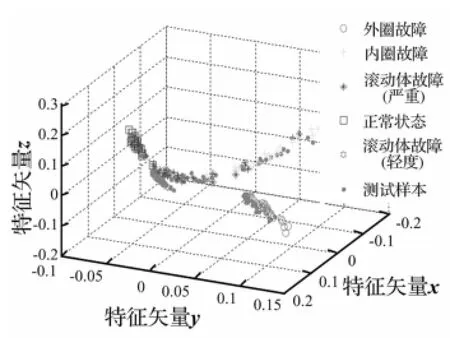
图4 原始混合特征集(X)的降维结果Fig.4 Processing result of the raw feature setby LLTSA
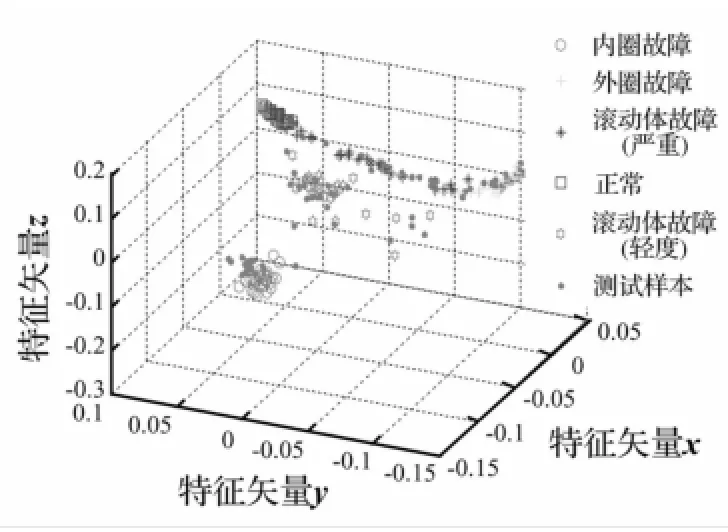
图5 KDM-FS选取的敏感特征子集(X1)的降维结果Fig.5 Processing result of the feature subset X1by LLTSA
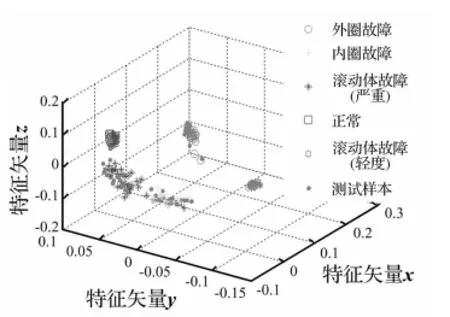
图6 IKDM-FS选取的敏感特征子集(X2)的降维结果Fig.6 Processing result of the feature subset X2by LLTSA
图5为基于KDM-FS的敏感特征子集进行特征融合的结果,可以看出,由于排除了部分的非敏感特征,降维后基本能够将几种轴承状态分离开。但是,由于没有考虑特征的类内散度,造成非敏感特征没有完全排除或者敏感特征误选的情况,因此,降维后样本类内散度仍然很大,且外圈故障和滚动体故障(严重)还存在较大的耦合。
图6中为IKDM-FS的敏感特征子集进行特征融合的结果,可以看出,由于IKDM-FS充分地考虑了特征样本的类内散度和类间距离,能够有效地排除非敏感特征,因此通过特征融合后,很好地将几种轴承状态样本分离开,同时具有较好的聚类效果。
最后,将融合敏感特征子集输入分类器进行故障识别。为了验证分类器邻域大小kc对识别精度的影响,本文分别选取分类器的邻域大小kc=8、10、12进行实验,实验结果如表1所示。
从表1可以看出,由于原始特征集中包含有非敏感特征,因此,故障识别精度较低,平均识别率为94%;而KDM-FS没有考虑样本类内散度的影响,导致非敏感特征没有完全排除或者敏感特征误选,影响了识别精度的进一步提高,其平均识别率为97%;本文提出的IKMD-FS充分地利用了核空间中样本类内散度和类间距离,有效地排除了非敏感特征,因此其能够准确、有效地识别出故障的类别。
通过对比试验可以看出:WKNNC的识别精度几乎不受邻域大小kc的影响,而KNNC的识别精度受邻域大小kc的影响比较明显。
6 结 论
本文提出基于敏感特征选取与流形学习维数约简的故障诊断方法,其原理是:结合敏感特征选取与流形学习维数约简的特点,有效地排除原始特征集中的非敏感特征并对其进行非线性维数约简,得到对故障更加敏感的融合特征子集,然后通过WKNNC对故障进行模式识别。通过实验验证,本文方法能够有效、精确地识别出故障的类别,为故障诊断提供了一种新的解决思路。
本文的后续研究可以从以下几个方面进行:
(1)深入研究故障机理,揭示故障与故障特征之间的本质联系。
(2)特征加权的权值选取规则还需要进一步的分析和研究。
(3)本文还未对早期故障(即故障萌芽即将出现、刚刚出现或者故障程度尚轻微)进行研究,后续研究可深入到早期故障的预示与识别。
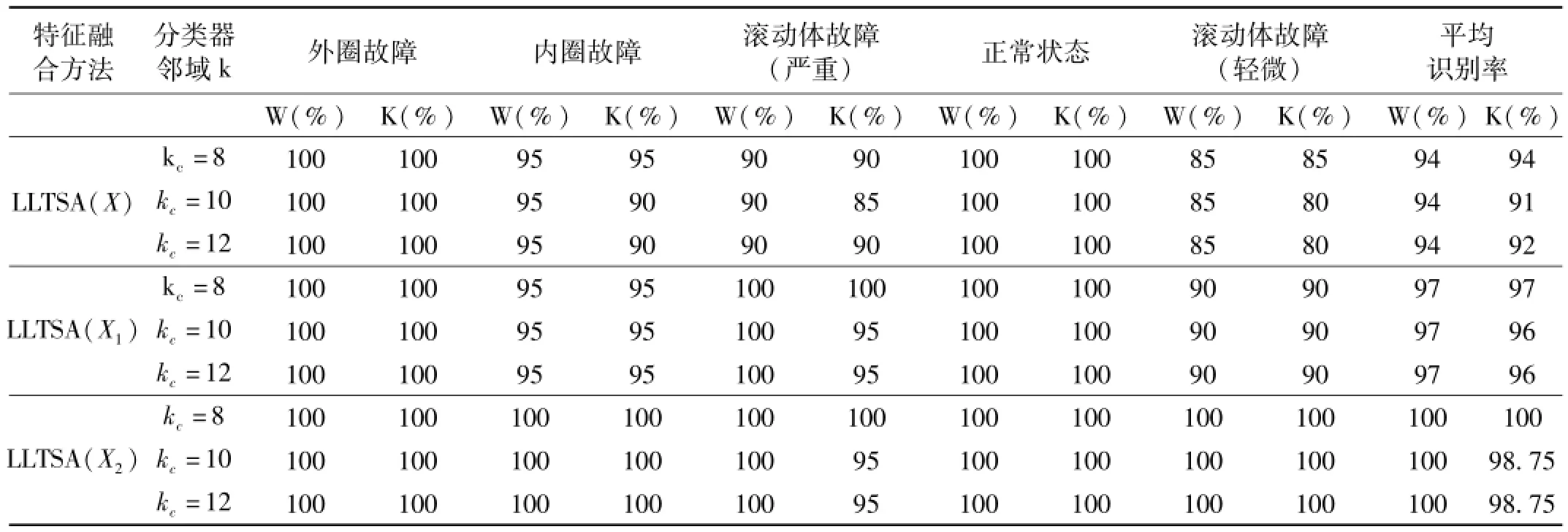
表1 几种故障状态的识别精度(W、K分别代表WKNNC和KNNC)Tab.1 The recognition accuracy of the 5 kinds of fault signals of bearing(W、K indicateW KNNC and KNNC respectively)
[1]Li B W,Zhang Y.Supervised locally linear embedding projection(SLLEP)for machinery fault diagnosis[J].Mechanical Systems and Signal Processing,2011,25:3125-3134.
[2]蒋全胜,贾民平,胡建中,等.基于拉普拉斯特征映射的故障模式识别方法[J].系统仿真学报,2008,20(20):5710-5713.
JIANG Quan-sheng,JIA Min-ping,HU Jian-zhong,et al.Method of fault pattern recognition based on laplacian eigenmaps[J].Journal of System Simulation,2008,20(20):5710-5713.
[3]李 锋,汤宝平,陈法法.基于线性局部切空间排列维数化简的故障诊断[J].振动与冲击,2012,31(13):36-40.
LI Feng,TANG Bao-ping,CHEN Fa-fa.Fault diagnosis model based on dimension reduction using linear local tangent space alignment[J].Journal of Vibration and Shock,2012,31(13):36-40.
[4]Zhang TH,Yang J,Zhao D L,et al.Linear local tangent space alignment and application to face recognition[J].Mechanical Systems and Signal Processing,2007,70:1547-1553.
[5]Hechenbichler W,Schliep K.Weighted K-nearest-neighbor techniques and ordinal classification[OL].http://Epub.ub.Uni-muenchen.de/1769/,2007-4-10/2008-9-12.
[6]蔡哲元,余建国,李先鹏,等.基于核空间距离测度的特征选择[J].模式识别与人工智能,2010,23(2):235-240.
CAIZhe-yuan,YU Jian-guo,LI Xian-peng,et al.Feature selection algorithm based on kernel distance measure[J].Pattern Recognition and Artificial Intelligence,2010, 23(2):234-240.
[7]Avci E,Turkoglu L.An intelligent diagnosis system based on principle component analysis and ANFIS for the heart valve[J].Expert Systems with Applications,2009,36(2):2873-2878.
[8]Zhang Z Y,Zha H Y.Peincipal manifolds and nonlinear dimension reduction via local tangent space alignment[J].SIAMJournalof Scientific Computation,2004,26(1):313-338.
[9]Songbo T.An effective refinement strategy for KNN text classifier[J].Expert Systems with Applications,2006,30:290-298.
[10]雷亚国,何正嘉,訾艳阳.基于混合智能新模型的故障诊断[J].机械工程学报,2008,44(7):112-117.
LEI Ya-guo,HE Zheng-jia,ZI Yan-yang.Fault diagnosis based on novel hybrid intelligentmodel[J].Chinese Journal ofMechanical Engineering,2008,44(7):112-117.
[11]朱明旱,罗大庸,易励群.一种序列的加权kNN分类方法[J].电子学报,2009,37(11):2584-2588.
ZHU Ming-han,LUO Da-yong,YI Li-qun.A sequential weighted k-Nearest neighbor classificationmethod[J].A c ta Electronica Sinica,2009,37(11):2584-2588.
[12]Kouropteva O.Unsupervised learning with locally linear embedding algorithm;an experimental study[D].Finland:University of Joensuu.Department of Computer Science and Statistics,2001.
[13]宋 涛,汤宝平,李 锋.基于流行学习和K-最近邻分类器的旋转机械故障诊断方法[J].振动与冲击,2013,32(5):149-153.
SONG Tao,TANG Bao-ping,LI Feng.Fault diagnosis method for rotatingmachinery based onmanifold learning and K-nearest neighbor classifier[J].Journal of Vibration and Shock,2013,32(5):149-153.
Fau lt diagnosism ethod based on sensitive feature selection and manifold learning dimension reduction
SU Zu-qiang,TANG Bao-ping,YAO Jin-bao
(The State Key Laboratory of Mechanical Transmission,Chongqing University,Chongqing400030,China)
A fault diagnosis method based on feature selection(FS)and linear local tangent space alignment(LLTSA)was proposed,aiming at solving the problem that there are non-sensitive features and over-high dimensions in the feature set of a fault diagnosis.Firstly,improved kernel distance measurement feature selection method(IKDM-FS)was proposed considering both the distance between classes and the dispersion within a class,and the selected sensitive features were weighted with their sensitive-values.The weighted sensitive feature subset was compressed with LLTSA to reduce its dimensions and get the compressed more sensitive feature subset.Then,the feature subset was fed into a weighted k nearest neighbor classifier(WKNNC)to recognize the fault type,its recognition accuracy wasmore stable compared with that of a k nearest neighbor classification(KNNC).At last,the validity of the proposed method was verified with fault diagnosis tests of a rolling bearing.
fault diagnosis;feature selection;improved kernel distance measurement;linear local tangent space alignment;weighted k nearest neighbor classifier
TH165.3;TN911.2
A
国家自然科学基金项目(51275546,51375514);高等学校博士学科点专项科研基金资助(20130191130001)
2012-12-17 修改稿收到日期:2013-03-23
苏祖强男,博士生,1987年生
汤宝平男,博士,教授,1971年生
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:06:44
数学物理学报(2020年3期)2020-07-27 01:19:56
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
电子制作(2017年23期)2017-02-02 07:17:06
数学物理学报(2016年5期)2016-08-24 07:38:40
数学物理学报(2016年6期)2016-04-16 04:40:58
西北工业大学学报(2015年4期)2016-01-19 03:31:47
振动工程学报(2014年4期)2014-03-01 01:15:41
