
机器翻译自动评价综述
2014-02-28 07:57李良友贡正仙周国栋
中文信息学报 2014年3期
李良友,贡正仙,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006; 苏州大学 自然语言处理实验室,江苏 苏州 215006)
引言
机器翻译评价是一项复杂而具挑战性的研究课题,它与机器翻译技术的发展息息相关。目前它面临的最主要的问题在于评价指标的确定。在评价过程中,人工译文经常作为评价的标准,但是由于语言表达的多样性,人工译文不可能完全覆盖所有的正确译文。同时,人工译文具有一定的主观性,对于同一篇文章,不同的人会有不同的理解,这种差异也增加了这项任务的困难。因此,一个全面、客观的评价体系是必不可少的。欧盟、美国国家自然科学基金会和瑞士政府支持的ISLE(International Standards for Language Engineering)项目在2000年提出了机器翻译评价的ISLE/ EAGLES 体系[1],该体系的核心思想是,评价不是找出系统的缺陷、找出它不能够做什么,而是找出系统能够在哪方面减轻人工劳动[1]。在此思想的指导下,研究者们提出了多种评价方法。
机器翻译的评价方法按照评价者的不同可以分为人工评价和自动评价。人工评价的准确率高,但需要耗费大量的人力和时间。而自动评价方法具有成本低、速度快和一致性高的优势,但是评价的准确率*目前自动评价的准确率主要指其与人工评价的相关度。常用的计算方法有: 皮尔森相关系数(Pearson correlation coefficient)、斯皮尔曼等级相关系数(Spearman rank correlation coefficient)和肯德尔等级相关系数(Kendall’s tau Rank Correlation Coefficient)。较低,因此它也是机器翻译方向一项很重要的研究内容。
本文从两个角度对自动评价进行介绍,一是侧重评价方法本身,另一个是针对受限参考译文。针对评价方法的部分主要讨论各种主流评价方法,并根据其所依赖的核心技术出现的时间次序予以介绍,这种介绍方式能体现出评价方法的发展历程和变化。针对参考译文的研究包括两个方面: 不使用参考译文进行评价和自动扩展参考译文用于评价。这类研究虽然在评价技术上的贡献并不显著,但是对提升自动化程度和评价性能有着非常积极的意义,因此本文也特意设立一个章节对此进行介绍。
本文下面几节的安排如下: 第1~3介绍一些主流的评价方法,包括基于语言学监测点的方法、基于字符串相似度的方法和基于机器学习的方法;第4节从参考译文的角度进行介绍;第5节介绍两个著名的国际评测大会对评测结果进行简要地分析;最后进行总结,并指出自动评价方法的发展趋势和有待进一步研究的问题。
1 基于语言学检测点的方法
早在1993年,北京大学计算语言学研究所的俞士汶教授就在Machine Translation一个专辑上提出了基于检测点的评价方法[2]。该类方法可以看作是目前最为实用的评价方法。评价时并不是考虑译文的全部,而是只根据事先定义好的语言学测试点,对译文的相应部分进行打分。但是文献[2]中测试集的构造不是一个完全自动化的过程,所以成本较高,没有得到广泛地使用。
2008年,微软亚洲研究院自然语言计算组的周明博士等在这种方法的基础上,提出了一种采用自动构建语言学检测点的机器翻译评价方法[3],其实现平台为WoodPecker,该方法有如下特点: (1)利用句法分析器、词对齐工具等自动构建测试集;(2)利用多个句法分析器提高抽取检测点的准确率,并使用词典计算自动抽取的检测点译文的可信度;(3)采用了基于n元匹配的计算公式进行打分,能更精细地体现匹配程度;(4)由于采用自动方法抽取检测点,该方法能够方便地应用到其他语言对的翻译评测上。
从2008年开始,国内的CWMT评测*http://nlp.ict.ac.cn/new/CWMT/index.php已连续两年采用该种评测方法。与国际上主流的机器翻译评测方法相比,该方法不仅可以对机器翻译系统给出一个总的评价,而且能使研究者快速了解评测系统在各个语言点上的翻译能力,方便比较不同系统以及不同机器翻译模型的性能。同时,与其他应用了语言学特征的自动评价方法相比,基于检测点的方法可以针对较为完备的语言学分类体系,把语言学类别作为评价的目标;而其他方法多是将语言学特征仅仅作为宏观评价的一个维度。
2 基于字符串相似度计算的方法
1997年,WER、PER被应用在评价上[4],可看作是最早的基于字符串相似度的评价方法。该类方法主要关注词汇及其顺序的正确翻译,它们一般将译文看成是符号的序列,通过计算候选译文和参考译文间的序列相似性评价翻译质量。本节将它们分为3类,并按照时间顺序进行介绍: (1)基于距离的方法;(2)基于n元语法的方法;(3)基于词对齐的方法。
2.1 基于距离的方法
基于距离的方法认为一个句子越容易改写成另一个句子,则两句的相似度越高。因此,这类方法主要利用定义的改写操作及其代价计算译文之间的距离,通常使用的操作有插入、删除、替换和移动。并采用错误率的形式给出评分,如式(1)所示。
其中dist(c,r)是候选译文c和参考译文r之间的距离,l是归一化因子,通常取参考译文长度。常用的基于距离的评价方法有PER、WER、TER[5]和CDER[6]。
评价时,PER只考虑插入和删除两个操作,即忽略词序,常会高估译文的质量;WER使用插入、删除和替换三个操作,即编辑距离,因此WER严格要求译文的词序,会低估译文的质量;TER和CDER都在计算距离时考虑了块移动。需要注意的是,块移动操作的加入使得编辑距离的计算成为NP难问题[7],所以需要采取一定的策略在多项式时间内寻找较优的结果。TER采用了两种方法: 使用贪心算法选择移动操作集合,限制移动操作出现的位置;CDER则放松了传统距离计算中存在的限制,允许候选译文中的词参与0次或多次改写操作。
通常,距离计算中的操作代价都为1,但文献[6]提出: 参与替换的两个词的相似度越高代价越小。并据此采用了两种计算替换操作代价的方法: 两词的字符编辑距离(Lev. subst)和共有前缀长度(prefix subst)。
表1是文献[6]的实验结果。从结果可以看出CDER取得了最好的成绩,而且WER和CDER在加入替换代价后,评价准确率都有不同程度的提高。但是TER却表现的不是很好,可能原因是像文献[5]指出的,TER会高估译文中实际存在的错误。
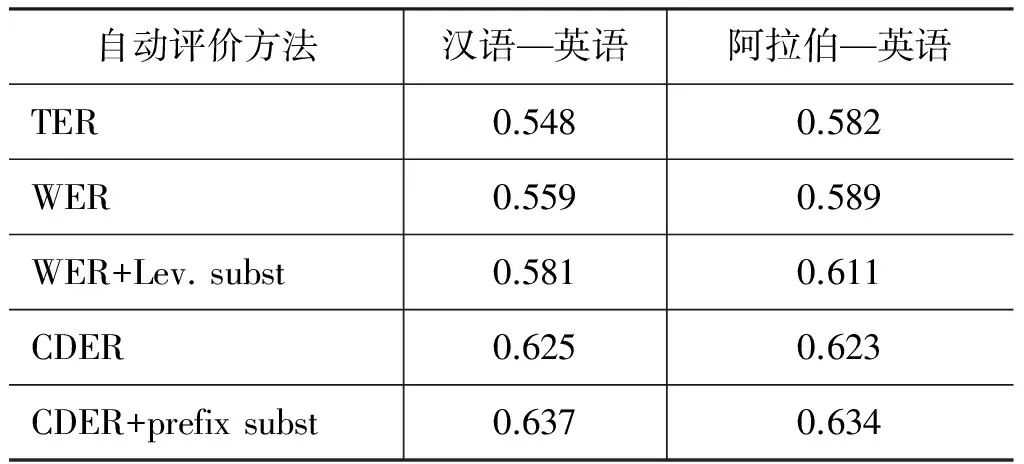
表1 自动评价与人工评价的皮尔森相关系数
2.2 基于n元语法的方法
基于n元语法的方法的基本模式是在候选译文和参考译文的n元语法集合上建立匹配,然后计算匹配得分。2002年,Papineni等人提出了第一个基于n元语法的评价方法—BLEU[8]。
BLEU用候选译文n元语法的准确率计算几何平均得到句子的相似度,如式(2)所示。所谓n元语法的准确率就是候选译文中的n词串出现在参考译文中的比例。为了防止句子通过重复n元语法提高分值,BLEU在计算准确率时限制其次数不能超过参考译文中该n元语法的最大数量。
其中pn表示n元语法准确率,BP是句子长度惩罚因子:
其中c为候选译文中单词的个数,r是与c长度最接近的参考译文长度。
目前,BLEU已基本成为自动评价的标准方法。但是它也存在一些明显的缺陷。文献[9]给出了BLEU的三个不足: (1)在同义词和复述方面的不足;(2)所有单词的权重都一样,没有区分实义词和功能词的不同影响;(3)缺少召回率的计算。同时,实验结果显示,BLEU偏向于统计的机器翻译模型,尤其是基于短语的模型,而对基于规则的系统给出的评价通常不可靠。不仅如此,BLEU使用的是n元语法的几何平均,由于高阶语法数据稀疏,可能导致BLEU分值为0,因此BLEU一般将多个句子作为单位进行评价,以减轻数据稀疏的影响。
针对BLEU中存在的问题,有很多研究提出了改进,例如,
• NIST[10]: 用算数平均取代BLEU中几何平均;同时NIST根据n元语法在参考译文中出现的次数给其不同的权重。
• WNM[11]在计算n元语法准确率时使用了词的权重信息,一个词的权重由它在参考译文中出现的频率决定(通过tf、idf和s-score计算)。
• ROUGE[12]和SIA[13]采用公共子串进行评价。公共子串可以看作传统n元语法的扩展,允许词出现的位置不连续,因此能反映远距离的句子结构。
• MAXSIM[14]采用了基于语言学知识的多种规则确定n元语法匹配,并且每个匹配有一个权重,因此可以看成是模糊匹配。
2.3 基于词对齐的方法
2003年,文献[15]提出的GTM是最早采用词对齐并同时使用准确率和召回率进行评价的方法。基于词对齐的方法有两个特点: (1)能在候选译文和参考译文之间建立词汇的对应关系,详细显示词汇翻译的情况;(2)对齐可以反映译文间词序的不一致。
目前应用最广泛的基于词对齐的方法是METEOR[16],它是在GTM的基础上发展而来。主要有以下明显的特点:
(1) 为增加对齐的可能性,使用了不同的模块: 严格词形对齐;词根相同对齐;WordNet同义词对齐。这种基于模块的方法有很好的可扩展性,但由于METEOR使用了词根和WordNet,因此只能在有限的几个语言中使用。而且同义词匹配并没有考虑上下文。
(2) 使用Fmean值计算词汇翻译得分,并在实际应用中加大了召回率在评价中的重要性,如式(4)所示。
其中α是可调节的参数,P是准确率,R是召回率。
(3) 显式地对词序进行打分,根据对齐中的块数,计算词序的惩罚因子,如式(5)所示。
其中γ和β是可调参数,m是候选译文和参考译文长度的均值,ch是对齐中的块数。
METEOR评价的最终得分由Fmean和Pen得到,如式(6)所示。
2.4 本节小结
根据前文对基于字符串相似度的自动评价方法的介绍,此处将总结其发展的几个特点。
(1) 召回率在评价中的重要性。基于距离的方法可以看作采用召回率;n元语法和词对齐的方法也在重视召回率的计算。而且召回率的重要性往往大于准确率[14, 16]。WMT2007中的ParaEval-recall[17]方法只使用了一元语法的召回率,却在评测中取得了较好的成绩[18]。当然召回率的使用也降低了评价方法对多参考译文的使用能力。
(2) 语言学知识的使用。一些较早的方法只使用了严格词形,这样会过度地惩罚译文。因此近来的方法都加入了深层次的语言学知识,如TERp[19]在TER的基础上加入了复述技术;文献[20-21]使用了一系列基于词性、语素的n元语法匹配进行评价。
(3) 评价中考虑权重,包括句子成分权重和匹配权重。例如,TESLA[22]在MAXSIM上进行改进,降低了功能词的作用,并且允许n元语法的一对多匹配,每个匹配都有相应的权重;文献[23]也对METEOR加入了对齐和词汇的权值;像WNM、AMBER[24]在BLEU的基础上使用tfidf作为词汇的权重。
(4) 词序问题。基于距离的方法对词序的限制较为严格;基于n元语法的方法中高阶n元语法仅能考虑局部词序;而词对齐方法则可以基于对齐定义词序惩罚因子。研究显示评价中直接衡量词序问题会对评价带来帮助[25-26]。
3 机器学习方法
从2001年开始,机器翻译自动评价中出现了使用机器学习进行评价的研究。通过引入机器学习模型,一方面可以抽取并使用与语言相关的内在特征,另一方面也可以结合已有的评价方法。因此,机器学习在提高自动评价和人工评价的一致性方面具有重要的意义,其优势在句子级的评价方面显得尤为突出。
3.1 自动评价中常用的机器学习方法
目前评价中的学习方法可以归结为三个方面: 分类、回归和排序。
分类学习将评价看成分类问题,既可以用来区分机器译文和参考译文[27],也可以从多个系统中选取最好的译文[28-29]。但是对于分类来说,“好”与“坏”的边界很难确定,而且弱化了数据中的不同评分反映的质量差异。
回归的方法将训练数据看作(x,h)的集合(其中x是特征向量,h是人工评价),通过训练调节不同特征的权值使得特征组合产生的评价尽可能地接近训练数据的人工评分。如使用线性回归模型[30]、SVM回归模型[31]等。
排序学习反映的是不同系统译文之间的相对质量,在一定程度上可以看成是一种多分类问题。虽然分类和回归方法也可以产生排序,但是它们需要一个从评分到排序的转换过程。而且由于人工排序产生的数据更加可靠[32],因此排序在评价中被认为是比较合适的方法[33]。
一些研究发现,分类的准确率高并不能保证评价效果好,回归的方法比分类更加可靠[34];在相同的特征集上,回归和排序方法评价效果相似[35]。
3.2 机器学习在混合多种评测方法中的应用
任何单个的评价方法都不可能准确地把握决定译文质量的各个因素[30],因此其在适应性和稳定性上存在一定的缺陷。一种解决的办法就是组合不同的评价方法,从多个方面同时进行评价。
最直观的组合方式就是线性组合,其基本形式可以表示为式(7)。
其中wj表示第j个自动评价方法xj的权重。
显然机器学习是进行训练的一种有效方法,如TESLA使用了SVMrank进行训练。当然也可以采用针对目标函数的最小错误率训练进行优化[36],而ULC[37]直接采用均值,如式(8)所示。
它不需要进行权重训练,但是这种做法也使得权重失去了意义。
由于组合中的单个方法都需要对候选译文进行评价,所以盲目地组合会增大评价的代价,有时还会导致性能的下降。文献[37]提出了一种寻找最优组合的方法: 各个评价方法按照与人工评价的相关度降序排列,然后逐个加到最优集合直到组合的评价性能不再提高。实验中文献[37]从TER、BLEU、ROUGE、METEOR以及其他一些基于句法语义的方法[38]中进行选择,验证了最优组合的优势。因此组合中的方法数量与性能并不成正比,在进行组合时,选取的方法应能代表译文不同方面的质量,这样会产生较好的效果[36]。
3.3 机器学习在综合多个特征中的应用
由于机器学习可以使用任何能用数字度量的特征,所以除了组合已有方法外,还有很多可用的有效特征。但是特征并不是越多越好,因为随着数量的增加,特征之间的相互制约和影响会增大,训练和评价的代价也会增大。本小节从特征类型和特征组合效用两个方面进行介绍。
3.3.1 特征类型
根据语言学知识的不同,特征主要可以分为三类: 词汇、句法和语义。
其实一些已有的自动评价方法可以看作是对语言学特征的简单使用,例如,基于词汇特征的WER和BLEU,基于句法特征的STM、HWCM等评价方法[39],基于依存关系的方法[40],基于语义角色的方法[41-42],还有文献[38]中的一系列基于浅层句法、语义、命名实体等的方法。但是这些评价方法对特征的使用不够灵活。
虽然机器学习中常根据已有的评价选择特征[30, 33-35, 43],这些特征代表了译文在词汇、句法、语义等层面上的质量,但是机器学习还可以使用非直接评价的特征,如词的数量[44]、句子长度[28, 45-46]、未知词[27, 46]、句法树的性质[27]、解析工具的准确度[46]、语言模型相关特征[46]、实义词和虚词相关特征[27]等。这些特征大多数反映了翻译中常存在的错误现象。
3.3.2 特征组合的效用
各个特征的贡献在不同的任务上会有不同,本文建议在进行特征选择时需要考虑以下方面:
(1) 基于深层语言学的特征可以有效提高评价效果。如复述特征对评价的帮助[30],依存结构对评价句子流利度的作用[33]。文献[47]对比了基于n元语法的方法和基于深层语言学的评价方法,发现深层语言学知识能提高系统和质量较差句子的评价准确度。
(2) 盲目地组合各类特征并不一定会产生好的评价,一些简单直观的特征贡献更多[45]。文献[30]的分析显示,词汇匹配的特征对句子准确度评价贡献较为显著,而词序的一些特征对流利度评价做出了主要贡献。因此在选取特征时应该考虑特征是否代表了翻译中存在的问题,或者是否反映了译文质量的某些方面。
(3) 通过查看近年来的研究可以发现,大部分特征还只是来自句子内部,句子之间或者篇章结构等上下文很少被考虑。这主要是因为多数自动评价针对句子,所以只涉及到局部上下文。由于目前篇章的翻译越发显示出其重要性,能反映篇章信息的特征也是一个很好的应用。
4 参考译文对评价的影响
前面三节介绍的评价方法都是在具有特定参考译文的情况下对译文质量进行评价的,重在研究评价方法的设计和提升。但是人工参考译文的数量有限,费用昂贵并且获取费时。因此,一些研究者试图从另一个角度——受限参考译文—-出发来提高自动化程度和评价性能。这类研究可以归结为无参考译文的评价方法和扩展参考译文的评价方法。
4.1 无参考译文的评价
无参考译文的评价通常又称为质量估计。目前无参考译文评价的效果还不太令人满意,但是其可用范围比较广泛,也具有较强的实用价值,如过滤译文以进行人工编辑或选取最好的译文等。由于源语言和目标语言没有明显的对应关系,因此评价通常是通过学习产生的。
文献[48]选取一些目标语言的特征训练SVM分类器[43],结合语言模型的困惑度对句子流利度进行评价;文献[29, 46]结合使用了源语言特征,指出源语言特征对无参考译文评价有着重要的作用[29]。与选取特征的方法不同,文献[49]通过训练词汇的翻译概率使用IBM1进行评价,但缺少对词序的衡量。
4.2 扩展参考译文
扩展参考译文就是使用某些方法自动增加参考译文数量,以提高参考译文所能提供的信息量,给评价带来帮助。本节主要介绍两种扩展参考译文的方法: 伪参考译文和复述。
4.2.1 使用伪参考译文
所谓伪参考译文就是将其他机器翻译系统的译文作为参考译文。Albrecht和Hwa[31]发现使用四个伪参考译文的评价效果要好于一个人工参考译文。但是相比于其他一些自动评价,基于学习的方法对伪参考译文的使用更加有效,因为基于学习的方法会在学习的过程中决定伪参考译文的可信度,所以得到的自动评价具有更好的健壮性[50]。虽然伪参考译文存在质量问题,但是根据文献[51],参考译文的数量和质量对评价的影响并不是绝对的,因此伪参考译文也可以作为评价中的可用资源。
4.2.2 复述的使用
复述表示语义对等的句子或短语,研究的是同义现象[52]。前文已经提到了一些自动评价方法使用了复述匹配[17, 19, 23],此处主要介绍复述生成[52]在评价中的使用。
句子级复述的生成可以直接使用复述的平行语料训练一个机器翻译系统实现[53],这种方法的一个好处是能快速地增加参考译文的数量;短语级的复述则可以使用词对齐自动地从双语平行语料中抽取——对齐到相同源语言短语的目标短语对是复述短语对,然后利用这些复述短语对在参考译文上建立混淆网络,网络中的每条路径对应参考译文的一个复述,自动评价可以在该网络上选取最好的评分[54];利用一些已有资源,如WordNet,可以在参考译文上进行同义词替换,使其在形式上最接近候选译文,同时基于替换词的上下文信息判断当前替换是否可行,能有效地提高复述的准确率和自动评价的性能[55]。
事实上,除了复述的质量之外,复述在评价中的使用还存在很多问题,其中最明显的就是缺少对上下文的考虑。虽然文献[55]使用上下文训练了一个分类器,但是这种方法对评价来说比较费时。另一个值得注意的问题是,目前评价只关注复述实例的使用,并不考虑复述规则。
5 自动评价方法的评测比较和分析
随着自动评价的不断发展,自动评价的评测也显得越来越重要,因此本节介绍两个著名的国际评测: WMT和MetricsMATR。
5.1 WMT
从2006年开始的WMT(Workshop on Statistical Machine Translation)每年举办一次,其主要任务是对机器翻译系统进行评价,评价方法使用人工评价和自动评价相结合。会议中的一个共享任务就是自动评价方法的评测。WMT使用的是欧洲平行语料,所以其自动评价方法主要使用在英语和其他欧洲语言上。
图1和图2显示了2007—2011年一些自动评价方法的评测结果[18, 56-59]。根据系统级和句子级两种评价粒度、英语和欧语两类语言,可以组合产生四种类型的评测。图中保留了各个评测类别中成绩最好的方法以及前文介绍并出现在评测中的若干主流方法。其中图1给出的是2007—2009年系统级评价的结果,虽然WMT2008和WMT2009评价中已经加入了句子级评价,但是受篇幅所限本文未给出;图2 是WMT2010和WMT2011中四个类型的评测结果。
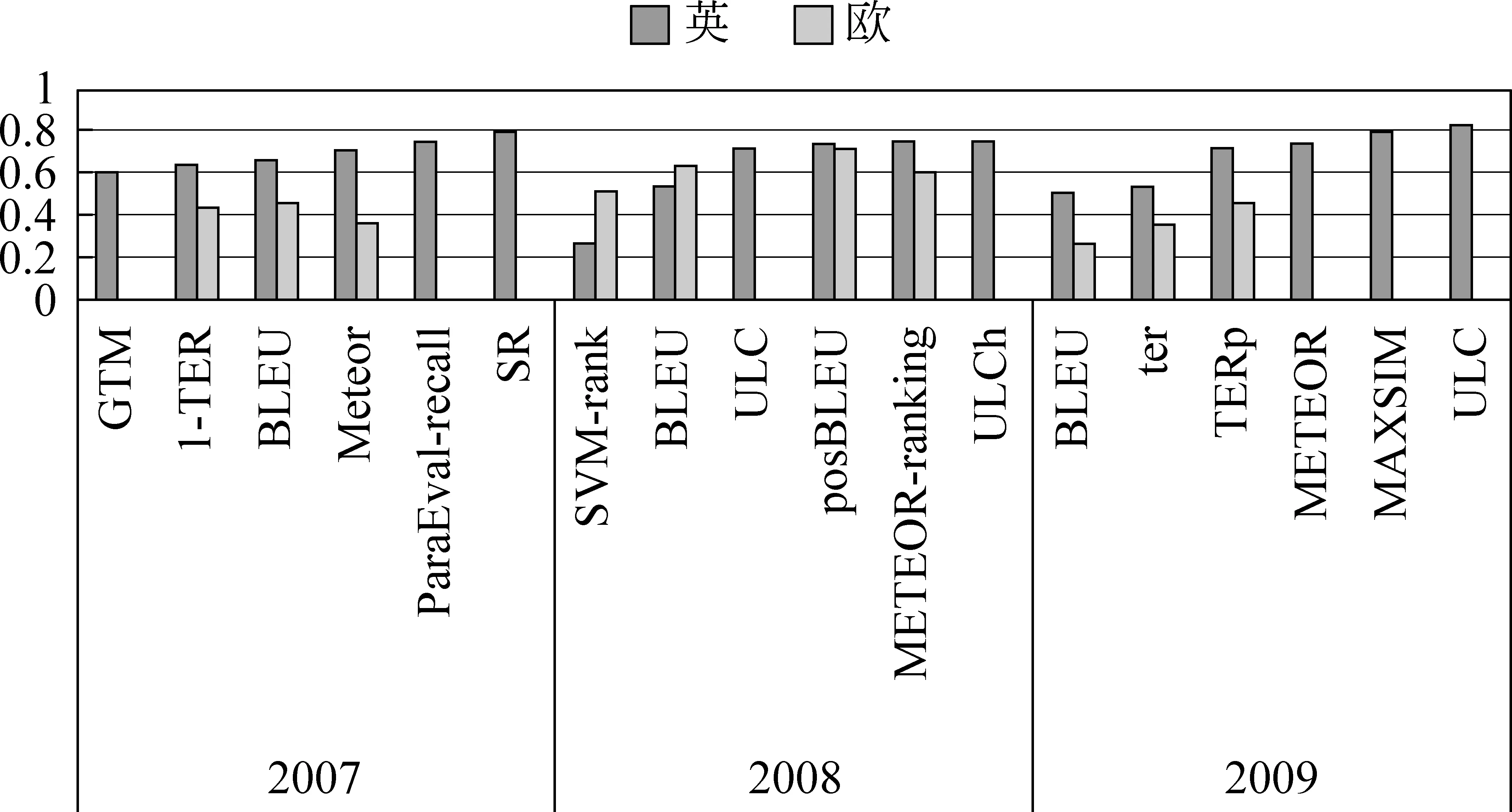
图1 2007—2009年WMT系统级评价的斯皮尔曼等级相关系数

图2 2010—2011年WMT系统级和句子级的英欧语言评价的相关系数。其中系统级使用斯皮尔曼等级相关系数,句子级使用肯德尔相关系数。
观察图1、图2可以发现近年来自动评价中存在的一些现象和问题。
(1) 近来的方法多基于一定的语言学知识(如POS、句法、语义等),而且这些方法在历年的评测上都取得了不错的排名。一些已有的词汇级方法加入较深层语言学知识后,性能也有显著提高,如2009年的TERp等。但是深层语言学知识的作用并不是绝对的,如2010年的I-Letter-BLEU,该方法是将BLEU的计算方法应用在字符序列的评价上,并且n元语法的最大长度由句子长度决定,虽然简单,但是它在评价中取得了最好的成绩。因此如何有效的使用各种知识似乎更加重要。
(2) 组合方法在评价中取得了较好的结果,如ULC(或ULCh)连续三年的参评中都名列前茅,远高于其组合成分中的单个方法。
(3) 评价方法在不同类型的评价上表现不一致。例如,2010年的机器学习方法SVM-rank在句子级上取得了最好的成绩,而系统级要差一些。2007年BLEU方法在英语上虽然表现不佳,但在其他欧洲语言上取得了最好的效果。评价方法的这种不稳定性的一个原因是方法在设计时就针对特定类型或级别的评价,或受到使用的资源的限制,所以其应用也会受限。
5.2 MetricsMATR
另一个针对自动评价的评测是NIST从2008年开始每两年举办一次的MetricsMATR*2010年WMT与MetricsMATR联合举办,此处不再对MetricsMATR2010进行介绍。。针对评价中存在的问题,如人工评价费时费力、评价效果还不能很好地预测系统的性能、很少有针对非英语语言的自动评价方法等,MetricsMATR将创办目标定为: 提供一个公共的平台从多个方面测试各个自动评价方法的优劣,以对方法的改进提供详细、有效的指导。
2008年的MetricsMATR评测[60],除了从句子级、文档级、系统级三个方面计算自动评价与人工评价的相关度之外,评价速度、对系统的区分度等也是评测的内容。因此MetricsMATR中结果对于分析不同评价方法在不同条件下的优劣提供了很好的指导。
其中,MetricsMART2008在评价速度上的实验很值得评价方法的设计者反思,如图3所示。虽然由于采用深层语言学知识或者组合等更加复杂的形式,多数自动评价方法取得了较好的评价效果,但是评价的速度也随之降低。如果需要频繁对不同数据进行评价,显然借助于解析工具或训练的方法实用性会大大降低。
5.3 评测小节
根据前面的介绍,可以看出,机器翻译的自动评价获得了足够的重视和广泛的关注,其评价结果也相应地成为机器翻译研发的风向标。在自动评价方法和方法的评测之间存在一个良性循环: 评测可以指出自动评价方法存在的缺陷,为下一步改进提供指导;自动评价方法也为评测提供了方向、前沿的研究信息和趋势。

图3 MetricsMATR2008中评价方法的评价速度
通过对评测结果的分析,可以发现,深层语言学知识虽然有助于提高评价的准确度,但其作用并不是绝对的,而且目前评价方法几乎已经涉及到了所有可用的语言学类别,所以与更加复杂的深层知识相比,如何有效利用一些简单的信息似乎显得更加重要。并且用抽象的语言学知识对语言本身进行分析,这也会限制自动评价方法的使用范围。
目前针对自动评价并没有形成一个统一、可靠的评测体系,主要是由于自动评价方法在不同环境中的表现并不相同: 不同语言、不同参考译文、不同人工评价、相同语言但数据不同等。因此在使用各个方法时应根据其特点进行选择,如WordNet的使用会限制适用的语言范围、速度的要求会更加倾向于简单的方法等。
6 总结
本文对机器翻译的自动评价进行了较为全面的分析和介绍。根据自动评价方法出现的时间先后,本文介绍了基于检测点的方法、基于字符串匹配的方法和基于机器学习的方法。以上方法都是针对改善自动评价方法本身而进行的,但是另一类研究也不可以忽视,那就是针对受限参考译文的研究,它们对提升评价方法的自动化程度和评价性能有着积极的意义。从本文的描述中可以看出,自动评价有以下发展趋势或特点。
(1) 句法、语义等深层语言学知识的使用。深层语言学提供了更加抽象的语言表现形式,在评价中允许词汇或句法的合理变化。因此深层语言学知识使得评价更加灵活和可靠;
(2) 倾向于从多个方面组合评价。单个方法或特征往往只能从有限的角度考察句子的质量,因此把面向不同方面的方法或特征聚集起来,可以在较小代价下给出更加全面的评价;
(3) 评价方法多针对单个句子进行。这主要因为多数机器翻译系统的输入单位都是句子。而系统评价或篇章评价则是由句子评价中的数据组合得到。
虽然近年来自动评价技术已在各种机器翻译评测大会中被广泛地使用,但是还有很多需要考虑的问题,如: 对于篇章来说,存在一些结构上的特征,例如实体的指代,上下文的一致性等,句子为单位评价时会忽略这些信息,因此如何评价篇章翻译还是一个需要研究的问题。
同时本文建议,在设计评价方法时应遵循简单、有效、通用的原则。这一点BLEU最具有代表性,虽然诸多研究指出了BLEU的不足,但是BLEU依然得到了重视,尤其在系统调参过程中,还没有形成公认的、被广泛使用的替代性选择。
[1] International Standards for Language Engineering[DB/OL]. http://www.ilc.cnr.it/EAGLES96/isle/ISLE_D14.2.zip.2003.
[2] Y Shiwen. Automatic evaluation of output quality for Machine Translation systems[J]. Machine Translation. 1993, 8: 117-126.
[3] M Zhou, B Wang, S Liu, et al. Diagnostic evaluation of machine translation systems using automatically constructed linguistic check-points[C]//Proceedings of the 22nd International Conference on Computational Linguistics—Volume 1. Stroudsburg, PA, USA: 2008: 1121-1128.
[4] C Tillmann, S Vogel, H Ney, et al. Accelerated DP Based Search for Statistical Translation[A]. In European Conf. on Speech Communication and Technology. 1997: 2667-2670.
[5] M Snover, B Dorr, R Schwartz, et al. A Study of Translation Edit Rate with Targeted Human Annotation[C]//Proceedings of the 7th Conference of the Association for Machine Translation in the Americas. 2006: 223-231.
[6] G Leusch, N Ueffing, H Ney. CDER: Efficient MT Evaluation Using Block Movements[C]//Proceedings of EACL. 2006: 241-248.
[7] D Lopresti, A Tomkins. Block Edit Models for Approximate String Matching[J]. Theoretical Computer Science. 1997, 181: 159-179.
[8] K Papineni, S Roukos, T Ward, et al. BLEU: a Method for Automatic Evaluation of Machine Translation[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA, USA, 2002: 311-318.
[9] C Callison-Burch, M Osborne, P Koehn. Re-evaluating the Role of BLEU in Machine Translation Research[C]//Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics. 2006: 249-256.
[10] G Doddington. Automatic Evaluation of Machine Translation Quality Using N-gram Co-Occurrence Statistics[C]//Proceedings of the second international conference on Human Language Technology Research. San Francisco, CA, USA, 2002: 138-145.
[11] B Babych, A Hartley. Extending the BLEU MT Evaluation Method with Frequency Weightings[C]//Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA, USA: 2004.
[12] C Lin, F J Och. Automatic Evaluation of Machine Translation Quality Using Longest Common Subsequence and Skip-Bigram Statistics[C]//Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA, USA: 2004.
[13] D Liu, D Gildea. Stochastic Iterative Alignment for Machine Translation Evaluation[C]//Proceedings of the COLING/ACL on Main conference poster sessions. Stroudsburg, PA, USA, 2006: 539-546.
[14] Y S Chan, H T Ng. MAXSIM: A Maximum Similarity Metric for Machine Translation Evaluation[C]//Proceedings of ACL-08: HLT. Columbus, Ohio, 2008: 55-62.
[15] J Turian, L Shen, I D. Melamed. Evaluation of Machine Translation and its Evaluation[C]//Proceedings of MT Summit IX. 2003: 386-393.
[16] S Banerjee, A Lavie. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments[C]//Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Ann Arbor, Michigan: 2005: 65-72.
[17] L Zhou, C Lin, E Hovy. Re-evaluating Machine Translation Results with Paraphrase Support[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: 2006: 77-84.
[18] C Callison-Burch, C Fordyce, P Koehn, et al. (Meta-) Evaluation of Machine Translation[C]//Proceedings of the Second Workshop on Statistical Machine Translation. Prague, Czech Republic, 2007: 136-158.
[19] M Snover, N Madnani, B J Dorr, et al. Fluency, Adequacy, or HTER? Exploring Different Human Judgments with a Tunable MT Metric[C]//Proceedings of the Fourth Workshop on Statistical Machine Translation. Stroudsburg, PA, USA, 2009: 259-268.
[21] M Popovi C. Morphemes and POS tags for n-gram based evaluation metrics[C]//Proceedings of the Sixth Workshop on Statistical Machine Translation. Edinburgh, Scotland, 2011: 104-107.
[22] C Liu, D Dahlmeier, H T Ng. TESLA: Translation Evaluation of Sentences with Linear-programming-based Analysis[C]//Proceedings of the Joint 5th Workshop on Statistical Machine Translation and MetricsMATR. Uppsala, Sweden, 2010: 354-359.
[23] M Denkowski, A Lavie. Meteor 1.3: Automatic Metric for Reliable Optimization and Evaluation of Machine Translation Systems[C]//Proceedings of the Sixth Workshop on Statistical Machine Translation. Edinburgh, Scotland, 2011: 85-91.
[24] B Chen, R Kuhn. AMBER: A Modified BLEU, Enhanced Ranking Metric[C]//Proceedings of the Sixth Workshop on Statistical Machine Translation. Edinburgh, Scotland, 2011: 71-77.
[25] A Birch, M Osborne. Reordering Metrics for MT[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Portland, Oregon, USA: 2011: 1027-1035.
[26] B T Wong, C Kit. ATEC: automatic evaluation of machine translation via word choice and word order[J]. Machine Translation. 2009, 23: 141-155.
[27] S Corston-Oliver, M Gamon, C Brockett. A machine learning approach to the automatic evaluation of machine translation[C]//Proceedings of the 39th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA, USA: 2001. 148-155.
[28] C B Quirk. Training a Sentence-Level Machine Translation Confidence Metric[C]//Proceedings of LREC 2004. 2004.
[29] L Specia, D Raj, M Turchi. Machine translation evaluation versus quality estimation[J]. Machine Translation. 2010, 24(1): 39-50.
[30] G Russo-Lassner, J Lin, P Resnik. A Paraphrase-Based Approach to Machine Translation Evaluation[R].University of Maryland, College Park, 2005.
[31] J Albrecht, R Hwa. Regression for Sentence-Level MT Evaluation with Pseudo References[C]//Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics. Prague, Czech Republic: 2007: 296-303.
[32] P Koehn, C Monz. Manual and Automatic Evaluation of Machine Translation between European Languages[C]//Proceedings on the Workshop on Statistical Machine Translation. New York City: 2006: 102-121.
[33] Y Ye, M Zhou, C Lin. Sentence Level Machine Translation Evaluation as a Ranking Problem: one step aside from BLEU[C]//Proceedings of the Second Workshop on Statistical Machine Translation. Stroudsburg, PA, USA: 2007: 240-247.
[34] J Albrecht, R Hwa. A Re-examination of Machine Learning Approaches for Sentence-Level MT Evaluation[C]//Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics. Prague, Czech Republic: 2007: 880-887.
[35] K Duh. Ranking vs. Regression in Machine Translation Evaluation[C]//Proceedings of the Third Workshop on Statistical Machine Translation. Stroudsburg, PA, USA: 2008: 191-194.
[36] D Liu, D Gildea. Source-Language Features and Maximum Correlation Training for Machine Translation Evaluation[C]//Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics. Rochester, New York: 2007: 41-48.
[37] J Giménez, L Márquez. Heterogeneous Autmatic MT Evaluation Through Non-Parametric Metric Combinations[C]//Proceedings of the Third International Joint Conference on Natural Language Processing. 2008: 319-326.
[38] J Giménez, L Màrquez. Linguistic Features for Automatic Evaluation of Heterogeneous MT Systems[C]//Proceedings of the Second Workshop on Statistical Machine Translation. Stroudsburg, PA, USA: 2007: 256-264.
[39] D Liu, D Gildea. Syntactic Features for Evaluation of Machine Translation[C]//Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Ann Arbor, Michigan: 2005: 25-32.
[40] K Owczarzak, J van Genabith, A Way. Dependency-Based Automatic Evaluation for Machine Translation[C]//Proceedings of the NAACL-HLT 2007/AMTA Workshop on Syntax and Structure in Statistical Translation. Stroudsburg, PA, USA: 2007: 80-87.
[41] C Lo, D Wu. MEANT: An inexpensive, high-accuracy, semi-automatic metric for evaluating translation utility via semantic frames[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA, USA: 2011: 220-229.
[42] M Rios, W Aziz, L Specia. TINE: A Metric to Assess MT Adequacy[C]//Proceedings of the Sixth Workshop on Statistical Machine Translation. Edinburgh, Scotland: 2011: 116-122.
[43] A Kulesza, S M Shieber. A Learning Approach to Improving Sentence-Level MT Evaluation[C]//Proceedings of the 10th International Conference on Theoretical and Methodological Issues in Machine Translation. Baltimore: 2004.
[44] X Song, T Cohn. Regression and Ranking based Optimisation for Sentence Level MT Evaluation[C]//Proceedings of the Sixth Workshop on Statistical Machine Translation. Edinburgh, Scotland: 2011: 123-129.
[45] S Sun, Y Chen, J Li. A Re-examination on Features in Regression Based Approach to Automatic MT Evaluation[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies: Student Research Workshop. Stroudsburg, PA, USA: 2008: 25-30.
[46] E Avramidis, M Popovi C, D Vilar, et al. Evaluate with Confidence Estimation: Machine ranking of translation outputs using grammatical features[C]//Proceedings of the Sixth Workshop on Statistical Machine Translation. Edinburgh, Scotland: 2011: 65-70.
[47] E Amig O, J U S Gim E Nez, J Gonzalo, et al. The contribution of linguistic features to automatic machine translation evaluation[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1-Volume 1. Stroudsburg, PA, USA: 2009: 306-314.
[48] M Gamon, A Aue, M Smets. Sentence-level MT evaluation without reference translations: Beyond language modeling[A]. In 10th EAMT conference Practical applications of machine translation[C]. Budapest: 2005: 103-111.
[49] M P D V Burchardt. Evaluation without references: IBM1 scores as evaluation metrics[C]//Proceedings of the Sixth Workshop on Statistical Machine Translation. Edinburgh, Scotland: 2011: 99-103.
[50] J S Albrecht, R Hwa. The Role of Pseudo References in MT Evaluation[C]//Proceedings of the Third Workshop on Statistical Machine Translation. Stroudsburg, PA, USA: 2008: 187-190.
[51] O Hamon, D Mostefa. The Impact of Reference Quality on Automatic MT Evaluation[C]//Proceedings of the 22nd International Conference on Computational Linguistics (Coling 2008). Manchester, UK: 2008: 39-42.
[52] 刘挺,李维刚,张宇,等. 复述技术研究综述[J]. 中文信息学报. 2006, 20(04): 25-32.
[53] A Finch, Y Akiba, E Sumita. Using a Paraphraser to Improve Machine Translation Evaluation[C]//Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP). 2004.
[54] K Owczarzak, D Groves, J Van Genabith, et al. Contextual Bitext-Derived Paraphrases in Automatic MT Evaluation[C]//Proceedings of the Workshop on Statistical Machine Translation. Stroudsburg, PA, USA: 2006: 86-93.
[55] D Kauchak, R Barzilay. Paraphrasing for Automatic Evaluation[C]//Proceedings of the main conference on Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics. Stroudsburg, PA, USA: 2006: 455-462.
[56] C Callison-Burch, C Fordyce, P Koehn, et al. Further Meta-Evaluation of Machine Translation[C]//Proceedings of the Third Workshop on Statistical Machine Translation. Columbus, Ohio: 2008: 70-106.
[57] C Callison-Burch, P Koehn, C Monz, et al. Findings of the 2009 Workshop on Statistical Machine Translation[C]//Proceedings of the Fourth Workshop on Statistical Machine Translation. Athens, Greece: 2009: 1-28.
[58] C Callison-Burch, P Koehn, C Monz, et al. Findings of the 2010 Joint Workshop on Statistical Machine Translation and Metrics for Machine Translation[C]//Proceedings of the Joint Fifth Workshop on Statistical Machine Translation and MetricsMATR. Uppsala, Sweden: 2010: 17-53.
[59] C Callison-Burch, P Koehn, C Monz, et al. Findings of the 2011 Workshop on Statistical Machine Translation[C]//Proceedings of the Sixth Workshop on Statistical Machine Translation. Edinburgh, Scotland: 2011: 22-64.
[60] M Przybocki, K Peterson, S E B Bronsart, et al. The NIST 2008 Metrics for machine translation challenge—overview, methodology, metrics, and results[J]. Machine Translation. 2009, 23(2-3): 71-103.
猜你喜欢
中国神经再生研究(英文版)(2022年2期)2022-08-08
家庭影院技术(2021年2期)2021-03-29
天津外国语大学学报(2021年1期)2021-03-29
家庭影院技术(2021年1期)2021-03-19
天津外国语大学学报(2020年4期)2020-08-24
中国自行车(2018年11期)2018-12-03
小天使·二年级语数英综合(2017年12期)2017-12-05
中国自行车(2017年1期)2017-04-16
小天使·二年级语数英综合(2017年3期)2017-04-01
辞书研究(2016年5期)2016-05-14
