
混合流媒体系统的资源搜索机制研究*
2014-02-28 06:16郭大钢卓明琴张继荣
电信科学 2014年2期
郭大钢,卓明琴,张继荣
(1.西安邮电学院邮电技术公司 西安710061;2.中兴通讯股份有限公司南京研发中心 南京210012;3.西安邮电大学通信与信息工程学院 西安710121)
1 引言
传统的基于P2P(peer to peer,对等)网络的流媒体系统中,资源的搜索方法是单一的基于结构化搜索或非结构化搜索,并未将这两种模式进行优势互补。事实上,针对不同的资源分布,两种搜索模式体现出不同的特性:结构化搜索模式能准确命中资源,且具有相对确定的路由跳数和响应时间[1],其缺点在于为了保持网络逻辑拓扑而引入的动态维护开销过大且过程较复杂,增大了网络节点的处理负荷;非结构化搜索模式消除了对逻辑拓扑的依赖所带来的维护开销,并且对知名资源具有很好的搜索效率与质量[2],但其对稀有资源的查找效率不高,且一般响应时间较长。本文研究的混合流媒体系统[3]综合考虑了这两种搜索模式的优势,并进行了改进。根据搜索资源的知名度采取不同的搜索方法,即当搜索稀有资源时采用结构化搜索机制,当搜索热门资源时则采用非结构化搜索机制,从而大大提高了搜索效率。为了更好地提高搜索命中率,还根据不同的资源知名度,采取不同的策略支持模糊查找。主流模糊查找大体分为2类,即多关键码搜索(multi-keyword query,MKQ)和语义搜索。
在处理稀有资源时,使用结构化搜索过程,结构化P2P网络中散列函数的随机性和均匀分布性导致它不能很好地支持语义搜索,而稀有资源在网络中的数量较少,采用MKQ所引入的分割发布对发布节点的存储空间和网络带宽占用量很小,且实现方法简单,因此在结构化搜索部分,使用MKQ支持模糊查找。
在处理知名资源时,使用非结构化搜索过程,由于资源词条较为热门,在网络中的存储量很大,采用MKQ将会大量占用发布节点的存储空间和网络带宽,因此MKQ在此处不适用,而非结构化P2P网络能够很好地支持语义搜索,研究发现,利用语义相关度可以较精确地在众多相似资源词条中找到与要求最接近的资源词条,因此在非结构化部分,采用语义相关度来支持模糊查找。
2 混合流媒体系统结构及原理
2.1 混合流媒体系统结构
在混合流媒体系统中,将媒体分发网络分为2层,分别为骨干网层和边缘网层。在骨干网层次,采用CDN技术,通过在网络边缘合理布置代理缓存服务器(边缘服务器),将视频内容推送到靠近用户端侧;在边缘网层次,以不同的代理缓存服务器为中心,组成多个自治的、相互独立的P2P流媒体网络,利用P2P技术进行流媒体的共享,具体系统结构如图1所示。
系统的整体设计结合了互联网的结构特点,流媒体中心服务器(central server,CS)、请求路由服务器(request routing server,RRS)和分布在各自治系统的边缘服务器(edge server,ES)通过骨干网互连组成流媒体CDN,各互联网自治系统内的边缘服务器与客户机组成与其他自治系统相互独立的混合流媒体网络。边缘服务器是混合流媒体网络中的超级节点(super peer,SP),客户机是叶子节点(leaf peer,LP)。
2.2 系统工作原理
在上层应用中,中心流媒体服务器负责在初始状态发布流媒体资源。RRS负责对新加入的LP进行身份鉴权,若鉴权成功,则根据LP的IP地址或端口号通过SHA-1算法为其分配一个全局唯一的ID,并向LP指定一个对它最合适的SP。RRS还负责在资源知名度更新过程中对CSP(chief super peer)进行选择。
LP按照一定的词条抽取规则对本节点共享的资源进行词条抽取后,重定向到SP,并向SP传送其共享资源的词条,供SP进行本地资源的统计和更新。
SP根据全局资源变化率η计算出资源在网络中的实时数量,并与系统预设的泛洪阈值r进行比较,将资源分别归入稀有资源集和热门资源集中。为了支持模糊查找,SP还需向LP发送实时的η值,LP根据η值判断其存储资源的流行度,并对其中的稀有资源进行分割和发布,以支持MKQ;对于热门资源,直接以二元组(词条、节点IP地址)的形式存储于本节点中。
在需要搜索某个流媒体资源时,LP会向SP发出搜索请求,SP根据LP输入的关键码Key判断其在网络中的流行度,即SP在稀有资源集和热门资源集中查找含有Key的资源词条,按照式(1)和式(2)计算两个集中相关词条与Key的平均语义相关度SRaver。
其中,n为相关词条个数,pi、qj为Key和S相应关键码的隶属度,p≥1,pi≥0,qj≤1,SR(Keyi,Sj)根据知网义原预先设定[4]。
通过计算,SP优先选择SRaver较大的集合作为候选集,若热门资源集中相关词条与Key的平均语义相关度大些,则SP选定热门资源集为候选集,并告知LP采用改进的泛洪机制和语义相关度匹配进行模糊搜索,在搜索结束后,将结果按照一定的规则显示给LP,若LP不满意,则重新以DHT(distributed hash table)机制和MKQ结合进行模糊搜索。若在全局搜索完成后仍然没有满意结果,SP会向上层CS请求该资源。
2.3 主要节点的数据结构定义
2.3.1 SP中的主要数据结构和数据成员
SP中的主要数据结构和成员如下:邻居SP表、本地资源表、本地节点的拓扑表、泛洪阈值、本地网络规模、全局拓扑维护周期。
2.3.2 LP中的主要数据结构
在LP中,对传统的Chord网络节点路由表(finger table)进行改进,增加了逆向路由。双向路由表(逆时针路由表,前继节点,后继节点,顺时针路由表)见表1和表2,其中,i=log3N,N为网络规模。其他主要数据结构介绍如下。

表1 顺时针路由

表2 逆时针路由
·本节点资源表(资源词条列表),邻居表。由本地LP代为发布、存储LP代为发布的资源及其源节点信息,此时LP被称为发布节点Distr_ID。
·缓存表(cache table):存储之前网内成功搜索的资源信息。由于在Distr_ID退出时,它代为发布的资源就会被转存到它的后继节点,因此在缓存表中将存储它的若干个后继节点,可以确保在其退出时,转而访问它的后继节点,进而找到资源的源节点S_ID。
3 改进的Chord搜索机制
混合流媒体系统中的结构化搜索(DHT机制)部分采用改进的Chord搜索机制,节点路由表与以往的Chord网络节点路由表不同:路由表节点间隔以3为基数;增加了逆向路由表,查找以双向的方式进行;增加了缓存表,若之前查找过相同的资源,便可以快速地再次定位;以MKQ的查找方法来支持DHT部分的模糊查找。
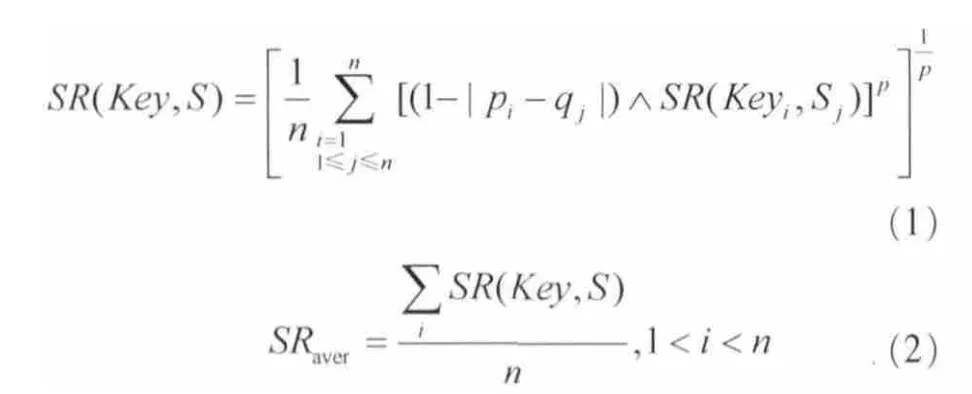
3.1 节点加入(弱稳定算法)
假设LPi的节点ID为IDi,所属的SP记为SPi,泛洪阈值为r,网络规模为N。
当有节点LPi要加入网络时,通过RRS鉴权后重定向到SPi,向SPi发送本节点资源词条信息。SPi开始进行拓扑的弱稳定维护,即SPi向LPi发送它的后继节点Si信息和实时的全局资源变化率η,则LPi及其相关节点进行如下操作:
LPi.successor=Si;
LPi.predecessor=Si.predecessor;
LPi.Predecessor=LPi
同时,LPi复制Si的路由表信息。经过上述弱稳定维护后,LPi成功加入逻辑拓扑环中,并保持了Chord环的完整性,而其他相关的节点暂时不更新自己的路由表。
之后,LPi根据η进行资源发布:若资源为稀有资源,则将资源词条以较小单位(如以单个汉字或字符为单位)通过SHA-1算法得到资源标识SID,SID和节点标识ID属于同一个命名空间。LPi根据SID的值将资源发布到与SID最接近的ID节点上。例如,节点LPs中存有“创世纪”这一稀有电影资源,则LPs将“创世纪”的资源属性按照抽取规则进行抽取后得到资源词条(如片名、主演、电影情节和关键字等),将词条内容进行分割,如“创世纪”被分割成“创”、“世”、“纪”,并分别通过散列函数发布到相应的节点IDn、IDk和IDm上,每个发布节点包含其所负责的关键码和对应的资源词条以及相应的节点信息。
此外,LPi还将通过探测邻居节点与其距离来初始化自己的邻居表。初始状态下,节点的缓存表为空或保留上次在网内的成功查找记录。
3.2 查询路由
当LPi需要搜索某个流媒体资源时,例如搜索电影“创世纪”时,用户只需输入影片的若干个词条关键码便可进行模糊查找,具体查找过程如下。
(1)LPi首先查询本地缓存表,若之前LPi成功查询过该资源,缓存表中会有相应的记录,LPi可以直接定位到资源发布节点Distr_ID,从而找到资源的源节点S_ID。
(2)若缓存表中无相关记录,LPi向所属SPi发送查询请求,SPi通过分析得出候选集,若稀有资源集合中相关词条与输入请求码字的平均语义相关度较大,则SPi指示LPi采用DHT搜索机制,即采用改进的Chord机制和MKQ结合进行模糊查找。
要论某一部蒙古史诗所产生的时代,就有必要先将它放到世界史诗的框架中加以比较分析,进行综合考量,然后再对其做出推断。这样做的理由是,蒙古史诗既然是世界史诗重要的组成部分,那么它就不应该游离于世界史诗之外而孤立存在。
(3)若LPi被指示采用DHT机制搜索,它将输入的关键字分割成单位关键码并经过SHA-1算法得到资源标识,如LPi输入 “世纪”时,将其分割为 “世”、“纪”,并调用SHA-1算法分别得到资源标识SID0和SID1,LPi将按照SID0或SID1进行搜索。
假设LPi以SID0开始搜索,首先判断SID0与IDi+N/2的大小关系,若SID0小于IDi+N/2,则在顺时针路由表中进行查找,否则,在逆时针路由表中进行查找;查找时首先查看LPi.successor(后继节点)的ID,若SID0介于LPi与LPi.successor之间,则资源存储在LPi.successor上,否则,在路由表中找到小于SID0但最接近它的节点IDj,将查询请求转发给IDj,IDj节点重复IDi节点的过程,经过有限轮的转发和查找,最终找到和SID0最接近的节点IDk,负责SID0的节点IDk将返回所有包含“世”字的资源列表,LPi在返回的结果中再根据关键码“纪”搜索词条中包含“纪”字的所有词条,剔除不含“纪”字的资源词条,如果还有其他的关键码则继续搜索。此过程可能找到精确的目标文件,也可能只是一些符合条件的资源词条的集合,用户自己再进行选择。知道的关键码越多,找到的词条范围越小,用户越容易做选择。
(4)通过选择后,LPi将最终的结果集合{LPs,s≥1}按照匹配度进行排序,并检查LPn∈{LPs,s≥1}是否存在于自己的邻居表中。若存在,则认为LPn距离LPi最近,否则,LPi将计算与各个LPs的距离。LPi将优先选择与自身距离最近且资源匹配度较高的节点进行连接。
(5)若LPi不满意返回的结果,则LPi可激活以改进的泛洪机制和语义相关度进行模糊查找。当搜索完成后,若仍没有满意结果,LPi将上报SP,由SP向上层CS请求资源。
(6)LPi搜索成功后,在缓存表中存储此次资源搜索相关信息以备下次使用。缓存表采取LRU(最近最少使用)策略进行维护更新。
3.3 节点退出
节点的退出分为主动退出和被动退出。主动退出时,节点LPi会向所属的SPi报告自己的退出消息,SPi会在本地资源数据库中删除LPi所对应的节点及资源信息。此外,LPi向自己的邻居节点通知即将离开,邻居节点据此删除邻居表中LPi的相关项,同时,LPi还将向自己的前继节点和后继节点通知自己即将退出,在LPi的协助下,进行如下操作:
LPi.successor.predecessor=LPi.predecessor;
LPi.predecessor.successor=LPi.successor
其他相关节点暂时不更新路由表。
被动退出时,每个节点都会定时向其邻居节点发送心跳检测信息,若在规定的时间内未收到邻居节点LPi的响应,则节点就认为LPi已退出网络,检测节点便向SPi发送LPi的退出消息,并删除邻居表中LPi的相关项。SPi据此在本地资源数据库中删除LPi的节点资源信息,并协助LPi的前继节点和后继节点完成连接,而其他的节点则暂时不更新路由表。
3.4 拓扑维护(强稳定算法)
由于网络节点可以动态加入或退出,为了保持网络的逻辑拓扑结构,SPi会周期性地进行本地的全局逻辑拓扑维护操作,即强稳定算法,假定其周期为T。
当到达全局拓扑维护周期T时,SPi会根据本地资源数据库中的节点ID进行排序,生成新的全局拓扑信息,并向每个节点发送它所需要的双向节点信息,节点会根据此信息更新自己的路由表。此外,每个节点将更新自己的邻居表,检测表中的所有邻居是否全部在线,若通过检测,在表中删除已退出网络的邻居节点的表项,并为新邻居添加相应的表项。
4 改进的泛洪搜索机制
采用改进的泛洪搜索机制进行泛洪查找,以布鲁曼滤波器[5,6]这种随机数据结构进行搜索消息的转发,且与迭代泛洪[7]相结合,并在搜索过程中通过计算语义相关度支持资源的模糊查找。将这种基于布鲁曼滤波器进行的泛洪搜索机制记为BF_Flooding。
假设布鲁曼滤波器共有m位,网络规模为N,为实现布鲁曼滤波器结构采用k个散列函数,允许布鲁曼滤波器产生假阳性错误的最大值为ε,最小值为f。为了实现f,则k=ln 2×(m/N);而在散列函数的个数取到最优时,要让错误率不超过ε,则m≥N×lb e×lb(1/ε);布鲁曼滤波器分别通过添加和查询操作判断添加成员和成员是否存在于布鲁曼滤波器中。
4.1 节点加入
节点LPi加入网络的流程大体同第3.1节所述。此外,LPi会初始化自己的布鲁曼滤波器,假设在初始时刻LPi未发出资源搜索请求且未收到来自其他节点的搜索请求,即LPi暂时不会转发查询消息,此时,将布鲁曼滤波器初始化为全零,否则,将要转发的目的邻居节点加入布鲁曼滤波器中。布鲁曼滤波器的结构如图2所示。其中,style默认为泛洪消息报文;ID表示报文发送者的全网ID;message是具体的消息内容。

图2 布鲁曼滤波器报文结构
4.2 查询路由
查询路由的具体流程如下。
(1)当LPi需要查询某个流媒体资源时,节点首先查询本地缓存表,看是否存有该关键字的查询记录,若有,则可直接定位到资源的源节点。
(2)若缓存表中无相关记录,LPi向SPi发出请求,SPi通过分析计算得出候选集,若热门资源集合中相关词条与输入的请求码字的平均语义相关度较大,则SPi指示LPi采用改进的泛洪搜索机制,即通过BF_Flooding和语义相关度计算相结合进行模糊查找。
(3)若LPi被指示采用改进的泛洪查找机制,LPi将所要搜索的资源关键字信息、迭代深度和语义相关度门限φ附入布鲁曼滤波器的message项中,将迭代策略设置为P={a,b,c}(a为第一轮迭代深度;b为第二轮迭代深度;c为最大迭代深度)。LPi按照一定的概率f(本文中取最坏情况f=1进行试验)选择若干个邻居节点作为查询消息的目的转发节点,并对这些节点进行添加操作,将其加入布鲁曼滤波器中,然后向这些目标转发节点以布鲁曼滤波器的结构发起TTL=a的查询请求。
(4)收到查询请求的节点LPj将布鲁曼滤波器的message项中的资源关键字信息与本节点的资源列表进行比较,找出相关项,并按照式(1)计算其与请求关键字的语义相关度λ,若λ≥φ,则将结果返回给LPi。LPj按照概率f选择若干个邻居节点作为本轮的目的转发节点,继而对这些目的转发节点进行查询操作,判断所选定的目的转发节点是否存在于所接收到的布鲁曼滤波器中(将此时收到的布鲁曼滤波器记为receiver i,i为当前的迭代深度),若不存在,则向这些目的转发节点发送查询消息,否则,不再向其发送查询消息。之后收到查询消息的节点都将重复LPj的操作,直到TTL=a时暂停搜索。此时,处在深度为a的节点成为下一轮泛洪的前继节点,前继节点保存receiver a消息,并等待一定的时间t接收LPi是否继续搜索的指示。
(5)在完成深度为a的泛洪搜索后,将结果按语义相关度降序排列后返回给LPi,LPi对返回结果进行处理。若满意该结果,则搜索过程结束;否则,LPi将启动下一轮的迭代,进行深度为b的泛洪搜索。LPi向存在于布鲁曼滤波器中的邻居节点发送第二轮迭代的启动消息renew,其TTL=b。深度在a以内的节点只接收并转发这个消息,并不处理。直到深度等于a的前继节点收到renew后,丢弃renew并取出receiver a消息,开始进行深度为(b-a)的迭代搜索,重复步骤(4)的过程,直到TTL=c时结束搜索。由于TTL=c为最大的迭代深度,泛洪搜索到此结束。
(6)若LPi不满意返回的结果,则LPi可激活以改进的Chord机制和MKQ结合进行模糊查找。当搜索完成后,仍没有满意结果时,LPi将上报SP,由SP向上层CS请求资源。
(7)同DHT搜索一样,LPi在搜索成功后,将在缓存表中存储此次资源搜索相关信息以备下次使用。缓存表采取LRU策略进行维护更新。
4.3 节点退出
节点退出分为主动退出和被动退出,LPi的主动和被动退出流程大体同第3.4节所述,只是其邻居节点在LPi退出后,还需将其布鲁曼滤波器中的LPi信息删除。
5 算法仿真
实验中,利用BRITE产生不同节点规模N的底层P2P网络拓扑,所有节点的资源存放策略和热门程度均服从Zipf分布。
5.1 改进的Chord搜索机制仿真
采用DHT搜索机制,主要考察节点搜索过程中节点维护的路由表长度、查询消息转发次数和搜索成功率。传统的Chord算法的路由表长度为lbN,改进的Chord算法的路由表长度为2×log3N。在不同的网络规模下,每个节点所需要维护的路由表长度如图3所示,在不同的网络规模下,节点分别利用传统Chord算法和改进的Chord算法进行资源搜索时的查询消息转发,转发次数对比如图4所示。由图3可知,改进的Chord算法的路由表比传统的Chord算法的路由表长,但增长较缓慢。随着网络规模的增大,改进的Chord算法的路由表长度增长并不明显,但是路由消息转发次数却明显下降,如图4所示。因此,改进的Chord算法在网络规模较大时体现出明显的优越性。
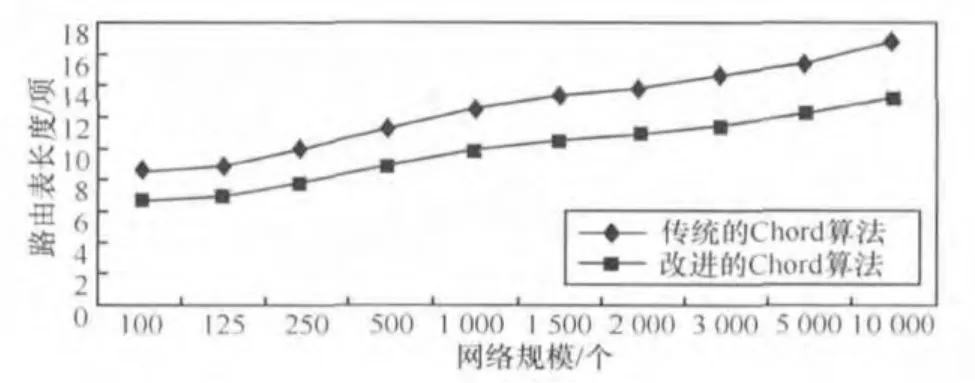
图3 改进的Chord算法与传统Chord算法路由表长度比较

图4 改进的Chord算法与传统Chord算法最大转发次数比较
采用MKQ支持模糊查找后,改进的Chord算法的搜索成功率比较如图5所示,由于引入了MKQ,改进的Chord算法只需在较小的转发次数内便可达到较高的查找成功率,而传统Chord算法则需要将近2倍的转发次数才可达到相同的查找成功率。

图5 不同Chord算法的搜索成功率
5.2 改进的泛洪搜索机制仿真
采用BF_Flooding搜索方式,主要考察采用布鲁曼滤波器报文结构查询时,网络中的冗余消息数量和搜索成功率。假设系统设定迭代最大深度为q,每个节点平均度数为d。在不同的迭代深度和邻居度数下,查询消息在网络中的转发流量如图6、图7所示。
由图6、图7可知,随着网络规模和节点度数的不断增加,采用BF_Flooding算法在度数较大时,其查询消息的转发量少于传统泛洪算法的一半,从而大大减小网络和节点的负担。

图6 不同泛洪算法产生的转发流量(q=3)比较

图7 不同泛洪算法产生的转发流量(q=6)比较
引入语义相关度匹配后的BF_Flooding算法与传统泛洪算法的搜索成功率的比较如图8所示。由图8可知,BF_Flooding算法通过引入语义相关度来支持模糊查找,提高了查询的命中率,其成功率稳定在80%左右,而传统泛洪算法远远低于该值。
6 结束语
本文主要讨论了混合流媒体系统资源搜索机制,由于传统的搜索机制较单一,没有考虑到资源知名度对搜索算法的影响,本文采用改进的Chord机制和BF_Flooding结合的混合搜索方式进行资源查找,并且为了更好地提高搜索成功率,分别引入MKQ和语义相关度匹配来支持资源的模糊搜索。由仿真结果可知,与传统的Chord搜索算法相比,改进的Chord搜索算法在小幅度增加路由表长度的代价下明显降低了查询路由时延,并且通过与MKQ结合,大大提高了搜索成功率。BF_Flooding算法与传统的泛洪算法相比,随着迭代深度和节点度数的增加,明显减少了查询消息在网络中的重复传输次数,大大降低了查询消息在网络中引起的冗余流量,通过引入语义相关度,支持了资源的模糊搜索,提高了资源搜索的质量。
1 施晓秋.非集中式P2P系统中资源搜索与现存问题分析.计算机工程,2007,33(5):91~105
2 崔晓微,董雷刚.非结构化P2P搜索方法分析与展望.大庆师范学院学报,2011,31(3):13~16
3 王煜坤.基于CDN和P2P技术的流媒体系统设计.现代计算机,2009(303):179~181
4 刘震,邓苏,黄宏斌.基于混合P2P网络模型的语义检索方法研究.计算机科学,2009,36(12):60~64
5 池静.Bloom Filter的研究和应用.河北建筑科技学院学报,
2003 ,20(4):59~61
6 Bloom B.Space/time tradeoffs in hash coding with allowable errors.Communications of the ACM,1970,13(7):422~426
7 张誉腾.混合P2P网络信息搜索方法的应用研究.湘潭大学硕士学位论文,2011
猜你喜欢
湖北第二师范学院学报(2020年2期)2020-06-05
魅力中国(2019年37期)2019-10-21
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
成都信息工程大学学报(2018年1期)2018-05-31
知识经济·中国直销(2016年5期)2016-11-07
系统工程与电子技术(2016年7期)2016-08-21
火控雷达技术(2016年2期)2016-02-06
信息安全研究(2015年3期)2015-02-28
中国教育网络(2011年1期)2011-09-25
