
改进谱聚类算法在多模型软测量中的应用
2014-04-03 02:23:12
自动化仪表 2014年6期
(南京工业大学自动化与电气工程学院,江苏 南京 211816)
0 引言
在化工过程和很多其他工业应用领域中,由于大多数系统存在机理复杂、高度非线性、强耦合、大时滞等特点,采用单一的软测量模型无法全面地描述复杂系统的全局特性,并且存在回归精度低和泛化能力差等问题。
为了解决上述问题,一种能够提高系统模型精度和泛化能力的多模型软测量建模方法应运而生[1-3]。仲蔚等[4]提出模糊C均值聚类和径向基核函数(radial basis function,RBF)网络相结合的策略来进行多模型建模。现场应用表明,该方法易于实现且具有更好的泛化结果和预报精度。周立芳等[5]提出基于K均值聚类算法的多模型预测控制,试验证明了多模型建模的模型精度和泛化特性。然而,传统的聚类算法如K均值算法、模糊C均值算法等都是建立在凸球形的样本空间上,当样本空间不为凸球形时,算法将会陷入局部最优。
针对传统聚类方法存在的问题,本文提出一种基于改进谱聚类的多模型建模算法。该算法具有识别非凸分布聚类的能力,不会陷入局部最优解,且能避免数据的维数过高所造成的奇异性问题,以便得到更加精确的聚类结果,提高模型精度。样本聚类后,采用最小二乘支持向量机(least square-support vector machine,LS-SVM)建立各子类模型,并采用粒子群(particle swarm optimization,PSO)算法对多模型权值进行寻优,系统软测量模型输出可视作各子模型的加权组合。本文所研究方法在丙烯精馏塔塔顶丙烯含量软测量中进行了应用研究,结果表明,该方法具有较高的精度和良好的泛化性能。
1 谱聚类算法
1.1 标准谱聚类算法
谱聚类是建立在图论中谱图理论的基础上[6],将聚类问题转化为一个无向图的最优划分问题的过程,其本质是通过Laplacian Eigenmap实现降维的过程。谱聚类的思想来源于谱图划分理论,将每个样本数据看作图中的顶点V,根据样本间的相似度将相应顶点之间的连接边E赋权重W,从而得到基于样本相似度的无向加权图G=(V,E,W)。此时,可以将聚类问题转化为在图G上的图划分问题。根据图论的划分理论来看,谱聚类的本质就是使得划分后的子图之间相似度最小[7],子图内部相似度最大。
根据准则函数和谱映射方法的不同,谱聚类算法有多种实现方法。实现过程一般分为三步:①定义数据样本点之间的相似性度量,建立数据点之间的相似矩阵;②通过计算相似矩阵的前k个特征值与特征向量,构建新的数据特征空间;③采用K均值或者其他传统聚类算法对特征空间中的特征向量进行聚类。
虽然K均值算法实现简单,可以重复运行而不受初始化的影响,但是K均值算法也有一些致命的缺点,如不能处理非球型簇以及不同尺寸和不同密度的簇,对于含有离群点的聚类也不太适应。同时,K均值算法是一种贪心算法,经常会陷入局部最优解。然而,谱聚类算法只需要数据之间的相似度矩阵,不必像K均值算法那样要求数据必须是N维欧氏空间向量。因此,本文采用改进谱聚类算法来克服K均值算法的缺点,从而得到准确的聚类结果,提高模型精度。
1.2 改进的谱聚类算法
在谱聚类算法中,特征值和特征值向量的选择对聚类结果影响很大,而特征值和特征向量的选择以聚类分组数为依据[8]。因此,本文采用基于特征差值与正交特征向量的改进谱聚类算法,对标准谱聚类算法进行改进,实现聚类数目的自动确定。谱聚类算法的基本思想是:先利用样本数据构建相似矩阵,然后对由相似矩阵生成的规范化相似矩阵进行谱分解,从而得到相应的特征值和特征向量;随后对特征值按降序排列,并用本征间隙来表述相邻特征值之间的差,通过第一个极大本征间隙出现的位置来自动确定类个数;最后结合获得的类个数和特征向量之间的夹角实现数据分类。本文选择规范割集划分准则来实现谱聚类算法。
设输入数据集为S={S1,S2,…,Sn},且S为Rn空间中待聚类的数据集;输出为聚类分组数k和聚类结果。聚类算法具体步骤如下。
① 构造数据集的亲和(相似)矩阵Wij,Wij=exp(-‖Si-Sj‖2/2δ2),i≠j,且Wii=0,其中δ为阈值参数。
② 构造拉普拉斯矩阵L=D-1/2AD1/2,D为对角矩阵,其对角元素为Dii=∑Wik。
③ 求解拉普拉斯矩阵L的特征值(λ1,λ2,…,λn)及其对应的特征向量(η1,η2,…,ηn)。
④ 计算特征值差值g1,g2,…,gn-1,其中gi=λi-λi+1。

⑥ 构造矩阵X=[x1,x2,…,xk],其中x1,x2,…,xk为拉普拉斯矩阵L的前k个特征值对应的特征向量。
⑦ 对矩阵X中的每一行进行单位化处理,得到矩阵Y。
⑧ 将Y中的每一行看作Rk空间中的一个点,并对其使用K均值算法,得到k类样本子集,如果矩阵Y中第i行属于第j类,则Xi也属于第j类。
根据矩阵的摄动理论,当第k和(k+1)个特征值之间的差值越大时,所选的k个特征向量构成的子空间就越稳定。此时,以矩阵Y中的每一行作为k维空间中的一个点,形成k个聚类。它们将彼此正交地分布于k维空间中的单位球上,且在单位球上形成的这k个聚类对应着原来空间中所有点形成的k个聚类。由此根据拉普拉斯矩阵的特征值之间的差值来确定类个数,其中差值取[0.06,0.1]。
与标准谱聚类算法相比,改进后的谱聚类算法可以自动确定聚类个数[9],对样本数据建立规范化相似矩阵并进行谱分解;利用本征间隙自动确定样本数据的类个数;根据确定的类个数和谱分解后的特征向量间的夹角,实现样本数据的分类。
2 基于LS-SVM的子模型建模
支持向量机是一种小样本学习理论,它的基本思想是采用结构风险最小化原则构造最优决策函数[10],解决样本空间中高度非线性回归问题。最小二乘支持向量机(LS-SVM)是一种改进的支持向量机,它将求解二次规划问题转化为求解线性方程组[11],解决了一般标准支持向量机求解凸二次规划问题所带来的复杂度的问题,提高了学习速度。LS-SVM算法的优化问题描述如下。
(1)
式中:φ(xi)为核空间映射函数;ω为权矢量;ei为误差变量;b为偏差量;γ为正则化参数。
为了求解上述优化问题,需要把有约束优化问题变为无约束优化[14]。为此建立相应的Lagrange函数:
(2)
根据KKT(Karush-Kuhn-Tucher)最优条件,得到如下线性方程组:
(3)
式中:y=y(y1,y2,…,yl);e=[1,1,…,1]T;α=(α1,α2,…,αl)T为拉格朗日乘子;Ωij=φT(xi)φ(xj)=K(xi,xj)为核函数(核函数采用径向基核函数)。
因此,LS-SVM算法的优化问题转化为求解线性方程组(3),最终可得到LS-SVM的模型表达式为:
(4)
3 软测量多模型建模
本文软测量多模型建立步骤如下。首先,采用改进谱聚类算法对训练样本集X1聚类,得到n个类别,对各类建立LS-SVM子模型;然后,根据欧氏距离将测试样本集X2中的测试样本点划分到相应的子模型中,得到相应的子模型输出yi(i=1,…,n);最后,将各子模型按照“加权方式”进行组合,得到系统模型输出Y,完成多模型的建立。基于改进谱聚类算法的软测量多模型结构如图1所示。
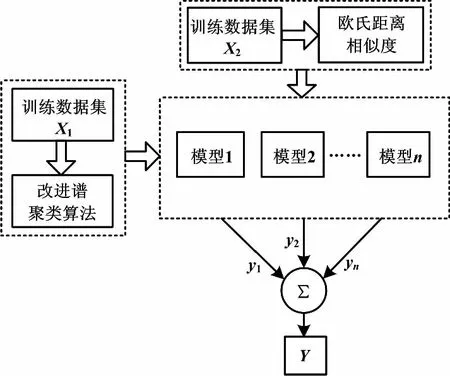
图1 多模型软测量系统结构图
在辨识出系统各个子模型的基础上,按照“加权方式”进行组合,得到系统的软测量模型输出。描述如下:
(5)
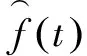
粒子群算法是一种适应性较强的全局优化算法,能够快速找到合适的权向量[12]。本文采用粒子群算法对多模型权值进行寻优,算法步骤如下。
① 初始化粒子种群及参数,设定多模型中加权系数个数n、粒子数目c;对于第i个粒子,将每个加权系数作为粒子i的位置编码;计算各粒子的适应度,设置粒子i的初始速度为0。反复进行,生成m个粒子。
② 由初始化粒子群得到粒子的个体最优位置Pid(i)和全局最优位置Pgd。
③ 更新初始化粒子的速度和位置,惯性因子ξ按式(6)计算:
(6)
式中:D为当前迭代次数;Dmax为最大迭代次数;ξmax=1,ξmin=0。
④ 对于每一个粒子i,比较它们的适应度函数和经历过的最好位置的适应度值Pid(i),若更好,则更新Pid(i)。
⑤ 对于每个粒子i,比较它们的适应度值和群体所经历的最好位置Pgd的适应度值,若更好,则更新Pgd。
⑥ 检查终止条件(是否到达设定迭代次数)。若条件满足,迭代终止,输出全局最优加权解,否则返回步骤③。
4 仿真实例
丙烯是重要的石油化工基础原料,用于生产聚丙烯、苯酚、丙酮等。丙烯精馏塔中丙烯浓度是重要的质量指标,人工采样离线分析的方法存在长时间滞后问题,不利于生产过程的在线检测与控制。因此,本文将基于改进谱聚类的多模型软测量建模方法应用于丙烯生产过程中质量指标的预测。
根据丙烯生产工艺,选择塔顶温度、进料量温度、回流温度、进料压力、塔釜压力、回流量、塔釜液位以及回流罐液位作为输入变量,丙烯含量作为输出变量。将现场采集的样本数据进行异常样本数据的剔除,对输入变量的样本数据进行归一化处理,得到150组样本数据,其中100组用于训练模型,50组作为测试。采用改进谱聚类算法进行聚类的步骤如下。
首先,用改进谱聚类算法对训练样本聚类,样本数据被自动聚为3类,分别建立子模型;然后根据欧氏距离将测试样本归类,用相应的子模型预测输出;最后,根据粒子群算法求解多模型权值,将建立的子模型按照“加权方式”组合,得到丙烯质量指标的软测量模型。
为了验证本文方法的有效性,分别采用基于K均值-LS-SVM多模型建模(分类参数取为2)和基于LS-SVM单模型建模,然后与本文方法进行比较。同时,采用均方根误差(root-mean-square error,RMSE)和最大绝对误差(maximum absolute error,MAXE)来评价模型预测性能。
(7)
(8)
式中:f(xi)和y(xi)分别为模型的输出值和真实值;n为样本个数。
根据试验结果,3种方法的模型测试误差比较结果如表1所示。
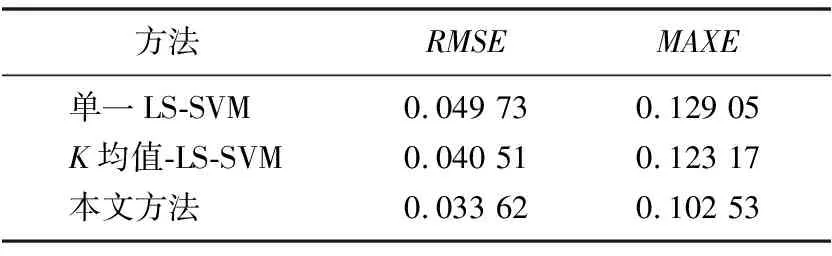
表1 模型预测误差
精馏塔塔顶丙烯质量指标的3种方法模型预测结果如图2~图4所示。
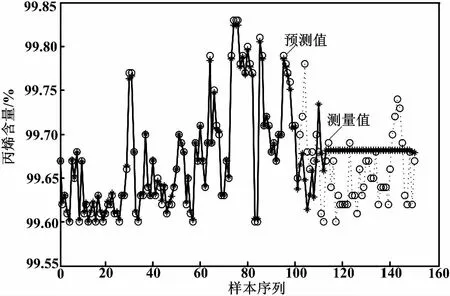
图2 单一LS-SVM模型预测
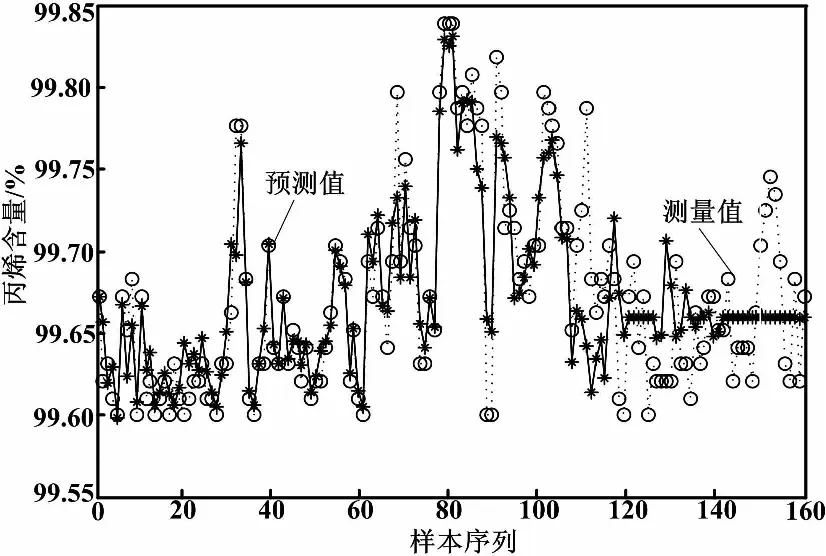
图3 K均值LS-SVM多模型预测
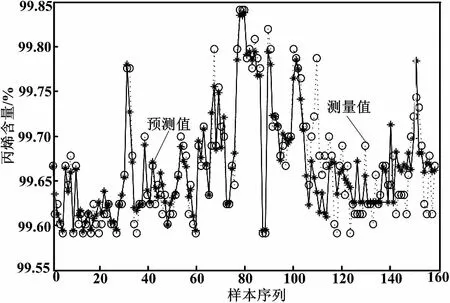
图4 改进谱聚类LS-SVM多模型预测
由表1可以看出,采用本文提出的方法得到的模型均方根误差(RMSE)和最大绝大值误差(MAXE)均体现了该方法的优势。
比较图2、图3和图4的预测结果可知,本文方法建立的模型较其他建模方法具有更好的跟踪效果,说明了本文方法的有效性。
5 结束语
本文提出的基于SC-LS-SVM多模型建模方法,通过改进谱聚类算法对样本数据进行聚类,对各子类样本建立LS-SVM子模型,采用粒子群算法对多模型权值进行寻优,并将子模型按照“加权方式”进行组合,得到系统软测量模型。将该方法应用于丙烯精馏塔塔顶丙烯含量的软测量建模中,通过仿真试验对比,本文方法可以较好地跟踪丙烯质量指标的变化,具有更好的模型预测精度。
[1] 王孝红,刘文光,于宏亮.工业过程软测量研究[J].济南大学学报:自然科学版,2009,23(1):80-86.
[2] Petr K,Bogdan G,Sibylle S.Data-driven soft sensors in the process industry[J].Computers and Chemical Engineering,2009,33(4):795-814.
[3] Fortuna L,Graziani S,Rizzo A.Soft sensors for monitoring and control of industrial processes[M].London:Springer,2007.
[4] 仲蔚,俞金寿.基于模糊c均值聚类的多模型软测量建模[J].华东理工大学学报:自然科学版,2000,26(1):83-87.
[5] 周立芳,张赫男.基于聚类多模型建模的多模态预测控制[J].化工学报,2008,59(10):2546-2552.
[6] Luxburg U V.A tutorial on spectral clustering[J].Statistics and Computing,2007,17(4):395-416.
[7] 戴月明,高倩.自适应半监督模糊谱聚类算法[J].计算机工程与应用,2010,46(33):212-214.
[8] Zhao F,Jiao L C,Liu H Q,et al.Spectral clustering with eigenvector selection based on entropy ranking[J].Neurocomputing,2010,73(10-12):1704-1717.
[9] Ng A Y,Jordan M I,Weiss Y.On spectral clustering:analysis and an algorithm[C]//Cambridge:MIT Press,2002:121-526.
[10]Vapnik V N.The nature of statistical learning theory[M].New York:Springer Verlag,1995.
[11]Suykens J A K,Vandewale J.Least squares support vector machine classifiers[J].Neural Processing Letters,1999,9(3):293-300.
[12]Kennedy J,Eberhart R C.Particle swarm optimization[C]//Proceedings of 1995 IEEE International Conference on Neural Networks,New York,1995:1942-1948.
猜你喜欢
扬子江诗刊(2023年3期)2023-05-06 10:40:14
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
大众文艺(2022年16期)2022-09-07 03:08:04
保定学院学报(2022年2期)2022-04-07 02:26:50
数学物理学报(2021年5期)2021-11-19 07:01:12
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:40
农药科学与管理(2019年5期)2019-08-13 00:48:02
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
当代化工研究(2016年7期)2016-03-20 16:21:55
