
Logistic回归与分类树模型的比较
2014-04-04 01:46:22杨君慧
西安工业大学学报 2014年9期
孙 颖,杨君慧
(西安工业大学 理学院,西安710021)
由于信用卡能给银行带来很高的利润,国内外各大商业银行受信用卡业务的高额利润和市场空间吸引,都开始增加了该部分的投入,但是高利润也伴随着高风险[1].如何更好地对信用卡申请人进行识别和判断,提高银行预防和抵抗信用卡风险的能力,是所有发卡机构迫切需要解决的问题.信用度,是指从社会信誉、经济状况、商品交易的履约情况等方面反映出来的发卡对象的遵约守信程度.信用度评估对发卡机构来讲,是一项非常重要的任务.一个人的社会信用度直接关系到他申请和使用信用卡的状况[1].如何对信用卡申请的资产信用评估,统计学方法主要包括非参数模型分类树方法、判别分析和参数模型Logistic回归[2].随着电子商务的发展,信用卡的使用者和交易量迅速增加,导致信息量急剧扩大仅凭个人经验已经很难有效的做出正确的判断,而判别分析所做的假设条件又常常无法满足.Logistic回归模型在这一点上,具有简单易懂,模型的解释强的优点(模型的结果可以产生一个评分卡,易于被实际部门工作人员理解和实施).因此在信用度评估上得到了广泛的应用.而分类树模型具有较好的稳健性和逻辑性[3].本文将通过统计学中参数方法Logistic回归和非参数方法分类树建立模型.
1 Logistic回归和分类树综述
1.1 Logistic回归模型
Logistic回归又称Logistic回归分析,主要在流行病学中应用较多,Logistic回归的主要用途:①寻找某一疾病的危险因素;②根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大.如果已经建立了Logistic回归模型,则可以利用计算机教学软件,通过迭代计算最大似然估计的方法,得到相关的系数.
Logistic回归与多重线性回归实际上有很多相同之处.最大的区别就在他们的因变量不同,其他的基本都差不多.正是因为如此,这两种回归可以归于同一个家族,即广义线性模型 (generalized Linear Model).Logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释.所以实际中最为常用的就是二分类的logistic回归,也是文中要使用的回归模型.在很多实际应用中,由于模型不能适用多元线性回归模型 (比如独立变量不符合正态分布等),那么Logistic回归分析就很好的弥补了这一方面.在二项Logistic回归分析中,如果我们让y=1代表一个结果,y=0代表另一个结果,y是满足二项分布的,那么Logistic回归模型规定为
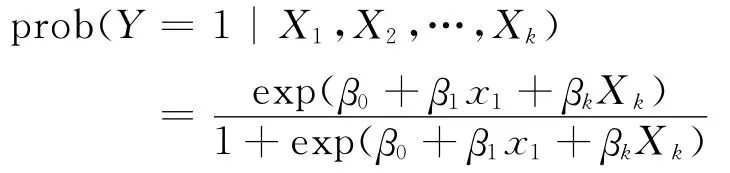
其中:β0,β1,…βk是未知的多元Logistic回归系数.对系数有一个解释为

Logistic模型在以上的意义是几率的乘法
即[基本事件的几率]*[由于 X1的因素]*…*[由于Xk的因素]
1.2 分类树模型
决策树是用二叉树图来表示处理逻辑的一种工具.可以直观、清晰地表达加工的逻辑要求.特别适合于判断因素比较少、逻辑组合关系不复杂的情况.决策树提供了一种展示类似在什么条件下会得到什么值这类规则的方法.决策树中最上面的节点称为根节点,是整个决策树的开始.每个分支要么是一个新的决策节点,要么是树的结尾,称为叶子.在沿着决策树从上到下的过程中,在每个节点都会遇到一个问题,每个节点上问题的不同回答导致不同的分支,最后会到达一个叶子节点.这个过程就是利用决策树进行分类的过程,利用几个变量 (每个变量对应一个问题)来判断所属的类别(最后每个叶子会对应一个类别).建立决策树的过程,即树的生长过程是不断的把数据进行切分的过程,每次切分对应一个问题,也对应着一个节点.对每个切分都要求分成的组之间的“差异”最大.决策树的这种易于理解性对数据挖掘的使用者来说是一个显著的优点.然而决策树的这种明确性可能带来误导.比如,决策树每个节点对应分割的定义都是非常明确毫不含糊的,但在实际生活中这种明确可能带来麻烦.
建立一颗决策树可能只要对数据库进行几遍扫描之后就能完成,这也意味着需要的计算资源较少,而且可以很容易的处理包含很多预测变量的情况,因此决策树模型可以建立得很快,并适合应用到大量的数据上.
对最终要拿给人看的决策树来说,在建立过程中让其生长的太枝繁叶茂是没有必要的,这样既降低了树的可理解性和可用性,同时也使决策树本身对历史数据的依赖性增大,也就是说这棵决策树对历史数据可能非常准确,一旦应用到新的数据时准确性却急剧下降,我们称这种情况为训练过度.为了使得到的决策树所蕴含的规则具有普遍意义,必须防止训练过度,同时也减少了训练的时间.因此需要有一种方法能在适当的时候停止树的生长.常用的方法是设定决策树的最大高度(层数)来限制树的生长.还有一种方法是设定每个节点必须包含的最少记录数,当节点中记录的个数小于这个数值时就停止分割.决策树中最重要的就是对最大区分度属性的选择方法,通常认为,有最高信息增益的属性是给定数据集合中最高区分度的属性,通过计算信息增益,可以得到属性的排序.
信息增益的定义为
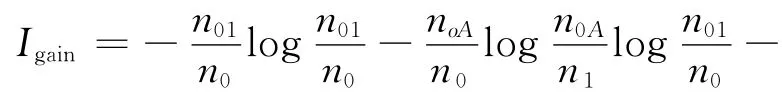
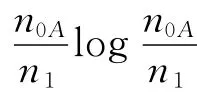
1.3 ROC曲线
接受者操作特性曲线(Receiver Operating Characteristic,ROC),又称为感受性曲线.得此名的原因在于曲线上各点反映着相同的感受性,他们都是对同一信号刺激的反应,只不过是在几种不同的判定标准下所得的结果而已.接受者操作特性曲线就是以虚惊概率为横轴,击中概率为纵轴所组成的坐标图,和被试在特定刺激条件下由于采用不同的判断标准得出的不同结果画出的曲线.
ROC曲线具有以下属性:①β的改变独立于d′的变化,考察β值变化对p(y/SN)和p(y/N)的影响时发现,当β接近无穷大时,虚惊概率几乎为0,即噪音全当成信号接受.而当β从接近0到无穷大渐变的过程中,将形成一条完整的ROC曲线,曲线在某一处达到最佳的标准βOPT.②ROC曲线的曲率反应敏感性指标 d′,对角线代表p(y/SN)=P(y/N),即被试者的辨别力d′为0,ROC曲线离这条线愈远,表示被试者辨别力愈强,d′的值就愈大.由上可知,d′的变化使ROC曲线形成一个曲线簇,而β的变化体现在这一曲线簇中的某一条曲线上不同点的变化.此外,如果将ROC曲线的坐标轴变为Z分数坐标,将看到ROC曲线从曲线形态变为直线形态.这种坐标变换可以用来验证信号检测论一个重要假设,即方差齐性假设.本文中将通过ROC曲线的性质来对模型的性能作出评价.
2 模型的建立和预测
2.1 数据的收集和处理
文中使用一个在信用评分领域非常有名的免费数据集 German Credit Data Set,可以在 UCI Machine Learning Repository找到.
对数据进行预处理,将评估结果转化为二项分布,定义(0,1)中GOOD=0.即在数据中确定的好用户用0来表示,而危险用户则为1.之后将这组数据随机抽取了550个事件,组成实验组,并选取Account,Duration,History,Amount,Saving,Employment,Income,Personal,Property,Age,Installment和Job作为探索变量.
2.2 Logistic回归模型的建立
通过统计产品与服务解决方案(Statistical Product and Service Solutions,SPSS)软件中 Binary Logistic Regression方法求解:将数据中的信用度评估结果作为Dependent 12个属性作为Covariates;由于数据有112个变量,为了得到简单并有代表性的回归方程,选择向后变量加入,向前变量剔出的方法,在 Method中选择Forward Conditional.要求软件输出预测概率和分组结果Probabilities&Group Membership;标准检验值为0.05,置信区间为95% ,并输出 HOSM ERLEMESHOW 检验[4].
在逐步将每个变量放入模型之前,采用得分检验方法,检验某一个自变量与因变量之间有无关系.有结果可见,Checking,Account,Duration,History,Credit,Amount,Savings,Property 在0.05检验水平下与评估客户的分类有着显著的统计学意义.这也说明对客户 的信用度评价中,用户的还款能力以及还款意向占有很重要的因素.而个人的婚姻居住职业等情况对最后结果影响的统计学意义较小.
同时可以得到检验值P,优势比OR(分析疾病与暴露因素联系程度的指标)以及95%的置信区间.可以通过回归方程对试验组中的数据进行计算,从而得到他们的预测概率,并通过预测概率来分组,实现Logistic回归模型对信用度的评估.这一步骤可以在SPSS的Save选项中要求输出.由每个自变量可获得对应的优势比OR值.例如Duration的OR值为1.065,在其他变量取值固定的情况下,Duration每增加一个月,相应的客户信用度评估优势比增加自然对数值为1.065,也就是说随着Duration的时间增加,客户的信用度将增高,这也符合实际意义.
由此可得到最后预测结果.正确率84.5%,灵敏度为90.9% ,特异率为69.7% .由此可以看出建立的Logistic回归模型对信用度的预测准确率还是很高的,550个事件中,有465的用户都能被准确的判断.对本来是资格客户,但是被评为危险客户的有35人,误判率为9.1% .本来是危险客户,被分类为资格客户的有50人,漏判率为30.3%.此模型可以基本满足实际操作的需要,通过得到的预测违约概率Probabilities(OUTCOME=1)来对客户进行分组,实现信用度的评估[5].
2.3 分类树模型的建立
通过SPSS中Classify Tree来得到决策树模型:使用信用等级做因变量Dependent,所有属性作为协变量,由于在2.2中Logistic回归模型计算的是客户违约的预测概率,为了保持一致,在分类中同样把目标定为BAD;为了得到简单的模型以便于解释,我们减少父节点和子节点的个数为20和10;同时要求SPSS输出预测概率,预测分组和树形图.在使用CHAID算法时,活期帐户Checking Account是模型的最佳预测因子.在低存款(Account=1)的节点上,存款Property成为另一个预测因子,在存款 (Account=2)的节点上,Duration成为了他的预测分子,并且在Duration>42的时候终止.通过这种逻辑,分类树在CHAID算法下产生了6个预测因素[6].
实际上为得到更准确地分类,可减少每个节点含有的信息数量得到更精确的分类.比如当设置节点数量为10和5时,会输出分类更加准确的决策树.但是降低了树的可理解性和可用性,同时也使决策树本身对历史数据的依赖性增大.
3 结 论
通过Logistic回归模型和分类树模型,分别对同一组实验数据进行了信用度评估,得到结论为
1)Logistic回归模型和决策树模型对信用度评估都有较好预测性,准确率都很高.然而特异率对危险用户判断的准确率对银行来说有更大的意义(将危险客户预测为资格用户会给银行带来更大的损失 ),尽管分类树模型的总体预测正确率要低于Logistic回归模型,但是在特异率的表现上却更加突出,更值得信赖.
2)作为参数方法的Logistic回归模型可以得到一个回归方程,用于预测新加入的数据的违约概率,相比于分类树模型,更容易操作.但是分类树方法在加入型的事件后预测准确率将降低,这表明分类树模型对现有数据的依赖性很大.
3)分类树模型的ROC曲线更加平滑,这说明决策树模型在稳健性上更有优势.
4)作为非参数方法的分类树模型有很强的逻辑性,不需要概率分布,输出结果明确,清晰.且假设条件少,易于建立,在很多情况下都能使用.
通过统计学对数据分析并预测是一门在实际中应用广泛的学科,在很多领域中也取得了成功.随着市场经济在全球的推广,竞争日益激烈.信贷结构都面临着更大的风险,有效地评估客户的可信度必然成为趋势和提高信贷机构经济效益的有效途径.对客户的信用评估是一项具有发展前景的领域.本文针对统计学中Logistic回归和分类树这两种参数和非参数方法,对数据进行预测,根据输出的结果比较,这两种模型都是可行有效的并都有着各自的优点,在实际操作中应因地制宜,善于把握两种方法的优势,得到更有价值的结果.
[1] 吴喜之.统计学:从数据到结论 [M].北京:中国统计出版社,2009.WU Xi-zhi.Statistics:From Data to Conclusion[M].Beijing:China Statistics Press,2009.(in Chinese)
[2] 何晓群.多元统计分析 [M].北京:中国人民出版社,2004.HE Xiao-qun.Multivariate Statistical Analysis[M].Beijing:People’s Publishing of China,2004.(in Chinese)
[3] 方兆本等.消费者信用评估分析综述[J].系统工程,2001,19(6):9;FANG Zhao-ben.Analysis of Consumer Credit Evaluation[J].Systems Engineering,2001,19(6):9.(in Chinese)
[4] 王济川.Logistic回归模型方法与应用[M].北京:高等教育出版社,2001.WANG Ji-chuan.Logistic Regression Model Method and Application[M].Beijing:Higher Education Press,2001.(in Chinese)
[5] 任康,李刚.Logistic回归模型在判别分析中的应用[J].统计与信息论坛,2007,22(6):71.REN Kang,LI Gang.Application of Logistic Regression Model in Distinguishing[J].Statistics and Information Forum,2007,22(6):71.(in Chinese)
[6] 谢远涛,杨娟.Logistic与分类树模型变量筛选的比较——基于信用卡邮寄业务响应率分析[J].统计与信息论坛,2011,26(6):96.XIE Yuan-tao,YANG Juan.Comparative Analysis of Logistic Regression and Tree Models—Based on Response Ration of Credit Mail Statistics &Information Forum,2011,26(6):96.(in Chinese)
猜你喜欢
意林(2023年7期)2023-06-13 13:00:55
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
浙江工业大学学报(2018年5期)2018-10-08 12:33:42
电子制作(2018年16期)2018-09-26 03:27:06
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
商场现代化(2016年8期)2016-05-10 16:43:43
