
一个小型搜索引擎的设计与实现
2014-05-09 09:33刘嘉
河南科技学院学报(自然科学版) 2014年6期
刘嘉
(郑州轻工业学院软件学院,河南郑州450002)
搜索引擎是一种能够通过Internet接受用户的查询指令,并向用户提供符合其查询要求的信息资源网址的系统[1].它是一些在Web中主动搜索信息(网页上的单词和特定的描述内容)并将其自动索引的Web网站,其索引内容存储在可供检索的大型数据库中,并建立索引和目录服务.
本文设计了一个基于Web的小型搜索引擎.系统基于Linux平台,通过C语言编程,采用模块化的设计模式,主要实现了网页获取子系统、索引子系统、检索子系统3大系统,进而实现对搜索引擎原理的解释,并为解决系统性能提供了有关方法.
1 系统架构
搜索系统由数据采集、文档组织和索引、查询服务3个模块构成.作为数据的收集处理系统,网页抓取系统从互联网上通过某些策略获取信息,经过简单分析整理后传输至索引系统;索引系统建立可供检索系统检索的数据结构;作为与用户交互的检索系统,得到检索请求之后,把索引系统提供的信息整理后发送至用户[2].简易系统结构如图1所示.
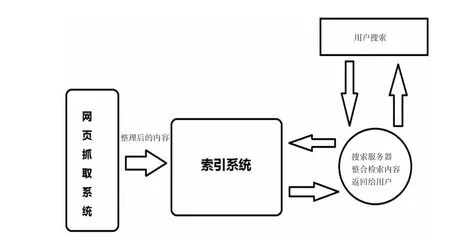
图1 系统结构Fig.1 Diagram of the System structure
2 系统设计
2.1 网页抓取模块
采集总调度是整个网页获取子系统的核心[3],其主要负责:合理分配每个采集点的采集任务;整理并发送从采集点发送来的采集数据;进行URL排重工作.采集点通过内部任务分配算法,使其减少同一采集点频繁采集相同网站的频率.每个采集点采集到的数据汇总到总调度之后,总调度进行分析整理,然后发送至索引系统.
任务分配算法用来解决采集点频繁采集同一网站不同网页,造成网站发现非正常浏览而进行屏蔽操作的问题[4].核心思想为:构造一个任务队列,将任务分类后,由总调度负责将每一类任务发送给采集点.在采集的过程中,采集点采集到网页原始数据,经过总调度分析后,从中取得大量URL,这些URL将会作为待采集任务放入URL库中,但是,每个网页中的URL可能会重复,所以必须设计一种高效排重算法.在本系统中,采用的是经典排重算法:布隆过滤器(Bloom Filter).假定数据量为N,并且出错率控制在M以下时,需要K个hash函数,此K个哈希得到相应的位并检测是否已经出现过的核心算法为:


2.2 索引模块
索引系统获取数据的来源有2种,一种是原始数据,一种是网页获取子系统发送来的数据.首先,系统会将原始数据建立检索二叉树,用于快速定位索引位置,然后建立原始数据的倒排索引.其次,当从网页获取子系统接收到数据之后,更新二叉树,进行增量索引.架构如图2所示.

图2 索引系统架构Fig.2 Diagram of the index system architecture
2.3 检索模块
用户通过API或者网页端CGI接口发送相应请求.检索系统接到请求后进行解析,判断属于检索请求还是权值请求.若是检索请求,系统将检索词分词后分别进行检索,并且将获得的内容进行合并操作,然后根据权值时间等信息进行相关度计算,排序后发送回用户请求端口;若是权值请求,将会根据信息确定权值加减,然后更改其权值[5].
通过采用线程池的技术,解决频繁创建销毁线程时占用大量CPU处理时间的问题,提高检索速度.下面是建立线程池的核心代码:

为了得到有序的检索结果,需要一定的策略帮助用户选择最适合的内容.本系统采用权值排序算法-TF/IDF相关性排序.
3 搜索界面及结果
通过对搜索引擎技术的分析研究,设计并实现了一个小型搜索引擎.系统的索引建立及检索用数据全部在内存中存储.测试环境为:CPU,Intel(R)Xeon(R)CPU E5-2630 0@2.30 GHz;MEM,64 G;System,CentOS release 6.2(Santiago).图3是第一电商的用户界面,图4是输入检索词“郑州轻工业学院”后的检索结果.

图3 用户界面Fig.3 Diagram of the User interface

图4 输入“郑州轻工业学院”后的检索结果Fig.4 The retrieval results after input"Zhengzhou University of Light Industry"
4 小结
本文详细介绍了小型搜索引擎的设计过程,并设计了一个小型搜索引擎系统,实现用户对网络信息检索的基本需求,结果令人满意.但要实现一个功能完备的搜索引擎,还有许多问题要进一步研究解决,如:随着系统运行时间的增长,索引会越来越大,当内存不足以存放该索引及索引文件时,必须考虑硬盘存放的问题;备份服务器及多台服务器共同服务造成分布式搭建时如何处理的问题以及更深层次的检索优化问题.
[1]邱哲,符滔滔.Lucene2.0+Heritrix搜索引擎[M].北京:人民邮电出版社,2007.
[2]王玉婷,杜亚军,涂腾涛.基于Web链接的主题爬行虫初始URL的研究[C]//第四届全国信息检索与内容安全学术论文集(上),2008:324-333.
[3]赵敏涯.基于主题的新闻搜索引擎的设计与实现[D].扬州:扬州大学,2006.
[4]Bharat K,Henzinger M.Method for ranking documents in a hyperlinked environment using connectivity and selective content analysis[C]//Proceeding of ACM-SIAM symposium on discrete algorithm,San Francisco,California,US,1998:17-21.
[5]Zobel J,Moffat A.Adding compression 10 a Full-Text retrieval system[J].Software Practice and Experience,1995,25(8):891-903.
猜你喜欢
China Report Asean(2022年8期)2022-09-02
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
物联网技术(2020年12期)2021-01-27
汽车零部件(2017年4期)2017-07-12
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
科学导报·学术论坛(2013年5期)2013-06-26
