
基于Ap rio ri改进算法的中药处方分析技术
2014-02-18 05:43:38滕璐灵张宝林
西部中医药 2014年5期
滕璐灵,宋 尧,张宝林
甘肃省中医院,甘肃 兰州 730050
在中医医院,HIS系统数据库里的中药处方数据是极其宝贵的,对中医处方数据的分析,可以得到中医师针对不同患者开具的中医处方用药规律,可对今后同类病症的治疗起到辅助参考的作用。因此本研究以关联规则挖掘为模型,设计了中药处方分析算法。
1 中药处方分析的基本原理
Apriori算法是一种挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。算法需要对数据集进行多步处理,第一步,简单统计所有含有一个元素项目集出现的频率,并找出不小于最小支持度的项目集;从第二步开始循环处理直到再没有最大项目集生成。循环过程是:第n步中,根据第n-1步生成的(n-1)维最大项目集产生m维候选项目集,然后对数据库进行搜索,得到候选项目集的项集支持度,与最小支持度比较,从而找到n维最大项目集[1]。
中药处方分析算法是以关联规则模型为依据,在给定中医数据集中进行频繁项集的搜索[2],应用最小支持度计数阈值为度量标准从候选集中查找频繁项集。关联规则在D中的支持度(suppor t)是D中事务同时包含X、Y的百分比,即概率;置信度(conf idence)是包含X的事务中同时又包含Y的百分比,即条件概率。
查找频繁项集是实现中药处方分析的关键,采用查找频繁项集的经典算法——Apriori算法为核心进行设计实现,但又通过缩小扫描事务集的范围提高算法的执行效率。
2 中药处方数据的预处理
数据挖掘对基础数据的要求较高,因此数据预处理就变得尤为重要。数据的预处理通常按照以下步骤进行:
2.1 数据筛选 中药处方分析技术的研究对象是中医医嘱中相关中药处方的内容,所以作为基础数据,首先需要将中药处方信息从医嘱信息中分离开来[3]。
2.2 数据表标准化 在标准化处理的过程中需要解决的问题是中药药名的统一,一味中药可能存在不同的别名,因此在统计分析时不应作为不同的药物来对待,需要根据中药药名对照表进行匹配核对。
2.3 生成中药处方 生成中药处方布尔值统计表与事务统计表,流程见图1、表1—5。
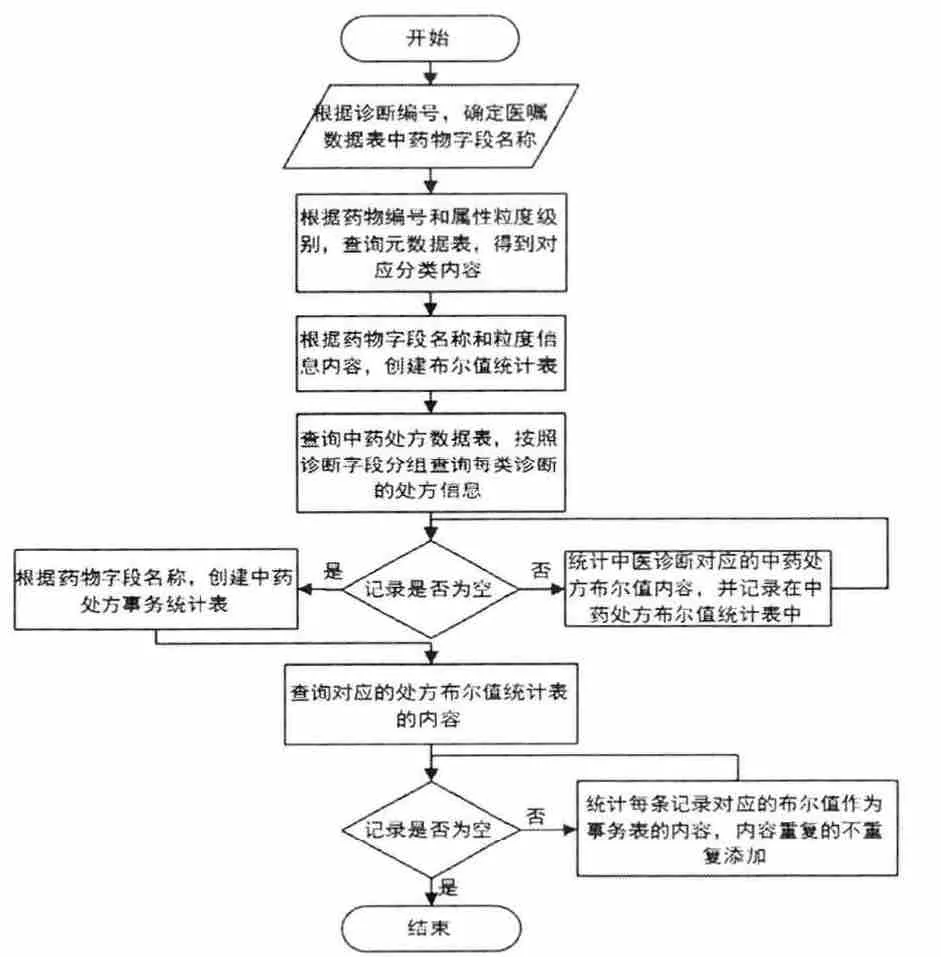
图1 生成布尔值统计表与事务统计表的流程

表1 中医诊断类别定义
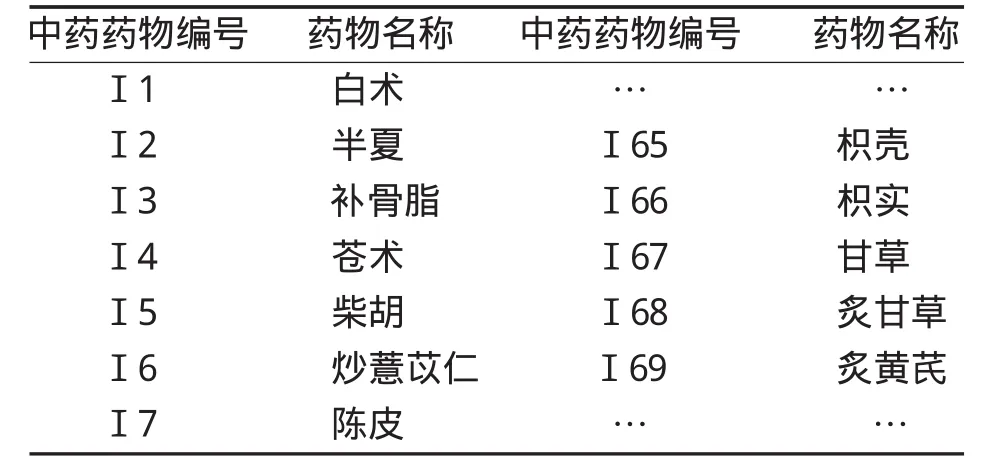
表2 中药药物信息定义

表3 中药处方信息定义

表4 中药处方药物布尔值统计
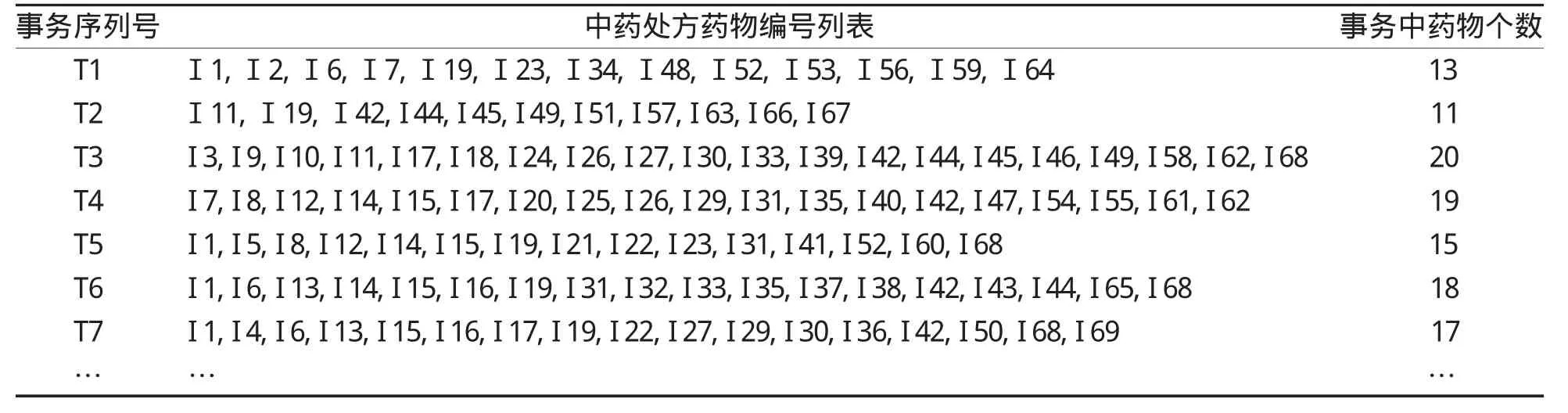
表5 中药处方事务统计
3 中药处方分析算法设计
以上得到的中药处方事务统计表不是真正需要的有价值的信息,还需要通过中药处方分析算法,对表中的记录进行进一步分析[4],主要流程见图2:
L1=f ind_f requent_1-itemsets(D);
for(k=2;Lk-1≠Φ;k++){Ck=apriori(Lk-1,min_sup);
for each t ransaction t∈D{Ct=subset(Ck,t);
for each candidate c∈Ctc.count++;}
Lk={c∈Ck|c.count≥min_sup}}
return L=所有频繁集;
4 中药处方分析中的算法运行情况
通过输入不同的中医诊断编码,可以得到不同病症的中药处方分析数据。首先筛选出中医诊断中痹症的中药处方部分事务,结合这些数据说明算法的实际应用,见附图1。
临时表中输出频繁项集为{I1,I15,I19,I68}。由频繁项集可产生中药处方用药规则,其置信度计算如下:

将事务编号进行替换后得到中药药物名称的规则记录表,见表6。
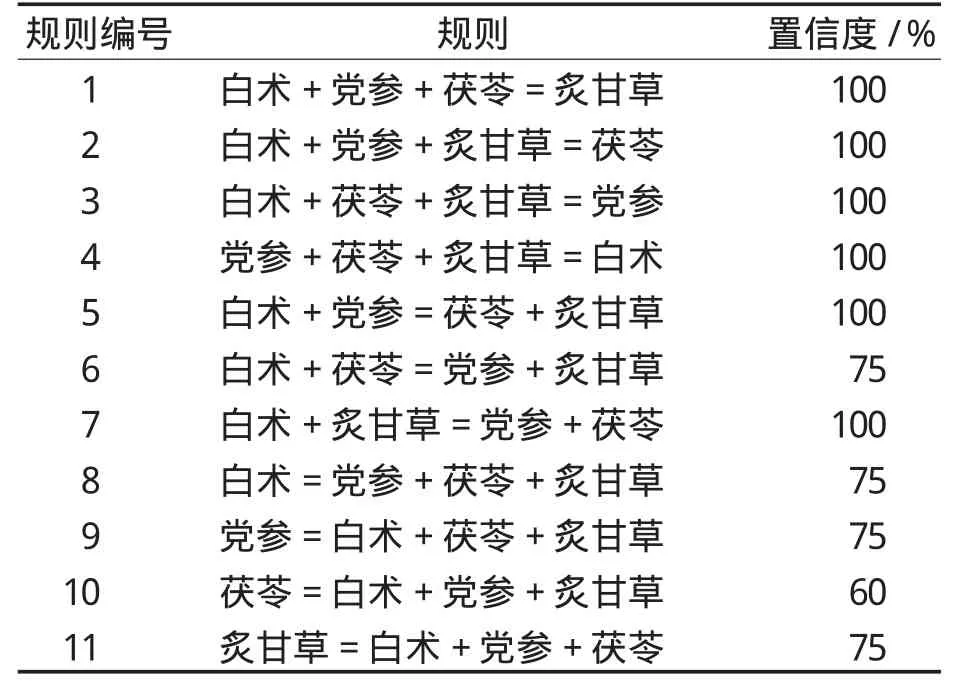
表6 转换后的规则记录
5 讨论
传统的Apriori算法在候选项集进行支持度计数时,每次都要对原事务表进行扫描,原事务表中的数据往往较巨大,导致该算法效率低下,因此在中药处方分析算法中,设置了“药物个数”字段,记录每张处方中包含的中药药物个数,在进行候选集支持度计数时,只针对“药物个数”>=3的记录进行扫描,以提高算法的执行效率。

附图1 频繁项集生成过程
[1] Jiawei Han,Michel ine Kamber.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2007:133.
[2] 李凌艳,李认书,孙鹤.数据挖掘技术在中药研究中的应用[J].中草药,2010,41(5):I0016-I0018.
[3] 钱增瑾,辛燕.中医药数据预处理方法的设计与实现[J].计算机工程与设计,2005,26(12):3199-3200.
[4] 丁一琦.基于Apriori算法的数据挖掘技术研究[J].现代计算机,2012(24):20-22.
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
山西教育·招考(2021年8期)2021-12-17 23:33:17
山西教育·招考(2020年8期)2020-08-28 11:29:59
河南水利年鉴(2020年0期)2020-06-09 05:43:44
学苑创造·B版(2018年5期)2018-05-30 09:06:02
派出所工作(2017年10期)2017-05-30 08:34:15
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
长春大学学报(2013年8期)2013-06-21 09:04:04
