
无线网络中基于强化学习的拥塞控制算法改进
2014-04-03 02:18
自动化仪表 2014年6期
(西南科技大学信息工程学院,四川 绵阳 621010)
0 引言
TCP协议以其可靠性、端到端、定向的传输服务被广泛应用于各种网络。它主要包括慢启动、拥塞避免、快速恢复和拥塞处理4个阶段[1]。TCP采用拥塞窗口(cwnd)来解决网络中的拥塞,以上4个阶段根据不同的环境状态改变cwnd值,以适应网络。虽然现有TCP协议应用广泛,但对于链路带宽不对称、节点运动不规则的无线网络而言,其在拥塞判断和决策处理上容易使网络出现拥塞、传播延迟过大等情况。主要原因是拥塞判断方式单一以及不合理的cwnd变化方式。拥塞判断方式单一指TCP在拥塞避免和快速恢复阶段分别采用往返时延(round-trip time,RTT)和重复确认(acknowledgement,ACK)决定cwnd值增长和判断拥塞状态,这种方式在无线网络下易出现不能正确判断丢包或拥塞的现象。因cwnd值表征此时网络节点可以传输的数据包大小,不合理的cwnd变化方式易使网络在不必要的时候减少网络吞吐量。
1 算法描述
针对TCP拥塞控制,文献[2]对往返时延进行压扩,动态改变加性因子大小。文献[3]根据前向链路的转发跳数对TCP拥塞窗口增长速率进行控制。文献[4]采用一种类似学习的TCP思想,对网络状态进行学习,反馈动作作用后结果,智能选择加性因子大小。文献[2]~[4]都忽略了拥塞控制协议中乘性因子对网络拥塞产生的影响。文献[5]对近年来多种AIMD拥塞控制算法进行对比和分析,结果表明,针对无线网络而言,99%的丢包来自于拥塞。文献[6]在高速网络应用下给出了一种学习拥塞控制算法,有效提升了TCP协议在快速网络下的性能,但该算法须对接收端、发送端以及路由进行改进,实施性不强。
到目前为止,解决现有TCP拥塞控制协议在无线网络中出现的性能问题受到业界的广泛关注。为使TCP在无线网络下拥有更好的性能,本文提出一种基于AIMD的网络动态学习算法,即NewReno-RF。通过进一步学习网络带宽表征量,动态设计cwnd值的变化方式。同时考虑协议自动感知环境和强化决策控制协同作用在整体拥塞控制中的改进对网络性能的影响。
NewReno-RF算法整体思想如图1所示。算法通过AI加法因子和MD乘法因子两部分中的cwnd进行动态调整。
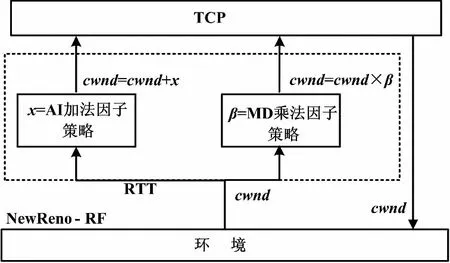
图1 NewReno-RF算法整体思想框图
1.1 AI加法因子策略
对于无线网络而言,往返时延(RTT)值随着网络不断更新。当RTT值较小时,网络带宽充裕,可以承载更多数据量;当RTT值增大时,网络负载增大。此时,AI协议应采取更为有效的拥塞避免措施,使网络带宽利用率最大。因此,本文在AI阶段对RTT作进一步判断,动态决定加性因子大小。
1.1.1 RTT量化
本文对RTT进行进一步量化,将区间[RTTmin,RTTmax]均匀量化为M个区间。量化间隔如式(1)所示。
Δv=(RTTmax-RTTmin)/M
(1)
当mi-1≤RTT≤mi时,量化器输出m=i(i=1,2,…,M),其中mi=RTTmin+Δv×i。对任意RTT,相应的输出m作为加性因子选取的判断条件。
1.1.2cwnd加性因子选取
本文对加性因子x选取采用如下函数关系。
(2)
式中:m为RTT量化值;T为m的量度;α为滚降因子,范围为[0,1]。
函数将根据m的大小输出不同比例的加法因子,使cwnd的增长适应网络变化。函数可根据网络的不同需求,改变α滚降因子的值来得到不同特性的加性因子。
1.2 MD乘法因子策略
对于网络传输而言,怎样充分利用带宽传输数据是本文需解决的难题。TCP仅依靠重复ACK来判断拥塞,单一对cwnd值减半的做法不能充分地利用网络带宽。本文将MD阶段视为一个有限状态的离散马尔科夫决策过程(MDP),利用强化学习策略,对无线信道带宽作进一步学习,动态改变cwnd乘性因子,最终达到充分利用带宽、提高网络性能的目的。
强化学习把学习看作是一种“试探—评价”的过程。首先学习系统(称为智能体)感知环境状态,采取某一个动作作用于环境,环境接受该动作后状态发生变化,同时给出一个回报反馈。强化学习系统根据强化信号和环境的当前状态再选择下一个动作,选择的原则是使折扣期望回报最大。本文采用强化学习中的Q学习算法,它是一种与模型无关的强化学习算法[6]。
1.2.1 状态和动作值描述
Q学习算法中状态值和动作值的选取须结合MD阶段特性。网络中节点变动、信道变化时刻会触发系统状态的改变。因此,本文将MD阶段的cwndmax(即当前时段内cwnd峰值)作为Q学习模型状态(s)值。
学习策略是一个在当前状态(s)下从可能的动作集中随机选择动作,即故意执行一种目前不是最优的动作来获得关于那些未知状态的知识[7]。当建立了足够多的样本值之后,系统将利用Q值来选择当前状态的下一最优动作值。为确保探索的有效性,本文结合现有系统的乘法因子特性,采用与之相近的随机值,以求找到系统动作最优解。
1.2.2 回报值的设计
本文将cwndmax归一化为R(0,1),衡量某一动作在该状态下的性能好坏。转换关系如式(3)、式(4)所示。
(3)
(4)
式中:BM为当前系统认为表现较好的cwndmax的均值,即满足当前AIMD阶段持续时间与之平均持续时间差值εt和实时cwndmax与平均cwndmax的差值εcm在一定范围内的cwndmax;cw为实时cwndmax。
为使R归一化为(0,1),δ取固定值-2。当cw越接近BM,R越接近于1,当前动作对当前状态的影响越大;当cw相对BM越小,则R越接近于0。
1.2.3Q学习算法
Q学习算法的基本形式为Q*(s,a),表明在状态s下执行动作a所得到的最优奖赏值的和,如式(5)所示。
(5)
式中:T(st,at,st+1)为学习系统在时间步t时由于采取行动at,而使环境从状态st转移到状态st+1的转移概率。
最优策略π*(s,a),即在状态s下执行动作a使得:
(6)
Q学习可直接优化一个迭代公式(7)来获得最优策略。更新系统Q值表,选取下一状态的最优动作解。
(7)
式中:Q(st,at)为旧Q值;Rt+1为状态st的下一状态st+1所对应at回报值;αt(s,a)(0<α<1)为学习效率,若αt(s,a)衰减合适,即满足条件∑∞n=0αnt(s,a)=∞,∑∞n=0[αnt(s,a)]2<∞,且所有状态-动作对都能被无穷次访问更新Q值,则Q值最终将依概率1收敛于Q*,其收敛性已得到证明[8];0<γQ<1为折扣因子,γQ如取值较小,则表示Q学习策略更关注最近动作的影响,如取值大,则表示当前Q值要受系统较长时间状态动作对的影响;maxQ(st+1,at+1)为状态st的下一状态st+1所对应动作at产生最大Q回报值。
在每一个离散的时间步t中,智能体感知当前状态st,执行相应动作at,给出回报值Rt,并产生一个后继状态st+1。在无线网络环境初始时,系统对于所有状态的Q值和回报值都默认为0。因此,针对式(7),Q值将变成0。为使系统不产生此种情况,本文在系统初始时,采用式(8)更新Q值。
(8)
式中:γR(0,1)为回报函数的折扣率,γR的取值表明当前回报值函数受前向回报的影响大小。
2 算法实现
根据上述分析,基于AIMD的TCP改进算法NewReno-RF的分析如下。
① 初始化系统中所需各固定参数。
② 重复步骤③~⑥。
③ 由式(1)得到m,由式(2)更新加法因子x,cwnd=cwnd+x。
④ 根据当前状态执行的动作,由式(4)得到γ,Q(R)←γ;根据式(7)、式(8)更新Q值。
⑤ 选择当前st中Q最大对应的at,执行此时乘法因子at。
⑥ 根据AIMD持续时间和cwndmax大小更新BM。
3 场景设置及结果分析
本文基于网络模拟器(network simulator,NS),实现改进算法NewReno-RF。其中量化区间M为16,滚降因子α=0.72,cwndmax选取差值范围低于平均量的5%。为满足收敛条件,本文设置学习效率αt(s,a)=0.2。系统建立足够样本之前,设置式(8)中回报函数折扣率γR=0.3,以使当前状态受回报折扣影响较小。进入Q学习值迭代系统,即利用式(7)对MD阶段进行优化,折扣因子γQ=0.95,充分考虑前向回报对系统的影响。本文讨论所述协议在两种网络场景下的性能情况。为和现实试验环境匹配,两种场景都规定各节点的传输能耗。根据文献[9]对NS2中能量模型和无线传输模型的说明,场景设置为室外自由空间。本文采用阴影无线传输模型,路径损耗指数βs为2.0,阴影方差σdB为4.0。NS中实现的能量模型是一个节点的属性,表示一个主机的能量水平[9]。本文中设置各个节点初始能量1 000 W,发送能量0.660 W,接收能量0.395 W以及天线增益5.5 dBi,高度1 m。
3.1 场景一
本文所述场景一为随机Ad hoc网络。本文对该场景进行N(N≥10)次仿真试验,试验场景中节点随机分布。大体遵循以下规则:10个节点初始位置随机分布,在场景大小为1 000 m×1 000 m内以最大10 m/s的速度随机运动,仿真开始10 s即在n5和n4间建立TCP数据传输,直至结束。仿真结果在相应点取N次平均。在Ad hoc网络下,改进NewReno-RF算法和NewReno协议在吞吐量、传播延迟和重传率方面的性能状况如图2所示。
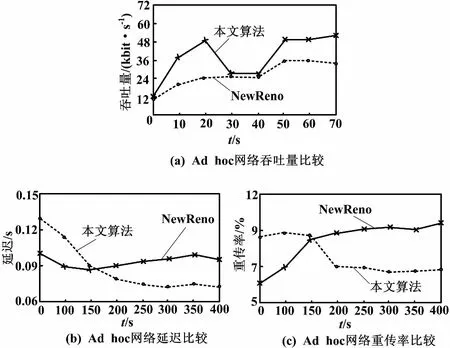
图2 Ad hoc网络仿真结果
由图2可以看出,由于Ad hoc网络中节点运动的随机性,协议在各时段表现不平稳。但总体而言,NewReno-RF在吞吐量上一直高于NewReno,平均提升了40%。传播延迟和重传率方面则总是低于NewReno,分别平均减少11%和27%。
3.2 场景二
场景二为在无线多跳链式网络下对改进协议进行N(N≥10)次仿真试验。链式网络拓朴模型如图3所示。试验中,场景大小1 000 m×1 000 m,N次仿真试验于n5和n4间建立TCP数据传输,开始时间在10 s内随机分布。场景中节点初始位置略有不同,但节点运动曲线和速度基本一致。各节点保持不超过10 m/s的链式匀速运动,运动过程中两节点间距离保持不变。仿真结果在相应点取10次平均,如图4所示。

图3 链式网络拓扑模型

图4 链式网络仿真结果
由图4可以看出,虽然NewReno-RF协议初始时由于对环境感知的不完全性,在吞吐量、传播延迟、重传率上都表现不稳定,但随着学习次数的增多,NewReno-RF性能逐渐优于NewReno。重传率呈现大幅降低的趋势,平均降低34%;传播延迟同比减少了17%;NewReno-RF吞吐量比NewReno平均提升53%。
4 结束语
随着网络的日益发展,现有TCP协议不足以满足其复杂性、多样性的需求。本文提出一种基于AIMD拥塞控制协议的改进算法,加入量化和强化学习理念,提高了TCP协议在网络传输方面性能。通过和现有版本TCP-NewReno在两种传输模型上进行多次仿真比较,结果表明,改进协议在传播延迟、吞吐量、重传率方面都有明显提升。
[1] Ghassan A A,Mahamod I,Kasmiran J.Exploration and evaluation of traditional TCP congestion control techniques[J].Computer and Information Sciences,2012,24(2):145-155.
[2] 刘俊.拥塞窗口自适应的TCP拥塞避免算法[J].计算机应用,2011,31(6):1472-1475.
[3] 宋军,李浩,李媛源,等.Ad Hoc中的TCP改进方案-Adaptive ADTCP[J].计算机应用,2010,30(7):1750-1756.
[4] Badarla V,Murthy C S R.Learning-TCP:A stochastic approach for efficient update in TCP congestion window in Ad Hoc wireless networks[J].Journal of Parallel and Distributied Computing,2011,71(6):863-878.
[5] Hiroki N,Nirwan A,Nei K.Wireless loss-tolerant congestion control protocol based on dynamic AIMD theory[J].IEEE Wireless Communications,2010,17(2):7-14.
[6] 褚建华.Q-Learning强化学习算法改进及其应用研究[D].北京:北京化工大学,2009.
[7] Kento T,Junichi M.A study on use of prior information for acceleration of reinforcement learning[C]∥SICE Annual Conference,2011:537-543.
[8] Nicholas M,Mihaela V S.Reinforcement learning for energy-efficient wireless communications[C]∥IEEE Transactions on Signal Processing,2011:6262-6266.
[9] NS2.The network simulator ns-2[EB/OL].[2010-10-25].http://www.isi.edu/nsnam/ns.
[10]Marek G,Daniel K.Online learning of shaping rewards in reinforcement learning[J].Neural Networks,2010,23:541-550.
[11]Maryam S.Knowledge ofopposite actions for reinforcement learning[J].Applied Soft Computing,2011(11):4097-4109.
[12]Nadim P,Anirban M,Carey W.An analytic throughput model for TCP NewReno[J].IEEE/ACM Transmission on Networking,2010,18(2):448-461.
猜你喜欢
载人航天(2021年5期)2021-11-20
聊城大学学报(自然科学版)(2020年1期)2020-11-27
科学导报(2020年51期)2020-09-09
铁道通信信号(2020年12期)2020-03-29
小学生作文(低年级适用)(2019年5期)2019-07-26
读友·少年文学(清雅版)(2018年12期)2018-04-04
消费导刊(2017年24期)2018-01-31
中央民族大学学报(自然科学版)(2016年1期)2016-06-27
山东青年(2016年3期)2016-02-28
中国烟草科学(2012年5期)2012-07-31
