
延迟容忍网络中基于邻居信息精确度的查询算法*
2014-03-12 05:17吴大猛钱江波陈叶芳董一鸿
电信科学 2014年4期
吴大猛,钱江波,陈叶芳,董一鸿
(宁波大学信息科学与工程学院 宁波 315211)
1 引言
随着移动无线通信技术的发展,越来越多的应用要求网络中的节点部分或全部具有移动性。例如,对野生动物进行监控和追踪以了解其生活习性的网络[1]、偏远地区的网络传输[2]及车载网络[3]等,这些网络的共同特点就是某一时刻网络中的源节点和目的节点不一定存在端到端的通信路径,数据的传输具有一定的延迟性。延迟容忍网络(delay tolerant network,DTN)模型[4]正是为解决这一问题而产生的。该网络泛指没有端到端传输路径的间断性连接的网络,其主要利用节点“存储—携带—转发”的通信模式实现数据传输。大量低成本、具备短距离无线通信能力的移动设备(如智能手机、PDA及掌上电脑)在生活中的普及进一步推动了延迟容忍网络的迅速发展。这些移动设备一般都具有吉比特字节的存储能力并且可以通过蓝牙[5]、IEEE 802.11[6]短程通信技术实现相互连接。在一个特定区域(如某商业区)内,移动设备利用无线通信技术相互连接形成一个区域内的延迟容忍网络,人们利用自己的移动设备搜索和共享信息资源(如MP3歌曲、电子书、广告信息等)。这种场景在生活中到处可见,比如在学校、商务中心、大型购物广场及机场等,每个移动设备自由移动,可以加入或离开网络。由于网络中移动设备的高度动态性,维护网络结构的代价非常高,一个合理的解决方案就是采取无结构的网络方式构建网络中的节点[7,8]。在这种方式下,移动设备仅动态维持其通信可达范围内的邻居移动设备信息。由于移动设备时刻移动,设备间的邻居关系变化很快,网络中的信息要不断地更新。
在实际应用中,很多用户期望能主动搜索自己想要的信息,比如搜索特定用途的信息、查找打折广告及下载音乐等。本文主要讨论在延迟容忍网络中为终端用户提供主动查询的方法。在延迟容忍网络中进行主动信息查询主要面临以下几个挑战:第一,网络没有全局索引;第二,由于移动设备计算能力、电池能量、通信带宽的限制,查询转发算法必须是轻量型、高能效的;第三,由于网络具有高动态性,查询算法必须适应频繁的数据更新及网络波动性。
为了解决上述问题,本文模拟社会网络[9]中的人类行为解决信息查询问题。用相关邻居节点的邻居信息(neighbor information)表示社会网络中的相识;用信息精确度(information accuracy,IA)估计所有邻居节点提供信息的精确度,从而帮助节点在其邻居节点中选择一个最优的后继节点将查询信息传送下去。邻居节点间的信息交换犹如人们之间的聊天,并在邻里范围内传播,可以帮助节点从其邻居节点处收集信息,同时节点也可以从自己的查询经验中学习。通过对社会网络的模仿,本文提出一种基于邻居信息精确度的方法,可以有效处理延迟容忍网络的查询请求。
本文主要贡献如下:
·基于社会网络中的模仿机制,模仿人类通过相识的人获取答案并从经验和闲谈中学习的自然行为,在延迟容忍网络中提出一个新的信息查询方法;
·本文提出的方法用于动态网络和数据需不断更新的环境,通过消耗模型分析能量消耗和通信消耗,证明本文提出的方法在高度动态的网络中有很好的适应性及稳定性。
2 相关工作
延迟容忍网络可用于间断连通的网络传输数据,其本质是一种机会网络[10]。由于网络中同一时刻可能不存在从源节点到目的节点的连通路径,因此需要充分利用节点移动的通信机会,采用“存储—携带—转发”的模式转发消息。
近年来,研究人员针对DTN环境下的数据传输,提出了多种查询转发机制[11~22]。最简单的机制是直接传输(direct transmission)[11],即源节点缓存数据直到遇到目的节点才转发信息。这种方式网络开销很小,但传输时延大、成功率低。2-HOP算法[11]中源节点将消息副本传输给最先遇到的L个中继节点,源节点和L个中继节点只将消息转发给目的节点,消息需要两跳到达目的节点,相对直接传输提高了传输效率。Vahdat等人提出的传染路由(epidemic routing)[12]本质上是一种泛洪算法,由于其在网络中大量复制转发数据,网络资源消耗较大,且随着网络节点数的增多,其性能由于广播导致的拥塞会急剧下降。Spyropoulos等人提出了基于效用与单副本的搜索聚焦路由协议[13],虽然可以降低资源消耗,但带来较大的时延。Spyropoulos等还对该协议进行改进,提出了Spray and Wait算法[14],在源节点指定消息允许的最大副本数为L,并使用基于二叉树的方法产生L份副本。该机制包括Spray和Wait两个阶段,相比只允许源节点分发消息副本的2-HOP算法,进一步降低传输时延。Sun等人[15]针对机会网络中多种类型数据具有不同传输质量的需求,提出了一种自适应的数据收集机制,有效控制了网络开销。朱金奇等人[16]设计了一种基于选择复制的传输策略,但节点实时定位需要消耗较多的能量,影响网络寿命且无法适用于移动汇聚节点的数据收集场景。Hass等人[17]讨论了采用 SWIM(system wideinformation management,正广域系统管理)系统收集鲸鱼的生物信息的场景,该机制实际上是传染转发式,如果节点的缓存足够大,这种机制的数据传输成功率就高,但网络开销较大。Princeton大学的ZebraNet项目[1]是追踪并研究斑马活动习性的网络系统,但由于传感器节点与基站相遇的机会很少,数据的传输可靠性较低。Wang等人[18]对该转发机制进行了改进,提高了节点和基站相遇的概率。Wang等人还建议采用 FAD (fault tolerance based adaptive data delivery)策略[19,20],但FAD策略忽略了消息的存活时间。Pasztor B等[21]提出的SCAR(sensor contex-aware routing)机制依靠节点上下文信息定义传输概率。Song等[22]提出的ProPHET协议则基于历史记录预测节点接触概率。
与本文研究最相关的是Fiore等[23]提出的Eureka算法,其移动节点估算其邻近范围内的信息密度并把查询结果向密度大的区域发送,但它需为每个节点建立信息密度索引,维护成本高,同时也面临信息更新时的高通信开销问题。本文提出的IA方法能在常见的移动环境下更好地适应具有频繁数据更新的高度动态网络,实验表明本文所提方法的性能优于其他算法。
3 基于邻居信息精确度的查询策略
对于延迟容忍网络中基于邻居信息精确度的查询策略,其主要思想是模仿社会网络中人的行为,从而提高查询的效率,即模仿人从经验中学习,节点(设备视为网络中的节点)在查询处理后调整信息精确度值;模仿人的闲谈方式来交换、更新邻居信息;模仿人从熟人那获取答案的自然行为来确定查询的转发策略。如图1所示,查询路由可分解为多个步骤,在每一步中,携带查询信息的节点根据其邻居节点提供的信息及信息精确度将查询信息转发给其可达范围内的某一个邻居节点。其中,L表示查询的路径长度,K表示处于第K跳的位置。本文使用TTL(time-to-live)控制查询信息的转发跳数,如果查询信息的转发跳数大于或等于TTL且没有发现所要查询的结果时,则认为此条信息查询失败;否则,资源提供者(R-provider)按照查询路径将资源发送给查询节点(Q-issuer)。

图1 查询路由示例
3.1 信息精确度
在介绍查询策略之前,先介绍邻居信息以及计算邻居信息精确度的方法。邻居信息是指对于某一查询,邻居节点所知道的关于此查询相关结果所在节点的信息,这些信息主要通过邻居节点之间的信息交换及查询转发的经验获取。如图2所示,每个节点都保持两张索引表,图2(a)的索引表称为自包含数据项(self-contained item,SCI),保存节点本身已有的信息,主要用来和邻居节点进行信息交换;图2(b)的索引表称为邻居节点数据项 (neighbors’item,NI),主要从邻居节点处收集而来,记录邻居节点的相关信息,用来决定查询转发的方向。

图2 索引表结构
IA是查询节点到最近资源提供节点距离的评判标准。设节点i保存的数据项j的信息精确度为Ii,j,由于是高度动态的网络环境,设置参数time表示数据信息的实效性。本文按如下步骤计算信息精确度值。
(1)对于节点本身提供的数据信息,将数据信息的精确度设置为I0,表示网络内最大的IA值;时间参数设置为T0,表示本节点可提供的信息,一直可利用直到数据被更新或删除。
(2)转发查询结果信息j后,中介节点NI表中关于数据信息j的IA值和时间参数都需要更新。IA值更新的策略遵循这一原则:节点越靠近数据项信息j的提供者,则此节点NI表中关于数据项信息j的IA值就越大。在实际执行过程中,为了提高网络环境中数据的查询成功率,将查询结果在查询发起节点缓存一段时间。在这期间,查询发起节点也可以作为资源的提供者。如果查询发起节点的存储空间已满,则将最老的缓存数据删除,缓存时间要根据具体的应用环境而定。之所以不将查询结果在中间节点暂存,是基于平衡数据分发与设备存储消耗的考虑。查询发起节点内的缓存数据对查询发起节点周围邻居节点中关于此数据的IA值也会有影响,调整IA值时必须考虑这一影响。因此,本文调整相关数据信息的IA值是根据它和相关资源提供者及缓存点的位置而定的。如图3所示,若节点离源节点或缓存节点近,则其IA值就高;反之,其IA值就低。
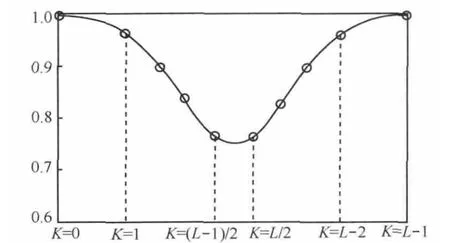
图3 IA值的调整
本文使用类似正态分布函数模拟IA值的调整。假设查询数据项 j,节点i是数据项j查询转发路径上的节点,节点i处于第K跳位置上且路径长度为L,如图1所示,本文使用式(1)计算节点i中关于数据项 j调整后的IA值。
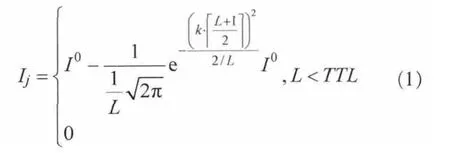
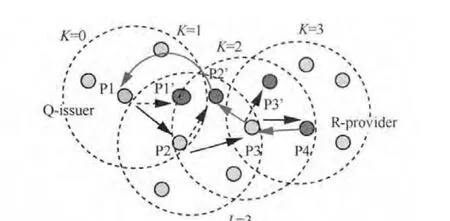
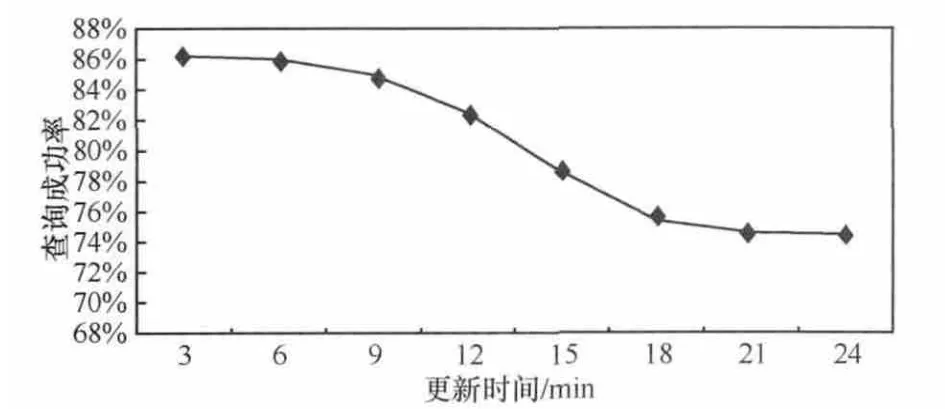
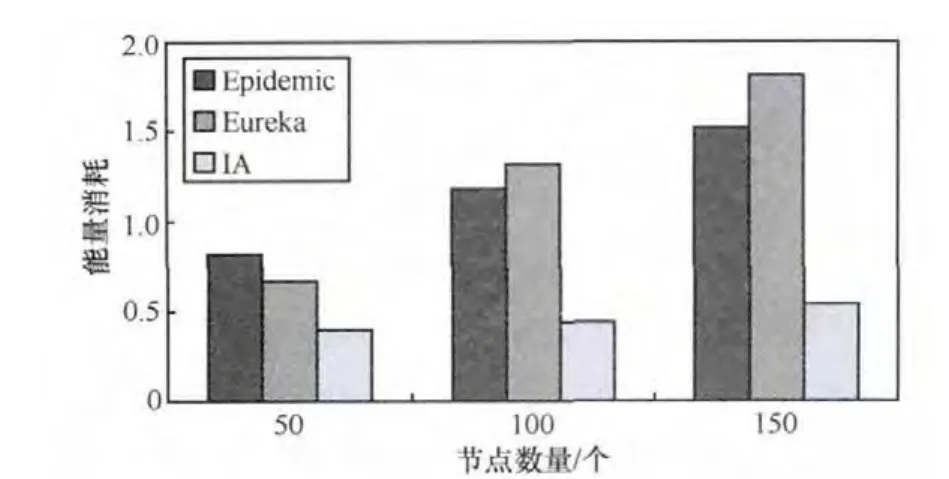
式(1)是调整后的正态分布函数,期望值 μ=[(L+1)/2],方差σ=1/L。如图1所示的查询转发过程中,K=0和K=3处节点的IA值都是I0;而K=1和K=2处节点的IA值I (3)节点i通过信息交换从其邻居节点处收集数据信息并更新本地保存的NI表: 其中,Mi,j是由更新时间及IA值计算出来的,表示节点i邻居节点内关于数据项j的最大转发权重。若IA值大,并且与上一次更新时间间隔短,则转发权重就大(因为有的IA值可能会比较大,但是在很久之前更新的,这个较大的IA值不一定精确)。文中部分符号含义见表1。 基于上述讨论,信息精确度值一定程度上表示节点到源节点的距离。对于某项要查询的数据项j,某个节点IA值越接近I0j,则说明此节点越靠近网络中提供数据项j的资源节点,节点i将查询转发给Ii,j值大的邻居节点。若考虑时间因素,则最近更新的IA值最精确。综合以上考虑,本文的信息查询算法设计如下。 表1 文中部分符号含义 (1)节点i接收到一个数据项j查询请求,查看本地是否有数据项j,若有则将数据项j发送给查询请求节点。 (2)如果节点i本身没有数据项j,则根据NI表把查询转发给其Ni个邻居节点中关于数据项j具有最大权重的邻居节点,此点经过式(2)、式(3)计算后保存在NI表中: 其中,Ni,k指节点i邻居节点中的第k个节点 ,I(Ni,k),j是节点 i的邻居节点 Ni,k关于数据项 j的 IA值,NIi是节点i的NI表,Node是最终选出的接收查询信息的邻居节点。 (3)如果节点i所有邻居节点关于数据项j的精确度值Ii,j都是 0,即邻居节点中没有关于数据项j的信息,节点 i把查询转发给其邻居节点中总体信息精确值最高的节点Vi,Vi由式(5)计算得出: 其中,SCIk指Numi个邻居节点中第k个邻居节点的SCI表,|SCIk|表示SCIk表中的数据项数。节点i将查询发送给总体信息精确度值最高的邻居节点,就像人们经常会向知识渊博的熟人询问问题一样。总体信息精确度最高的节点可使得查询通过它找到查询的结果,通过这样的节点查询成功率就会提高。Vi是由邻居节点和交换更新信息计算得来的。 在延迟容忍网络中,节点的移动是自由的。当查询信息查询到结果时,需要考虑如何将结果顺利返回到查询节点处,介绍如下。 当查询信息转发路径上的节点都在彼此的通信范围内时,可以直接将结果按照查询路径返回给查询节点,如图1所示。 当查询转发路径上的某一个节点移出下一跳邻居节点的通信范围时,如何将结果返回给查询节点呢?本文采取的方法是:某一个节点在向邻居节点传送查询信息时,在本节点通信范围和所选择的邻居节点通信范围的交集内选择一个节点备份数据信息。此备份的数据信息包含有关上一跳节点的相关位置信息,以此增加结果返回的成功率。如图4所示,节点P1向邻居节点P2转发查询信息时,会在P1和P2通信范围的交集内选择一点P1’备份P1的数据信息。同理,节点P2、P3也会选择数据备份点。当节点P3接收节点P4返回的结果后,P3会检查其上一跳节点P2是否还在其通信范围内,若在,则直接将结果传送给P2;若已移出P3的通信范围,则节点P3选择P2的备份节点P2’作为转发的中介节点向查询发起节点发送结果。 图4 查询路由示例 在延迟容忍网络中,移动节点可以自由地加入或离开网络,并且移动节点可以任意地添加、删除和修改数据,网络具有很高的动态性。在这种不稳定的网络环境下进行通信和维护数据更新的开销非常大。实验表明,本文提出的IA方法在处理这种不稳定网络的数据更新时效果较好。下面介绍如何利用IA方法处理网络动态及数据的更新。 (1)节点的加入或离开 如果一个新的节点加入网络,它只需将其本身自带的数据IA值发送给它可达范围内的邻居节点。邻居节点收到此信息后将其看作一个正常的NI表更新来处理;如果一个节点离开网络,它可以通知其邻居节点,也可以什么都不做直接离开。即使一个节点悄悄地离开,也可以通过查询转发及NI的更新将关于此点的相关信息很快删除。 (2)数据的插入或删除 对于节点的数据项,如果某条数据被删除,则把SCI表中此数据项的I和T都设置为0,并通知其邻居节点;如果添加一条新的数据项,则在SCI表中添加一个新的项,把此数据设为I0、T0并通知其邻居节点。接收到通知信息的邻居节点仅执行正常的NI表更新过程。 (3)数据的修改 如果一条数据被修改,在这种不稳定的网络环境下很难就地修改其他节点的相关数据信息。为此设置数据的版本信息,将修改后的数据作为新的数据添加到节点。查询节点可以通过数据的版本号区分数据的新旧。查询节点选取它所查询到的最新版本的数据作为最终结果。即使某条数据不是最新版本的数据,在没有找到最新版本数据之前仍旧是可以利用的,如果一个节点发现新的版本数据,将丢弃旧版本数据的相关索引和缓存副本,并用新的代替。 通过以上论述,除了NI的更新,对于网络动态性和数据更新问题不需要额外的开销,本文提出的方法可以很好地应用于高动态性的网络。 本文以发送的信息量来表示通信开销C,发送的信息包括查询请求信息、查询结果返回信息及更新信息。为了表述清晰,将一条信息的大小统一记为m,接下来分析查询转发及更新IA值的通信开销。 如前所述,如果查询节点成功查询到结果时的路由跳数为L,否则为TTL。在查询路径中,每个节点根据本地索引选择一个邻居节点,然后将查询请求转发给邻居节点,一次只发送一条信息。查询结果的返回信息也按照此方式进行。通信开销C为: 在通信开销中,主要是IA值的更新开销,因为很多过程本质上是IA值的更新,比如节点的加入或离开过程、数据的添加和删除及更新过程。对于节点i,假设它有Ni个邻居节点,在更新过程中,节点i只需向每个邻居节点发送一条信息mi,邻居节点接收到信息后,只需自动更新它们的NI表。节点i关于某条数据IA值更新的通信开销为: 在转发或更新IA值时要考虑移动设备电池的能量消耗问题。节点能量消耗与通信量成正比。假设节点i一次转发(或更新)的能量消耗是ei,移动设备可以配置成多个能量水平状态传输数据分组,不同能量水平的可达范围也是不同的,为了简化计算,假设网络中各节点的能量水平是相同的,记为p,则每个节点有相同的可达通信范围。节点i发送一个消息数据的能量开销为: 其中,σi是参数,反映节点电池电量及计算单元数据开销情况。 在查询转发过程中,分以下两种情况解释能量的消耗: ·如果节点i不在查询路径上,则节点i不参与查询信息的转发,其能量开销ei=0; ·如果节点i位于查询路径上,节点i在能量水平为p的情况下转发一个数据单元的查询请求或者返回查询结果,其能量开销均为p×σi。 另外,节点i接收一个数据单元的能量消耗为固定值ri。对于网络中的任意中间节点Eitm,它在查询转发和返回结果过程中都要接收和转发信息两次,能量开销为: 对于查询发起节点Eisr或资源提供节点Ersp,它们仅接收和转发信息一次,其能量开销为: 对于向其Ni个邻居节点更新某项数据IA值的节点,其能量开销Eupd为: 本文模拟实现了IA、Eureka[23]、Epidemic算法,主要从以下3个方面进行性能分析: ·对网络通信量、查询响应时间、查询成功率及能量消耗进行功能比较; ·研究不同的实验参数对3种算法产生的影响; ·分析比较IA与其他两种算法的优缺点。 本文将Epidemic算法作为基本方法进行参考比较,同时也和Eureka算法相比较。Eureka算法中每个移动节点都维持其范围内资源信息的密度大小,根据密度大小转发查询信息。 实验是基于ONE Simulator仿真[24]平台设计实现的。在模拟实验中,定义整个模拟区域为500 m×500 m的方形区域,区域内移动节点按照随机漫步(random waypoint)移动模型进行移动,节点移动速度在[0.5,1.5]km/h内随机选取,移动节点的通信半径为10 m,节点缓存为50 MB。消息大小统一为1 KB。具体模拟参数设置见表2。 表2 模拟参数 网络通信量是指在模拟实验中网络内传输的消息总量,包括查询信息、结果返回信息、信息更新等,通信量按照第4.1节所述方法计算。如图5所示,本文提出的IA方法明显优于另外两种方法。IA和Eureka算法都是采用索引保存有用的信息,但Eureka算法的通信量明显高于IA,这主要是由其低效的索引更新引起的。在Eureka算法中,当有数据更新发生时,节点就将更新后的索引值发送给其邻居节点,邻居节点接收到更新信息后同样将更新后的信息发送给它们的邻居节点,这样每一次更新都可能会涉及网络中的所有节点。而IA方法索引更新是在查询过程中,某一节点以一个固定的时间间隔向其邻居节点发送更新信息,不会像Eureka算法那样出现递归现象。 查询响应时间是指从查询信息发出到查询结果返回到查询节点所用的时间,是判断查询优劣的重要标准之一。在模拟实验中,本文只计算查询成功的查询响应时间。为每条查询信息设置一个时间阈值,如果一条查询信息在时间阈值内没有任何返回则认为此条查询失败。如图6所示,Epidemic算法的查询响应时间最短,这主要是它泛洪查询信息的结果。本文提出的IA方法的响应时间比Eureka算法快,这意味着IA方法的查询路径要比Eureka算法短,这主要是因为IA方法中各个节点相互配合并根据数据信息精确度选择出一条最优的查询路径。 图5 网络通信量性能比较 图6 查询响应时间性能比较 查询成功率是指查询信息的成功数占查询信息的比重,计算式如下: 图7显示了不同方法的查询成功率,即同样的信息量不同网络规模(节点数量多少)情况下的成功率,与网络规模相关。很明显,Epidemic算法的成功率最高,这是其泛洪查询信息的结果。比较IA和Eureka算法可发现,IA方法的成功率低于Eureka算法,当节点增多、网络规模变大时,IA方法优于Eureka算法。尽管IA方法只选择一条路径转发查询信息,但其可以有效地获取数据资源相关信息并按照信息精确度选择最可靠的邻居节点转发查询信息。在高度动态的网络环境下,节点不断地移动、数据不断地更新,高查询成功率表明本文提出的IA方法的稳定性高于Eureka算法。 对于本文中提出的IA算法,不同更新频率对查询成功率的影响也要考虑。本文为验证更新频率对查询成功率的影响,在网络节点数为150个、独立数据量为150 MB的环境下进行实验。在更新间隔时间分别为[3,6,9,12,15,18,21]时,对查询成功率进行统计,统计结果如图8所示。可以看出,更新时间越长,查询成功率越低。当更新间隔时间为[18,21,24]时,成功率出现平缓趋势,即更新间隔时间大到一定时间时,成功率趋于稳定。 图7 查询成功率性能比较 图8 更新时间对查询成功率的影响 只要移动节点参与查询过程,就会产生能量消耗。按照第4.2节的方法计算节点的能量消耗。如图9所示的平均电池能量消耗对比,IA方法的能量消耗比另外两种方法要低。能量消耗和网络通信量有密切的关系,信息传输量越大,能量消耗就越大。Eureka算法比Epidemic算法能量消耗大,主要是由其索引更新及查询策略引起的。对于每一个查询,Eureka算法都会将此查询泛洪给所有的邻居节点,只有少数几个邻居节点会根据自身索引转发此查询,大多数邻居节点不进行任何操作,能量就浪费在这些过程中;另外,Eureka算法的索引更新涉及网络中的大部分节点,这也需要消耗大量的能量。 图9 能量消耗对比 本文主要解决了延迟容忍网络中基于邻居信息精确度的查询问题。提出的IA方案充分利用了移动设备的特性分享有用的资源信息。基于邻居信息精确度的IA算法通过模仿社会网络中人的行为来帮助移动设备转发查询信息,采用信息精确度机制使得算法在查询资源时是轻量高效的。实验结果表明,本文提出的方法能更好地适应高度动态型的延迟容忍网络,与其他算法相比,本文提出的IA算法查询成功率更高,传输能耗低且性能好。 1 Juang P,Oki H,Wang Y.Energy-efficient computing for wildlife tracking:design trade offs and early experiences with ZebraNet.ACM Operating System Review,2002,37(10):96~107 2 Pent land A,Fletcher R,Hasson A.DakNet:rethinking connectivity in developing nations.Computer,2004,37(1):78~83 3 Hull B,Bychkovsky V,Zhang Y.CarTel:a distributed mobile sensor computing system. Proceedings of the 4th Int’l Conference on Embedded Networked Sensor Systems,Boulder,2006:125~138 4 Fall K.A delay-tolerant network architecture for challenged internets.Proceedings of the ACM Conference on Computer Communications (SIGCOMM 2003),New York,USA,2003:27~34 5 The blue tooth specification. http://www.bluetooth.com/dev/specifications.asp 6 The IEEE 802.11 standards.http://grouper.ieee.org/groups/802/11,2013 7 Conti M,Gregori E,Turi G.A cross-layer optimization of gnutella for mobile Ad Hoc networks.Proceedings of MobiHoc 2005,Urbana-Champaign,IL,USA,2005:343~354 8 Diao Y,Rizvi S,Franklin M.Towards an internet-scale xml dissemination service.Proceedings of VLDB 2004,Toronto,Canada,2004:612~623 9 Daly E M,Haahr M.Social network analysis for routing in disconnected delay-tolerant MANETs.Proceedings of the 8th ACM Int’l Symp on Mobile Ad Hoc Networking and Computing(MOBIHOC 2007),Montreal,2007:32~40 10 Pelusi L,Passarella A,Conti M.Opportunistic networking:data forwarding in disconnected mobile Ad Hoc networks.Communications Magazine,2006,44(11):134~141 11 Grossglauser M.Mobility increases the capacity of Ad Hoc wireless networks.IEEE/ACM Transactions on Networking,2002,10(4):477~486 12 Vahdat A,Becher D.Epidemic Routing for Partially Connected Ad Hoc Networks.Technical Report,Durham,Duke University,2000 13 Spyropoulos T,Psounis K,Raghavendra C S.Efficient routing in intermittently connected mobile networks:the single-copy case.IEEE/ACM Transactions on Network,2008,16(1):63~76 14 Spyropoulos T,Psounis K,Raghavendra C S.Efficient routing in intermittently connected mobile networks:the multiple-copy case.IEEE/ACM Transactions on Network,2008,16(1):77~90 15 Sun L M,Xiong Y P,Ma J.Adaptive data gathering mechanism in opportunistic mobile sensor networks. Journal on Communications,2008,29(11):187~193 16 Zhu J Q,Liu M,Gong H G.Selective replication-based data delivery for delay tolerant mobile sensor networks.Journal of Software,2009,20(8):2227~2240 17 Small T,Haas Z J.The shared wireless infostation model-a new Ad Hoc networking paradigm (or where there is a whale,there is a way).Proceedings of the 4th ACM Int’l Symp on Mobile Ad HocNet working and Computing (MOBIHOC 2003),Annapolis,2003:233~244 18 Wang Y,Wu H Y.DFT-MSN:the delay fault tolerant mobile sensor network for pervasive information gathering.Proceedings of the IEEE 25th Int’l Conference on Computer Communications(INFOCOM 2006),Barcelona,2006:1~12 19 Wang Y,Wu H Y,Dang H.Analytic study of delay/faulttolerant mobile sensor networks (DFT-MSN’s).Proceedings of the 10th IEEE Int’l Symp on World of Wireless,Mobile and Multimedia Networks(WoWMom 2009),San Francisco,USA,2009:1~9 20 Wu H Y,Wang Y,Dang H,et al.Analytic,simulation and empirical evaluation of delay/fault-tolerant mobile sensor networks.IEEE Transactions on Wireless Communications,2007,6(9):3287~3296 21 Pasztor B,Musolesi M,Mascolo C.Opportunistic mobile sensor data collection with SCAR.Proceedings of the 4th IEEE Int’l Conference on Mobile Ad Hoc and Sensor Systems(MASS 2007),Pisa,Italy,2007:1~12 22 Song L B,Kotz D F.Evaluating opportunistic routing protocols with large realistic contact traces.Proceedings of the 2nd ACM Workshop on Challenged Networks (CHANTS 2007),Montreal,2007:35~42 23 Fiore M,Casett C,Chiasserini C F.Efficient retrieval of user contentsin MANETs.Proceedings of 26th Annual IEEE Conference on Computer Communications,IEEE INFOCOM 2007,Anchorage,Alaska,USA,2007:10~18 24 Opportunistic network environment simulator.http://www.netlab.tkk.fi/tutkimus/dtn/theone/
3.2 查询转发算法


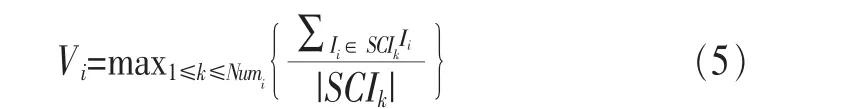
3.3 查询结果返回情况的处理
3.4 网络动态及数据更新
4 通信开销及能量消耗
4.1 通信开销
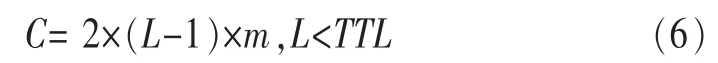

4.2 能量消耗




5 实验与分析
5.1 模拟环境

5.2 网络通信量比较
5.3 查询响应时间性能比较


5.4 查询成功率性能比较


5.5 能量消耗性能的比较
6 结束语
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21
体育科技文献通报(2022年3期)2022-05-23
云南教育·中学教师(2020年11期)2021-01-07
作文中学版(2020年1期)2020-11-25
甘肃科技(2020年19期)2020-03-11
山东煤炭科技(2020年1期)2020-03-06
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
植物营养与肥料学报(2014年1期)2014-03-11
计算机工程与设计(2011年7期)2011-09-07
