
基于Hadoop云计算平台的图像分类与标注*
2014-02-28 06:16陆寄远黄承慧
电信科学 2014年2期
陆寄远,黄承慧,侯 昉,李 斌
(1.广东金融学院计算机科学与技术系 广州510521;2.甲骨文研究开发中心(深圳)有限公司 深圳518057)
1 引言
随着网络的普及以及多媒体数据获取设备的发展,图像和视频的数量都飞速增长,多媒体资料的存储和检索成为热门的研究领域。基于内容的图像检索、对象识别、标注等都是现在的研究重点。各种分类算法、模型和系统不断涌现,如基于SVM(support vector machine,支持向量机)、pLSA(probabilistic latent semantic analysis,概率潜在语义分析)或决策树的图像分类方法[1]。其中,基于内容的图像检索是形成基于内容的标注和图像之间的映射。有了这些标注,就可以将用户的查询分解到标注的概念,以检索出结果。
图像分类和标注的问题可以理解为模式识别的问题,计算机无法像人类一样具有抽象概括的能力,只能利用图像的底层特征进行识别分类。现有的图像分类系统大部分是按照如图1所示的工作流程:从图像中提取视觉描述子向量;利用已经学习到的码本(codebook)对这些描述子向量进行编码,使得相似的描述子向量得到相近的标签;根据每个标签的出现频率统计出图像内容的全局直方图,得到图像的视觉特征表示;将直方图导入分类模型中,估计该图像的类别标签。

图1 图像分类系统的一般工作流程
目前已经有两类图像检索系统:基于文本的图像检索(text based image retrieval,TBIR)系统和基于内容的图像检索(content based image retrieval,CBIR)系统。在基于文本的系统中,图像要进行人工标注,然后通过这些标注信息进行检索。然而,在CBIR中是由图像的视觉特征(如颜色、纹理、形状等)建立索引。很多人在该领域中取得了出色的研究成果,现在已经可以使用的CBIR系统有QBIC、Informedia-Ⅱ、ALIPR、GazoPa等[2,3]。随着研究的深入,人们发现CBIR系统存在两个明显的不足:低层可视特征和高层语义概念之间存在巨大鸿沟;与人类视知觉机制具有明显的不一致性。为了缩小图像底层特征和用户检索语义概念之间的“语义鸿沟”,部分研究者开始进行语义图像检索的研究。微软亚洲研究院开发了一个Web图像检索系统[4],目的是将传统Web图像检索返回的结果重新进行聚类。搜索的结果被聚类成不同的语义类别,对每个类别,都会选出几张代表性的图片,使用户能够马上了解到这一类的主题。每一类里面的图片则根据它们的视觉特征进行组织,使其显示结果更符合用户的需求。其中,训练集的大小和质量是影响分类效果的重要因素,现在基本使用人工收集训练集,这是件复杂的工作,当需要分类的对象越多,要收集的训练集越大,消耗的人力也越多时。本文的重点是要解决该问题,高效地获取训练分类模型所需的训练集图像。本文所提出的解决方案为:一是依靠云计算技术解决训练集大小的问题,二是通过pLSA主题聚类的方式实现人机交互的训练集选取,从而提高效率。
2 基于Hadoop的图像分类与标注系统
云计算是一种新的IT资源提供模式,依靠强大的分布式计算能力,使成千上万的终端用户能够依靠网络连接的硬件平台的计算能力实施多种应用。Hadoop[5]是一个分布式系统基础架构,由Apache基金会开发。使用者可以在不了解分布式底层细节的情况下,搭建分布式计算平台。Hadoop的核心组件有两个:Hadoop分布式文件系统(HDFS)和MapReduce,如图2所示。HDFS是一个隐藏下层负载均衡、冗余复制等细节的分布式文件系统,适合部署在廉价的机器上。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用,并对上层程序提供一个统一的文件系统API(应用程序接口)。从图2(a)可以知道,HDFS只有一个名字节点,负责管理元数据操作和控制数据块的放置,由数据节点实际保存数据块。另外,MapReduce代表了map和reduce两种操作,如图2(b)。大多数分布式运算可以抽象为MapReduce操作。map是把输入分解成中间的key/value对,reduce把key/value合成最终输出。这两个函数由程序员提供给系统,下层设施把map和reduce操作分布在集群上运行,并把结果存储在分布式文件系统上。从图2(b)可以知道,用户提交MapReduce任务给主节点,JobTracker负责将任务分配到各个子节点上,实现并行处理。
考虑到Hadoop的开源以及容易进行开发的特点,同时为了保证平台的稳定性,本系统以Hadoop+Ubuntu的方式进行构建。Ubuntu是一个完全以Linux为基础的操作系统,可自由地获得,并提供社区和专业的支持。本系统的框架设计如图3(a)所示。首先,利用云技术发挥互联网中多台硬件的计算能力,加快图像抓取的速度,并获取所需要的原始图像集。其次,当抓取到足够的原始数据集以后,使用训练集提取模块通过交互的方式帮助用户选取恰当的训练集。第三,通过分类器学习模块训练分类器。最后,分类标注模块利用这些分类器对新图像进行分类标注。系统的硬件拓扑,如图3(b)所示。从图中可以看出,图像抓取平台中有一个主节点,抓取任务通过安全外壳(SSH)协议提交到主节点,由该节点负责将任务分配到所有的子节点。


图3 基于Hadoop+Ubuntu的系统架构
从图3(a)可以知道,分类标注系统要满足4个功能需求:原始图像抓取、训练集提取、分类器模型学习和分类标注。用户通过训练集提取可以从原始数据集中生成训练集,然后学习分类器模型,利用分类器模型进行图像的分类和标注,并对分类标注结果进行存储,以供用户查询或者检索系统。本节将介绍分类标注系统功能模块设计。结合系统的架构,把系统分为图像抓取模块、训练集提取模块、分类器学习模块、分类标注模块,如图4所示。
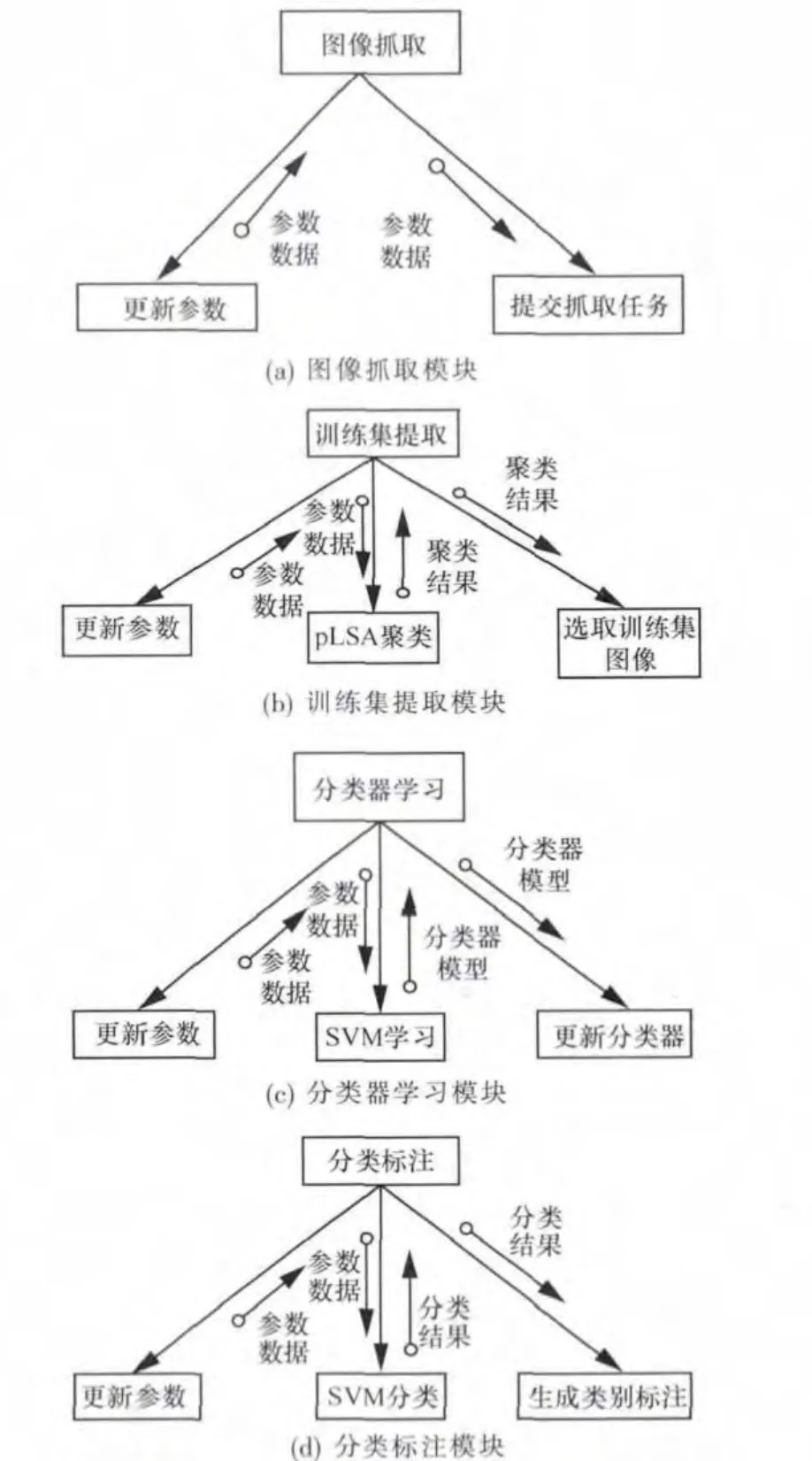
图4 分类标注系统的模块结构
其中,图像抓取模块负责将用户的抓取任务提交到图像抓取平台,通过SSH协议连接到云计算平台的主节点,从互联网中抓取所需的原始图像集;训练集提取模块负责对原始图像集进行基于pLSA模型的主题聚类分析,通过用户交互的形式选取出训练集图片;分类器学习模块的任务是根据用户提供的训练集图像学习分类器模型,并保存为分类器模型文件;分类标注模块完成对图像或者图像序列进行分类标注的任务,并生成分类标注文件。
训练集提取模块分为3个子模块:更新参数模块、pLSA聚类模块和选取训练集模块。用户通过更新参数模块设置训练集提取任务的参数,pLSA聚类模块根据用户的参数设置进行原始图像的主题聚类分析,完成后用户可以通过训练集选取模块选取所需的训练集图片。
分类器学习模块进一步分为更新参数、SVM学习和更新分类器模型3个子模块。用户通过更新参数模块设置分类器学习任务的参数,SVM学习模块根据用户的参数设置从训练集中学习分类器模型,运行成功后更新分类器模块负责存储更新分类器模型。
分类标注模块分为更新参数、SVM分类和生成类别标注3个子模块。用户通过更新参数设置模块设置任务的参数,SVM分类模块根据用户的参数设置对图像(或图像序列)进行分类标注,并通过生成类别标注模块生成类别标注文件。
3 实验结果
系统使用操作系统平台为Ubuntu Desktop 9.10,分布式系统平台为Hadoop 0.19.2。图像抓取模块主要用Java开发,开发工具为Eclipse,运行环境为sun-6-jdk、sun-6jre。选取2组测试集,第一组是 “Caltech-256 object category dataset”[6],第二组是利用网络抓取平台抓取的原始数据集,如图5所示。通过实验发现,对原始图像集进行10个主题的聚类,取得了较好的效果。下面将展示摩托车、蝴蝶测试的结果。
利用训练集提取模块对原始图像集进行10个主题的聚类,结果见表1。从表1中可以看出,大部分聚类还是比较理想,可以直接去掉如聚类1、聚类3、聚类4、聚类7、聚类8、聚类10,从而实现了“按类选取”,加快了训练集的筛选速度。

图5 原始图像集

表1 摩托车和蝴蝶的10个主题聚类测试结果
4 结束语
随着网络的普及和多媒体数据获取设备的发展,图像和视频的数据量都在飞速增长,多媒体资料的存储索引成为热门的研究领域。本文针对当前图像分类技术中都要面对的提取训练集问题,提出了一个基于Hadoop云平台的解决方案。该方案基于现有文本图像搜索引擎的图像抓取器,实现基于云计算的图像抓取平台,并在此基础上利用pLSA模型,采用MSER和STAR区域特征,实现了主题聚类的训练集提取,同时通过对原始图像集进行基于主题的聚类,使得用户可以“按类”筛选训练集,比“逐张”筛选要有效率得多。
1 Moosmann F,Nowak E,Jurie F.Randomized clustering forests for image classification.IEEE Transactions on Pattern Analysis and Machine Intelligence,2008,30(9):1632~1646
2 ALIPR.Automatic photo tagging and visual image search.http://www.alipr.com/,2012
3 GazoPa.Similar image search.http://www.gazopa.com/,2010
4 Cai D,He X F,Ma W Y,et al.Organizing www images based on the analysis of page layout and web link structure.Proceedings of 2004 IEEE International Conference on Multimedia and Expo,ICME’04,Sorrento,Italy,2004
5 Grangier D,Bengio S.A discriminative kernel-based approach to rank images from text queries.IEEE Transactions on Pattern Analysis and Machine Intelligence,2008,30(8):1371~1384
6 Griffin G,Holub A,Perona P.Caltech-256 Object Category Dataset.Technical Report,California Institute of Technology,2007
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
计算机应用(2017年4期)2017-06-27
雷达学报(2017年6期)2017-03-26
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
专利代理(2016年1期)2016-05-17
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
中原工学院学报(2014年4期)2014-04-01
质量与标准化(2010年5期)2010-05-03
