
基于WordNet的藏文语义词典半自动构建方法研究
2014-05-04 14:05:32柔特
西藏大学学报(自然科学版) 2014年1期
柔特
(青海师范大学计算机学院 青海西宁 810008)
基于WordNet的藏文语义词典半自动构建方法研究
柔特
(青海师范大学计算机学院 青海西宁 810008)
摘要:语义词典是人工智能、语义网与知识工程等研究领域的热点,它可以支持机器学习、自然语义理解、数据挖掘及机器翻译等技术。文章在藏语独特的文法理论研究基础上,利用对比英文和藏文词之间的语义关系、构建双语大型数据库和制定映射过程中词汇空缺等方法,构建了基于半自动匹配的藏文语义词典。本语义词典既兼容了国际通用的英文WordNet,又保留了藏语的特点,为藏文信息处理提供了重要的数据资源。
关键词:藏文语义词典;半自动;WordNet;词汇映射
随着计算机的普及,传统意义上的词典已经不能满足人们的需求,人们希望通过计算机自动对词的语法语义属性和语法语义规则进行挖掘和剖析,以解决语言学的实际问题。计算语言学工作者把语义词典的质量看作是自然语言处理系统的瓶颈和基石,英语、汉语等文种的语义词典研究和应用在不断扩大和深入,语言知识工程所需要的语法、语义信息量在急剧增加,其应用领域在不断扩大和深入,语义词典的构建已成为语言知识工程建设的基石。
1 WordNet国内外研究现状
WordNet是一个应用非常广泛的英语词汇知识库,在自然语言处理相关的诸多领域内均有着应用前景,在国际计算语言学研究领域具有很大的影响[1]。2001年成立了WordNet研究学会;2002年2月召开了第一届WordNet国际会议,到2012年7月已先后召开了六次WordNet国际会议。如今许多国家都已着手实施构造本国各族语言的WordNet,如:英国、法国、荷兰、捷克、西班牙和意大利等国家都参与构建了EuroNet系统[2]。此外,以英语WordNet为基础,印度、缅甸、印度尼西亚、泰国、孟加拉国、老挝、越南和蒙古国等国已经参与了AsianWordNet系统的研究工作。根据普林斯顿大学网站发布的WordNet研究成果中,基于英文WordNet的词汇语义网络系统就有100多种不同的语言版本。
目前国内比较有代表性的中文语义词典或相关工作主要是由北京大学计算语言学研究所刘扬等构建的中文概念词典(CCD)以及中国科学院董振东先生首创的HowNet[3-4]。其中,CCD基本是按照WordNet的简化思路,集中构建基本的语义关联,它按照WordNet上、下位关联构成树状结构,提出了利用对齐和调整语义树节点的方法著录中文语义,开发了相关桌面应用工具VACOL[5]。而HowNet则构建了更复杂的语义关联关系,并定义了更加完备的分类体系,更侧重于对语言建模的完备性研究,另外HowNet还提供了查询相关的应用和接口。在中国少数民族语言文字方面,目前只有蒙古语语义词典在国家各项目的支持下处于初步建立和发展的阶段[6-7]。
藏语语义词典的研究近几年才刚刚起步,由于藏文字的特殊性,藏文信息处理的速度缓慢,很多工作还处于萌芽阶段。先后有中央民族大学,青海师范大学和西北民族大学等科研院所从不同角度讨论了藏语语义词典的技术问题。其中,中央民族大学邱莉榕博士等研究了藏文语义本体中的上下位关系模式匹配算法[8];西北民族大学祁坤钰探讨了机器翻译用现代藏语语义词典的设计研究,并提出了藏语语义词典设计的理论框架、语义分类思想和属性描述原则[9]。但是,目前还没有基于WordNet的藏语语义词典半自动构建技术和方法方面的文献报道。基于此,本文在参考其他语种的语义词典构建方式的基础上,探讨了用半自动方法构建藏语语义词典的思想,本方法与传统的手工构建方式相比,在效率上有很大的提高并节约了一大笔支出。
2 藏文WordNet的研究意义
语义理解已成为自然语言处理的瓶颈问题,实现自然语言理解离不开语义词典。由于不同民族文化和语言结构上的差异,作为语言载体的词汇部分不免存在着文化语言学上的差异,这种文化上的差异直接反映在概念词汇上。因此,构建一个能反映藏语语言特点的词汇语义网具有重要的理论价值和应用价值。通过基于WordNet的藏语语义词典构建技术和方法研究有利于促进藏语语言学与计算语言学的整合与互补,拓展交叉学科研究领域,对藏语语义进行定性、定量的系统研究,可形成跨学科的学术成果。
2.1 对词法分析而言,通过藏文语义词典的开发可以为藏文命名实体识别、词义消歧、词义分析等自然语言处理的底层技术提供基础数据资源。
2.2 对句法层面而言,对问答系统、信息检索、文本分类及机器翻译等研究领域具有重要应用价值。
2.3 藏语语义词典构建技术来说,半自动构建方式和手工构建方式相比,所构建的语义词典在效率上有很大的提高,节省了大量的人力和物力。
3 构建藏文半自动WordNet的基本思路
本文在构建半自动语义词典时首先对语义词典中的共性和个性进行了分析,以有利于相互兼容和保留特色。
3.1 词网关系的对比
任何一种民族语言的语义系统都是该民族在长期的生活、生产、社会实践活动中逐步积累并约定俗成的。本文首先对现有的英文WordNet和藏文词之间存在的个性和共性问题进行分析和研究,然后结合藏文传统文法和计算语言学的理论知识制定符合藏文词网关系,这样有利于相互兼容和构建一个反映藏语言特点的词汇语义网。
3.1.1 分析wordNet词网关系
WordNet是一个由普林斯顿大学认识科学实验室开发和维护的英语词典。从1985年开始,由于它包含了语义信息,所以有别于通常意义上的词典,它与其它标准词典最显著的不同在于WordNet将词汇分成4个种类:名词、动词、形容词、副词。WordNet根据词条的意义将它们进行分组,每一个具有相同意义的字条组称为一个synset(同义词集合)。WordNet为每一个synset提供了简短而概要的定义,并记录不同synset之间的语义关系。synsets表示词汇概念,用词汇矩阵描述词汇间的关系,即在词形和意义之间建立映射关系。WordNet通过同义词集合之间建立同义(synonym)、反义(antonym)、整体(holonym)、部分(meronym)、上位(hypernym)、下位(hyponym)、蕴含因果及近似等多种语义关系连成词的语义网。
3.1.2 藏语词网关系

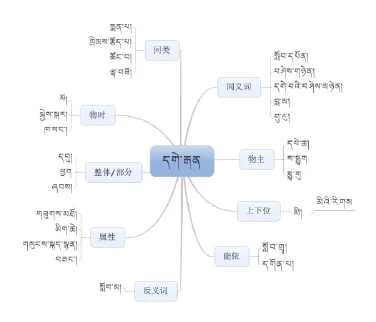
图1 藏文语义网关系图
3.2 技术方法研究
计算机实现自然语言理解,离不开语义词典,语义词典为机器学习、语义理解、数据挖掘等技术的发展提供了重要的数据资源。在构建语义词典时,如何平衡成本、时间及性能之间的关系是必须要优先考虑的问题。同时,如何与国际通行的语义词典WordNet有较好的兼容性并方便实用,为后续的开发者提供理论基础和方法是本文的研究重点。
目前,大部分语义词典仍是手工构建方式,这种方法既费时又费力,极大地限制了语义词典的开发和应用。因此,为了较系统地研究藏语语义词典半自动构建技术,本文的基本研究思路如图2所示,具体步骤为:

图2 构建藏文语义词典框架图
①分析和对比英语WordNet以及现代汉语语义词典的语义分类方法的基础上,提出一个符合藏文文法,又结合计算语言学的藏语语义分类方案。
②了解英语WordNet词典的数据结构和语法信息,并对现有的汉藏、英藏双语词典的资源进行整合后建立大规模双语词典,同时制定相应的词汇映射方案。
③解决词汇空缺问题。由于语言与文化的差异,源语和目的语分别存在着许多文化局限词或映射问题,需要根据已有的有效策略和方案以人工方式解决。
4 构建半自动藏语语义词典流程
目前较为成熟的WordNet、HowNet、CCD以及同义词词林等均为人工开发。它们对知识的描述较为准确,但开发的工作量巨大,实际应用存在很多困难。为了节省人力和物力,本文采用上述较成熟的语义词典的共性部分,利用计算机技术对现有双语电子词典进行整合后建立大规模双语电子词典,再以半自动映射方法进行分析(见图3)。
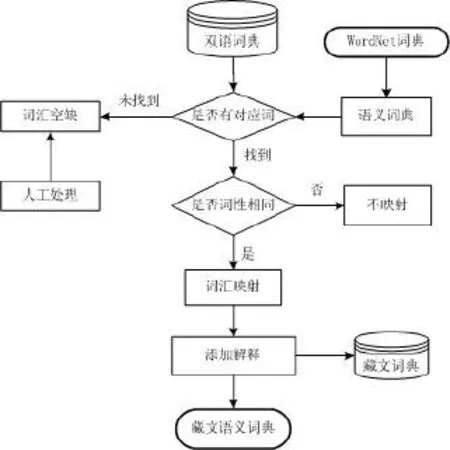
图3 半自动构建方案流程图
4.1 建立大型词典
4.1.1 建立大型双语词典
首先要收集许多英藏或藏英双语词典,然后整合资源和校对内容。其中词典中词汇规模要达到一定数量,同时词典必须要包含词性标注和语法信息,以便进行数据库映射工作。
4.1.2 建立藏文词典
藏文词典主要用于添加解释,所以词典需要包括解释和词性标注,后者为了词汇映射后词汇概念之间的替换做准备工作。
4.2 数据库映射技术研究
4.2.1 词汇映射法
数据映射是指WordNet和双语词典两个数据库,对于WordNet中的每个词汇,我们试图在双语数据库中为它找到一个语义相同或者相近的对应词,对于双语数据库中的每个词或者节点也是如此。本文采用WordNet词汇来查询双语词典的工作方式,若找到语义相同或相似的词汇时抽取双语词典内容,但词性标注必须要一致。若WordNet词汇未查到时预留原文内容,进一步进行人工翻译或处理。
4.2.2 词汇解释添加法
为了进一步完善对词汇所添加的解释,要根据词汇映射结果,以刚建立的藏文语义词典为依据,查询藏文单语词典中对应的词,若找到该词,并且词性标注相同或条件满足时,藏语单语词典中的对应的解释可添加到藏文语义词典。
4.3 词汇空缺策略探析
由于语言与文化的差异,源语和目的语之间存在着许多文化局限词,文化局限词可以通过词义差异模式或词汇空缺方式解决。人工翻译时词汇空缺方式主要从历史文化、宗教信仰及地理环境等几个方面对双语词典映射过程中的词汇空缺问题建立对应策略,通常采用的方法有:
①提供意义接近的近似对应词。
②人名和地名按英藏字母对照关系来音译。
③目的语中带文化色彩的词语,可以代替源语中内涵基本相同的文化局限词,这种方法称为代换对译。
④采用源语和目的语混合使用的方法来处理文化局限词的对译,目的是为了将源语所含信息准确完整地传递给读者,这种方法称为双语混译。
⑤某些文化局限词对应词可采用半音译半意译的方式翻译。
5 实验结果
在面向自然语言处理中的语义词典而言,词汇一般都是一词多义的,即一个形态词汇代表了多个概念。如:work一词,有“工作、职业、作品、车间、操作及(物)功”等几个义项。所以,首先通过双语词典对源数据库做词汇自动映射和人工修改,再次通过藏文词典添加解释(见图4、图5)。

图4 词汇映射过程

图5 添加词汇解释
结语
藏语语义词典是藏语信息处理技术研究中的重要内容,也是藏文信息处理满足公众需求的重要基础性工作之一,同时又是藏文信息处理研究过程中必须解决的领域。构建藏语语义词典可提升藏文信息化服务质量和藏文信息处理语义层面的研究,使藏文信息处理研究从词层面向句子、语义和语用层面过渡。本文采用半自动方式构建一个藏语语义词典,此词典允许公众参与并对内容进行修改和完善,最终建立一个规模较大、实用性较强、准确率较高的实验性藏语语义词典。
参考文献
[1]George A.miller.WordNet:A Lexical Database for English[J].Communication of the ACM(CACM),1995,38(11):39-41.
[2]Dan Tufis,Dan Stefanescu.Experiments with a differential semantics annotation for WordNet 3.0[J].Decision Support Systems,
2012,53(4):695–703.
[3]于江生,俞士汶.中文概念词典的结构[J].中文信息学报,2002,16(4):12-20.
[4]董振东,董强.面向信息处理的词汇语义研究中的若干问题[EB/OL].2013-02-11.http://www.keenage.com/html/c_index.html.
[5]刘扬,陆顾婧.汉英双语概念对应的实证研究[J].云南师范大学学报,2012,44(1):35-39.
[6]塔娜,林民,李小庆.面向跨语言信息检索的蒙汉语义词典构建初探[J].计算机与数字工程,2010,38(8):42-45.
[7]海银花,那顺乌日图.蒙古语名词语义信息词典数据库的构建[J].中央民族大学学报,2012,39(203):125-130.
[8]邱莉榕,翁彧,赵小兵.藏文语义本体中的上下位关系模式匹配算法[J].中文信息学报,2011,25(4):45-49.
[9]祁坤钰.机器翻译用现代藏语语义词典的设计研究[J].西北民族大学学报,2004,25(3):33-37.
[责任编辑:索郎桑姆]
中图分类号:TP392
文献标识码:A
文章编号:1005-5738(2014)01-048-06
收稿日期:2014-03-10
基金项目:2011年度国家自然科学基金资助项目“藏文字符信息熵研究”(项目号:61163018);2012年度国家自然科学基金资助项目“藏语音素拼读法文语转换技术研究”(项目号:61262051);2013年度国家社会科学基金项目“面向自然语言处理的藏语句型自动分析及分布统计”(项目号:13BYY141);2013年度教育部“春晖计划”合作科研项目“藏族远程教育资源共享平台建设”(项目号:Z2012093)阶段性成果。
作者简介:柔特,男,藏族,青海果洛人,青海师范大学计算机学院讲师,主要研究方向为藏文自然语言处理。
Research on Construction Method for Tibetan Semiautomatic Semantic Dictionary based on the WordNet
Rou Te
(School of Computer Science,Qinghai Normal University,Xining 810008,Qinghai)
Abstract:Semantic dictionary is a hot research topic in the areas of artificial intelligence,semantic web and of knowledge engineering.Semantic dictionary can support machine learning,natural semantic understanding,data mining,machine translation and other techniques.Previously established semantic dictionaries such as English WordNet,HowNet,and CCD are developed artificially.Thus,in order to save human power and material resources,in this paper,a Tibetan semantic dictionary was constructed following traditional Tibetan grammar rules based on semi-automatic matching method,comparison of the semantic relation between English and Tibetan words,classifying semantic categories,and developing lexical gap strategy in mapping.This semantic dictionary is not only compatible with English WordNet,but also retains the characteristics of Tibetan language and provides important data resources for Tibetan information process.
Keywords:Tibetan semantic dictionary;semiautomatic;WordNet;lexical mapping
