
面向动态主题数的话题演化分析
2014-02-28 07:41黄河燕魏骁驰
中文信息学报 2014年3期
方 莹,黄河燕,辛 欣,魏骁驰,庄 琨
(1. 北京理工大学 计算机学院,北京 100081)(2. 商丘师范学院 计算机与信息技术学院,河南 商丘 476000)
引言
话题检测和跟踪[1](Topic Detection and Tracking, TDT)经过近30年的研究,已形成了一些较为成熟的算法和系统,其目标是将待处理的新闻语料按照阐述的话题内容归并到相应的类中,并在没有所属话题类时建立新类[2]。新闻报道多是发展变化的连续事件过程,如何自动分析出其变化趋势并以一定形式(例如,话题变化曲线图、话题简报等)呈现出来,是诸多用户关心的问题,这也正是话题演化[3]任务的目标,目前在该方面仍有较大研究空间。
按文本表示模型不同,可把已有计算话题演化的方法归为两类: 一种基于向量空间模型(Vector Space Model,VSM),另一种基于概率模型(Probabilistic Model)。前者把文本看作无序词的组合,计算文本相似度,由文本分类和聚类方法决定前后话题的联系,例如,文献[4-5]分别基于K-means聚类和FCA(Formal Concept Analysis)实现话题的演化,该方法只考虑重复出现的词对话题的决定作用,且文本分类或聚类的类别数要么需要事先指定,要么按给定阈值后迭代求出,无法做到非人工参与;近年来迅速发展起来的方法多是基于概率模型的,该方法通过计算主题概率及前后主题间的概率差异来衡量话题的联系性,可以在一定程度上摆脱词形差异带来的计算偏差,同义词和近义词的作用得以发挥,例如,文献[6-7]分别基于PLSI(Probabilistic Latent Semantic Indexing)和LDA(Latent Dirichlet Allocation)模型进行话题演化分析,文献[8]在LDA模型中加入了增量信息,文献[9]设计的OLDA(Online LDA)模型更加注重在线文本的处理能力。虽然以上研究的侧重点各有不同,但它们具有一个共同的弊端: 主题的数量是固定不变的且需事先给定。
在话题演化的整个过程中,主题的数量当然不是固定的,某个主题也并非贯穿整个过程。例如,地震发生的前1~3天,报道重点一般集中于地点、震级、伤亡等基本信息,接下来对于救助人员、抢通道路、恢复水电等各方面的报道逐渐增多,再接着对震后生活状态、重建等方面的描述会成为主流。如果能按照时间顺序动态确定主题出现的时间段,并且动态调整主题数目,则该方法更符合事件发展的真实情况和报道规律。基于此,提出了基于ILDA(Infinite Latent Dirichlet Allocation)模型[10]的话题演化分析方法,该模型的突出特点是: 当输入文本集发生变动时,主题数目会随之发生变动。
本文的贡献有: (1)利用ILDA模型自动获取文本集的主题数;(2)构造了话题演化分析系统,对连续发生的真实新闻报道文本集进行演化分析,针对实验规模和划分出的超大子主题划分提出了针对性改进方法,实验结果与话题实际发展过程一致;(3)将变动的主题数加入实验系统后显示出不错的应用效果,可扩展性强和自动执行能力高,演化分析过程完整可行。
1 LDA和ILDA模型介绍

图1 LDA模型生成示意图
主题模型是一种概率模型,可以自动提取隐含在文档集中的主题,并按照词的分布形式直观地表达主题,为无监督地分析文档提供了方便的工具。LDA模型[11]由Blei等人于2003年提出,由于参数简单、不产生“过拟合”现象,已成为一种重要的主题模型,在话题演化领域亦得到广泛应用[12]。该模型可看作一个生成性的3层贝叶斯网络,即把文本语料看作离散数据,数据中的每一个元素看作是由底层的有限个混杂在一起的主题产生出来的,而每一个主题又被看作是从一个更底层的概率模型中产生出来,其生成结构图如图1所示。
在LDA模型中两个超参α和β是需要事先给定的,通过多次迭代后它们的初值对系统影响很小。主题数K是另一个需要用户给定的值,表示文本将在多少个主题上进行划分,值太大则主题过于分散,存在空主题,造成运算开销大且各主题间差别偏小;值太小则不能满足划分需求,不利于进行正常分类。到底K值多大是合理的?如何自动得到K值?ILDA 模型(图2)着力解决以上问题。

图2 ILDA模型生成示意图
比较图2与图1,可看到两点不同: (1)主题数K不再局限于具体数值,而是扩大到无穷区间(k∈[1,∞)),且φk~Dir(β);(2)θ不再单纯是超参α的多项分布,而是由α0与某个基分布(base distribution)G0产生的狄利克雷过程(Dirichlet Process,DP)[13]。DP(图3)是产生概率分布的随机过程,基于多项参数变量和建立在离散变量上的分布而进行,记作式(1)。
其中,

图3 DP模型示意图
由于本质上的离散性,DP通常作为混合模型的先验分布[13],其优势是元素个数不再作为模型的直接输入,而是可以随着实际需要发生变化,这正是本文采用ILDA模型的精髓之处。

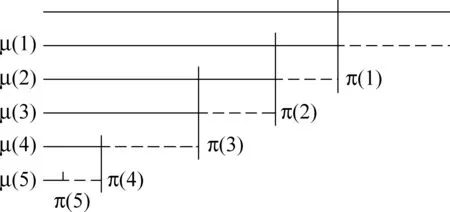
图4 SBC过程示意图
2 动态主题数下的话题演化分析
话题演化过程需考虑的两大因素是时间和内容,既要实现在内容上按主题进行分类识别,又要实现在时间上的延续和关联。
2.1 话题演化分析框架
要实现上述功能,本文采用的思路[14]是: 以时间周期为分界,把文本集划分为多个独立单位,根据主题将其中文本分到不同小类中,然后按时间顺序把相邻的小类关联起来,进而分析关联起来的主题之间的关系。以上述思想为指导,话题演化的分析框架(图5)可分为以下5部分。
S1 把文本集Dm(m∈[1,M])按周期T划分为多个子文本集DSi(1≤i≤Tmax);
S2基于Gibbs采样对DSi求ILDA模型参数: 确定每个周期的子主题数和主题概率;
S3 把DSi分为独立的子主题;
S4 用公式(12)计算相邻周期间子主题的距离,如超过阈值则建立关联;

图5 话题演化分析框架图
S5 以折线图形式显示结果并分析发展过程。如:Topic2的相关子主题为t11→t22→t32→t42,强度大小由曲线的高低来反映。
演化分析过程中有3个关键问题: 如何确定子主题数?子主题间的距离(关联度)如何计算?阈值如何自动获得?以下两小节将做介绍。
2.2 基于Gibbs采样的ILDA主题数获取算法
由于Gibbs采样方法简单、适应性强等优点,用其作为参数获取方法,相应的ILDA主题数获取算法[15]可描述为:

算法过程为:
初始化K=K0,nm,k、nk,t、nm、nk置为0
步骤1 计算所有文本的参数初值:
对文本中每个词
{分配一个多项分布初值使得zm,n=k~Mult(1/K);
与主题对应的数据nm,k、nk,t、nk分别加1;}
步骤3 对所有文档进行采样过程:
对文本中每个词
{去掉当前主题时计算:nm,k-=1;nk,t-=1;nk-=1;}

否则
{产生一个新主题,置其nm,k、nk,t、nk为1;

步骤4 如果主题相关概率值Θ和Φ收敛,结束本次迭代;否则转步骤5;
步骤5 重新开始采样并计算参数值:
清理空主题
{ K值减1;
与空主题相关的nm,k、nk,t、nk全部置为0;}
步骤6 若迭代次数未达到iteration,则转步骤3重复采样过程;否则结束算法。
其中
mk=∑m∑rmm,k,r(4)
(r∈[1,nm,k],m∈[1,M],k∈[1,K])
参数说明2α计算公式为:
其中,
参数说明3γ计算公式如式(9)所示。
其中,
2.3 主题关联度计算、阈值确定和文本集处理方法
(1) 子主题的关联度选用KL距离来衡量,这是主题模型中最常用的方法,定义如下:
设Ti周期中,文本集DSi包括NiM个文本,被划分成Ki个子主题,子主题ti-1,j′与ti,j间KL距离(KL divergence)为式(12)。
(2) 不同子主题间的KL距离可能差别较大,人工给定阈值的做法将大大降低系统自动执行和移植的能力,对此,采取了“取均值-加权”的做法,ti,j与前一周期的阈值计算公式为式(13)。
其中,ti-1表示ti-1周期的子主题数目,λ为大于等于1的实数。
(3) 实验过程发现,文本集规模会在一定程度上影响系统性能,需要针对性地采取措施,以提高效果,具体过程可分为两类。
(a) 当文本集规模过小(少于20篇)时,词语的集中程度不够突出,得到的主题数有可能超出文本个数,这时算法的优势将不能得到充分体现。对此,系统采取这样的措施: 把实验文本复制多份,这样能在不影响词语分布概率的情况下,提高词语集中度,扩大采样空间。
(b) 当文本集规模较大(多于300篇)时,易划分出“超大子主题”。这是因为系统本质上可归结为文本分类过程,而“超大类”的产生是文本分类中一个常见问题,这是由于大类包含特征多,待分类文本易与其找到共性信息,因而易归入已存在大类中,导致大类呈现“滚雪球”式增长。对此,系统采取这样的措施: 当子主题包含文本数超过一定比例(例如,所在文本集2/3规模)时,对其进行二次划分。
3 实验分析
关于主题数的确定问题,以英文数据集NIPS为对象进行,与文献[4]进行比较,以说明主题数动态产生的必要性和可行性。关于演化系统,以自建语料库进行,实验文本是关于“神州九号飞船”的中文连续报道,关注点在于能否对汉语文本正确分析出话题转变的过程。
3.1 NIPS上主题数的确定实验
英文数据集NIPS[16]以年为单位分成若干卷,每卷对应一个文件集,集合中文本数从90到152不等。以上述文本集为对象,文献[4]基于LDA模型进行了演化分析,其对每个文本集设定同样的主题数目30。本文对从1987年到1999年的1 740篇文本,按年进行了主题数确定实验,实验一设定迭代次数为100,实验二设定迭代次数为150,图6给出两次实验提取到的主题数与文献[4]的对比情况。

图6 NIPS语料上的对比实验
对NIPS语料的分析发现,虽然其中的论文集研究领域受限定,但每年的论文集涉及的主题数是变动的。例如, 实验二反映的情况是: “主题数应介于8~24之间”,经过与真实语料库的比较分析,本文的实验结果与实际的主题数一致,这比把主题数固定为30更为合适。实验还发现: 主题数的多少与文本集大小没有正比关系,决定因素在于主题的集中程度;例如,实验二中nips02由101篇文本组成,其主题数为8,而nips01由95篇文本组成,其主题数却为13。
3.2 关于“神州九号飞船”报道的话题演化分析
实验数据来自凤凰网、新浪网、强国网、国际在线、网易新闻、万维读者网、大旗网、华声在线、中国金融网等14个网站,分别在7点、11点和17点3个时间点采集信息,关于“神九”的报道从6月9日~7月9日,共采集到6 088篇,文本数—时间分布图见图7。

图7 实验文本采集数量图示
从图7可看出文本数量在不同时间段有较大差别,经人工分析,峰值与关键报道的发生时间一致,内容要点可简要说明为: 6月9日神九进入待发射状态,之前鲜有报道,之后呈现小幅上升态势;16日发射时报道数量较前成倍增长,以加注燃料、安全保障、天气状况、各项准备工作等为主要内容;17日报道数量达到最高峰值,以发射过程和现场状态为主;之后两天数量呈小幅下降趋势,内容多以航天员生活状态为主;经历两天下降有小幅回升再下降过程;29日神九返回时报道数量再次达到一个高峰,其前后两天的报道数量也相对多起来;7月份以后报道数量明显回落,内容也较为分散,航天员身份、成长经历、武装力量、周边关系等诸多主题进入大众视野。
以天为周期,把每天采集到的信息构成一个子文本集,规模从19篇到791篇不等。100次迭代后,基于ILDA确定的各周期的子主题数如图8所示。
关键词是文本集的直接描述,通过抽取并比较各子主题相应文本集的关键词,可大致看出子主题划分得是否合理。表1给出对6月16日13个子主题分别抽取到的得分靠前的关键词,词语的重要程度由卡方检验χ2(Chi-square)[17]来度量,这是用于特征选择的效果比较好的方法之一,词w与子主题t的卡方值计算公式如式(14)所示。
其中,A、C分别表示在t中出现和未出现w的文本数目,B、D分别表示在除t之外的子主题中出现和不出现w的文本数目,N为A、B、C、D四数之和。
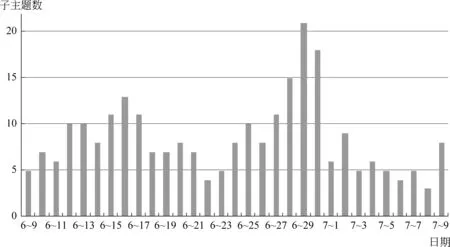
图8 子主题数示意图

子主题关 键 词0航天员神九女任务中国飞行航天载人发射对接飞船对接交会进行完成天宫工程太空1小区凉皮郑州电视骄傲物业奖励烩面退休电视机家乡观看河南女儿邻居居住挤满家2入选刘洋成为第一载人训练孩子两年景海鹏结果生活获得学习大队部队珍惜安全刘旺3海底弹海浪海沟矗立海水吊缆热带重臂大海甲板风暴双臂高新热血响彻解脱蛙人4父母问题讲坛生理同学欢迎性格特点安静手舞足蹈支离破碎拼凑正气清秀嘴角确切5交警完成门前中山飞船发射如虎添翼丰盛广东省社保献策驾校足球访问量球迷传回交锋6形状反推力热量跟踪测量气阀圆柱分解蛹搜集落点不测应答报警工序隔热升华蒸发7景海鹏对接刘旺交会执行刘洋发射太空工程训练天宫体会操作亮相酒泉发言人搭配指令8递景色航天部玻璃罩一流神经中枢奋斗左手颤抖房门手指人脑控制实现控制模式作用力9生育已婚临床恶劣年度调研结论病史各科特殊性静力伸展超人体检稳定性直系亲属10防毒面具一定量死神盐湖区氧化剂管路反应器办事处防化绘图塑像上眼预期跳跃氧化泄露11规避院士发型工程院出身品格通行发卡心率口号中毒飘逸优于带子妊娠理发孔达科娃12致力焦点对准CNN俱乐部英国航天局建设性安南一飞冲天墨西哥欧盟寻求叙利亚外交部
从表1可以看出各子主题间词语分割比较清楚,各有侧重点,例如,topic0、1、3、9、12分别描述了发射情况、刘洋家乡反映、“蛟龙”号信息、航天员选拔条件、外媒看法,topic5因为在介绍神九的报道中混入了足球赛情况使得与足球相关的词汇凸显出来。这些词语表现出来的明显的区分度标识出本文的子话题划分方法是成功的。
当阈值定义为后一周期某子主题与前一周期子主题间KL距离的平均值的1.3倍时,在各周期间共建立了158条连线,首位女航天员无疑是“神九”一大亮点,这也成为实验中连线强度最大的子主题,图9给出相关文本集强度折线图,其中,折线越粗表示KL距离越大。分析发现,联系性极强的两个时间节点为: 6月15日~6月16日和6月21日~6月22日,对应的报道分别涉及首位女航天员的确定和刘洋在太空值班情况,因为报道焦点相对集中,所以对应子主题较为突出。

图9 子主题联系示意图
为了更好地描述折线变化的原因,以与具体报道联系起来,对图9涉及文本抽取了每个周期中代表性的文本标题(表2)。

表2 代表性报道的标题抽取结果
通过对“神九”连续一个月的报道进行实验,尝试了按周期进行子主题划分、相邻周期间子主题的连接强度计算并关联、反映主题特征的关键词和标题抽取等步骤,分散的报道得以串联起来,方便对话题形成按时间顺序的大致发展过程的描述。
4 结束语
基于ILDA的参数获取方法使得主题数可根据输入文本集进行动态更新,无浪费,可扩展,更符合话题演化的需求。在此基础上构建的话题演化分析系统无须事先指定主题数,自动执行能力强,结果可行,能达到设定的演化需求,对中英文语料的实验显示出良好的可移植性,具备实际应用能力。但研究还暴露出一些问题,对主题差别小的文本集分类效果不够好,主要原因是文本特征区分度不够强,另外也一定程度上受到分词效果的影响,因此,下一步需要加强文本预处理工作: 提高分词效果,加入文本特征选择,加强重要特征的分类作用,以期改进子主题划分结果。
[1] Allan J. Introduction to topic detection and tracking[M]. Topic detection and tracking. Springer US, 2002: 1-16.
[2] 洪宇,张宇,刘挺,等.话题检测与跟踪的评测及研究综述[J]. 中文信息学报,2007,21(6): 71-87.
[3] Gohr A, Hinneburg A, Schult R, et al. Topic Evolution in a Stream of Documents[C]//Proceedings of the SDM’09:859-872.
[4] 吕楠,罗军勇,刘尧,等.一种有效的事件演化分析算法[J].计算机应用研究,2009,26(11):4101-4103.
[5] Martinovic J, Gajdoš P. Vector model improvement by fca and topic evolution[C]//Proceedings of the DATESO. 2005, 129: 46-57.
[6] Mei Q, Zhai C X. Discovering evolutionary theme patterns from text: an exploration of temporal text mining[C]//Proceedings of the 11th ACM SIGKDD international conference on Knowledge discovery in data mining. ACM, 2005: 198-207.
[7] 崔凯,周斌,贾焰,等.一种基于LDA的在线主题演化挖掘模型[J].计算机科学,2010,37(11): 156-159,163.
[8] Song X, Lin C Y, Tseng B L, et al. Modeling and predicting personal information dissemination behavior[C]//Proceedings of the 11th ACM SIGKDD international conference on Knowledge discovery in data mining. ACM, 2005: 479-488.
[9] AlSumait L, Barbará D, Domeniconi C. On-line LDA: adaptive topic models for mining text streams with applications to topic detection and tracking[C]//Proceedings of the Data Mining, 2008. ICDM’08. Eighth IEEE International Conference on. IEEE, 2008: 3-12.
[10] Heinrich G. Infinite LDA implementing the HDP with minimum code complexity[J]. Technical note, 2011: 170.
[11] Blei D, Ng A, Jordan M. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research,2002,3:993-1022.
[12] 单斌, 李芳. 基于LDA话题演化研究方法综述[J].中文信息学报,2010, 24(6): 43-49.
[13] Gershman S J, Blei D M. A tutorial on Bayesian nonparametric models[J]. Journal of Mathematical Psychology, 2012, 56(1): 1-12.
[14] 贺亮,李芳. 基于话题模型的科技文献话题发现和趋势分析[J].中文信息学报,2012: 26(2): 109-115.
[15] Teh Y W, Jordan M I, Beal M J, et al. Hierarchical Dirichlet processes[J]. American Statistical Association, 2006,101(476): 1566-1581.
[16] NIPS corpus[DB/OL]. http://sourceforge.net/Projects/knowceans/files knowceans/ knowceans-tools/ nips-corpus-20111205.zip download.
[17] Zheng Z, Wu X, Srihari R. Feature selection for text categorization on imbalanced data[J]. ACM SIGKDD Explorations Newsletter, 2004, 6(1): 80-89.
猜你喜欢
小猕猴智力画刊(2022年9期)2022-11-04
云南教育·小学教师(2022年4期)2022-05-17
民用飞机设计与研究(2020年4期)2021-01-21
艺术评论(2020年3期)2020-02-06
制造技术与机床(2019年10期)2019-10-26
小哥白尼(趣味科学)(2019年6期)2019-10-10
电子制作(2018年18期)2018-11-14
电子制作(2018年18期)2018-11-14
山东工业技术(2016年15期)2016-12-01
发明与创新(2016年38期)2016-08-22
