
基于Hadoop的高频电力负荷监测数据存储研究
2014-02-10 10:34黄骏
机电工程技术 2014年3期
黄骏
(广东电网公司阳江供电局,广东阳江 529500)
基于Hadoop的高频电力负荷监测数据存储研究
黄骏
(广东电网公司阳江供电局,广东阳江 529500)
电力负荷数据采集频率已从分钟级低频数据转向秒级甚至毫秒级的高频数据,数据存储量级呈数百倍增长,对数据的存储及查询的效率要求更高。为处理这些海量数据,设计了基于Hadoop技术的负荷数据存储系统,并验证了该系统具备分布式存储及实时查询的优势,适合智能电网环境下高频负荷数据的存储。
Hadoop;高频电力负荷;数据存储
0 引言
随着智能电网技术的大力推进,智能电网环境下电力行业数据量以几何形式激增。电力负荷数据已从传统的分钟级低频数据转向了以秒甚至毫秒级采集的高频数据,对数据存储的可靠性和实时性要求更高,原有存储系统已远远不能满足海量数据的要求。国内现有的电力信息系统建设大多采用大型服务器,存储部分采用磁盘阵列,数据库采用关系型数据库,导致系统扩展性低、成本高、查询和计算效率较低,难以适应智能电网对高频电力负荷数据可靠性和实时性的要求。
随着Map Reduce编程思想的提出,它在互联网Web应用中成为研究热点。Hadoop作为MapRe⁃duce的一个开源实现,由于成功的借鉴了Big⁃Table和MapReduce并行算法等技术,使得它能够对大规模海量数据进行分布式处理,已成为一个成熟的软件框架。Hadoop通常会保存和维护多个数据副本,因为它考虑到计算和存储过程中可能会出现一些故障,以便当故障出现时能够对出错的地方重新进行计算处理,从而具备纠错功能。HDFS(Hadoop Distributed File System)作为Ha⁃doop上的一个分布式文件系统,能够并行的进行文件操作,从而可以加快任务处理速度。Hadoop的计算具有一定的扩展性,能够处理PB级数据,但其扩展性的强弱受部署Hadoop的计算机群的规模的影响较大,Hadoop如今已广泛应用于搜索引擎、数据挖掘和生物计算等领域[1-2]。
本文针对电力负荷数据的特点,设计并实现基于Hadoop的高频电力负荷数据存储系统。
1 基于Hadoop的电力高频负荷数据存储系统设计
Hadoop文件系统(HDFS)是适合存储电力高频负荷数据的存储系统,它作为一个分布式文件系统运行在普通的硬件上。由于HDFS的高容错性,可以在低成本的硬件之上部署大数据集的应用程序。HDFS的数据上传流程如图1所示。
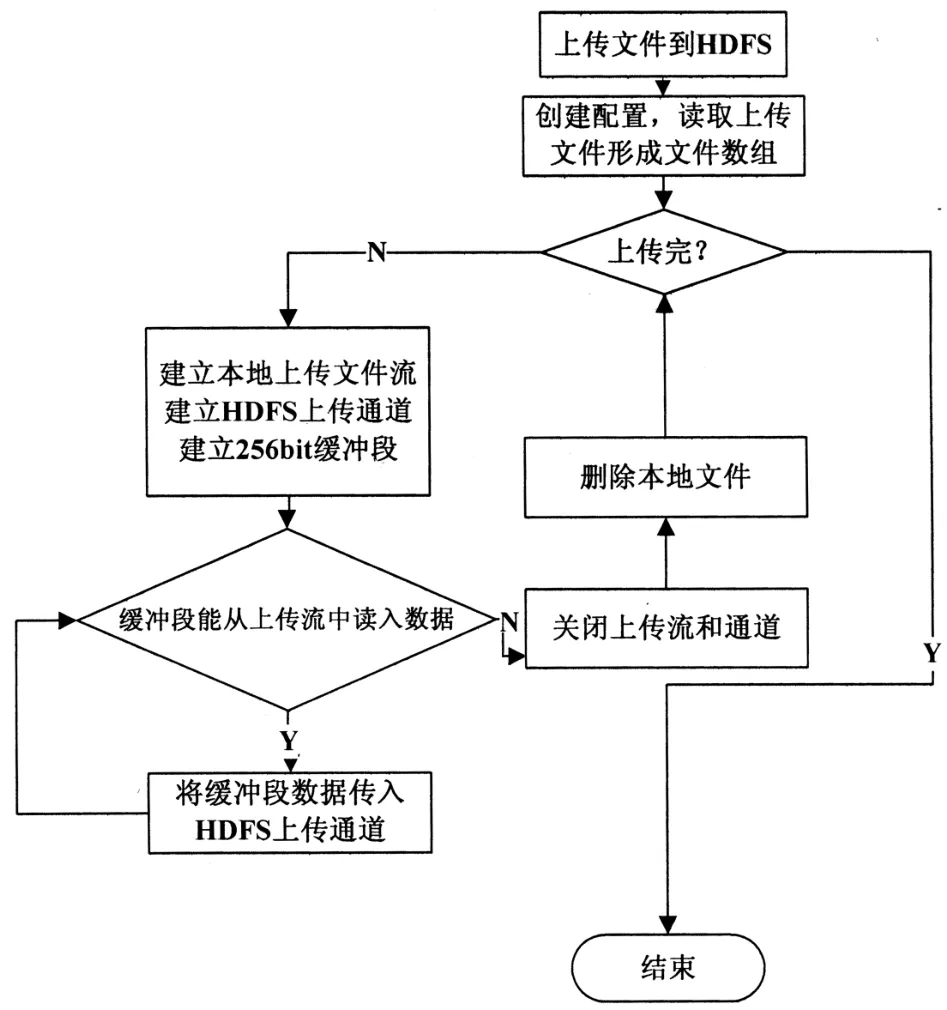
图1 HDFS上传流程
一个HDFS集群是由一个主服务器NameNode和多个数据节点组成。主服务器NameNod的通常用来控制客户端的文件访问和实现文件命名空间的管理。NameNod是仲裁者,通常系统设计的实际数据不经过NameNode。数据节点则用来管理存储,通常一台机器部署一个数据节点,有时也会在一台机器上部署多个数据节点。HDFS不仅暴露文件的命名空间而且允许将用户数据以文件形式存储。其原理机制是首先将文件分割成一个或多个块,然后再将这些块存储在一组数据节点中。NameNode用于文件命名空间和目录的操作,例如文件和目录的打开、关闭和重命名。同时Na⁃meNode还用来确定数据节点和块之间的对应关系。数据节点则既要负责来自文件系统的客户读写请求,又要执行块的创建,删除和来自Na⁃meNode的块复制等指示操作。NameNode和数据节点软件通常都是运行在普通的linux机器之上,由于HDFS使用Java编写,因此任何支持Java的机器都可以运行NameNode和数据节点。另外,由于Java语言的可移植性,因此将HDFS应用并部署到大范围的机器上也非常容易。当部署到大范围的机器上时,通常会有一个机器专门用来管理和运行NameNode,机群中剩下的每个机器则运行一个数据节点实例。值得注意的是HDFS不允许在一个机器上运行多个数据节点的实例,然而在实际的部署过程中也不会出现这种情况。上述这种单NameNode的机群模式可以极大地简单化系统的复杂度。
1.1 Hadoop集群搭建
通过虚拟化技术,在安装Centos操作系统的PC机上,搭建内网环境(IP段:192.168.0.0),在各机上安装JDK、SSH和Hadoop,即完成了Ha⁃doop分布式集群的搭建。
传统的电力负荷数据通常采用关系型数据库来实现存储,然而对于海量数据而言,关系型数据库的存储和查询效率很低,难以适应智能电网对高频电力负荷数据可靠性和实时性的要求。在上述搭建好的Hadoop平台上,通过实验测试证明了HDFS分布式数据库管理的高效性。根据上述HDFS的特点,设计了一种基于HDFS的数据结构,如表1所示。
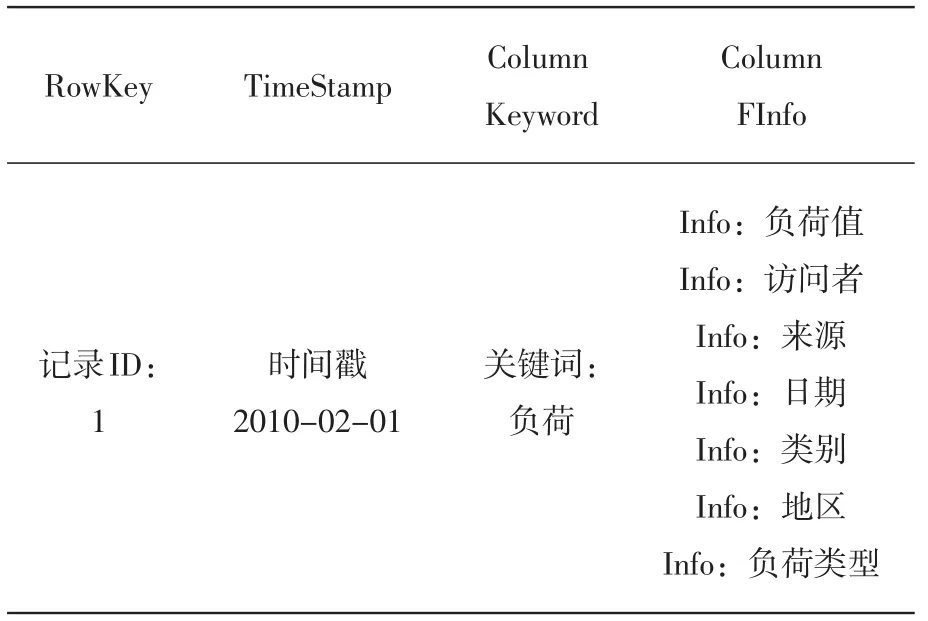
表1 LL_HD_MAIN表
用记录的ID作为RowKey,表示记录的唯一标识,表中共有1个列簇FInfo列簇,存储抽取结果的相关信息.包括负荷值、访问者、来源、日期、地区、负荷类型等。LL_HD_MAIN表是一张稀疏的半结构化的表,一张表即可满足业务需求。对于一个RowKey而言,只需制定相关的列簇名即可获得相关查询的全部信息。LL_HD_MAIN表的物理存储结构如表2。

表2 文档信息物理存储片段
上述物理表结构表明,在HDFS系统中实际存储时,业务相关数据的存储是连续,这样可以大大减少查询的时间耗时。
1.2 MapReduce设计
MapReduce设计的第一步是选择一个核心节点,这个核心节点包含在集群节点中。它作为一个主控角色存在,称为master,主要用来控制任务的分配,待分配的任务包括reduce任务和map任务,其数量分别为R和M。Master通常会将re⁃duce和map任务分配给将空闲的worker。每当有数据输入,master便会给worker指定一个map任务,让其处理相关的文件块数据,同时master还会在临近的机器或副本机器上开启map任务,以便减少远程I/O操作造成的时延。
Worker的任务是读取文件块,进行块处理,分析key/value并将结果转交给map函数,这个map函数是用户定义的。当Map worker的任务执行完时,便会告知master,让其更新数据(例如缓冲文件的位置信息),并将信息传递给正在运行的Reduce worker[3-4]。Reduce worker首先将排序后的所有中间数据进行迭代处理,然后将相关的中间结果和key转交给reduce函数。这个Reduce函数也是用户自定义的,其作用是将中间结果输出到最终的文件里。
2 实验与结果分析
本文实验建立在由10个节点组成的Hadoop平台上,每个节点物理机器配置为4核i5 CPU,4G内存,100 Mbit/s以太网带宽,虚拟机配置为2核CPU,2G内存,100G硬盘空间。
实验环境主要考察Hadoop平台受数据规模的影响。实验的数据规模选取分别为:10万,100万,500万,1 000万和2 000万进行实验。为了保证实验的可靠性,每个数据量进行3次实验取平均值,表3给出了实验结果。
图3为表3实验数据的折线图表示,其中纵坐标表示时间(单位为秒),横坐标表示数据集的大小(单位为万)。
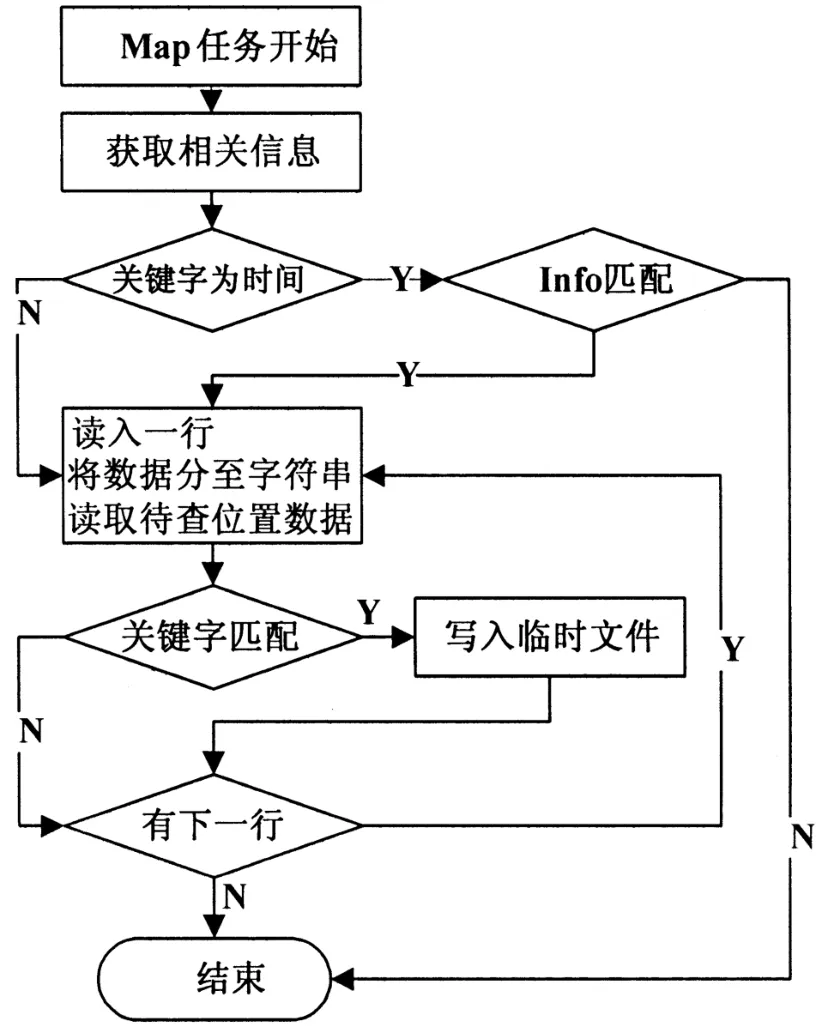
图2 Map函数处理过程
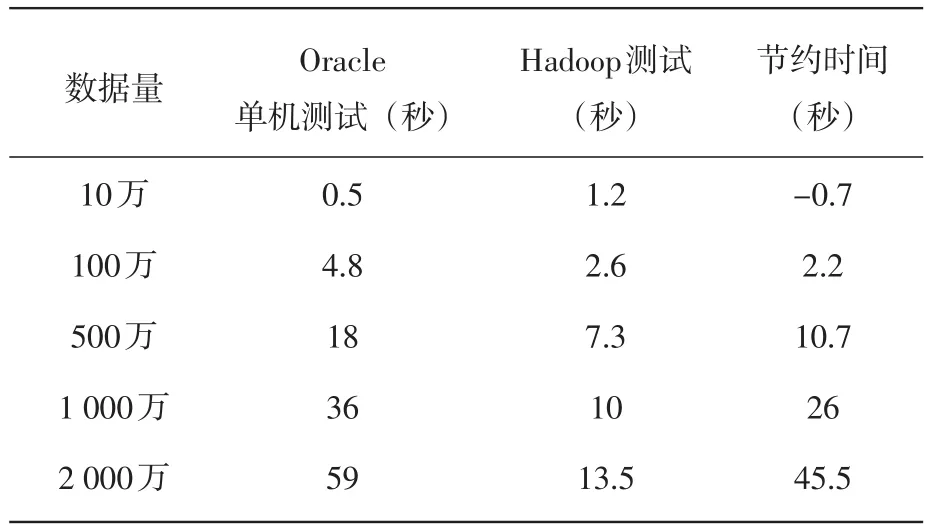
表3 试验比较
实验结果表明,随着数据量的增加,Oracle单机的耗时增加幅度一直高于Hadoop平台,Ha⁃doop平台节约的时间逐渐增加,优势越来越明显,因此,实验搭建的Hadoop集群适合处理大规模数据的读写。但是,当数据量很小时,Hadoop平台的扩展效率比Oracle单机差。
3 结论与展望
针对智能电网环境下高频电力负荷数据海量、分布式的特点,本文设计了基于Hadoop技术的高频电力负荷数据存储系统,测试环境搭建了10个普通PC机的Hadoop集群,实验结果显示Ha⁃doop集群适合于处理大规模、海量数据;应用HDFS实现负荷数据的分布式存储于各个集群节点,数据无异常;应用MapReduce实现数据查询,并与Oracle单机关系型数据库查询性能做了对比,结果显示,随着数据的增大,Hadoop集群查询优势明显,适用于高频电力负荷数据库系统建设。
Research on the Data Storage System of High-Frequency Power Load Based on Hadoop Technology
HUANG Jun
(Yangjiang Power Supply Bureau,Yangjiang529500,China)
Electric load data acquisition frequency shift from the minute level low frequency data in seconds or even milliseconds of high frequency data,was the order of several hundred times the data storage growth,data storage and query efficiency requirements higher.To deal with these massive data,design data storage system based on Hadoop technologies,and verify that the system has the advantages of distributed storage and real-time queries,suitable for high frequency load data stored under the smart grid environment.
Hadoop;high-frequency power load;data storage
TP274
A
1009-9492(2014)03-0033-03
10.3969/j.issn.1009-9492.2014.03.010
2014-01-19
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
军事运筹与系统工程(2019年4期)2019-09-11
发明与创新·大科技(2019年12期)2019-03-17
电子制作(2018年11期)2018-08-04
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
雷达与对抗(2015年3期)2015-12-09
中国教育信息化(2015年12期)2015-08-24
