
藏文构件元素识别算法研究
2014-02-28 07:41边巴旺堆陈延利
中文信息学报 2014年3期
边巴旺堆,卓 嘎,陈延利, 武 强
(西藏大学 工学院,西藏 拉萨 850000)
一、前言
现代藏文是由30个辅音字母和4个元音字母拼写组合而成的一种拼音文字,同时,它又是在横向上具有线性结构、纵向上具有叠加结构的一种复杂文字。除了现代藏文外,在藏文文档中通常还能见到许多梵音转写体和反转体藏文字,而这些文字在藏文中具有不可替代的功能和作用,因此,它们也是藏文文字的一部分。在研究藏文文字排序、文字识别、信息检索和文件检索等相关课题时,不仅要考虑常用的30个辅音字符和4个元音字符,还要考虑5个反转体、6个梵音转写体以及9个梵文元音。这样,藏文就有41个基字和13个元音字符。
但是,梵音转写藏文字由常见的某两个或几个字符叠加而成,因此,在算法设计过程中会有两种选择,一种是把所有藏文文档中可能出现的文字全部作为一个基字,使基字的数量变为43个;另一种是只把30个常见字符和5个反转体共35个作为基字。为了能够从现代藏文文本和梵音转写藏文文档中快速识别基字,本文将梵音转写字体和反转体一起作为基字来处理。
二、 藏文文字结构及其构件元素
藏文按照其书写顺序由前加字(前缀)、上加字、基字 、下加字、元音、后加字(后缀)和再后加字7种构件元素(部件)组成,如图1所示,每一种构件元素都有它不可替代的作用和功能。

图1 藏文结构及构件元素
在藏文的7种构件元素中,除了基字外其他构件元素可有可无,构件元素中只有基字的藏文音节称之为独体字,而一个藏文音节中除了基字外还有其他构件元素,则称之为复合字。根据复合字的构字情况来看,复合字又由前加字、上加字、下加字、元音、后加字和再后加字几个部分组成。在这些构件元素中上加字和下加字分别处在基字的上面和基字的下面,因此,从基字位看,纵向上有上加字、基字、下加字和元音。
三、 识别藏文构件元素算法

(1) 前加字作前缀的语法规则(语法规则1)

图2 语法规则1
根据语法规则1,我们能够清晰地看到5个前加字作前缀时,每个前加字能够作前缀的基字不尽相同,如图2所示。图2 的语法规则1通过表1进行说明。

表1 前加字与能作前缀的基字及说明表
(2) 上加字作上置辅音的语法规则(语法规则2)

图3 语法规则2
3个上加字作上置辅音的基字不尽相同,如图3所示。对于上置辅音变形为时,只能作基字的上加字,而不变形时,就作的上加字;对于上置辅音,则只能作基字的上加字;对于上置辅音,也只能作基字的上加字。
(3) 下加字作下置辅音的语法规则(语法规则3)

图4 语法规则3[1]

(4) 标识符的语法规则(语法规则3-1)

图5 标识符语法规则3-1[1]
藏文中标识符分为两种,一种是为了区别和标识藏文基字和特定意思的一种符号,用
表示,而另一种标识符就是为了表示某一种音节的读音加长的符号,即
。第一种标识符的语法规则是该标识符能与图5中的藏文字符组合后形成特定意思的音节,而第二种标识符就几乎与所有的基字组合后使该音节的读音加长。用表2表示该语法规则。

表2 标识符的语法规则表
(5) 后加字作后缀的语法规则(语法规则4):
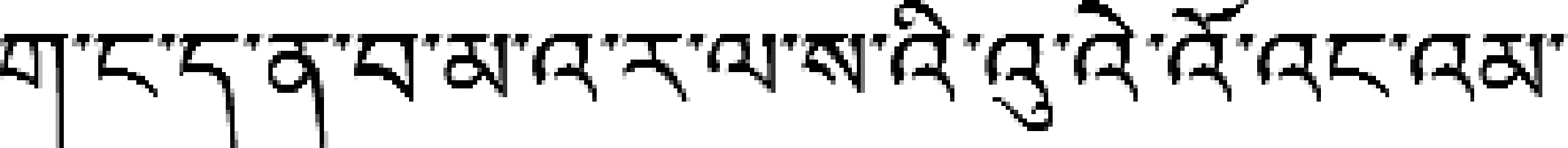
图6 语法规则4
藏文的后加字是指允许在基字后面添加的字符。 需要强调的是这里的基字分为两种形式,即独体基字和叠加基字。第二种基字有时与上加字组合,有时与下加字组合,有时与上下加字一起组合成组合体,此时,后加字就是允许在该组合体后面添加的10个字符,这10个字符分别是图6中的前10个字符。 严格来讲,由于现代藏文只有10个后加字,但是由于现代藏文中音节缩写的需要,本来独立的两个音节缩成一个音节后形成双元音音节(特殊音节处理时详述)。这里所说的后加字与藏文文法书中的内容不同,如图6所示。
(6) 再后加字作再后缀的语法规则(语法规则5):

图7 语法规则5[1]

表3 再后加字的语法规则及说明
(7) 上加字、基字和下加字三个构件元素组成纵向叠加字符的语法规则(语法规则6):

图8 语法规则6[1]
在现代藏文中能够叠加在一起的构件元素最多只有3个,且这些构件元素之间的组合方式成为了固定模式,如图8所示。当上加字为
且基字为
时,由下加字
再与前两者进行叠加,形成固定模式;同理,当上加字为
且基字为
时,下加字
和
分别与前两个字符进行叠加形成固定模式
[2]
。
2. 判断基字所在位置*边巴旺堆.基于ISO/IEC10646藏文编码字符集标准的藏文排序算法设计与实现[N] . 中国优秀硕士学位论文全文数据库:西藏大学,2009.
在现代藏文字符中,基字一般在第一位、第二位和第三位上,因此首先判断输入进来的音节是否为现代藏文,若是,则判断基字是否在上述三种位置上,否则按梵音转写藏文字来处理该音节[3]。
识别基字,即找到单个音节所有字符中哪个字符是基字,其识别规则为:
A. 藏文输入顺序为:前加字、上加字、基字、下加字、元音、后加字、再后加字,且符合藏文文字结构的所有语法规则。这样基字的位置应该处于1、2、3的位置*林河水,程伟等. 一种符合 ISO 14651语义的藏文排序实现方法[J] . 中文信息学报,2004,18(5):36-41.。
B. 当藏文字字符数量为1时,则该字符为基字,如果字符编码非43个基字对应的编码,则不予处理。
C. 当藏文构件元素数量为2时,识别规则为:
如果满足语法规则2或3,则输出上置辅音或下置辅音及基字,否则,看该音节中有没有元音,且是否满足元音字符总在一个独体字或叠加字后面的规则,若满足,则输出基字与元音,否则就是基字和后加字。
D. 当藏文构件元素数量为3时,其识别规则为:
有前加字且满足语法规则1,且该音节的第二和第三个构件元素满足语法规则2,则分别输出前加字、上加字和基字;否则看该音节的第二和第三个构件元素之间是否满足语法规则3,若满足,则分别输出前加字、基字和下加字;否则,第一个构件元素为基字,而基字后面的构件元素用识别其他构件元素模块来处理和识别。
E. 当藏文构件元素数量多于3时,其识别规则与构件元素数量正好等于3的完全相同,只是识别基字后面构件元素不同罢了。
3. 特殊音节的处理*
(1) 解决特殊构件元素及其二义性
当在一个藏文音节中只有三个构件元素,且没有叠加字符和元音符号时,这个音节可能存在二义性,如图9所示,该音节有两种读音,且都符合语法规则(暂时不管该音节存不存在实际意义)。此时,我们通过再后加字的语法规则5来处理就能解决该问题。

图9 特殊音节处理(a)
(2) 双元音处理方法
若在藏文文档中前一个音节与后一个音节能够满足缩写语法规则10,则就会去掉两个音节当中的音节符,使这两个音节变为一个音节,就构成了双元音音节。此时,如何识别该音节中的基字及其构件元素呢?
考虑是否满足前加字的语法规1,若满足,则接着看是否满足上加字的语法规则2、下加字的语法规则3和后加字的语法规则4,若满足,且该音节中存在两个元音字符,则用后一个元音与其前一个构件元素一起构成特殊后加字,即用后加字来处理双元音问题;若不满足,则第一个为基字,后一个为后加字。如图10和图11所示。

图10 特殊音节处理(b)图11 特殊音节处理(c)
(3) 梵音转写藏文字体处理
由于算法的通用性要求,将梵音转写藏文字符不再进行拆解,而是让这些字符看作基字,使基字数量变成43个。
(4) 缩写字体的转换处理(语法规则10)

图12 语法规则10


图13 特殊音节处理(d)
(5) 一个补充词语的处理方法

4. 识别基字算法流程图
(见下页图14)
5. 识别基字后面的构件元素算法流程图
(见下页图15)
由于基字后面最多只能有4种构件元素(标识符除外),且结合这4种构件元素可有可无的实际情况,利用相关语法规则,就得到图15所示的识别构件元素算法及流程图。
通过上述两个算法,能够从藏文文本的一个音节中正确识别各个构件元素,从而实现排序、信息检索和文件检索等事项的顺利进行。当然对于藏文排序而言,还需要做许多相关处理,例如,各种优先级算法设计和排序算法本身。
四、 测试
用809个常用且具有代表性的藏文词语对此算法进行测试,结果如表4所示,这809个词语中只要是符合藏文语法规则的都能正常识别,其识别效率达到99%以上。
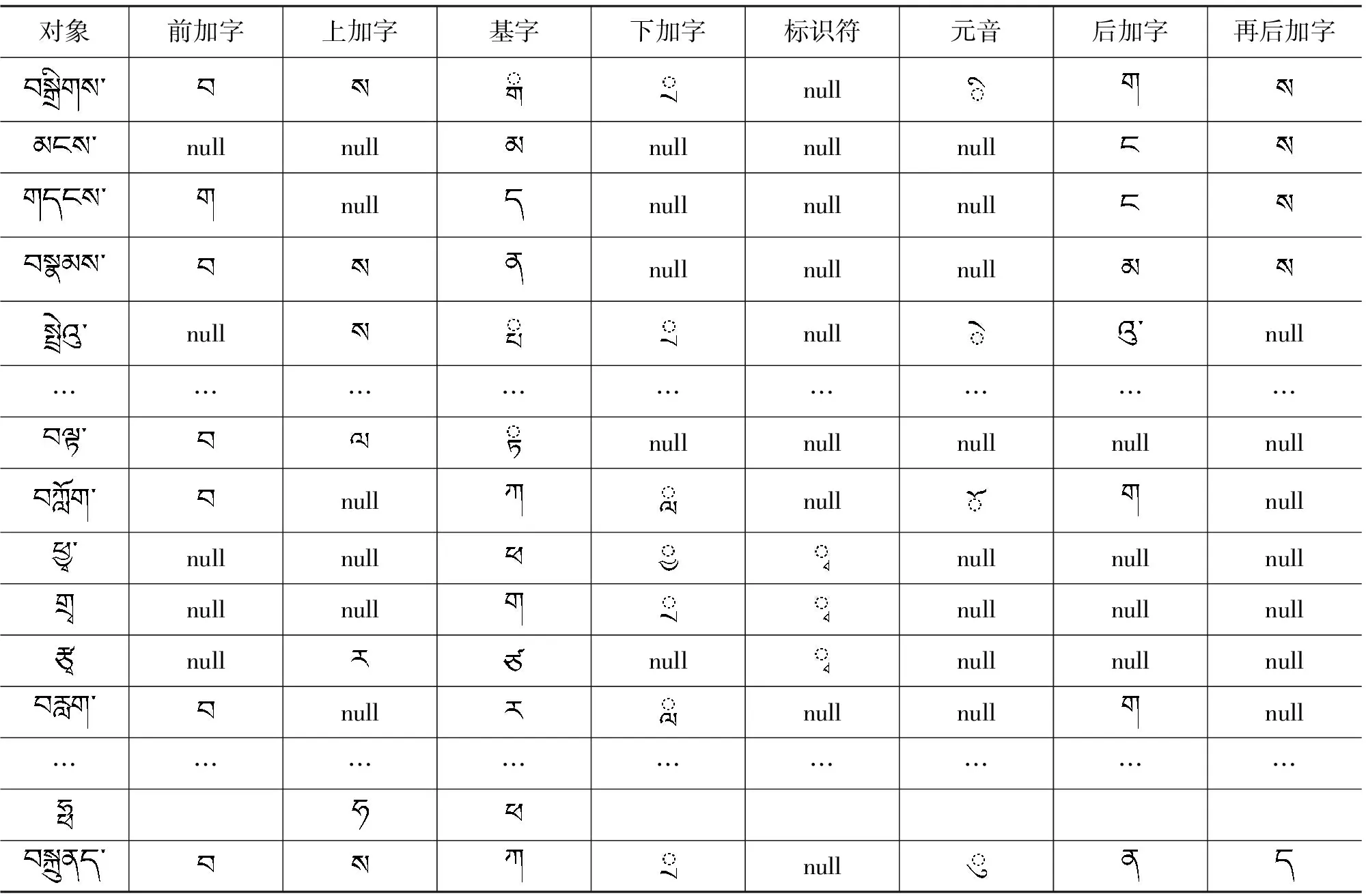
表4 测试对象及测试结果表

图14 识别基字算法流程图

图15 识别其他构件元素算法流程图
用扩A 中的1 536个藏文字符进行测试,该类字符中不包括前加字、后加字和再后加字,而是在基字位上将上加字、基字、下加字、标识符和元音字符或多或少地叠加起来的字符组成的,经测试发现,凡是有现代藏文常用四个元音的音节都能正常识别,但是有梵音转写藏文元音的音节却无法识别。主要原因是算法设计时只考虑了现代藏文的元音,并没有考虑梵音转写的藏文元音字符,也就是说在元音字符的集合中并没有包含梵音转写的藏文元音字符,所以出现不能识别情况。将这些元音添加到相应集合中就能实现识别梵音转写藏文元音字符的目的。
五、 结束语
本文主要研究了如何从藏文的一个音节中识别藏文的各个构件元素,并设计了识别藏文构件元素的算法。测试结果证明该算法能够满足实际需求。但是由于藏文是一种复杂文字,其结构受各种语法规则限制,且在计算机中处理该文字时受输入、输出、编辑等相关问题的制约,与此同时现代藏文中又出现了许多特殊字符,增加了算法设计的难度,影响算法的精确度。虽然本文中考虑了许多特殊情况,但是由于研究团队经验不足,难免漏掉部分特殊情况,望各位读者提出批评指正。下一步为了能够实现藏文词语按照词典规则进行排序,将主要研究各种优先级算法设计,并通过设计藏文的结构优先级、构件优先级和字符优先级,实现藏文词语的升序和降序。

[2] 黄鹤鸣,契嘎·德熙嘉措 (赵晨星). 基于DUCET的藏文排序方法[J] .中文信息学报, 2008,22(4):109-113.
[3] 王维兰,丁晓青,祁坤钰. 藏文识别中相似字丁的区分研究[J]. 中文信息学报,2002,16(4):60-65.
[6] 边巴旺堆.基于ISO/IEC10646藏文编码字符集标准的藏文排序算法设计与实现[N] . 中国优秀硕士学位论文全文数据库:西藏大学,2009.
[7] 林河水,程伟等. 一种符合ISO14651语义的藏文排序实现方法[J] . 中文信息学报,2004,18(5):36-41.
[8] 扎西次仁.藏文的排序规则及其计算机自动排序的实现[J] .中国藏学,1999,(5):128-135.
猜你喜欢
考试与评价·七年级版(2021年1期)2021-08-14
西藏研究(2021年1期)2021-06-09
考试与评价·七年级版(2020年1期)2020-10-23
汉字汉语研究(2020年2期)2020-08-13
布达拉(2020年3期)2020-04-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
西夏学(2019年1期)2019-02-10
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
