
基于规则的汉语名名组合的自动释义研究
2014-02-28 07:41袁毓林
中文信息学报 2014年3期
魏 雪,袁毓林
(北京大学 中文系 中国语言学研究中心 计算语言学教育部重点实验室,北京 100871)
1 引言
在汉语里,名词加名词构成的组合往往具有歧义,可能会形成不同类型的结构——主谓、定中、同位以及联合等。就定中结构的名名组合而言,其内部成分之间的语义关系十分复杂,存在着语义压缩现象,名词和名词之间常常隐藏了谓词*有的定中式名名组合甚至还隐藏了其他名词,例如,“封面女郎”(照片上了封面的女郎)等。(例如,总统[坐的]专机、 [骑/修]摩托[的]妈妈)[1-5]; 当谓词不出现时,名名之间的语义关系就不明显。
定中式名名组合在各种语言里都广泛存在,成为语言学和计算语言学的一个研究热点。研究定中式名名组合的语义解释“对信息检索、问答系统、机器翻译等诸多自然语言处理任务(都)有所帮助”[3-4]。
基于以上应用背景,我们借鉴《现代汉语语义词典》的语义分类体系、“生成词库论”中关于名词的物性角色的思想以及《知网》等资源,来探索自动发现名名组合中隐含的谓词并自动生成名名组合的释义的方法。
我们从2010年9月—2011年4月的百度新闻热搜词和前人研究文献以及一些小说、散文中搜集了一批由两个名词构成的定中式名名组合,总共得到850个组合。我们通过分析这些定中式名名组合的语义关系,来获取名名组合的语义组合关系数据库,从而为基于规则的自动发现名名组合的隐含谓词以及自动生成名名组合的释义短语提供数据基础。
2 文献综述
国外计算语言学界对英语名名组合的语义解释研究较为充分,主要有两种思路,分别是自上而下(top-down)的策略和自下而上(bottom-up)的策略。前者要求有一组已经定义好的、明确的关系集合,然后根据这个关系集合为每个名名组合分配语义关系。这基本上是一种模式识别的方法。后者是一种非受限、开放式的方法,研究者不事先规定语义关系集合,而是通过对大规模语料的研究来发现词语组合时隐含的语义关系,并通过某种模式进行释义。研究者们主要尝试用动词来解释名名组合的语义关系,寻找能够连接两个名词的“事件框架”(event frame)[6-8]。
国外还有专门为计算语义分析系统提供评测的平台SemEval(Semantic Evaluation)*具体情况请参考网页: http://aclweb.org/aclwiki/index.php?title=SemEval_Portal,http://www.aclweb.org/index.php?option=com_frontpage&Itemid=1。,旨在探索语言意义的本质。SemEval通过一系列的评测来提供一种机制,用更精确的术语来描述在语义计算中到底什么是必不可少的,指出语义计算的问题所在并为解决问题提供参考。2007年SemEval组织了一项评测“Classification of Sematic Relations between Nominals”*见http://nlp.cs.swarthmore.edu/semeval/tasks/task04/description.shtml。,旨在为判定两个名词性成分之间的语义关系的各种算法提供评估方法。2010年,Sem-Eval 举办了一项英文评测任务“Noun Compound Interpretation Using Paraphrasing Verbs and Prepositions”*见http://semeval2.fbk.eu/semeval2.php?location=tasks#T12。,旨在探索用动词和介词来解释名词复合词(noun compound)的意义这种方法的可行性。因为文献[3-4]已经做了介绍,本文不再赘述。
国内关于名名组合自动释义的研究还比较少,其中方法较为新颖的当属文献[3]。该文指出复合名词短语的语义解释的主要目的是,恢复修饰语和中心语之间隐含的语义关系。针对汉语复合名词短语的语义解释,该文首次采用动态的策略,提出了“基于动词的短语释义”的方法,利用语料库及Web数据,自动获取复合名词短语的释义短语,实验结果表明: 该方法不仅可以为复合名词短语提供多种可能的语义解释,而且能够反映相似的复合名词短语之间细微的语义差别。
文献[3]是一种自下而上地动态生成名名复合词的语义解释的方法,他们通过一些统计分析方法,在已经完成切分和词性标注的语料基础上,利用计算机自动识别复合名词短语(名名定中结构)。然后在识别名名组合的基础上,分“动词获取”、“释义短语生成”、“释义短语过滤”等步骤获得复合名词短语的语义解释。这种方法很新颖,能批量解决大量的释义问题,适用于计算机处理。但是,该文的做法,在“获得动词的方法”、“释义短语过滤取舍”等方面还存在一些问题[5],此外,该文使用的释义模板过于简单,而且按照该文的方法,得到的结果很多其实是对n1n2的扩展,并非是还原了n1n2隐含的谓词。例如,“儿童补贴”,利用该文提供的方法得到的释义短语是“儿童医疗补贴”,这仅仅是对原短语语义和形式上的扩展而非还原了原短语隐含的谓词,正确还原的释义应该是“给予儿童的补贴”。又如“爱情漩涡”,利用该文的方法得到的释义短语是“爱情陷入漩涡”、“产生爱情的漩涡”以及“陷入爱情的漩涡”,这些释义语句中的谓词都不是该短语隐含的谓词,这些释义语句仅仅是对“爱情漩涡”的扩展;该短语隐含的谓词应该是“像”,即为“爱情像漩涡”,n1和n2之间是一种比喻的关系。这可能是基于统计的方法的缺陷。
3 名名组合的语义模式分析和相应释义模板库的建立
3.1 汉语名名组合自动释义的方法与步骤 为了完成基于规则的汉语名名组合的自动释义程序的开发,我们分三个阶段来实施: (1)借鉴《现代汉语语义词典》中名词的语义分类体系,通过人工分析总结,建立名名组合的释义模板库; (2)利用《知网》,借鉴生成词库理论,在《现代汉语语义词典》的基础上,建立为获取名名组合的释义动词服务的汉语名词知识库;(3)编写名名组合的自动释义程序。
3.2 《现代汉语语义词典》关于名词语义的分类体系
《现代汉语语义词典》是北京大学计算语言学研究所研制的面向汉英机器翻译的语义词典。截至2006年,词典规模已达到6.6万余词条,不仅给出了每个词语所属的词类、语义类,而且以义项为单位详细描述了它们的配价信息和多种语义组合限制,可以为包括机器翻译在内的多种中文信息处理系统中的语义自动分析提供强有力的支持,同时,对于汉语词汇语义学和计算词典学研究也具有重要的意义。一般来说,应用语义知识应着重于解决那些仅靠语法规则难以解决的问题。该词典的语义分类就是在词的语法分类基础上进行的,并且只对名词、动词、形容词等实词进行语义分类描述。
我们主要使用《现代汉语语义词典》中的名词库。其中,名词的语义分为事物、过程、空间、时间四大类,然后再细分小类。具体的语义类分析体系,详见文献[9-12]。
该体系的名词“语义分类的深度与广度取决于语法分析的需要”[12]。正是基于这个特点,我们选择《现代汉语语义词典》的名词库作为分析的依据,并在它的基础上来构建名名组合的释义模板、发现释义动词。
3.3 生成词库论简介
生成词库论(generative lexicon theory,GLT)是由Pustejovsky[13]正式提出的,它在语言学界和自然语言处理学界都产生了很大的影响。该理论是基于计算和认知的自然语言意义模型,其基本主张是: 词汇学既要研究词语指谓什么,又要研究它如何指谓;词库并非是静态的,而是具有生成性的。该理论希望通过对词语的语义结构作多层面的详尽描写和构建数量有限的语义运作机制,来解释词义在语境中的具体实现。
生成词库论对词义的描写分为论元结构、物性结构(qualia structure)、事件结构和词汇继承结构(lexical inheritance structure)四层,这些静态的语义结构系统是为动态的语义运作系统服务的。
其中,物性结构包括四种角色: 形式角色(formal role)用于描写对象在更大的认知域内区别于其他对象的属性(包括方位、大小、形状和维度等);构成角色(constitutive role)用于描写对象与其组成部分之间的关系(包括材料、重量、部分和组成成分);功能角色*也有人翻译为“目的角色”,见袁毓林(2008a),宋作艳(2010),张秀松(2010)。(telic role)用于描写对象的用途和功能;施成角色(agentive role)用于描写对象是怎样形成或产生的(如创造、因果关系等)。词项的物性结构实际上说明了跟一个词项相关的事物、事件和关系[13-14]。
我们通过对850个汉语偏正式名名组合的考察和分析后发现,名名组合里隐含的谓词基本上是N1或N2的功能角色(telic role)或施成角色(agentive role)[15-16]。
3.4 语料的处理方法
针对收集到的这850个名名组合,我们的处理方法如下:
(1) 利用切分软件,将所有的名名组合都拆分成N1+N2。
(2) 查找所有的N1和N2在《现代汉语语义词典》中的语义类。在遇到未登录词时,由人工来判定该词的语义类。
(3) 针对每一个名名组合,由人工补充出相应的释义模板,并标明模板里动词相对于N1或N2的物性角色(施成或功能)。
(4) 所有的名名组合都对应一个N1和N2的语义类组合模式以及含有谓词的释义模板,我们对这些名词语义类组合模式和释义模板进行归并,得到一个名名搭配数据库。
通过详细的考察和归纳,我们得到了356个语义类组合模式和相应的释义模板。鉴于名名组合的类型众多,我们的模板无法保证涵盖了所有的情况。因此,我们在最后的程序中设置了由人工添加模板的操作,这样可以对名名搭配数据库进行人为补充。
3.5 名名搭配数据库的建立
我们建立的数据库名为“Noun_Noun&Noun_Verb.mdb”,其中含有三个表: Noun_Noun,Noun_Verb和dataofYuyilei。表Noun_Noun是这一节要讨论的名名搭配数据库,表Noun_Verb是下一节将着重讨论的名词知识库,表dataofYuyilei记录了名词的语义类别,具体用处我们将在第5节详述。
我们在表Noun_Noun中设置了5个字段,分别为: Noun1、Noun2、NumOfTemplate、Template、TypeOfVerb。其中Noun1用于记录名名组合中N1的语义类;Noun2用于记录名名组合中N2的语义类;NumOfTemplate用于记录该语义类组合模式下释义模板的个数;Template用于记录该语义类组合模式下的释义模板,不同的释义模板之间用西文“;”进行分隔;TypeOfVerb用于记录释义模板中出现的动词相对于有关名词的物性角色,如果动词是现成的,则该字段为空, 如果动词是N1或N2的施成角色,则该字段填入“施成角色”,如果动词是N1或N2的功能角色,则该字段填入“功能角色”,如果动词既可以是某个名词(N1或N2)的施成角色、也可以是该名词的功能角色时,该字段填入“施成角色|功能角色”,如果有多个释义模板、且不同的释义模板里的动词的物性角色不同时,则该字段下的不同角色之间用“/”分隔。至于是N1还是N2的相关角色,我们在释义模板中用“v1”“v2”表示*当释义模板中出现的是“v1”时,则表示是n1的物性角色;当释义模板中出现的是“v2”时,则表示是n2的物性角色,详见4.3节。。
在建立了表之后,我们把上文所述的语义模式和释义模板都录入至表Noun_Noun中,至此名名搭配数据库就建好了。以下是我们建立的表Noun_Noun的部分截图。

4 名词知识库的建立
在我们总结的释义模板库中,有很多释义模板都标明了隐含的谓词是n1或n2的施成角色或/和功能角色。我们利用《知网》来获取具体名词的施成角色和功能角色,并在《现代汉语语义词典》的基础上,进一步建立为获取名名组合的释义动词服务的汉语名词知识库。
4.1 《知网》的利用
我们需要用到《知网》(HowNet)系统中的知识词典。该词典是知网系统的基础文件,文件中每一个记录对应一个词语(包括词语的概念及其描述),包含五项内容,分别是编号、词语、词性、词语例子以及概念定义。知识词典是以词语及其概念为基础的,而概念的确定依赖于义原这种最基本的、不易于再分割的意义的最小单位[17-18]。
《知网》一共采用了1 500个义原,这些义原分为以下七个大类:
① 事件|Event
② 实体| Entity
③ 属性|Attribute
④ 属性值|Attribute Value
⑤ 次要特征|Secondary Feature
⑥ 符号|Sign
⑦ 动态角色与特征|Event Role and Features
我们发现,可以作为名词的功能角色和施成角色的义原多为事件类义原。
4.2 事件类义原的处理方法
我们将知网里所有“G_C=N”即词性标注为名词的记录都提取出来,命名为“HowNet_Noun.txt”文件。《知网》里事件类义原总共有805个。我们的操作步骤是:
(1) 统计每个事件类义原在文件“HowNet_Noun.txt”中出现的次数;
(2) 我们得到了129个出现次数为0的事件类义原,我们将这些义原删除掉;
(3) 对于余下的676个事件类义原,我们逐一进行分析。分析的方法如下: 首先检索该义原在文件“HowNet_Noun.txt”中的位置,找到该义原出现的名词词项;然后分析该义原是否能表示该名词的施成角色或者功能角色,如果能则给该义原做出一些标记,便于下一步的处理。举例来说,义原“LookBack|回想”在文件“HowNet_Noun.txt”中出现了1次,相应的名词是"回忆录",如下:
W_C=回忆录
DEF={text|语文:concerning={LookBack|回想:content={fact|事情:modifier={past|过去}}}}
我们可以看到,“回想”正是“回忆录”的功能角色,于是我们把义原“LookBack|回想”标记为“功能角色”。又如,“announce|发表”在文件“HowNet_Noun.txt”中出现了36次,分别对应第一位置义原是“human|人”“facilities|设施”“fact|事情”“text|语文”“information|信息”“shows|表演物”类的名词,我们各取一例列举如下:
W_C=颁布者
DEF={human|人:{announce|发表:agent={~}}}
W_C=布告牌
DEF={facilities|设施:{put|放置:LocationFin={~},patient={text|语文:{announce|发表:instrument={~}}}}}
W_C=发布会
DEF={fact|事情:CoEvent={announce|发表:content={news|新闻}}}
W_C=告示
DEF={text|语文:{announce|发表:instrument={~}}}
W_C=预告
DEF={information|信息:{announce|发表:content={~},manner={early|早}}}
W_C=预告片
DEF={shows|表演物:{announce|发表:content={~},manner={early|早}}}
通过考察,我们发现“发表”可以作为这些名词的功能角色,于是我们把义原“announce|发表”标记为“功能角色”。
通过这样逐一考察,我们发现: 部分事件类义原可以作为一些名词的功能角色,我们把它们标记为“功能角色”;部分事件类义原可以作为一些名词的施成角色,我们把它们标记为“施成角色”;部分事件类义原既可以作为一些名词的施成角色、也可以作为另一些名词的功能角色,我们把它们标记为“施成角色|功能角色”。还有一些义原既不能做名词的功能角色、也不能做名词的施成角色,我们把这些义原删除掉。例如,“fixed|已定”,它在文件“HowNet_Noun.txt”中只出现了1次:
W_C=成法
DEF={law|律法:modifier={PropertyValue|特性值:manner={fixed|已定}}}
我们看到“已定”既非“成法”的施成角色、也非它的功能角色,只是它的一个特征而已。因此,我们把义原“fixed|已定”删除。最后,我们得到358个能够充当名词的施成角色和/或功能角色的事件类义原,其中绝大多数义原都是做功能角色的。这些义原构成一个集合,我们称之为R1,它能够帮助我们建立名词知识库。
当然,我们对这些义原能否充当名词的施成角色和/或功能角色的判断,有一部分不一定准确。这在以后生成名名组合的释义的程序中,还可以进一步校对和更正。
4.3 名词知识库的构建
我们给表Noun_Verb设置了9个字段,分别为: Noun,用于记录名词词条;POS,用于记录名词的词类;PinYin,用于记录名词的拼音;Semantic,用于记录名词的释义;SemanticCategory,用于记录名词的语义类;TelicRole,用于记录名词的功能角色;AgentiveRole,用于记录名词的施成角色;IsContentNounORNot,用于记录该名词是否是内容义名词,如果是就标注为“1”,如果不是则缺省(default)。
由于《现代汉语语义词典》跟《知网》收录的词项不同,因而,我们的数据库Noun_Verb只收录了两者共有的词项。这些词项的Noun、POS、PinYin、Semantic以及SemanticCategory这五个字段的内容,直接从《现代汉语语义词典》继承过来,如果一个名词有多个读音(多音词)或多个义项(多义词),我们就将这些多音词和多义词都合并到一个词项中,多个读音、义项以及语义类之间用“|”进行分隔。TelicRole和AgentiveRole字段的内容的获取方法如下: 如果名词的DEF里含有的事件类义原属于集合R1,我们就将其摘取出来。 a. 如果该义原在集合R1中被标记为“施成角色”,我们就将该义原放在该名词的字段AgentiveRole下;b. 如果该义原在集合R1中被标记为“功能角色”,我们就将该义原放在该名词的字段TelicRole下;c. 如果该义原在集合R1中被标记为“施成角色|功能角色”,我们就将该义原同时放在该名词的字段TelicRole和AgentiveRole之下。我们对集合R1里的义原进行了改写。因为,《知网》里义原的书写形式是“英文|中文”,例如,“ally|结盟”,其中英文部分是我们不需要的;所以我们在写入数据库时,将这些义原的英文部分和符号“|”都去掉了。另外,有些义原名称不太自然,我们在写入时将其改写成更为通行的表达。如“cognition|感知状态”,我们在写入时直接改写为“感知”;“sign|题写”,我们在写入时直接改写为“写”。
《知网》将实体分成万物、时间、空间、部分四类,我们考察的名词的第一位置的义原都属于这四类,第一位置的义原能够体现这些名词所代表的概念的上下位关系。通过考察,我们发现,在《知网》对实体概念的分类中,部分类的实体具有相同的施成角色和功能角色。例如,表示“disease|疾病”类概念的名词的施成角色都可以概括为“罹患”,功能角色都可以概括为“治疗”;表示“vehicle|交通工具”类概念的名词的施成角色都可以概括为“造”,功能角色都可以概括为“运送”;表示“food|食品”类概念的名词的施成角色都可以概括为“制作”,功能角色都可以概括为“吃、买、卖”等。通过考察,我们得到了60类实体的施成角色和/或功能角色。我们把这些实体类义原构成的集合称为R2。我们获取数据库Noun_Verb中TelicRole和AgentiveRole字段内容的另一个方法是: 如果名词DEF中第一位置的义原属于集合R2,我们就将跟该义原相应的施成角色写入字段AgentiveRole下,将跟该义原相应的功能角色写入字段TelicRole下。通过这两种方法,我们可以获得大部分名词的施成角色和/或功能角色了。对于一些仍然无法获得施成角色和/或功能角色的名词,我们通过人工添加来完善它们的物性角色信息。
在考察第一位置义原是实体类义原的名词时,我们还发现: 如果该义原是“information|信息”、“news|新闻”、“text|语文”、“knowledge|知识”、“regulation|规矩”、“system|制度”、“law|律法”、“agreement|条约”、“plans|规划”、“problem|问题”、“account|簿册”之一时,那么该名词就是内容义名词。据此,我们可以将相应的名词的IsContentNounORNot字段标注为1。此外,当名词的语义类是“创作物”、“信息”、“法规”、“事件”等时,该名词也是内容义名词。相应地,它们的IsContentNounORNot字段也标注为1。
通过以上方法,我们用程序建立起了名词知识库Noun_Verb。以下是该数据库的部分截图。

5 名名组合自动释义程序的设计和实现
汉语名名组合自动释义程序包括五个功能模块和相应的运算步骤:
1. 对于输入的名名组合首先进行切分、标注词性操作,得到词串N1+N2,确定其为名名组合;
2. 分别查询N1和N2在表Noun_Verb中的语义类S1和S2;
3. 在表Noun_Noun中查找语义类组合模式为S1+S2的释义模板;
4. 根据释义模板的要求查找相关名词的相关动词及其物性角色;
5. 将动词、N1、N2插入至释义模板中,生成释义短语。
下面是“农民专家”的自动释义过程:
第一步,经过切分和标注词性,得到词串“农民/n 专家/n”。第二步,程序在Noun_Verb中查到“农民”的语义类是“身份”、“专家”的语义类也是“身份”。第三步,程序在Noun_Noun表中查到“身份+身份”这一语义类组合模式下的释义模板有两个: (1)“身份+是+n1+的+n2”;(2)“v2+n1+的+n2”,其中v2是n2的功能角色。第四步,程序在Noun_Verb中查到“专家”的功能角色是“研究”。第五步,程序将v2、n1、n2都插入到释义模板中,分别生成两个足以消解歧义的释义短语: (1)“身份是农民的专家”,(2)“研究农民的专家”,程序结束。
图1是自动生成汉语名名组合的释义短语的算法流程图。
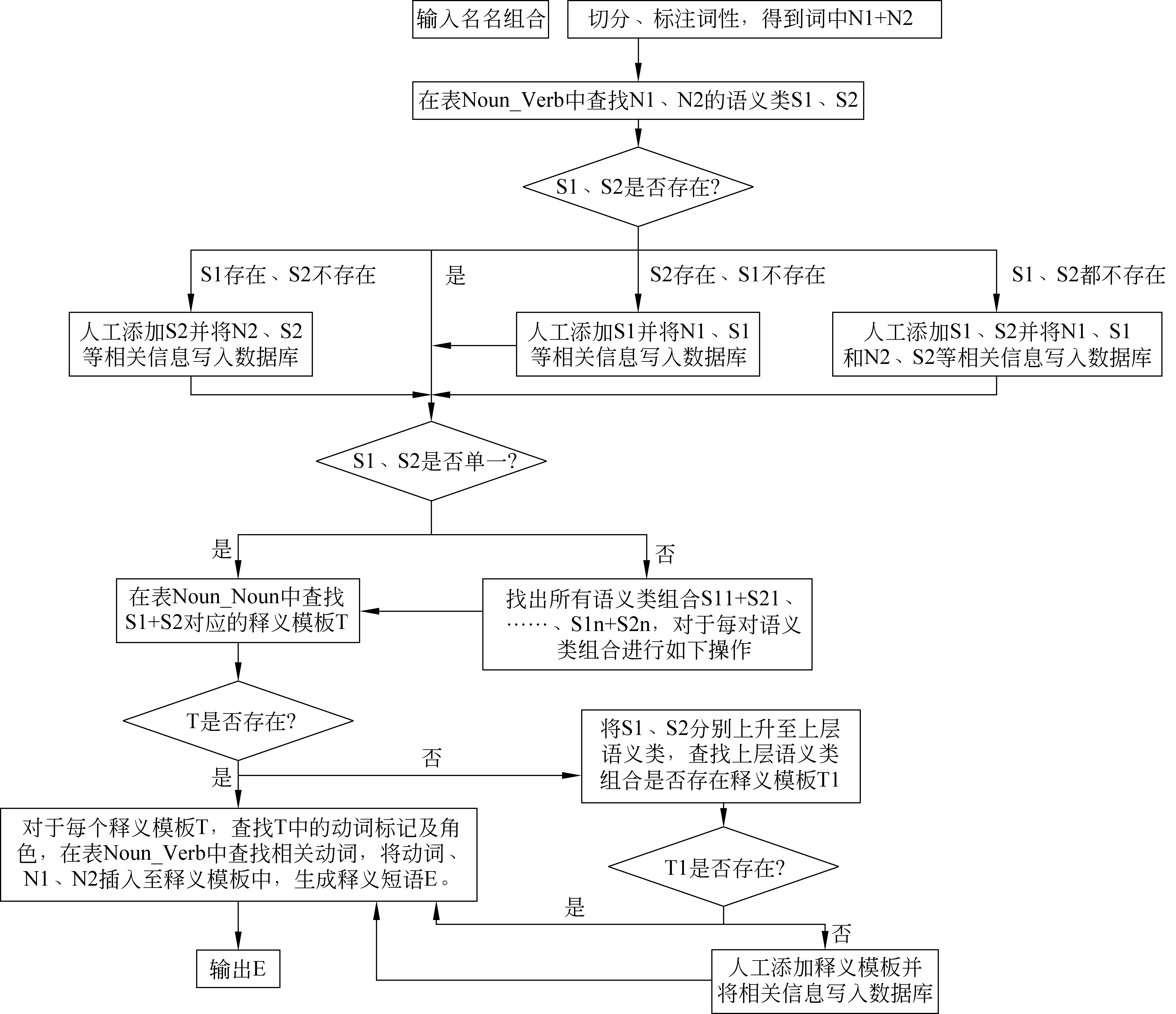
图1 自动生成汉语名名组合的释义短语的算法流程图
我们使用Java语言来开发汉语名名组合的自动释义程序。上文所说的五个步骤都体现在上图中了。
我们在第4节指出,在数据库Noun_Noun&Noun_Verb.mdb中还有一个记录了名词的语义分类层级的表dataofYuyilei。当我们在表Noun_Noun中找不到某个语义类组合模式S1+S2及其释义模板时,我们的操作是: 首先将S1、S2分别上升(或回撤,back-off)至其上层语义类,然后检索其上层语义类构成的语义模式是否存在于表Noun_Noun中;如果存在,则直接生成释义短语;如果不存在,则由人工添加释义模板。
在汉语名名组合自动释义程序中,由人工参与操作的步骤有如下三种: (1)当数据库Noun_Verb没有收录我们输入的名名组合中的N1或N2时,需要由人来写入该名词的语义类、施成角色、功能角色等相关信息; (2)当数据库Noun_Noun没有收录某个语义类组合模式及其释义模板、并且该语义类组合模式上升(或回撤)至其上层语义类组合模式后仍无合适的释义模板时,需要由人来写入该语义模式下的释义模板*我们在总结语义类组合模式时,一个语义类组合模式最多对应三个释义模板,因此我们设计的添加释义模板的操作界面上有三个可以输入释义模板的文本框,用户可以根据实际情况填写1~3个释义模板。; (3)当数据库Noun_Verb没有收录释义模板中要求的N1或N2的相关动词及其物性角色时,需要由人来写入N1或N2的相关动词及其物性角色。通过人工参与,我们能够进一步完善数据库Noun_Noun和Noun_Verb。
6 实验数据及结果分析
为了检验汉语名名组合自动释义程序的有效性,我们从2011年5月—9月的百度新闻热搜词中选出了245个由两个名词构成的名名组合作为测试数据来检验程序对名名组合自动释义的结果。
我们把245个待测名名组合输入到汉语名名组合自动释义系统中,经过系统运算,结果有128个名名组合得到了释义短语。召回率为(128/245=)52.24%。造成117个名名组合没有得到释义的原因有以下五点:
(1) 切分结果不正确。例如,“北京新地王”,我们希望得到的切分结果是“北京/ns*ns表示“处所词”。新地王/n”,但程序得到的是“北京/ns 新/a 地/n 王/nr”。因为“地王”是一个网络新词,切分程序无法正确识别。由于切分不正确造成无法释义的名名组合有76个。
(2) 词性标注不正确。例如,“高考分数线”,切分程序得到的词串结果是“高考/v 分数线/n”,程序把“高考”的词性标注成了动词(v)而非名词(n)。由于词性标注错误造成无法释义的名名组合有1个。
(3) 切分程序不能识别人名、地名等命名实体或者简称,因此无法获得准确的词串N1+N2。例如,“伊利举报门”、“美债危机”、“拉登日记”,程序目前无法识别“举报门”这样的派生词、“美债”这样的简称、“拉登”这样的人名。由于这种原因造成无法释义的名名组合有12个。
(4) 数据库Noun_Verb里没有收录待测名名组合中N1或者N2的信息,程序无法识别N1或者N2的语义类。例如,“宝马副教授”,它的切分和词性标注结果是“宝马/n 副教授/n”,但是数据库Noun_Verb里没有“宝马”这个词的相关信息,因此无法判别“宝马”的语义类,进而无法得到该名名组合的语义类组合模式。由于这种原因造成无法释义的名名组合有17个。
(5) 数据库Noun_Noun里没有收录待测名名组合的语义类组合模式,程序无法获得该模式下的释义模板。例如,“天价拖车费”,其语义类组合模式是“量化属性+钱财”,但是数据库Noun_Noun里没有这种模式,因此无法获得释义短语。由于这种原因造成无法释义的名名组合有11个。
可见,(1)—(3)三种情况是由切分程序造成的,占不能召回个例的(89/117=)76.07%。(4)—(5)两种情况是由释义程序造成的,占不能召回个例的(28/117=)23.93%。对于后两种不能召回释义短语的名名组合,我们通过人工操作,将缺失的名词及相关信息都录入到数据库中。这样,释义系统便可以生成这28个名名组合的释义短语了。
对于召回释义短语的(128+28=)156个名名组合,我们将它们及其释义短语交给3个标注者*都是北京大学中文系研究生,均长期生活在北方方言区。,让他们对释义短语进行二元判断: 释义短语是否能用来解释相应的名名组合。对每个释义短语,如果有两个或以上的标注者认为正确,则判定为正确。结果准确率为(147/156=)94.23%[5]。造成9个名名组合释义错误的原因有以下五点:
(1) 名名组合中名词的词义发生转喻。例如,“火箭新主帅”,数据库Noun_Verb里“火箭”的语义类是“武器”,在该语义类下生成的释义短语是“发射火箭的新主帅”;但是“火箭”在这里是指NBA篮球队的名称,正确的释义短语是“领导/指挥火箭的新主帅”。 由这种原因造成的释义错误有1个。
(2) 数据库Noun_Verb里收录的部分名词的功能角色或施成角色不正确。例如,“球队球迷”*原来的测试短语是“米兰球迷”,但是程序无法将“米兰”识别为球队,只能将其识别为处所。因此,我们使用“球队球迷”来代替“米兰球迷”。,该短语对应的语义类组合模式是“团体+身份”,相应的释义模板是“v2+n1+的+n2”(其中v2是n2的功能角色)。但是程序生成的释义短语是“比赛球队的球迷”,显然不正确*正确的释义短语是“喜欢/迷恋球队的球迷”。。原因是数据库中存的“球迷”的功能角色是“比赛”,实际上。应该是“喜欢、迷恋”。由这种原因造成的释义错误有2个。
(3) 待测名名组合表示比喻关系,这超出了我们目前的研究范围。例如,“粉末砖头、阶梯电价”,其意义是“像粉末一样易碎的砖头、像阶梯一样有层次的电价”。其中N1和N2是“喻体+本体”的关系。由这种原因造成的释义错误有3个。
(4) 数据库里没有收录待测名名组合的语义组合模式,程序通过回溯找到n1或n2的上层语义类构成的语义模式,但相应的释义模板并不准确。例如,“电力缺口”,语义模式“物性+抽象事物”,回溯至上层语义模式是“模糊属性+抽象事物”,释义模板是“拥有+n1+的+n2”,用于解释“电力缺口”并不准确。由这种原因造成的释义错误有1个。
(5) 释义模板归纳不完善。例如,“城市排行榜”,语义模式是“处所+人工物”,对应的释义模板“来自+n1+的+n2”,该模板的原型是“大陆产品”、“外国资本”。该原因造成的释义错误有2个。
7 汉语名名组合自动释义程序的改进
我们开发的汉语名名组合自动释义程序还有一些地方需要进一步改进。主要有以下三个方面:
1. 《知网》中值得我们进一步挖掘的信息还有很多,至少有两方面能够用以完善我们的自动释义程序: (1)《知网》的知识词典在收词的时候,不仅收录了词,还收录了一些短语。在这些短语的概念定义中,有些信息能够帮助我们寻找相关名词的功能角色或施成角色。(2)《知网》里还有一类义原叫动态角色义原,它是对跟动作相关的实体或者对跟实体相关的动作有关的实体的一种概括,它通常还有下一级的结构,在《知网》里用“={}”的形式来表示,大括号里的内容就是跟该动作相关的具体角色。有效地利用动态角色以及它的下一级结构能够帮助我们完善名名搭配数据库里的释义模板,使得名名组合的释义短语更加准确,从而提高名名组合自动释义程序的准确率。我们要进一步研究如何挖掘和有效地利用这些信息。
2. 目前我们总结的释义模板并不完善,获得的名词的施成角色和功能角色也不完善。今后,我们将通过搜集更多类型的名名组合、不断归纳,来进一步完善名名搭配数据库和名词知识库,从而让我们的程序能够用于更多的情况、更好地生成名名组合的释义短语。
3. 我们将进一步扩展程序,让它不仅能够解释由两个名词构成的名名组合,还能解释由三个及多个名词构成的名名组合。
8 结语
名名组合在现代汉语以及网络搜索词中十分常见,研究名名组合的自动释义对信息检索、机器翻译等自然语言处理任务都有所帮助。本文在前人研究的基础上,提出了一种自上而下与自下而上相结合的方法,设计并实现了自动生成由两个名词构成的名名组合的释义短语的程序。
本文主要的贡献在于引进了名词的物性角色这种结构化的语言学知识,来求解名名组合中所隐含的释义动词。名词的物性结构是对于名词所指的事物及其动作、行为、与其他事物的关系等百科知识的结构化表示。这种语义知识对于语句的语义解释和内容计算具有具有重要的作用[19]。这种语义处理方法可以推广到对“鲁迅[写作/拥有]的书”一类歧义结构的处理,从而为缺省动词的名词性短语的语义解释和歧义消解提供新的技术路线。同时,这种自动释义系统也可以反过来帮助我们收集和发现名词的物性角色;而名词的物性角色又可以跟动词、形容词的论元结构等语义知识关联起来,从而形成比较全面的名词-动词-形容词互相关联的语义知识资源。这种基于语言学规则和结构化的百科知识的自然语言处理方法,在一定程度上响应了近年来国际自然语言处理学界的一项呼吁: 让语言学重新回到计算语言学中,并且成为自然语言处理的支撑性学科(call for the return of linguistics to computational linguistics)[20]。
本文的研究成果跟文献[3]相比,有以下三个特点: (1)释义模板更为丰富。文献[3]只使用了4个释义模板,而本文归纳得出了117个释义模板;(2)释义短语更为自然;(3)多种方法的有机结合。文献[3]的研究方法是一种基于统计的、自下而上的方法,而本文对名名组合进行自动释义的方法则是一种基于规则的、自上而下与自下而上相结合的方法。其中,自上而下体现在: 我们事先总结出了一套语义类组合模式及其相应的释义模板、建立了名名搭配数据库Noun_Noun;对于待释义的名名组合N1+N2,我们的程序首先判定它对应哪种语义类组合模式,这是一种归类。自下而上体现在: 在我们总结出的很多释义模板中,我们只标注了模板中的动词是哪个名词的哪个角色,并未给出具体的释义动词;具体的动词要结合具体的N1、N2来获得(依赖于名词知识库Noun_Verb),因此,动词的获得具动态性。
跟文献[3]的研究相比,本文的研究也存在明显的不足: 第一,我们的研究成果在很大程度上依赖于人工建构的释义模板和相关的知识库,操作的步骤比较多,没有文献[3]的系统智能。我们希望以后能够通过机器学习等方法来自动获取我们需要的资源,提高程序的智能性;第二,我们归纳的释义模板、名词的施成角色和功能角色还不够完善,还需要在使用过程中不断扩充和改进,以期得到更好的释义短语。
最后,我们希望进一步改进名名组合的自动释义程序,使它能更好地为搜索引擎、机器翻译等自然语言处理任务服务。同时,也希望我们建造的名名搭配数据库Noun_Noun和名词知识库Noun_Verb能在其他自然语言处理任务中发挥一定的作用,为自然语言处理作出一点微薄的贡献。
[1] 袁毓林. 谓词隐含及其句法后果——“的”字结构的称代规则和“的”的语法、语义功能[J]. 中国语文,1995,4: 241-255.
[2] 谭景春. 名名偏正结构的语义关系及其在词典释义中的作用[J]. 中国语文,2010,4: 342-355.
[3] 王萌,黄居仁,俞士汶等. 基于动词的汉语复合名词短语释义研究[J]. 中文信息学报,2010,24(6): 3-9.
[4] 王萌. 面向概率型词汇知识库建设的名词语言知识获取[D]. 北京: 北京大学,2010.
[5] 魏雪. 面向语义搜索的汉语名名组合的自动释义研究[D]. 北京: 北京大学,2012.
[6] Nakov Preslav. Noun compound interpretation using paraphrasing verbs: Feasibility study [C]//Proceedings of the 13th International Conference on Artificial Intelligence: Methodology, Systems and Applications (AIMSA 2008), Springer. 2008: 103-117.
[7] Nakov Preslav, Marti A Hearst. Using verbs to characterize noun-noun relations [C]//Proceedings of the 12th International Conference on Artificial Intelligence: Methodology, Systems and Applications (AIMSA 2006), Springer. 2006: 233-244.
[8] Ryder M E. Ordered Chaos: The Interpretation of English Noun-Noun Compounds [M]. Berkeley, California: University of California Press.
[9] 王惠. 现代汉语名词词义组合分析[M]. 北京:北京大学出版社,2004.
[10] 王惠,詹卫东,俞士汶. 现代汉语语义词典规格说明书[J]. Journal of Chinese Language and Computing, 2003, 13 (2): 159-176.
[11] 王惠,詹卫东,俞士汶. 《现代汉语语义词典》的结构及应用[J]. 语言文字应用,2006,1: 134-141.
[12] 王惠,詹卫东,俞士汶. 现代汉语语义词典(SKCC)的新进展[C]. 孙茂松,陈群秀. 语言计算与基于内容的文本处理. 北京: 清华大学出版社,2003: 351-356.
[13] Pustejovsky James. The Generative Lexicon [M]. Cambridge, Massachusetts: The MIT Press, 1995.
[14] 张秀松,张爱玲. 生成词库论简介[J]. 当代语言学,2009,3: 267-271.
[15] 宋作艳. 现代汉语中的事件强迫现象研究——基于生成词库理论[D].北京: 北京大学,2009.
[16] 宋作艳. 类词缀与事件强迫[J]. 世界汉语教学,2010,4: 446-458.
[17] 董振东. 语义关系的表达和知识系统的建造[J]. 语言文字应用,1998,3: 79-85.
[18] 董振东,董强.知网和汉语研究[J]. 当代语言学,2001,1: 33-44.
[19] 袁毓林. 汉语名词物性结构的描写体系和运用案例[J]. 当代语言学,2014,1:31-48.
[20] Wintner Shuly. What Science Underlies Natural Language Engineering [J]. Computational Linguistics, 2009,35(4): 641-644.
猜你喜欢
建材发展导向(2022年23期)2022-12-22
建材发展导向(2022年20期)2022-11-03
北京航空航天大学学报(2022年8期)2022-08-31
建材发展导向(2022年12期)2022-08-19
开放教育研究(2020年2期)2020-03-31
中国修辞(2017年0期)2017-01-31
长江学术(2016年4期)2016-03-11
海峡姐妹(2016年2期)2016-02-27
中国卫生(2015年9期)2015-11-10
