
基于密度核估计的贝叶斯网络结构学习算法
2014-04-03 07:33韩绍金李建勋
计算机工程与应用 2014年15期
韩绍金 ,李建勋
HAN Shaojin1,2,3,LI Jianxun1,3
1.上海交通大学 电子信息与电气工程学院,上海 200240
2.中国人民解放军63926部队
3.教育部系统控制与信息处理重点实验室,上海 200240
1.School of Electronic Information and Electrical Engineering,Shanghai Jiaotong University,Shanghai 200240,China
2.Unit 63926 of PLA,China
3.Key Laboratory of System Control and Information Processing,Ministry of Education,Shanghai 200240,China
1 引言
贝叶斯网络(Bayesian Networks,BN)是融合了概率分布表的有向无环图,它将样本信息与先验知识相结合,具有形象直观的数据表达特点,以结构依赖和概率表示的形式分别描述了变量之间定性与定量依赖关系,理论基础坚实,表述方式直观,推理能力强大,是不确定性问题建模和推理的有效工具。
准确高效地学习贝叶斯网络结构和参数,是有效利用贝叶斯网络解决实际问题的基础,是贝叶斯网络理论研究的热点,其内容包括确定贝叶斯网络的结构(有向无环图)和学习节点变量的条件概率分布,即为结构学习和参数学习。其中结构学习是贝叶斯网络学习的重点和基础,目前在结构学习的领域已经研究发展了许多经典实用的算法,如爬山法[1],MMHC法[2]等,这些方法有扎实的理论支持,并且在各工程领域都得到了广泛的应用,但这些方法的实现和应用都是基于大规模数据集(完备或者经补充后完备),而在实际工程应用中,受限于环境、材料、时间等因素,很多实验往往不能够多次重复,使得能够获得的实验数据较少,样本规模很小,这样的小样本数据集里能够表达的信息不够完整,许多数据的统计因子缺失,由此进行的贝叶斯网络结构学习的准确性和可靠性无法保证。由此衍生出基于小样本数据集的贝叶斯网络结构学习问题的研究。目前研究比较多的集中在两个方面,一种是研究基于小样本数据集直接进行学习得到主体结构,然后利用数据修正等性质进行优化[3],另一种是通过拓展数据集来增加样本规模[4],以此提高结构学习的可靠性。基于数据集的Bootstrap抽样是常用的数据拓展方法,但传统的Bootstrap抽样是对数据集的可重复抽样,没有增加额外信息,学习效果无法得到实质性的改进。
在本文提出的算法中,将概率密度核估计的方法引入小数据集的拓展过程,将所得到的拓展数据集用于贝叶斯网络的深入学习,还通过计算互信息度确认了节点次序,较好地改善了Bootstrap抽样方法无法得到额外有效信息的缺点,弥补了K2算法需要确认节点先验次序的不足,有效地提高了贝叶斯网络结构的学习效果。
2 K2算法介绍
现有的贝叶斯网络结构学习方法分成两类,一类是基于评分搜索的学习方法,另一类是基于约束满足的学习方法[5]。其中评分搜索的方法过程简单规范,更被人们采用。Cooper提出的K2算法是简单经典的方法之一。K2算法的基本思想是定义评价网络结构模型优劣的评分测度函数,首先给定一个包含所有节点的变量顺序δ和最大父亲节点个数π。在搜索过程中,按给定顺序逐个考察δ中变量,确定其父亲节点,添加相应边。对变量 Xj,假设已经找到的父亲节点为πj。如果 Xj的父亲节点个数还未达到最大值π,即|πj|<π,则应继续考察δ中排在 Xj之前而还不是 Xj父亲节点的变量,在其中继续寻找父节点,操作步骤为:从这些变量中选出使得新网络评分Vnew达到最大的 Xi,然后将Vnew与旧网络评分Vold比较:如果Vnew>Vold,则 Xi为 Xj的父节点;当父亲节点数到达最大值或者网络评分无法提高时停止为Xj寻找父亲节点。其评测函数定义为:

学习流程伪代码为:

输入:X={X1,X2,…,Xn}为一组变量,δ为一个变量顺序,π为变量最大父亲节点个数,λ为完整的数据集。
输出:经过结构学习得到的贝叶斯网络。
ζ=由按照次序排列的全部节点组成的无边图

3 基于概率密度核估计的贝叶斯网络结构学习算法
传统的基于小样本数据集的贝叶斯网络结构学习问题通常采用Bootstrap[6-8]抽样方法来完成小样本的拓展,然后基于拓展后的数据集采用大规模数据集的结构学习算法完成学习。但由于Bootstrap抽样方法产生的样本只是来源于原样本,因此极有可能得到的拓展样本与原样本极为相似,且不会改善小样本集里的信息缺失的情况,特别在样本容量极小的情况下,这样的特性会使得概率分布集中于少量点,体现在学习得到的贝叶斯网络里便是这些点对应的连接边出现的概率较高,而原始小样本缺失的数据信息所对应的连接边无法得到补充。为改善Bootstrap抽样方法不能补充缺失数据的问题,本文以概率密度核估计的方法对原始小样本进行拓展得到大数据集,然后基于大数据集运用K2算法进行结构学习,由于概率密度核估计方法是估计概率密度分布后再进行重采样,因此可以有效补充小数据集缺失信息,以此进行结构学习得到的模型更加全面准确。
3.1 概率密度核估计
密度核估计(kernel density estimation)是估计未知概率密度函数的方法,是非参数检验方法之一,由Rosenblatt[9]和Emanuel Parzen[10]提出。密度核估计方法不利用有关数据分布的先验知识,对样本的总体分布不作任何假设,是一种从样本自身出发研究数据分布特征的方法,在统计学理论和应用领域均受到高度的重视。
设 X1,X2,…,Xn是从一维总体 X中抽出的独立同分布样本,X具有未知密度函数 f(x),x∈R,则 f(x)的核估计为:

其中 K(·)为 R=(-∞,+∞)上的Borel可测函数,称为核函数,在有意义的核估计里,核函数应当是概率密度函数,hn是个同n有关的正数,称为窗宽或带宽[11]。在独立同分布的情况下,核估计量具有逐点渐进无偏性和一致渐进无偏性、均方相合性、强相合性、一致强相合性等,这使得核估计在非参数密度估计中占有重要地位。
3.2 概率密度核估计参数优化
概率密度核估计的效果,既与样本规模n有关,也与核函数K(·)和窗宽h的选择有关,在给定样本的情况下,决定概率密度核估计性能好坏的变量就只有核函数K(·)和窗宽n。核函数的选择不是密度估计中最关键的因素,因为选用任何核函数都能保证密度估计具有稳定相合性。因此在实际工程应用中,只需选择满足一定条件的核函数即可。核函数的确定一般需要满足下列条件:(1)函数对称且 ∫K(t)dt=1;(2)一阶矩等于零,方差为有限值;(3)函数连续。常见的核函数有Epanechikov核、Parzen核、Triweight核等。见表1。

表1 常见核函数
常用来度量核估计性能的一种测度是积分均方误差MISE,表达式为:

对其进行展开计算,并略去高阶小量得到:

在上式中,第一项是估计的方差,第二项是偏差项。由此可知,当核函数固定时,若窗宽选得过大,偏差会随之变大,但方差能够得到抑制,此时x经过压缩变换之后 fn(x)对 f(x)有较大的平滑作用,淹没了密度的细节部分;若窗宽选得过小,偏差得到改善,但方差随之增加,这是因为此时引起了随机性影响的增加,fn(x)有较大的波动,f(x)的某些重要特性可能被掩盖。因此窗宽的选择需要同时考虑偏差和方差的影响。
3.3 基于贝叶斯网络概率密度核估计的小样本数据集拓展
贝叶斯网络得到的数据集为多维数据,数据维度取决于网络节点,且各维度之间存在相互关联和耦合,因此在贝叶斯网络的小样本数据拓展中,必须将数据集作为多维自耦合的整体来考察。
设将要学习的贝叶斯网络节点数为M,则可知得到的数据 X为 M 维变量,设 X1,X2,…,Xn为要得到的 X的样本,则由上文可知数据集X的概率密度函数 f(X)的核估计为:

其中:X=(x1,x2,…,xM)T,Xi=(xi1,xi2,…,xiM)T(i=1,2,…,n);h为窗宽,n为样本容量;S是 M×M 维对称样本协方差矩阵[12]。
依潘涅契科夫[13]经过统计研究得出,当概率密度核估计的窗宽系数确定时,核函数的不同对MISE的影响很小。本文以标准高斯函数作为核函数。标准高斯函数密度函数为:
在核函数固定的情况下,窗宽随数据规模的增大而减小。窗宽的确定应考虑数据集的密集程度变化,在数据集密集的部分,将窗宽选小一点,这样可以有效保留数据细节,保证数据集的精确可靠;在数据集稀疏的部分,将窗宽取大一些,这样可以剔除数据集毛刺,减小数据拓展开销。最优窗宽的具体计算方法很多。这里使用LSCV法。LSCV是基于积分平方误差(Integrated Square Error,ISE)最小准则的一种计算方法。对多维随机变量X ,ISE为:

式中最后一项与窗宽无关。LSCV就是取式中前两项进行最小化,即

多维数据样本集最简单的形式是二维数据样本,本文以此为例,验证多维数据核估计效果,取均值矩阵M=,协方差矩阵,样本采样率(样本集规模)N=300,得到仿真结果如图1所示。
由图可知,以二维数据样本为例的多维数据核估计取得了良好效果,所得概率密度函数十分贴近给定函数。
3.4 基于互信息度的变量顺序确定
传统的K2算法需要指定一个包含所有节点的变量顺序,而这个变量顺序在实际问题中通常是无法先验预知的。需要通过对样本数据的学习来识别最佳变量顺序,将其作为K2算法的输入变量之一,然后再利用K2算法对样本数据进行学习得到贝叶斯网络。本文提出一种基于互信息度确认变量顺序的方法。
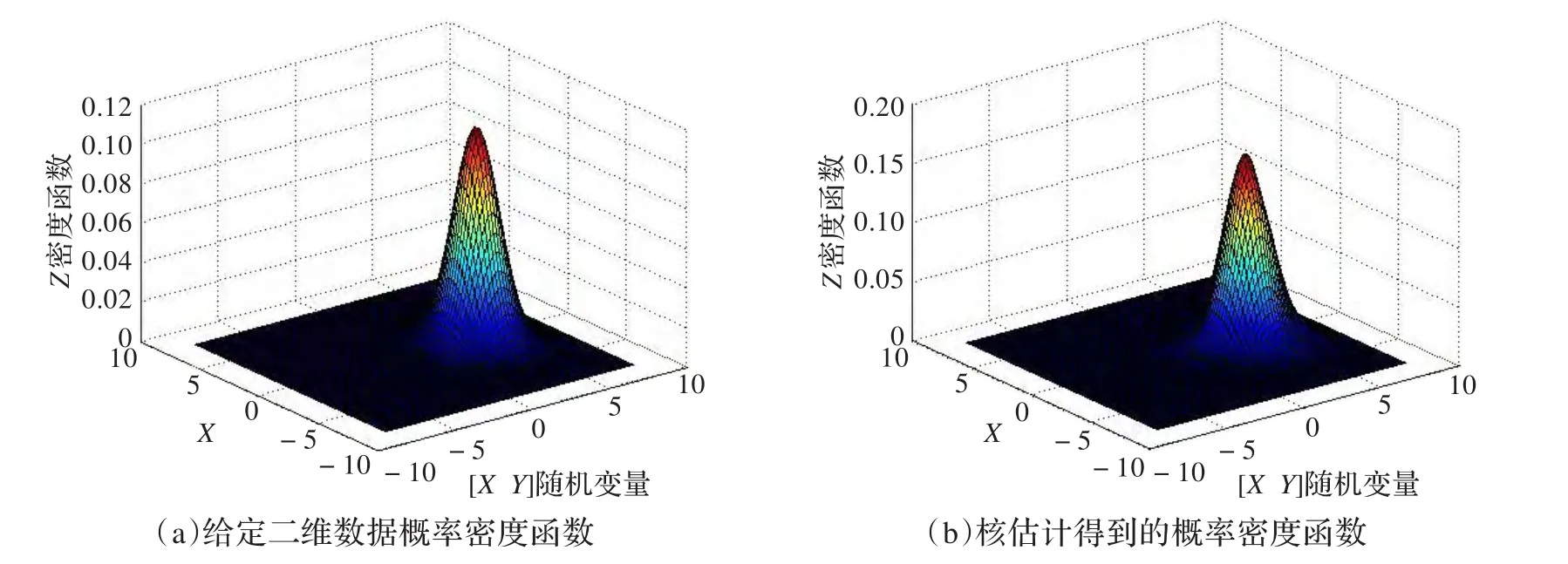
图1 维数据样本集核估计效果
两个变量之间的关联程度可用互信息度表示,记为I[X;Y],定义如下[14]:

其中H[X]表示随机变量X的信息熵,H[X|Y]表示给定Y条件下变量X的信息熵,定义如下:

其中,n和m分别表示随机变量X和Y的取值状态个数,根据互信息的定义,互信息度具有对称性,即I[X;Y]=I[Y;X]。
互信息度取值越大,表明两个变量间的联系越紧密,则两个节点间有边连接的可能性越大。基于这样的性质,可以构建一条节点链,具体步骤为:
(1)计算得到两两节点的互信息度Ii[Xi;Yi]。
(2)对互信息度Ii[Xi;Yi]进行降序排列。
(3)依据排列顺序,依次取出一对节点,判断两节点之间是否有边连接或者连接后是否形成回路,如果都没有,则在两个节点之间增加一条边。
(4)当所有节点都取完后,则形成一条节点链。
得到的节点链是一个无向节点链,作为K2算法的节点顺序输入,还需要确认节点链的方向,在样本集中提取小规模样本分别按照正向节点顺序δ1和反向节点顺序δ2的顺序利用K2算法进行结构学习,最终学习分别得到分数Score1和Score2,如果Score1>Score2,则取δ1作为变量顺序输入K2算法进行结构学习,反之取δ2作为结构变量高的顺序。
3.5 基于概率密度核估计的数据集拓展和K2结构学习
由上文可知,概率密度核估计的方法在进行多维数据样本的密度函数估计时取得了良好效果,在此基础上利用重抽样得到拓展数据集能有效克服Bootstrap抽样方法样本单一、数据集不确实的问题。
K2算法是网络结构学习中有效的打分搜索方法,但该算法要求具备大规模样本集以确保可以获得正确的网络结构,以及需要已知输入网络节点的逻辑次序。由于在实际应用中,多数情况下难以获得大规模样本集,也不是每个网络都能够得到先验的节点顺序,因此K2算法在工程实际的应用受到限制。本文将概率密度核估计、互信息度学习以及K2算法结合,提出基于小规模数据集学习的KI-K2贝叶斯网络结构学习算法,算法流程如图2所示。

图2 KI-K2算法流程图

表2 数据设计表
KI-K2算法以概率密度核估计来进行原始数据集拓展,同时利用互信息度进行节点次序确认,然后与K2算法学习网络结构相结合进行网络学习,这种算法能够充分发挥概率密度核估计在数据集拓展上的优势,为后期网络结构学习提供相对全面准确的样本数据,同时将互信息度确认节点次序与K2算法相结合,能够最大限度地保留独立性测试高效与K2算法快速准确的特点,使得K2算法摆脱节点次序这一先验输入的限制,在实际工程问题中更具有实用性。
4 仿真验证
以贝叶斯网络为工具,来评估导弹拦截系统的效能,以此为实例来进行学习验证本文提出的KI-K2算法的性能。
弹道导弹防御系统一般由搜索探测系统、指挥控制系统、跟踪制导系统、拦截弹系统、评估系统组成[15]。评判其效能有以下指标:
(1)作战能力。主要包括:预警探测能力、跟踪能力、通信能力、拦截能力等。
(2)生存能力。
(3)可靠性。
假定拦截系统为PAC-3(“爱国者”-3)末段低层拦截系统,进攻弹为“潘兴”-2中程战术弹道导弹。仿真实例为PAC-3多次拦截1枚弹道导弹。可靠实验数据表明,其贝叶斯网络节点可设计如表2。
导弹拦截系统全因素贝叶斯模型如图3所示。

图3 导弹拦截系统全因素贝叶斯模型
实验过程中共选取实验设计中的7个因素(见表3),并对每个因素取值进行离散化得到2个状态。

表3 最终数据设计表
得到贝叶斯网络如图4所示。
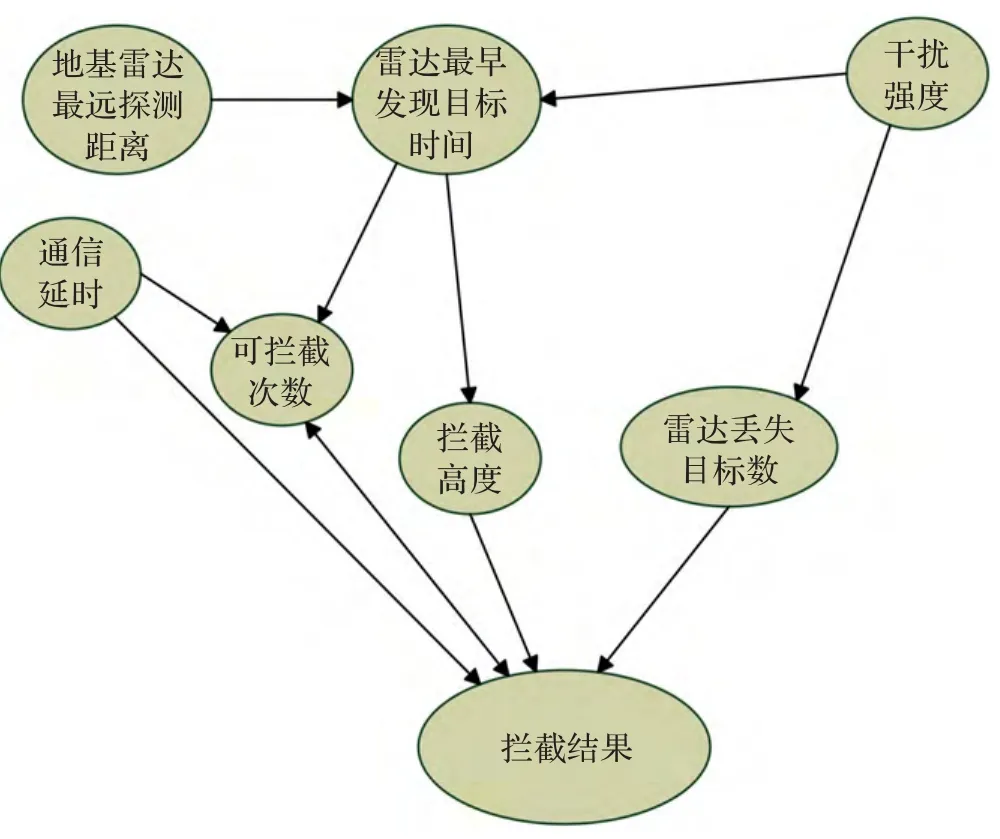
图4 生成贝叶斯网络
将均匀分布生成的随机数与节点的条件概率对比便可实现对节点的采样,基于给定的贝叶斯网络结构,按照网络结构顺序依次对节点进行采样便可生成对此网络的一组随机采样数据。利用Matlab贝叶斯网络工具箱里面的sample_bnet函数可产生规模为N的小数据集,然后基于数据集使用Bootstrap方法以及概率密度核估计的方法分别进行数据拓展,然后利用K2算法进行结构学习,最后进行比较。
本文采取的各个参数如下:Bootstrap抽样为原数据规模10倍,密度核估计选取核函数为高斯函数。为减少偶然误差,实验重复进行10次,取平均值作为实验结果输出。
实验环境为:硬件为Intel®CoreTMi5-2310 2.90 GHz 2.89 GHz;操作系统为Windows XP;编程软件为matlabR2010a。
用IE代表学习结构比原网络结构多的边,ME代表学习结构比原网络结构缺的边,RE代表学习结构与原网络结构相比反转的边,分别取原始样本数N=1 000,500和100,得到仿真结果如表4~6所示。
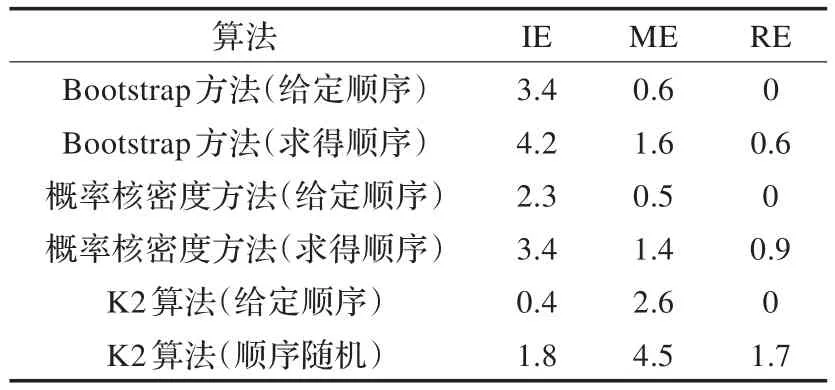
表4 原始样本数N=1 000时各算法仿真效果

表5 原始样本数N=500时各算法仿真效果
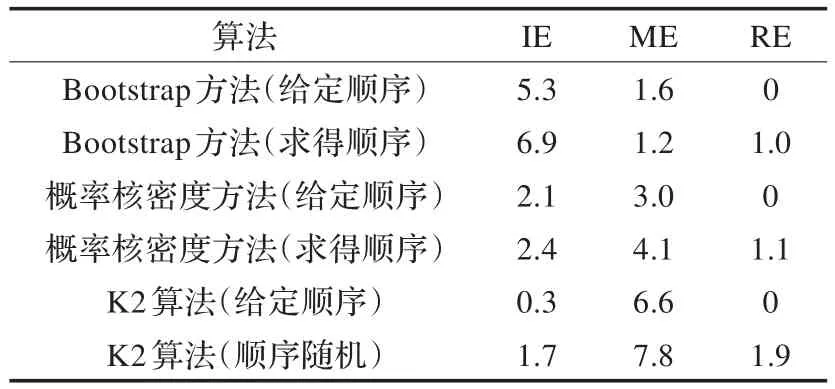
表6 原始样本数N=100时各算法仿真效果
由实验结果可知:
(1)小样本数据集条件下,概率密度核估计拓展数据集后进行贝叶斯网络结构学习效果比Bootstrap抽样方法拓展数据后进行结构学习的效果好,随着数据集减小,学习误差增大,但该算法效果优越性越明显。
(2)小样本数据集条件下,给定先验节点顺序的概率密度核估计拓展数据集后进行贝叶斯网络结构学习效果同样优于给定先验节点顺序的K2算法,随着数据集减小,学习误差增大,但该算法效果优越性越明显。
(3)小样本数据集条件下,基于互信息度求得先验节点顺序的概率密度核估计拓展数据集后进行贝叶斯网络结构学习效果与给定先验节点顺序的K2算法基本持平,优于随机顺序的K2学习算法,证明该算法确实有效,改善了必须指定节点顺序的不足。
(4)采用指定节点顺序的K2算法进行结构学习的话反向的边一直等于0是因为K2算法得到了顺序的变量逻辑结构,因此不会产生反向的边。
5 结束语
本文提出了利用概率密度核估计方法对样本数据集进行拓展,利用互信息度推算节点逻辑顺序,然后基于拓展后的样本数据集将确认的节点顺序进行贝叶斯网络结构学习的算法,最后通过仿真验证可以看到,本文提出的算法具有较强的结构学习能力和良好的学习速度,在实际工程背景下是一种可靠高效的结构学习方法。
[1]Cooper G F,Herskovits E.A Bayesian method for the induction of probabilistic networks from data[J].Machine Learning,1992,9(4):309-347.
[2]何德琳,程勇,赵瑞莲.基于MMHC算法的贝叶斯网络结构学习算法研究[J].北京工商大学学报:自然科学版,2008,26(3):43-48.
[3]王双成,冷翠平,李小琳.小数据集的贝叶斯网络结构学习[J].自动化学报,2009,35(8):1063-1070.
[4]Borchani H,Amor N B,Khalfallah F.Learning and evaluating Bayesian network equivalence classes from incomplete data[J].International Journal of Pattern Recognition and Artificial Intelligence,2008,22(2):253-278.
[5]金焱,胡云安,张瑾,等.K2与模拟退火相结合的贝叶斯网络结构学习[J].东南大学学报:自然科学版,2012,42(S1):82-86.
[6]Efron B.Bootstrap methods:another look at the jackknife[J].The Annals of Statistics,1979,7(1):1-26.
[7]陈峰,杨珉.Bootstrap估计及其应用[J].中国卫生统计,1997,14(5):5-7.
[8]刘伟,龙琼,陈芳,等.Bootstrap方法的几点思考[J].飞行器测控学报,2007,26(5):78-81.
[9]Rosenblatt M.Remarks on some nonparametric estimates of a density function[J].The Annals of Mathematical Statistics,1956,27(3):832-837.
[10]Parzen E.On estimation of a probability density function and mode[J].The Annals of Mathematical Statistics,1962,33(3):1065-1076.
[11]郭照庄,霍东升,孙月芳.密度核估计中窗宽选择的一种新方法[J].佳木斯大学学报:自然科学版,2008,26(3):401-403.
[12]李德旺,陈兴,喻达磊,等.多维密度核估计的Bootstrap逼近[J].西南大学学报:自然科学版,2007,29(11):34-37.
[13]Epanechnikov V A.Nonparametric estimation of a multidimensional probability density[J].Theory of Probability Application,1969,14(1):153-158.
[14]Herskovits E.Computer-based probabilistic-network construction[D].Stanford:Stanford University,1991.
[15]禹磊,唐硕.基于贝叶斯网络模型的导弹防御效能评估研究[J].飞行器测控学报,2012,31(5):89-94.
猜你喜欢
数学学习与研究(2020年15期)2020-11-28
数理化解题研究(2017年4期)2017-05-04
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
电子器件(2015年5期)2015-12-29
智能系统学报(2015年4期)2015-12-27
数学年刊A辑(中文版)(2015年1期)2015-10-30
河北建筑工程学院学报(2015年2期)2015-04-29
