
半监督流形正则化算法检测应用层DDoS 攻击研究
2014-04-01 00:57康松林樊晓平刘楚楚李宏安隆熙
中南大学学报(自然科学版) 2014年12期
康松林,樊晓平, ,刘楚楚,李宏,安隆熙
(1. 中南大学 信息科学与工程学院,湖南 长沙,410083;2. 湖南财政经济学院 网络化系统研究所,湖南 长沙,410205)
随着网络技术日新月异的发展,网络安全遭受着越来越大的威胁。其中,分布式拒绝服务攻击(DDoS)是当今网络安全的最大威胁之一。DDoS 攻击分为网络层DDoS 攻击和应用层DDoS 攻击。应用层DDoS攻击具有低速率、合法报文和标记样本获取难等特点,因此,比传统的网络层DDoS 攻击更具隐蔽性和破坏力。应用层DDoS 攻击主要针对Web,DNS 以及SMTP 3 类服务,其中针对Web 应用的攻击占据应用层DDoS攻击的61%,Web 网站服务器是应用层DDoS 的首要攻击目标。近年来,对于Web DDoS 攻击的检测技术不断涌现,从总体上分为2 种:第1 种是根据用户浏览行为的统计特征来区分攻击流和正常流。如Giralte等[1]提出了对Web 服务器的请求路径和访问时间等特征,Devi 等[2]提出了平均访问时间、网页请求序列等特征,他们都通过比较正常用户与异常用户的上述特征统计量来达到检测攻击目的。类似地,王风宇等[3]提出的Web 群体外联行为以及Jeyanthi 等[4]提出的网络流量信息熵等都属于这一种。这种基于用户浏览行为统计特征的方法取得了很好的效果,但这种单一的统计特征很难应付现今复杂多变的攻击形式。第2 种是基于机器学习的异常检测方法。如Kumar 等[5]用神经网络方法对日志记录进行有监督的分类;Stevanovic等[6]分别用2 种无监督学习算法SOM 以及modified ART2 对网络日志记录进行分类。因为机器学习具有很好的智能性,使得基于有监督学习和无监督学习算法应用于应用层DDoS 攻击检测格外引人关注。但在实际网络环境中,获得大量的有标记的网络信息较困难,需要投入大量人力和物力,并且有监督学习算法并没有利用到数据集的内在几何分布结构,因此,训练出来的分类器很难具有很强的泛化能力。而无监督学习算法虽然训练样本较容易获得,但它又未利用到标记信息的宝贵信息,这对训练效果产生不利影响。近年来出现了不少半监督学习方法,如阳时来等[7]提出一种基于半监督GHSOM 的入侵检测方法,该算法利用少量有标签的数据指导大规模无标签数据的聚类过程,与无监督的GHSOM 算法相比,具有较高的检测率。半监督学习方法主要包括generative models、自训练方法、直推学习、半监督流形学习等。其中,半监督流行学习由于受到谱图聚类[8]和图结构化核迅速发展的影响,在学界受到了广泛关注。半监督流形学习算法可以由正则化框架[9-10]来描述。对已辨识样本的损失函数加上光滑正则项,使整个图的标识尽可能光滑。这种学习算法能够挖掘数据的内在结构,使判决函数更加精确,可以达到更好的分类效果。在实际的网络环境中,用于应用层Web DDoS 攻击检测的训练数据集是大量原始未标记的样本,人工标记的样本只占很少一部分,因此,本文提出用半监督流形正则化算法检测Web DDoS 攻击。
1 相关工作
1.1 半监督流形正则化
数据分类时,获取足够多且有质量保证的标记样本需要花费大量人力和时间。在少量标记样本的基础上挖掘大量未标记样本中宝贵的有效信息则成为数据分类的关键。小样本的学习问题使得半监督学习倍受青睐。半监督学习是基于有监督学习和无监督学习的机器学习算法。未标记样本能提供的仅仅是有关边缘分布的知识,若这部分知识与目标问题不相关,则引入未标记样本不会带来实际帮助。事实上,所有半监督学习算法都直接或间接地通过某种模型假设来建立未标记样本与目标问题的联系。本文作者基于平滑假设和流形假设提出一种基于图的半监督算法——流形正则化。
流形正则化用加权邻接图表示数据的局部几何特性,图的节点表示样本,边的权重则反映样本的相似度信息。样本间的距离通过图上的最小路径得到[11-12]。直观地讲,样本的条件分布在数据的邻接图上变化平缓,在具体实现中往往用基于图的正则项修正其在图上的不平滑性。
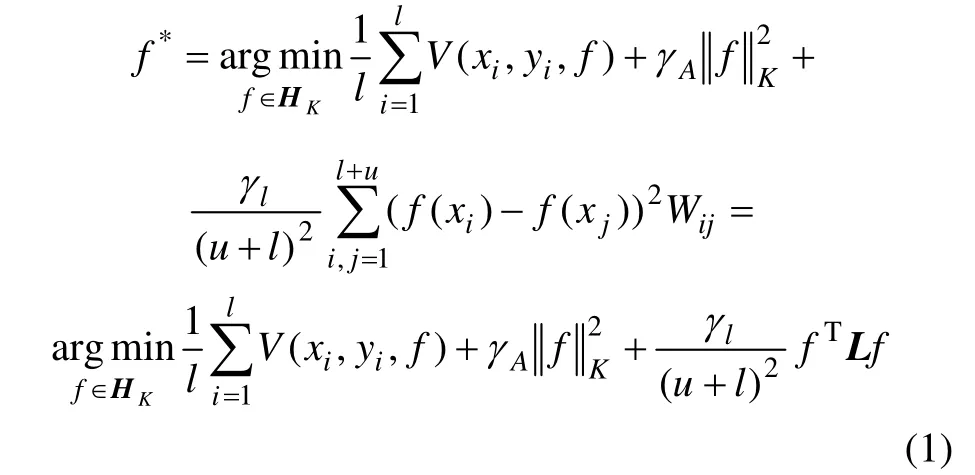
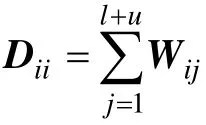
1.2 拉普拉斯正则化最小二乘法


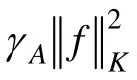
根据Representer Theorem 定理[9],可以得到1 个l+u 维变量α=[α1,α2,…,αl+u]T的凸可微目标函数:
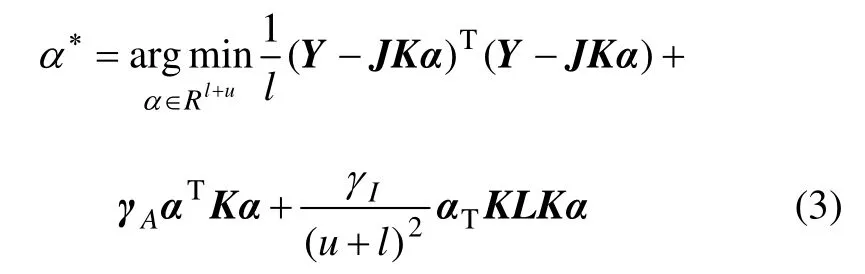
其中:K 为基于标记和未标记点的(l+u)×(l+u)维的格拉姆矩阵; Y 为(l+u) 维的标签向量,Y=[ y1,… ,yl,0,…,0];J 为1 个对角全由1 和0 组成的对角矩阵,J=diag(1,…,1,0,…0)。根据文献[9],解得
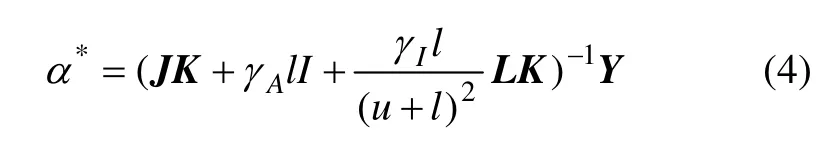
2 Web DDoS 攻击检测
2.1 Web DDoS 攻击检测流程图
基于半监督流形正则化的小样本Web DDoS 攻击检测方法分为2 步:第1 步,在1 个时间窗口内以IP地址或域名为标识,将过滤后的Web 日志映射到1 个14 维的特征空间以描述用户的访问行为;第2 步,采用Laprls 最小二乘法对小样本数据进行分类预测以区分正常用户与非正常用户。具体流程如图1 所示。
2.2 Web 日志中用户行为特征提取
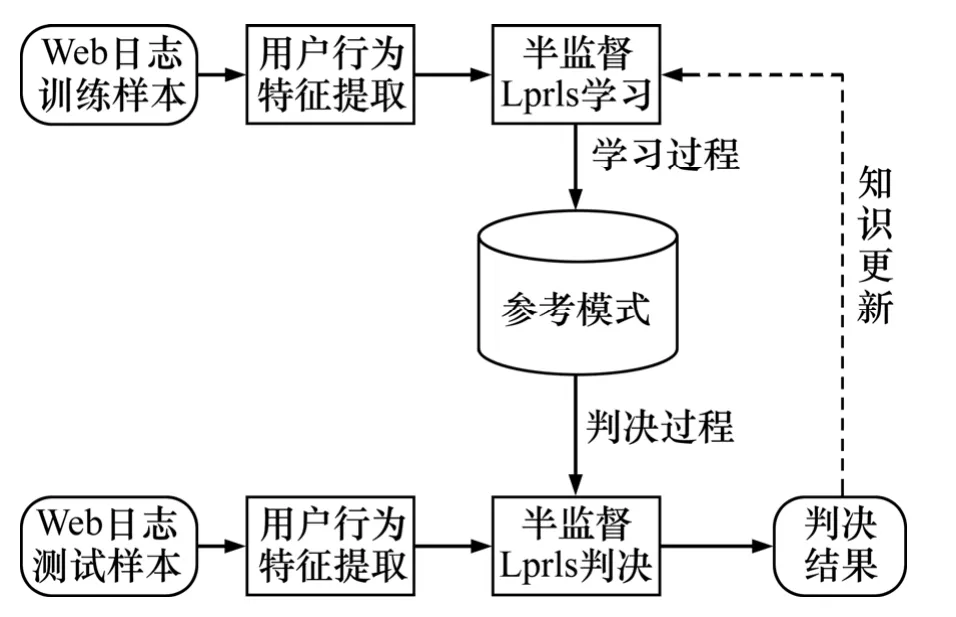
图1 Web DDoS 攻击检测流程图Fig.1 Flow chart of Web DDos detection
网站日志是记录Web 服务器接收处理请求以及运行时产生错误等各种原始信息的文件。网站日志蕴含着大量的访问信息,但若直接用于构造数据集进行分类预测,则会造成时间和成本浪费。下面研究如何在服务端的网站日志中提取有效的特征来描述用户的访问行为,以区分攻击用户和合法用户。
在网站日志中,每条记录代表1 次用户的访问行为。而用户的1 次点击行为可以造成网站日志中的多条记录,如鼠标仅点击1 次,浏览器却发出很多HTTP GET 请求,包含主页面的对象请求和嵌入式对象的请求(包括各种gif,jpeg,js,ico 和CSS 等)。因此,首先要把这些嵌入的对象过滤,将访问的主页面对象取出来。主页面一般是以/,htm,html 和shtml 等结尾的静态页面的URL,以及以.asp,jsp,.cgi,.php 和.peri结尾或者较长且包含符号“? ”的动态页面URL。
在过滤掉冗余的嵌入式对象请求后,网络日志仍然不能直接用于建模分析。这是因为过滤掉的仅仅是用户1 次点击所产生的冗余信息,而用户的1 次浏览行为中只有1 次点击的很少,所以,刻画用户的访问行为不能以单次点击作为1 个示例进行研究。为此,本文提出在1 个时间窗口内以IP 地址或域名为标识,分析用户行为特征,将过滤后的网站日志投射到1 个14 维的特征空间以描述用户的访问行为。特征属性如表1 所示。
通过对用户行为特征的提取,把每条原始日志信息变为1 个14 维的矩阵,其中:1~13 列为提取的用户行为特征;14 列为标签属性。通过特征提取后的数据集可以直接用于分类预测,为Laprls 最小化二乘法检测应用层Web DDoS 攻击奠定了基础。
2.3 流形正则化攻击检测算法


表1 特征属性Table 1 Feature attributions
输出:估计函数f :Rn→R;
步骤1:使用( l+ u)节点构造数据邻接图。选择边权重Wij。即若xi为xj的邻居结点,则Wij=1 ,否则Wij=0。
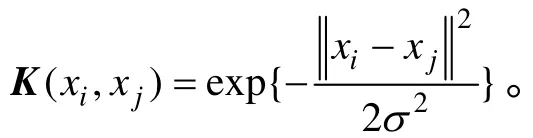
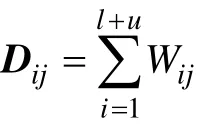
步骤4:经验选择正则化参数 γA和 γI,根据式(4)计算 α*。
算法利用少量标记样本和大量未标记样本一起参与图的建立,进而用图来逼近流形。由于流形假设高维的数据位于低维的流形上,利用流形可以帮助寻找高维数据空间内隐含的光滑低维流形和挖掘数据的内在结构得到更精确的判决函数[16]。此外,一个单核的SVM 分类器[17]对于处理多源或多属性复杂数据集可能是无效的。而多个内核可以对应多个不同源的信息或相似性等概念,同时可以表现不同特征之间的差异。因此,扩展了LapSVM 到多核的场合[18],即拉普拉斯算子的多内核学习,提高更复杂数据的半监督分类能力。算法根据判决函数对测试样本集进行判决分类,以区分正常用户与非正常用户,达到更好的分类效果。
3 实验结果与分析
3.1 实验数据集与Web DDoS 攻击仿真
实验正常用户记录来自于真实的ClarkNet-HTTP数据集,该数据集记录了美国马里兰州埃利科特城英特网服务提供商ClarkNet 的正常用户访问数据。记录时间跨度为14 d,共有3 328 587 条记录。数据格式为网站日志。
由于ClarkNet-HTTP 数据集数据量巨大,因此,将时间窗口设置为1 h 并截取其中21 459 条用户访问记录,通过对干扰请求对象过滤后提取3 423 条页面请求记录。
将攻击工具产生的攻击数据与从真实数据集提取出来的3 423 条记录混合形成Web DDoS 攻击检测数据集。将这个数据集根据表1 中的特征映射到14 维向量空间得到包含1 395条正常用户记录和4 000条攻击用户记录的数据集。仿真程序开发平台采用Visual Studio 2008 C#。
实验仿真了4 种常见的应用层Web DDoS 攻击:
1) 单URL 重复攻击,以固定或者随机速率反复请求单一页面。
2) 多URL 重复攻击,以固定或者随机速率请求多个不同的页面。
3) 基于页面链接的随机选择,扫描网站的所有页面,以固定或者随机速率随机地请求网站中的页面。
4) 会话重放DDoS 攻击,攻击者通过周期性模仿正常用户浏览过程发送恶意请求。
3.2 特征选择合理性验证
实验采用朴素贝叶斯概率分类算法、贝叶斯网络概率分类算法和C4.5 决策树分类算法来评价提取的特征是否合理。评价指标使用总体准确率、检出率和误检率。定义:
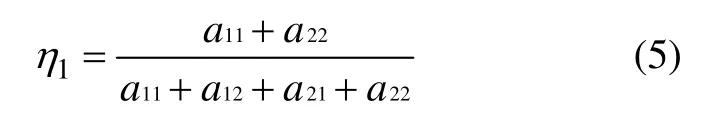

其中:η1为总体准确率;η2为检出率;η3为误检率;a11为本属于攻击用户被正确预测为攻击用户的样本数量;a12为本属于攻击用户被错误预测为合法用户的样本数量;a21为本属于合法用户被错误预测为攻击用户的样本数量;a22为本属于合法用户被正确预测为合法用户的样本数量。表2 所示为实验结果,其中序号1 为单URL 重复攻击,序号2 为多URL 重复攻击,序号3 为基于页面链接的随机选择攻击,序号4 为会话重放DDoS 攻击。
从表2 可以看出:这3 种分类器对这4 种攻击的检出率都为1,即能够完全检测出这4 种攻击,说明本文所提出的检测方法能够很好地区分合法用户与这4 种攻击类型的非法用户;但同时对每一种攻击的检测都存在少量误检。这是由于应用层DDoS 攻击模拟正常用户的访问行为,导致分类器错将该类型攻击用户分为合法用户。
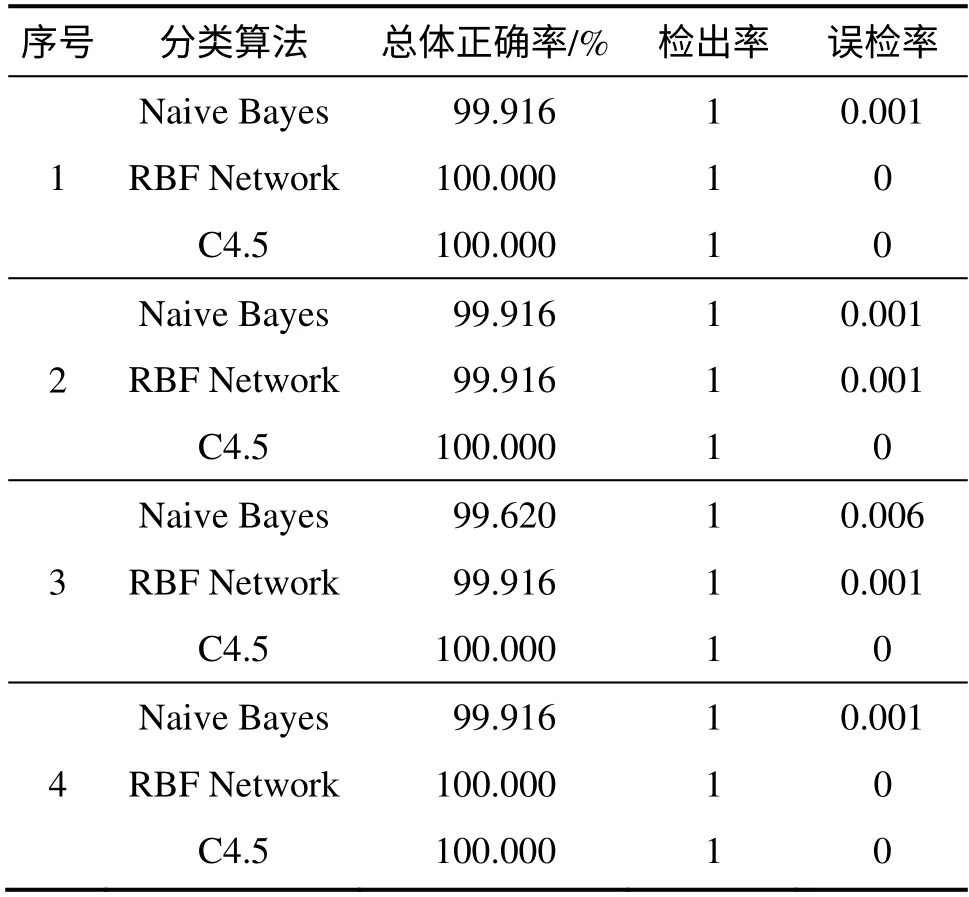
表2 4 种应用层DDoS 攻击检测结果Table 2 Test results of four types of DDoS attack on application layer
3.3 不同标记样本数的比较
从表3 可以看出:在只有极少数标记样本,例如标记样本数为2,4,8 时,Laprls 的正确率仍在80%以上,而其他几种算法的正确率却低于68%;随着标记样本数量的增加,各种算法的正确率都有所增加,但在这种少量标记样本的前提下,SVM,RLS 和K-NN的正确率还是大大低于Laprls 的正确率。随着标记样本的增加,SVM 和RLS 的正确率波动比较明显,而Laprls 的变化比较平缓。这是因为SVM 和RLS 依赖于对标记信息的学习,因此,随着标记数目的变化,正确率有明显浮动;而对于半监督的Laprls 最小二乘法,既可以利用无标记样本又可以利用有标记样本学习。因此,在小样本情况下,Laprls 算法有很高的的正确率,同时也具有很好的鲁棒性。

表3 不同标记样本数时各检测算法的正确率Table 3 Correct rate of algorithms for different number of labelled samples %
3.4 相同标记样本与不同未标记样本的比较
为了验证不同算法对未标记样本的学习利用情况,在实验中保持标记样本数量不变,不断增加未标记样本数量,观察不同算法在未标记样本增加的情况下正确率的变化情况。实验中保持训练样本中标记样本数量为10 不变,未标记样本从200 到500,每50增加1 次。每次实验循环20 次求平均值,实验结果如图2 所示。
从图2 可以看到:在相同标记样本数、不同未标记样本数的情况下,Laprls 的正确率有所提高,而RLS,SVM 和K-NN 这3 种算法的正确率在小范围内有所波动。因为RLS 和SVM 是利用有限的标记样本进行学习,而当标记样本数目不变时,对RLS 和SVM的影响不大。但标记样本占总样本的比例有所变化,因而,这3 种算法的正确率会有所影响,在小范围内波动。而对于Laprls 算法,虽然标记样本没有变化,但随着未标记样本的增加,正确率也有所增加。这是因为基于Laprls 最小二乘法的半监督算法可以利用未标记信息学习数据内部的几何结构,从而对训练样本有更深层次的挖掘和学习。Laprls 正确率的提高并非随着未标记样本数目的增加而呈线性变化,因为流形正则化用加权邻接图表示数据的局部几何特性,尽管采用正则项对边的不平滑性做了修正,但是不平滑性仍然存在,所以,正确率出现波动性增加。由于样本噪声的存在,在标记样本与未标记样本比例小于10:400 时,正确率呈缓慢下滑趋势。
综合以上3 个实验可见:半监督Laprls 最小二乘法在小样本下可以获得很好的分类效果,可以利用更内在的信息达到区分正常用户与非正常用户的目的,适合于Web DDoS 攻击检测。
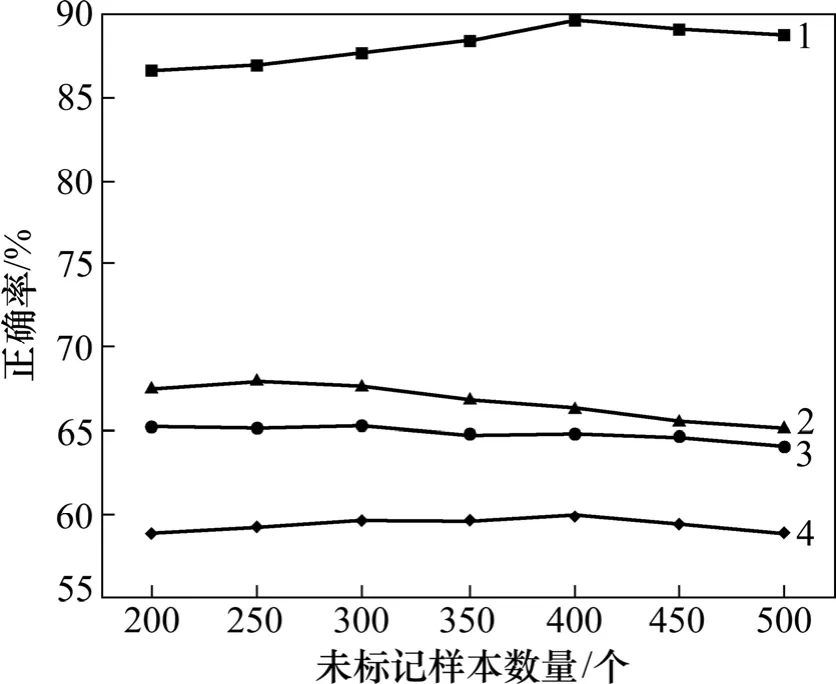
图2 未标记样本增量实验各算法的正确率比较Fig.2 Comparison of correct rate of different algorithms for unlabelled samples incremental experiment
4 结论
1) 提出了一种基于半监督流形正则化的小样本Web DDoS 攻击检测方法。该方法在对原始Web 日志进行用户行为特征提取的基础上,利用少量的标记样本进行学习的同时,利用大量无标记样本,挖掘数据的内在结构,使判决函数更加精确,达到区分正常用户与非法用户的目的。
2) 在少量标记样本的情况下,Laprls 最小二乘法比支持向量机(SVM)、最小乘方二乘法(RLS)和K-NN具有更好的分类效果。在现实网络环境中,这给获取标记样本需要付出很大代价的Web DDoS 攻击检测问题提供了解决方案。
3) Laprls 最小二乘法的正则化参数对于检测的影响以及如何提高检测实时性等有待进一步研究。
[1] Giralte L C, Conde C, Diego I M, et al. Detecting denial of service by modelling web-server behaviour[J]. Computers and Electrical Engineering, 2013, 39(7): 2252-2262.
[2] Devi S R, Yogesh P. A hybrid approach to counter application layer DDOS attacks[J]. International Journal on Cryptography and Information Security (IJCIS), 2012, 2(2): 45-52.
[3] 王风宇, 曹首峰, 肖军. 一种基于Web 群体外联行为的应用层DDoS 检测方法[J]. 软件学报, 2013, 24(6): 1263-1273.WANG Fengyu, CAO Shoufeng, XIAO Jun. Method of detecting application-layer DDoS based on the out-linking behavior of Web community[J]. Journal of Software, 2013, 24(6):1263-1273.
[4] Jeyanthi N, Iyengar N C H. An entropy based approach to detect and distinguish DDoS attacks from flash crowds in VoIP networks[J]. International Journal of Network Security, 2012,14(5): 257-269.
[5] Kumar P A, Selvakumar S. Distributed denial of service attack detection using an ensemble of neural classifier[J]. Computer Communications, 2011, 34(11): 1328-1341.
[6] Stevanovic D, Vlajic N, Aijun A. Detection of malicious and non-malicious website visitors using unsupervised neural network learning[J]. Applied Soft Computing, 2013, 13:698-708.
[7] 阳时来,杨雅辉,沈晴霓,等.一种基于半监督GHSOM 的入侵检测方法[J].计算机研究与发展, 2013, 50(11): 2375-2382.YANG Shilai, YANG Yahui, SHEN Qingni, et al. A method of intrusion detection based on semi-supervised GHSOM[J].Journal of Computer Research and Development, 2013, 50(11):2375-2382.
[8] Chapelle O, Weston J, Schölkopf B. Cluster kernels for semi-supervised learning[J]. Advances in Neural Information Processing Systems, 2003, 15(5): 585-592.
[9] Belkin M, Niyogi P, Sindhwani V. Manifold regularization: A geometric framework for learning from labeled and unlabeled examples[J]. Journal of Machine Learning Research, 2006, 7:2399-2434.
[10] Zhou D, Bousquet O, Lal T N. Learning with local and global consistency[J]. Advances in Neural Information Processing Systems, 2004, 16(3): 321-328.
[11] Yang T, Dongmei F. Semi-supervised classification with Laplacian multiple kernel learning[J]. Neurocomputing, 2014,140(22): 19-26.
[12] Chapelle O, Zien A. Semi-supervised classification by low density separation[C]//Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics.Bridgetown.Barbados, 2005: 57-64.
[13] Rifkin R M, Yeo G, Poggio T. Advances in Learning Theory:Methods, Model and Applications[M]. Amsterdam: IOS Press,2003: 68-103.
[14] Poggio T, Smale S. The mathematics of learning: Dealing with data[J]. Notices of the American Mathematical Society, 2003,50(5): 537-544.
[15] Zhang P, Peng J. SVM vs. regularized least squares classification[C]//17th International Conference on Pattern Recognition. New Orleans, USA, 2004: 176-179.
[16] 杨林聪, 夏志华. 针对空域LSB 匹配的隐藏信息检测方法[J].中南大学学报(自然科学版), 2013, 44(2): 612-618.YANG Lincong, XIA Zhihua. Steganalytic method based on spatial LSB matching[J]. Journal of Central South University(Science and Technology), 2013, 44(2): 612-618.
[17] 刘卫国, 胡勇刚. 基于SVM 和序列联配的攻击特征提取方法[J]. 中南大学学报(自然科学版), 2012, 43(11): 4328-4332.LIU Weiguo, HU Yonggang. Approach for attack signatures generating based on SVM and sequence alignment[J]. Journal of Central South University (Science and Technology), 2012,43(11): 4328-4332.
[18] Yang T, Fu D. Semi-supervised classification with Laplacian multiple kernel learning[J]. Neurocomputing, 2014, 140(1):19-26.
猜你喜欢
吉林大学学报(理学版)(2022年2期)2022-05-30
医学食疗与健康(2022年3期)2022-04-23
怀化学院学报(2021年5期)2021-12-01
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
中华养生保健(2020年7期)2020-11-16
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
科技风(2018年1期)2018-05-14
上海师范大学学报·自然科学版(2018年3期)2018-05-14
家教世界·创新阅读(2016年11期)2016-12-27
