
基于向量空间模型的文本风格相似度分析
——以女性文学为例
2014-03-21 03:28邢翠鹃
文教资料 2014年29期
邢翠鹃
(南京师范大学 文学院,江苏 南京 210097)
基于向量空间模型的文本风格相似度分析
——以女性文学为例
邢翠鹃
(南京师范大学 文学院,江苏 南京 210097)
本文主要用向量空间模型(Vector Space Model,VSM)来分析女性文学代表作家的作品,通过TF-IDF计算文本特征项的权重,最后根据计算结果来分析这些女性文学作家作品的文本风格相似度。并以此证明同时代不同作家或不同时代同类作家(女性文学作家)的文本是同中有异,异中有同,此外还分析了部分特征词的分布情况。
向量空间模型 TF-IDF 文本相似度 女性文学
引言:
文本中的相似度计算是自然语言处理领域中的关键问题之一,在信息检索、信息抽取、专利分析等领域都有着重要的应用价值。面对现代网络信息时代的海量信息,我们可以通过文本相似度算法来为信息分类,以提高信息检索的效率。早在20世纪30年代,西方文体学界即开始引入定量分析,尤其是统计学的方法[1],而将计算方法应用于汉语语言风格学研究最早始于20世纪70、80年代,人们用词频统计等方法来考证《红楼梦》的作者归属问题。这种方法也得到了我国语言风格学界一些学者的肯定,如黎运汉先生就专文论述了语言风格研究中常用的三种方法:分析综合法、比较法和统计法。他指出,“统计法适用于各种语言风格的研究”,因为“风格特点的质必然反映在语言因素的量上”,“风格学应用它提供的数据,从质和量的统一上研究风格现象,进而认识风格的本质”[2]。
1.向量空间模型[3]
向量空间模型是一种用来表示文档的方法,它的思想是将文档分解为由词条特征构成的向量。具体做法是将文档进行分词,然后计算文档中每个词条的权重,权重计算可以利用TF-IDF算法,由计算得到的权重构成一个矢量空间,即形成这个文档的向量空间。这里,文档(Document)用D来表示,如此这样,文档Dj就可以表示成如下的向量空间:
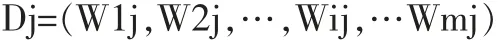
其中,m表示文档D中分词的特征词条数;Wij为词条ti在文档Dj中的权重。
向量空间模型假定某个文本di由一个特征向量(t1,t2,…,tn)表示,ti是出现在文本di中的特征项,n表文本di中各种不同特征项。特征项ti对应有一个特征权重wi=TF(wi,di)*IDF(wi),TF(wi,di)正比例于某个特征项在文本di中出现的频率,IDF(wi)反比例于某个特征项在文本集合中出现的频率。di对应于一个n维的向量Di=(w1,w2,…,wn),显然,特征权重度量了相应特征项的统计重要性。
TF-IDF是一种经典的基于统计分析的特征项权重计算方法。最早由G.salton在1973年提出①。TF(term frequency)是指关键词词频,即一篇文章中关键词出现的频率;IDF(inverse document frequency)是指逆向文本频率,即关键词在不同文档中的分布情况。它的基本思路是:一个词在一个文本中出现的频率越高,说明它区分该文本的能力越强(TF);一个词在不同文本中出现的范围越广,说明它区分文本的能力越低(IDF)。经过Salton的多次论证,信息检索领域广泛地使用TF-IDF算法计算权重,其经典计算公式为:

根据以上分析,容易获得两个直观结果:a)某个特征项在文本中出现的频率越高,则这个特征项对这个文本越具有标志能力,赋予这个特征项的特征权重应该越大;b)某个特征项在文本集合中各个文本内出现的频率越高,那么用这个特征项对文本集合中的文本进行分类的区分能力越弱。例如在英文文本中,“the”出现的频率很高,但是这个单词对各文本的区分能力却很差。
2.研究对象
女性文学是诞生于一定的社会历史条件下,以五四新文化运动为开端,具有现代人文精神内涵,以女性为经验主体、思维主体、审美主体和言说主体的文学。在这一界说之下,女性文学的视野是开放的、发展的系统,而不是封闭静止的,应该是女作家基于性别主体意识、生别视角表现的关注女性命运、女性情感、女性生命的文学,或者是基于超性别意识(隐含性别主体意识)、超性别视角(隐含性别视角)表现的包括女性生存在内的、具有人类普遍意义的文本。女性文学仍是一个有待探索和完善的命题。
中国的女性文学从五四时期到二十世纪九十年代共有三次高潮,每次高潮都有自己不同的主题和不同的具有代表性的作家作品,本文就选取了不同时期的十位作家——丁玲、萧红、张爱玲,杨绛,张洁,王安忆,铁凝,林白,陈染,魏微——的总计六十五部作品作为研究的对象。
3.实验过程
3.1 选取文本
首先根据研究需要,选取有代表性的女性文学作家十位及其代表作品总计六十五部,文本规模2247419词次。具体分布情况如下:

表1:语料分布情况表
3.2 文本预处理
选定语料后,对这些文本进行整理,主要是去掉一些无关的字符,例如:有关文档来源的电子链接等。
3.3 文本分词及词性标注
文本分词是文本分类的基础。简单地说,就是用分词算法把文本切分成字、词和短语。目前常用的自动分词方法有:
A.最大匹配法(Maximum Matching Word Segmentation)
正向最大匹配(MM):假如分词依据的词典中最长词条为n个字符,对待分词文本自左向右取n个字符,与词典进行匹配,若词典中存在该词条,则将该词条切分出去,继续取n个字符进行匹配,直到文本处理完毕;若词典中不存在该词条,则减去该词条最后一个字符,继续与词典进行匹配,重复该过程。还有逆向最大匹配法,过程与正向最大匹配法一样,不过方向是自右向左。最大匹配法分词方法的优点有:速度快、直观;与词表规模几乎无关;现代汉语语料(含一定未登录词)的分词精度在85%左右;其缺点有:几乎无法解决未登录词问题(只能猜对未登录的单字)、过于依赖词表,跨领域性较差、分词精度有待提高 (交集型歧义只能猜对一半;组合型歧义,只合不分)。其他的特点有切分一致度高。
B.最大概率法分词[7](Maximum Probability Word Segmentation)
又称为基于统计的分词方法。从形式上看,词是稳定的字的组合。相邻的字同现的次数越多,就越有可能构成一个词,因此字与字相邻共现的概率能够较好地反映成词的可信度。这种分词方法的基本思想是:一个待切分的汉字字符串可能包含多种分词结果,将其中概率最大的那个诈为该字串的分词结果。主要的语言统计模型和决策算法有:互信息、N元文法模型、最大熵模型等。其特点有:若每个词语的概率相等,则退化为最大匹配法、分词精度一般在90%左右、没有利用上下文信息,对交集型歧义字串采取千篇一律的切分方式、对于组合型歧义的消解基本无效、对于交集型歧义(伪歧义消解效果好、真歧义消解效果差[8]),对此可尝试利用词的转移概率(二元模型)。
词性标注(Part of Speech Tagging,POS)就是对文本中每一个词赋予相应的词性标记,包括对标点符号的标记。它代表了一个词的语法特征,也称语法标记、词语附码[17]。具体过程是从待分析词串中取一个Span:对词串中的每个词,查词库,(1)若查到,将该词所有词性标记取出,登记在数组Tags[i][j]中,i代表词的序号,j代表词性标记序号,将该词该标记的出现次数登记在Freqs[i][j]数组中;(2)若未查到,将开放类词性标记赋给该词,登记在Tags[i][j]中,将Freqs[i][j]的值置为1。对Span中的每个词的每个可能的词性标记;(3)计算该标记的累计费用;(4)记录该标记的最佳前驱标记当Span中最后一个词的词性标记确定下来后,顺次取出各词的最佳前驱标记,即得到词性标注结果。将Span类数据重新初始化,准备下一个Span的标注。例如:实现/v祖国/n的/u完全/a统一/vn,/w是/v海内外/s全体/n中国/ns人/n的/u共同/b心愿/n。/w(采用北京大学的词类标记集)
本文的语料是用最大概率法分词,用ICTCLS软件进行词性标注。之后又对其结果进行人工校对,修改了部分标注。接下来形成词频表。
3.4 去停用词
去停用词就是按照停用词表中的词语将语料中对文本内容识别意义不大但出现频率很高的词、符号、标点及乱码等去掉。一个句子,可能由名词、动词、形容词、副词、语气词等组成,而只有名词和动词能很好地标记文本,像有些副词如“非常”等和一些虚词“的、并且”等在文本中的出现频率很高,但是几乎不能标记文本,这类词就要用停用词表来去掉。
3.5 计算
首先利用公式算出每个文本的权值,再对其进行降序排列,从高到低依次选择权值比较大的2050个词语作为文本的特征项。由于特征项代表了一部作品中最重要的信息,因此文本的相似度就可以由特征项向量间的相似度来描述。
用VSM表示D1和D2两个文本向量:
D1=D1(w11,w12,…w1n)
D2=D2(w21,w22,…w2n)
如果使用N维空间中两个向量直接的距离来表示文本间的相似程度,设Sim(D1,D2)表示这种相似程度。一般使用向量间的内积,或两向量夹角的余弦值来表示相似系数Sim(D1,D2)。
(1)向量间的内积公式:

(2)向量夹角的余弦公式:
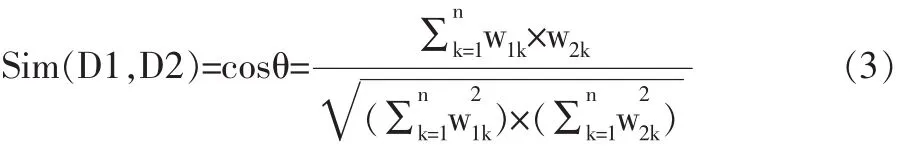
4.实验结果及分析
4.1 通过公式(3)计算得出中国女性文学不同时期六位代表作家作品之间的相似度如下:

表2:中国女性文学不同时期六位代表作家作品间的文本相似度
观察表1我们可以看到:女性文学的三个不同时期中,1)每个时期的两个代表作家之间的文本相似度都比较大,例如:张爱玲和萧红都是五四时期到五六十年代的女性文学作家,其文本相似度就是0.68,张洁和杨绛都是七八十年代我国女性文学的代表作家,其文本相似度就是0.52,陈染和杨绛都是九十年代我国女性文学的代表作家,其文本相似度就是0.84,其原因就是处于同一个社会环境中的作家文本风格会有一定程度的类似;2)不同时期的时期作家作品之间的文本相似度与前者相比就低一些,例如,张爱玲与不同时代作家作品之间文本相似度是0.07、0.55、0.13、0.09就明显比其与同时代的女性文学作家萧红的文本相似度0.68低一些,其他作家也都是类似情况,这正是由不同时代的不同社会环境以及作家自身的不同经历所造成的;3)总体来说,无论哪个时代女性文学作家之间的文本相似度还算比较稳定,因此这些作家都被定义为女性为学作家,其作品也就是女性文学作品,这是由于此类作家群 (包括历时的和共时的)基本都坚持女性主义思想,有鲜明的女性主义立场。
4.2 通过公式(1)计算得出一些有代表性的特征词的不同分布情况如下

图1:特征词权重分布图
在句子中,名词和动词是最具有标志性的词语,本文选出了四个名词(“现实、动物、友人、砖窑”)和四个动词(“预感、留心、吃醋、躲避”)分别分析(结果如表3):1)首先,每个词在不同的作家作品里都有不同的权重,例如动词“留心”在作家丁玲的作品中权重就明显高于其他作家的作品,而名词“友人”在作家陈染的作品中权重就明显高于其他作家作品;2)如果看同一个作家,有的作家相对偏向于使用某一些词语而不是另一些词语,而另外的作家则偏向于使用另外一些词语,例如作家丁玲,就多使用动词“留心”和“预感”,这首先是跟作家本人的敏感性格有关,另外也与作家本身身为女性的感性和细心以及其所处的社会环境有关。
5.结论
本文的实验证明,在比较大的文本语料中,使用基于TF-IDF加权的向量空间模型算法来计算文本相似度是比较可靠的,也就是说,我们可以把此方法推广到信息检索、专利分析等领域中。只是在不同的领域中应该加入其它的改进的加权算法,以进一步提高信息分类与识别的准确率。
注释:
①Salton G,Clement T Y.On the Construction of Effective Vocabularies for Information Retrieval[C]//Proc.of 1973 Meeting on Programming Languages and Information Retrieval.New York,USA:ACM Press,1973.
[1]曾毅平,朱晓文.计算方法在汉语风格学研究中的应用[J].福建师范大学学报(哲学社会科学版),2006(1): 14-17.
[2]黎运汉.汉语风格探索[M].北京:商务印书馆,1990.
[3]陶惠,张妍,郝光权.基于向量空间的文档聚类算法分析[J].电脑知识与技术,2011(7):4780.
[4]Zhongguo Li,Maosong Sun.Punctuation as Implicit Annotations for Chinese Word Segmentation[J].Computational Linguistics,2009(4):505-512.
[5]Shivakumar N,Garcia-Molina H.Building a scalable and accurate copy detection mechanism [C].Edward A.Fox,P Gary Marchionin.i International Conference on Digital Libraries,Maryland,United States:1996,160-168.
猜你喜欢
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
校园英语·月末(2021年13期)2021-03-15
信息安全研究(2016年4期)2016-12-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
外语学刊(2011年3期)2011-01-22
