
面向图解树库的标注工具开发与优化
2014-02-28 00:44彭炜明宋继华杨天心
中文信息学报 2014年6期
赵 敏,彭炜明,宋继华,杨天心
(北京师范大学 信息科学与技术学院,北京 100875)
1 引言
树库作为包含句法结构信息的深加工语言资源,对语言学研究和NLP自动句法分析具有非常重要的基础作用,其标注规模和标注质量直接影响句法分析的效果。
近年来,国内外许多研究机构十分重视汉语树库资源的建设,相继构建出若干大规模的汉语树库,影响较大的有宾州中文树库[1]、Sinica树库[2]、清华树库[3]、国家语委树库[4]、北大中文系树库[5]和哈工大树库[6]等。目前主流树库所依据的语法理论主要局限于短语结构语法和依存结构语法两大体系之内。何静[7]等人依据黎锦熙先生的“句本位”语法,尝试构建了一个小规模的基于句式结构的语法树库。
大规模树库的构建完全采用人工标注是不现实的,人机结合的模式不仅能够发挥机器的效率优势,而且通过人工干预和校对也可以保证树库的质量,因此树库的构建通常采用人机结合的模式[3,8],这就需要一套切实有效的标注工具。工具设计的好坏,对语料标注的效率以及标注结果的一致性均有非常重要的影响。可以说,标注工具在一定程度上决定了整个树库工程的成败。
本文在分析现有图解标注工具优缺点的基础上,针对其标注模式和体系设计上的不足,重新设计并实现了一个更加高效的图解标注工具。
2 图解标注系统概述
目前,自然语言处理领域还没有面向英文的图解标注系统,中文方面也只有杨天心等人开发的图解标注系统[9]。该系统参考了黎氏图解法的析句思路,句法体系设计则依据经过改造的基于句式结构的图解析句法[10],即首先将句子成分划分为8种: 主语、谓语、宾语作为3种主干成分,位于长横线的上方;定语、状语、补语作为附加成分,位于长横线的下方;呼语和插入语作为不影响句式结构的独立成分以虚线连缀于主干之上,其图解总公式如图1 所示。

图1 标注图解总公式
2.1 现有图解系统的优点与不足
现有图解系统以一种简洁明了的方式展现了句子的整体结构,描绘出各个句子成分及其相互间的句法关系。在句法层次上强调“句式结构”,能够分析连动句、兼语句等复杂句式。所谓句式结构,是指对于特定句式的树库结构,其句子成分和中心词节点“具有相对稳定的结构层次和位置顺序”[10]。引入“句式结构”的思想,系统地归纳和总结出了汉语的基本句式和扩展变换句式。
该系统还保留了黎氏语法中“句法控制词法,依句辨品”的词类观,特定成分与词类存在对应关系,简化了词类标注的工作量。即实行“主、宾—名、代”、“谓语—动、形”的缺省对应,将谓词的“指称化”和体词的“陈述化”过程统一转化为一种“句法实现”[11]。
该系统在标注过程采用图解切分的操作模式,通过几次简单的鼠标点击,即可完成对全句结构的句法分析。这种简单直观的操作模式从根本上保证了树库构建的效率。
现有系统尽管优势明显,但在以下3个方面仍有改进的空间。
(1) 采用图解样式来区分一部分词类,表现在图解总公式中,定语、状语和补语3种成分可以有多种图解样式,从而使得图解操作变得复杂,且不利于句式的归纳提取。
(2) 未对汉语“临时造词”等词法现象进行相应的形式化设计,仅仅采用“加杠”方式连接,在XML中生成单一节点,此举增加了后续信息提取的难度。
(3) 图解总公式糅合了多种样式的定、状、补以及连动、兼语等句式成分,直观上看显得十分繁杂,对标注人员把握具体句式的图解样式造成了一定的干扰。
2.2 图解系统设计的改进
针对以上不足,我们对图解系统进行了体系改进,结合现代汉语教学语法的发展,重新设计了树库建设的标注体系和图解样式的编解码规范。鉴于树库体系结构和析句规范的制定是一个相当复杂的工程,涉及汉语句法系统的方方面面,而限于篇幅,我们将另文阐述,此处只给出一个示例图解样式及其XML数据结构的最终结果,如图2所示。
其中元素(Element)和属性(Attribute)所表示意义说明如下。
元素标记: ju(整句),xj(小句),sbj(主语),prd(谓语),obj(宾语),att(定语),uu(助词成分),a(形容词),u(助词),n(名词),v(动词),w(标点)。
属性与取值: xj包含ptt(句式结构)属性,取值SVO代表基本句式;prd包含scp(辖域)属性,取值VO代表动宾结构;uu包含fun(助词成分)属性,取值UD代表结构助词“的”;a、u、n、v包含sen(义项)属性,取值代表各自的义项编码。
改进后的新版系统与现有系统的主要区别表现在以下3个方面。
(1) 句法标注和词类标注的分离。词类标注不再受句法成分的限制,即不通过图解样式来区分词类。词类标注能够完全兼容目前主流的词类体系,在此基础上增加了词语义项标注的功能。
(2) 同一成分的图解样式不因成分内部的词类不同而产生异样,从而使得整句的图解样式进一步简化,句式系统更加凝练。
(3) 句式系统设计的逻辑性增强,按照“基本句式→扩展句式→复杂句式”的顺序依次展开:基本句式是仅包含主语、谓语和宾语三个主干成分的最基本句子结构;扩展句式是指在维持“主—谓—宾”主干格局的前提下又加入定语、状语、补语等附加成分的句子结构;而复杂句式指打破单谓语核心主干格局的复杂句子结构。
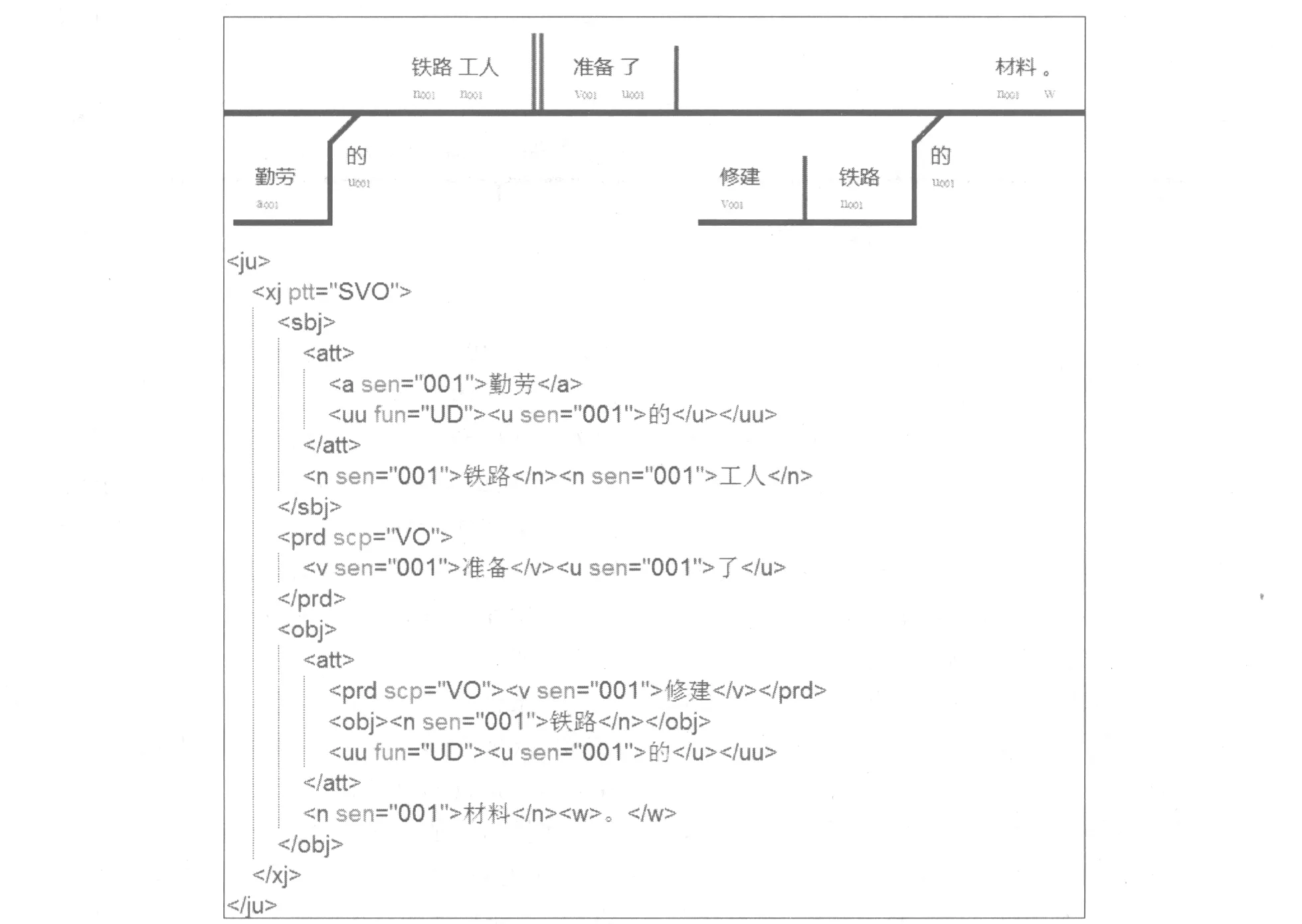
图2 图解图形与XML数据结构对应关系
3 标注模式实现
根据以上句式系统的设计,任何句子都可由基本句式经过扩展或复杂化得到。标注模式亦遵循这种由简单到复杂的思路,设计了一套“先 立 主 干,后分枝叶”的操作流程。这种“自顶向下,逐步求精”的流程设计符合人的认知心理,容易被标注人员接受和掌握;同时,借助图形化的人机界面,几次鼠标点击就能完成整句的句法切分和词法信息标注。这里首先给出图解标注工具的界面,如图3所示。
3.1 句法标注
下面以“勤劳的铁路工人准备了修建天桥的材料”一句为例说明句法图解的标注模式。标注人员首先确定句子的主干格局,将各个部分的内容切分到相应的主干位置上,如图4所示;然后对每一部分做内部短语结构的句法切分,如图5所示。

图4 图解标注模式(划分主干格局)
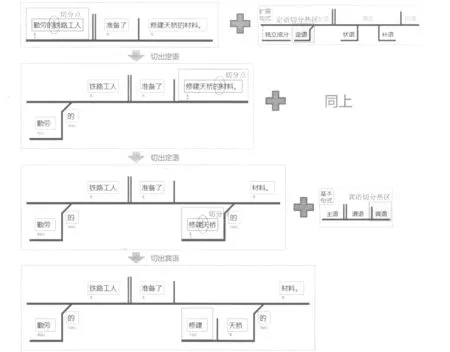
图5 图解标注模式(切分附加成分)
详细的操作流程阐述如下:
(1) 新建图解时,系统会默认生成一个基本句式的图形样式,选中焦点成分,将待分析的句子置于基本句式的核心——谓语文本框中。
(2) 切分主语: 将光标置于主谓待切分的文本位置,即“工人”之后,单击基本句式中的主语切分热区,工具会把光标位置前的文本置于到主语成分位置。
(3) 切分宾语: 将光标置于谓宾待切分的文本位置,即“准备了”之后,单击基本句式中的宾语切分热区,工具会把光标位置后的文本置于到宾语成分位置。
至此,句子“主—谓—宾”的基本格局已经确立,其后对主干各部分的附加成分做进一步的细分。
(4) 切分主语的定语和中心语: 将光标置于主语成分中待切分的文本位置,即“勤劳的”之后,单击扩展句式中的定语热区,工具会把“勤劳”和结构助词“的”置于新添加出来的定语成分和助词成分中。
(5) 切分宾语的定语和中心语: 切分方法同步骤(4)。
(6) 细分定语中的动宾结构: 将光标置于定语成分中待切分的文本位置,即“修建”之后,单击基本句式中的宾语切分热区,工具会把光标位置后的文本置于新添加出来的宾语成分中。
通过上述示例可以看出,图解分析过程采用二分的切分操作,通过几次简单的鼠标点击就能够快速构建出图解图形,完成句子的句法分析。
3.2 词法标注
词类和词义项的标注作为语料库建设的关键环节,对后续的信息提取、语义研究等具有十分重要的作用。本系统采用《现代汉语词典》作为底层知识库,辅助标注人员进行词单位的判断和词类、义项等属性的标注,实现了词法结构的标注功能,如图6所示,标注结果的词类和义项信息显示在词语文本框的下方。

图6 图解标注模式(词法分析标注)
3.2.1 基本词法标注
词法标注流程主要根据“义项标注区”中展示的词汇信息进行。词汇信息来自经过义项切分处理并存储于后台数据库的《现代汉语词典》义项知识库。《现代汉语词典》中词语的释义分为单字条目和多字条目,不同条目下再细分义项。我们从义项角度出发,为每一个义项标识了用3位数字来表示的义项编码(第一位为同形码,从0开始编号,后两位为同一条目下的义项编号,从01开始编号),并在该义项上附加了词类、用例、拼音等相关信息。
词法标注十分灵活,既可以在句法标注的过程中同时进行,也可以在句法标注完成后单独进行。在词语文本框中,将光标置于词语文本内部或边界处,义项标注区就会自动显示该词在词典中的所有义项,点击合适的义项即可完成标注。此时,选中的词类和义项码显示在词语下方,右侧被选义项则由黑边框突出显示。
3.2.2 命名实体的标注
命名实体主要是指: 从造句单位的角度出发,如果连续几个词汇可以整合为一个整体概念,则将其作为一个造句单位,不再进行图解切分,只做内部的“词法分析”。例如,图6中“铁路工人”由“铁路”和“工人”两个词汇组成,若认为其整体概念化,则只用空格分隔,再对两个基本词汇项分别进行词法信息标注。
3.2.3 特殊词类的标注
图解系统中,介词、连词、助词、语气词和方位词这5种词类对句法分析有一定影响,处理方式也与其他词类存在较大的差异,相应地,在其词类热区处也以特殊颜色突显。词法标注中分为两种情况: 其一,介词、连词、前置助词和语气词需要单独切出来做一个虚词成分。如图7所示,具体的操作过程为: 将光标置于待切分的位置,按“Ctrl”键并点击相应词类热区,工具会把字符文本置于新添加的虚词成分中。图解图形中,每种切分出的虚词成分都在横线下用特殊的符号标记该成分的词类信息和句法功能。其中,介词标记为“∧”,连词标记为“…”,助词标记为“△”,语气词标记为“▽”,方位词标记为“□”*有些后附的方位词用法类似于助词,这种情况下也按虚词成分处理。;其二,后置助词、方位词如果与中心词紧密结合成一个整体概念,则将其作为一个造句单位,只做词法结构分析,否则按前一种情况处理。
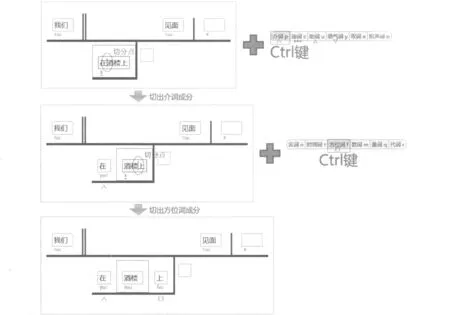
图7 图解标注模式(虚词成分切分)
为了提高树库标注效率,标注工具结合统计与规则的方法,添加了词法智能标注的功能: 一是统计词类和义项的频次信息,辅助标注人员参考判断;一是借鉴句本位“依句辨品”的思想,在词类辨析中进行基于规则的判断。程序会实时统计经审核标注结果的义项分布信息,并以阴影条的方式显示该义项在同形词所有义项中所占的百分比,如图6所示。词法标注过程中,若待标注词为单义词或者其多义项中有某一常用义项的分布比率占绝对优势(系统所设阈值为80%)时,程序会将该单义项或常用义项作为默认义项自动标注。如果待标注词在虚词成分中,且在该虚词词性下义项唯一,程序也会将该义项自动标注。当然,标注人员也可对多义项词的自动标注结果进行修改。
4 辅助功能
基于句式结构的图解标注模式从总体上保证了树库标注的效率,而增加便捷的辅助功能以优化人机界面,既能方便标注人员操作,提高树库标注效率,也可对树库构建的一致性起到特定的促进作用。本系统在图解标注基本功能的基础上,设计实现了一系列辅助树库建设的外围功能,比如成分的拖拽删除与交换、复制/粘贴、撤销/重复等。
4.1 图解成分的拖拽
图解标注过程中,拖拽是一种方便快捷的修改和调整图形的操作方式。系统对图解图形的编解码是根据最终的图解样式来进行转换的,而与中间的操作过程没有关系。所以通过成分控件的拖拽可实现成分的快速删除、顺序调整,有效提高图解标注的效率。如图8所示,“铁路”作为错误添加出的定语,操作上仅需将定语成分拖出图形边界即可删除定语。成分删除后其中文本“铁路”能回到它所依附的中心语成分,无需标注人员重新添加。

图8 成分删除示例
4.2 “复制/粘贴”和“撤销/重复”
为了在不调整整体句式的情况下,快速修改图形中的局部错误,系统针对NP、VP和小句3类句法单位,实现了复制与粘贴的功能。NP是由主语或宾语成分及其所带的定语、虚词等附加成分组成,VP是由谓语成分及其所带的宾语和状语、补语等附加成分组成。具体操作时,先把待复制的成分选为焦点成分,按“Ctrl+Shift+C”完成复制操作,接着选中待替换的焦点成分,按“Ctrl+Shift+V”完成粘贴操作。考虑到句法约束,粘贴操作只能替换相同类别的句法单位,即NP↔NP、VP↔VP、小句↔小句,而无法进行类似NP↔VP的替换操作。
此外,考虑到标注过程中偶尔会有一定的误操作,为了能够让标注人员在不用重新标注的情况下就能快速地修正错误,系统设计并实现了图解操作的撤销与重复功能。标注人员可通过按“Ctrl+Shift+Z”和“Ctrl+Shift+Y”执行。
5 图解实践的效果分析
为了检验标注工具的效果,完善相应的语法理论,并在标注过程中发掘更加合理高效的标注模式和机器辅助算法,我们将标注工具应用于句本位语法树库构建工程。树库构建所采用的生语料主要来源于国际汉语教学领域,遴选了一部分国际汉语教材文本作为首批标注语料。语料文本通过Web上传入库,上传后按照标点“。|?|!|: ”切句,切分后的句子作为图解析句的标注单位。
树库工程实施中,具体标注人员主要是高校的本科生和研究生,学科背景既有语言学相关专业的,也有非语言学专业的。我们制定了相关的规范文档用来培训标注人员,使其能够快速掌握图解系统的基本操作方法和标注规范。尽管标注人员的语言学基础不同,但经过一两天的培训学习和图解标注实践,基本上都能达到相对熟练的程度,标注正确率和速度接近平均水平。树库工程初始阶段以人工标注为主,在机器辅助的条件下,人均正确标注效率能够达到: 4 128字(238句)/每天(7h)。新版工具增加了词语义项的标注,义项的判断与选择相应会耗费更多的时间,但其标注效率与没有进行义项标注的现有工具基本持平*根据文献[11],其标注效率为: 4 450字(207句)/每天(7h)。。从总体来说,新版工具具有更高的标注效率。
相比短语结构体系和依存结构体系,基于图解析句的树库标注之所以能够体现出相对的效率优势,其中原因分析如下:
短语结构强调句法结构层次,在处理某些线性组合(如“状—状—动”、“状—动—宾”)的层次时,需人工进行逐级的层次划分,而这种层次因为受线性顺序的约束是可以由工具系统来完成的(如本系统的设计)。依存结构分析在这一点上与本系统是一致的,但是它也受统一的二元依存的影响,句法标注过于细碎。处理复杂长句时,部分依存弧的标注操作变得繁琐。而本系统词法标注的设计和逐层划分的方式使图解分析变得更加快捷。
以目前树库建设的进度来看,基于句式结构的语法理论和与之对应的图解标注工具对于树库构建效率的提升是十分明显的,所需投入的人力和物力资源也被大幅削减。接下来的工作是,在积累一定规模的语料之后,将深入研究机器自动辅助分析算法,使系统更具交互性和智能性,推进大规模深层标注句法树库的建设。
[1] Naiwen Xue, Fei Xia, Fu-Dong Chiou et al. The Penn Chinese TreeBank: Phrase structure annotation of a large corpus [J]. Natural language engineering, 2005, 11(2): 207-238.
[2] 陈凤仪, 蔡碧芳, 陈克健等. 中文句结构树资料库(Sinica Treebank)的构建[J]. Computational Linguistics and Chinese Language Processing, 1999, 4(2): 87-104.
[3] 周强. 汉语句法树库标注体系[J]. 中文信息学报, 2004, 18(04): 1-8.
[4] 靳光瑾, 肖航, 富丽等. 现代汉语语料库建设及深加工[J]. 语言文字应用, 2005(02): 111-120.
[5] 詹卫东. 大规模中文语料库句法结构信息标注及定量分析[C]//第二届现代汉语句法语义国际学术论坛, 台湾: 新竹, 清华大学.2009.8.22-24,
[6] Ting Liu, Jinshan Ma, Sheng Li. Building a dependency treebank for improving Chinese parser[J]. Journal of Chinese Language and Computing, 2006, 16(4): 207-224.
[7] 何静, 彭炜明, 宋继华. 现代汉语黎氏语法图解标注体系[C].第十四届汉语词汇语义学国际研讨会(CLSW2013). 郑州: 郑州大学, 2013-5-12.
[8] 赵怿怡, 关润池. 汉语依存树库的构建[C].第三届学生计算语言学研讨会论文集, 2006.
[9] 杨天心, 彭炜明, 宋继华. 基于句式结构的高效语法图解标注系统[J]. 中文信息学报, 已录用.
[10] 彭炜明, 宋继华, 王宁. 基于句式结构的汉语图解析句法设计[J]. 计算机工程与应用, 2014, 50(06): 11-18.
[11] 彭炜明, 宋继华, 俞士汶. 中文信息处理的词法问题——以句本位语法图解树库构建为背景[C].第十四届汉语词汇语义学国际研讨会(CLSW2013). 郑州: 郑州大学, 2013-5-12.
猜你喜欢
新世纪智能(英语备考)(2019年10期)2019-12-16
现代交际(2019年17期)2019-11-13
新世纪智能(语文备考)(2019年3期)2019-01-12
科技经济市场(2017年5期)2017-09-16
知识窗(2015年1期)2015-05-14
中学语文(2015年18期)2015-03-01
Beijing Review(2012年37期)2012-10-16
中学语文(2012年34期)2012-08-15
中学生英语高效课堂探究(2011年4期)2011-07-07
