
基于LDA-MFCC的藏语语音特征提取技术研究
2014-05-04 14:05普次仁顿珠次仁
西藏大学学报(自然科学版) 2014年1期
关键词:特征提取
普次仁 顿珠次仁
(西藏大学工学院 西藏拉萨 850000)
基于LDA-MFCC的藏语语音特征提取技术研究
普次仁 顿珠次仁
(西藏大学工学院 西藏拉萨 850000)
摘要:藏语特征提取算法是藏语语音识别系统中最为关键的一个环节。文章在分析藏语发音特点的基础上,建立了基于模拟人耳听觉系统的Mel倒谱系数(MFCC)特征提取算法,然后通过LDA信息压缩算法,对提取的特征数据进行压缩,在降低维数的同时提高了识别率和运算效率,总结出了符合藏语语音特点的LDA-MFCC特征提取算法。
关键词:MFCC;LDA;特征提取
语音识别是对语音信号进行读取后通过处理转换为文字或其他数据信息的过程,其中特征提取是语音识别的关键环节。特征提取是建立在去除噪音和端点检测技术基础上进一步对语音信号进行处理,提取有用特征,去除多余数据,从而降低运算量,提高识别精度的一道程序。
1 藏语的发音特点

2 藏语语音特征提取算法
根据藏语语音的发音特点及藏语语音的发音时长较汉语长的特点,在确定语音特征提取范围上以单个音节或多个音节即相当于汉语的常用词或字为单位进行识别,而不是以单个字丁进行识别,其缺点是导致整体数据量变大,识别效能降低。
传统藏语信号处理所采用线性系统理论不能取得较好的识别率。本文对藏文语音信号采用MFCC (Mel倒谱系数)进行提取。人的听觉系统导出的声学特征对不同频率的语音具有不同的感知能力,Mel倒谱系就是运用这一特点[4],模拟人的听觉系统。模拟原理为:1000Hz以下的藏文语音在感知能力与频率间成线性关系,而1000Hz以上的感知能力则与频率成对数关系[5-6]。其提取及计算过程如下:
① 经过对藏文语音信号S(m)去除噪音后,采用双门限法进行端点检测,即设有限长度的窗序列W(n),设窗长为N,定义信号的短时能量为:
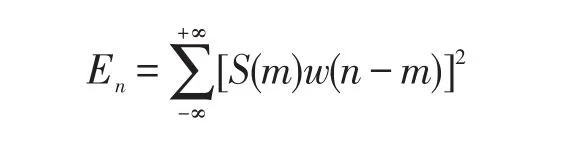
短时平均过零率定义为:
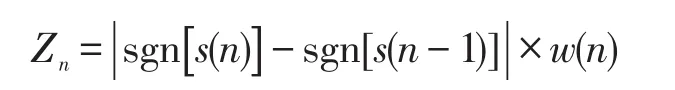
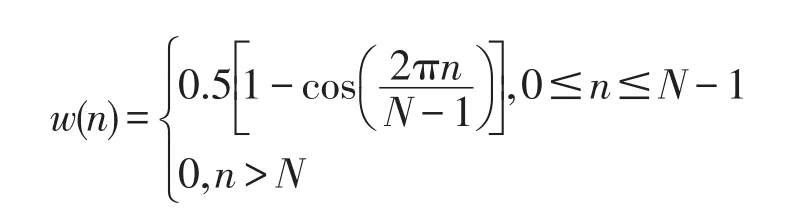
习近平总书记强调,要推动乡村产业振兴,就要紧紧围绕发展现代农业,围绕农村一、二、三产业融合发展,构建乡村产业体系,实现产业兴旺。中国农村的发展程度和富裕程度,决定着国家总体发展的质量与速度,决定着我国在实现全面建成小康社会的基础上全面建设社会主义现代化强国。这要求我们不仅要认识到乡村产业发展对乡村总体振兴的重要性与必要性,同时也要贯彻落实乡村振兴战略[5]。
经过端点检测预处理后得到语音各分段的藏语信号为X(n)。
② 对X(n)进行快速傅立叶变换:
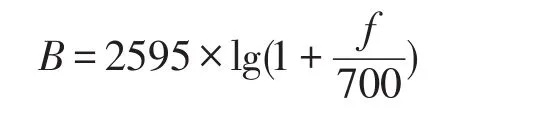
其中,Hm(k)为滤波器的传递函数;通过实验论证,藏文信号处理时,选定Mel滤波器的个数为25个,且具有三角形滤波特性,传递函数为:
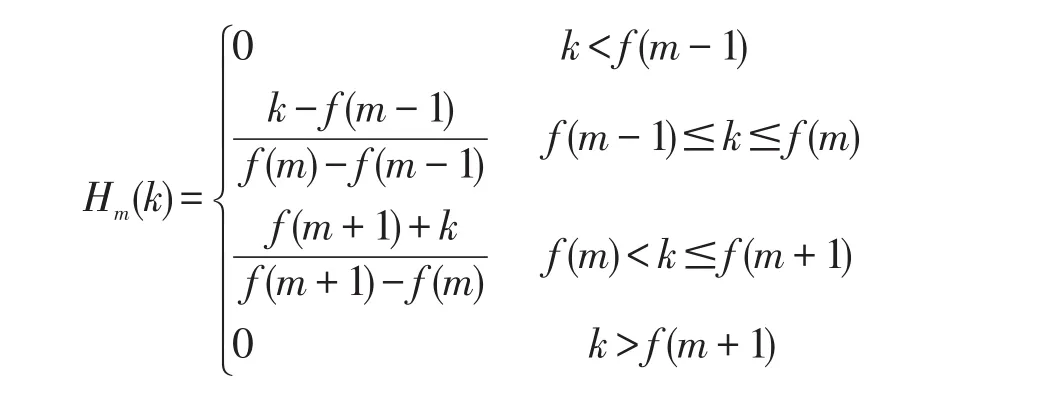
⑤ 最后引入动态差分参数d(n)作为特征矢量输入到识别系统中:
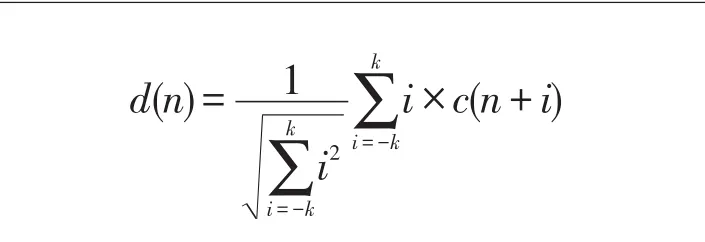
经过试验k=2。
试验结果:语音样本选自标准藏语语音库,为804个藏文发音,并从噪音库中选取White、Pink、F16及Buccaneer1四种噪声源,测试集为信噪比-5dB到15dB带噪语音信号,识别时系统输入带噪信号进行端点检测,表1给出了-5dB到15dB系统的识别性能。
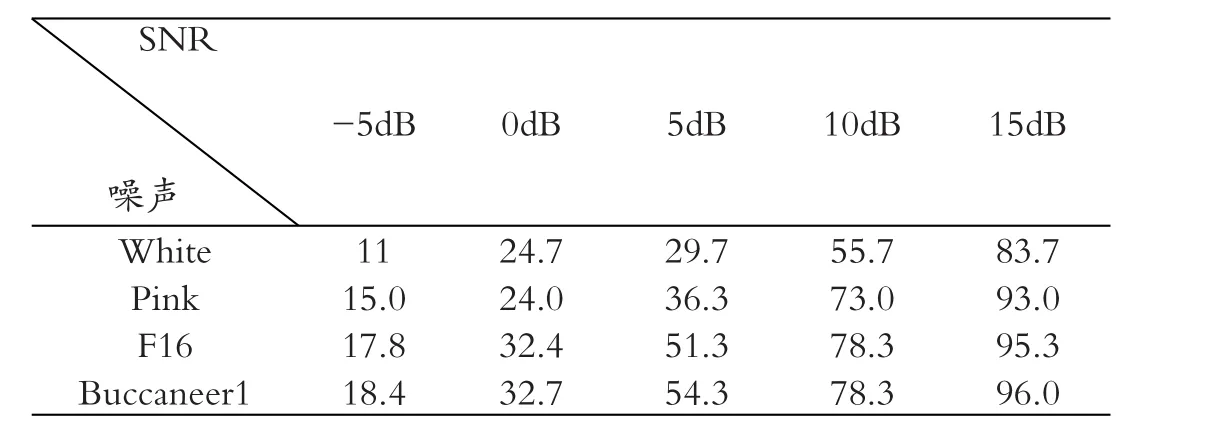
表1 系统识别性能
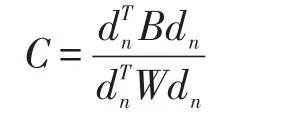
B为类间方差矩阵,W为类内方差矩阵,计算公式分别如下:
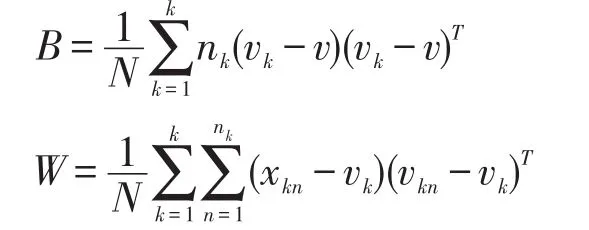
N为总样点数,k为类别数,nk为第k类样点数,vk和v分别是第k类样本及所有样本的均值向量:
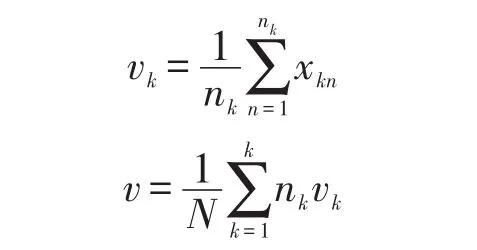
则最优线性变换矩阵Um×n=[d1,d2,…dn],采用Fisher线性准则每次递推的dn都是对应于最大特征值的特征向量。然后将MFCC进行LDA变换得:
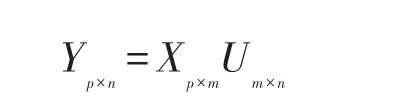
为其中p为帧数,Xp×m
为FCC的m维特征矢量,Yp×n为LDA-MFCC的n维特征矢量(m>=n),采用Yp×n将识别系统特征矢量维数从26维变换到18维,在噪声库中的White噪声及Pink噪声干扰下,选取26维、24维、20维Yp×n进行训练和识别[9],系统鲁棒性能如表2所示。
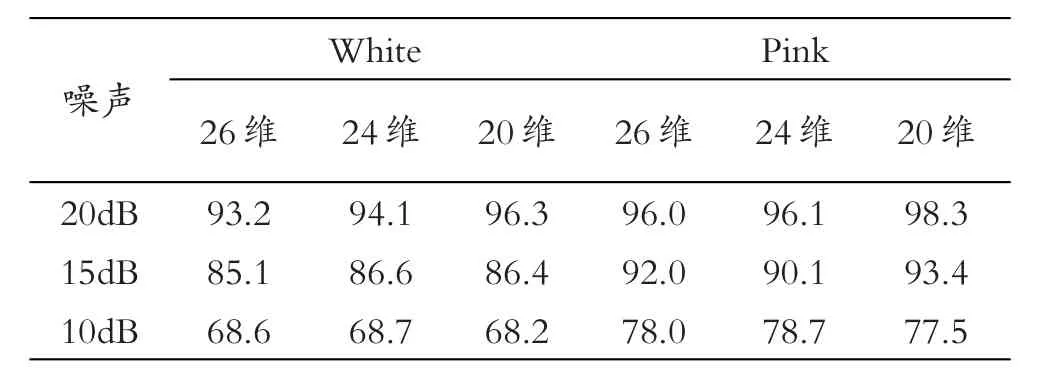
表2 系统鲁棒性能
系统误识率最初随着维数的降低而降低,在20维左右的时候达到最小,之后随着维数的进一步降低而升高,系统性能会一点点下降。因此,采用LDA变换后,识别系统的性能反而随着特征矢量维数的降低而有所改善。
3 结论
本文针对藏语语音自身特点,提出的基于模拟人耳听觉系统的MFCC特征提取算法,并在提取的高矢量特征维数基础上进行了LDA信息压缩算法,降低了维数同时提高了识别率和系统的运行效率,在藏语特征提取算法应用上取得了良好的应用。
参考文献
[1]杨行峻,迟惠生.语音信号数字处理[M].北京:电子工业出版社,1995:11-13.
[2]张雄伟,陈亮,杨吉斌.现代语音处理技术及应用[M].北京:机械工业出版社,2003:112-115.
[3]顿珠次仁.藏语语音信号降噪算法研究[J].西藏大学学报(自然科学版),2010(2):61-65.
[4]韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004:21-27.
[5]赵力.语音信号处理[M].北京:机械工业出版社,2003:132-141.
[6]蔡莲红,黄德智,蔡锐.现代语音技术基础与应用[M].北京:清华大学出版社,2003:62-65.
[7]董婧.鲁棒语音识别技术的研究[D].长春:吉林大学,2007:25-28.
[8]刘加.汉语大词汇量连续语音识别系统研究进展[J].电子学报,2000,28(1):85-91.
[9]张军.抗噪声语音识别技术的研究[D].广州:华南理工大学,2003:29-34.
[责任编辑:索郎桑姆]
中图分类号:TN912.3
文献标识码:A
文章编号:1005-5738(2014)01-044-04
收稿日期:2014-03-19
基金项目:2013年度国家自然科学基金重点项目“跨语言社会舆情分析基础理论与关键技术研究”阶段性成果,项目号:61331013
第一作者简介:普次仁,男,藏族,西藏日喀则人,西藏大学工学院副教授,主要研究方向为藏文信息处理。
Research on Feature Extraction Technique for Tibetan Pronunciation based on LDA-MFCC
Putsering Dondru-Tsering
(School of Engineering,Tibetan University,Lhasa 850000,Tibet)
Abstract:The algorithm of Tibetan speech feature extraction is most critical aspect of Tibetan speech recognition system.In this paper,according to Tibetan pronunciation feature,the feature extraction algorithm of MFCC was established based on simulating human auditory system.The extracted feature data was compressed by using information compression algorithm LDA.The algorithms used in this study can achieve the reduction of dimensionality,improvement of recognition rate and computing efficiency.The feature extraction algorithm LDA-MFCC of Tibetan pronunciation was summarized in accordance with the Tibetan characteristics.
Keywords:MFCC;LDA;Feature Extraction
猜你喜欢
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
自动化学报(2017年7期)2017-04-18
自动化学报(2017年11期)2017-04-04
中国生物医学工程学报(2017年6期)2017-02-10
制造技术与机床(2015年10期)2015-04-09
噪声与振动控制(2015年4期)2015-01-01
振动、测试与诊断(2014年6期)2014-03-01
