
高效的线性预测语音编码信息隐藏方法
2014-02-09 07:46李松斌戴琼兴邓浩江
计算机工程与设计 2014年4期
刘 鹏,李松斌+,戴琼兴,邓浩江
(1.中国科学院声学研究所南海研究站,海南海口570105;2.中国科学院声学研究所国家网络新媒体工程技术研究中心,北京100190)
0 引 言
网络语音流具有实时、大容量等特征,是进行信息隐藏的潜在优质载体。由于当前众多的VoIP(voice over internet protocol)常用语音编码器,如G.729、G.723.1等,都采用了线性预测编码(linear predictive coding,LPC)技术,因此基于LPC的信息隐藏方法具有较大应用价值。
近年来,研究者们在VoIP通信语音流中进行信息隐藏方面做了许多尝试。文献[1,2]给出了在G.729压缩语音流中进行最低有效位(least significant bit,LSB)替换的隐写方法;文献[3-5]给出了G.723.1压缩语音流中的LSB替换方法;文献[6]给出了针对G.711压缩语音流的LSB替换方法;文献[7]给出了在混合激励线性预测编码多级矢量量化过程中使用量化索引调制(quantization index modulation,QIM)进行隐写的方法;文献[8]给出了一种基于基音周期的隐写方法;文献[9]给出了一种在LPC过程中利用QIM进行隐写的方法。
LSB替换方法需要对不同的压缩标准进行具体分析,通用性较差。由于并不是所有压缩算法都具有基音周期或多级矢量量化过程,因此文献[7,8]中的算法通用性也不强。文献[9]中将LPC过程与QIM结合是一种较好的选择。但如果对LPC码字的改变次数过多,码字分布统计特征的变化很容易被察觉。
本文将给出一种联合矩阵编码与QIM的线性预测语音编码信息隐藏方法,称为MQCL(ME-QIM-Chaos based on LPC)方法。该方法通过提高信息嵌入效率达到减小失真、提高隐蔽性的目的。
1 MQCL方法介绍
1.1 MQCL方法概述
由于线性预测语音编码是以帧为单位进行的且编码时均包含LPC过程,因此语音码流可以看作一个LPC滤波器序列,如图1所示。

图1 语音码流的LPC视图
矩阵A代表了使用QIM进行嵌入时的所有可嵌入位置,即信息隐藏空间。由于嵌入的秘密信息长度是有限的,通常只需要用到部分载体帧。于是嵌入时存在对载体帧的选择,这种选择会导致不同的安全等级。
定义1 假设某种隐写算法b被检测算法d检测出存在隐写的概率是c,则该隐写算法的安全等级L可以表示为

安全等级代表了信息隐藏算法的安全程度,安全等级越高则隐写本身就越难以被发现。假设嵌入时挑选i帧作为载体帧,则隐写嵌入率可以表示为R=i/n。由于嵌入率和安全等级通常满足关系R∝1/Lb,d。因此为了达到不同的安全等级,只需要对嵌入率R进行调整。嵌入率确定后,需要对嵌入位置即载体帧进行选择。此时,如果采用固定的或易推测的选择算法,则检测者可以只针对嵌入位置进行检测,从而变相提高了嵌入率降低了安全等级。为此,本文将结合混沌理论对嵌入位置进行抽取,任何不知道密钥的第三方均不可能知道实际嵌入位置。
MQCL方法嵌入过程如下:
(1)根据所需安全等级选择合适的嵌入率。
(2)对矩阵A进行分块,每个子块为(p×m)阶矩阵,其中p为预先设定值。于是可以得到分块矩阵A=[A1A2…Aj]T。
(3)根据所需嵌入率结合混沌理论从每个块区中抽取i帧进行嵌入,根据p和嵌入率生成密钥K。于是可以得到待嵌入矩阵

(4)对B进行分块,每个子块为(q×m)阶矩阵,其中q为预先设定值。于是可得B=[B1B2…Bt]T。其中,每个子块即为MQCL方法中的最小嵌入单元,记为C。其获取过程如图2所示。
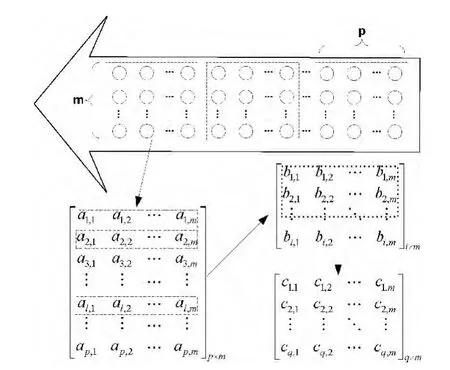
图2 最小嵌入单元的获取过程
(5)结合混沌理论利用密钥K进行块区内嵌入位置选择,本文共设计了8种嵌入模版。确定嵌入模版后,可以得到一个或多个待嵌入序列(c1,c2,…,cr),每个序列均含有若干个嵌入位置。
(6)针对每个待嵌入序列结合矩阵编码和QIM方法进行信息隐藏,并根据实际需要增加前向纠错编码。
MQCL方法提取过程如下:
(1)根据密钥K得到p、载体帧位置和块内嵌入模版。
(2)将载体帧携带的QIM信息记录下来,根据块内选择模版及q值得到待提取序列。
(3)根据前向纠错编码信息对秘密信息进行差错恢复,并通过矩阵编码的解码操作得到最终的秘密信息。
1.2 结合混沌理论进行嵌入位置及模版选择
混沌是一种确定系统中出现的伪随机无规则的运动,具有以下特性:
(1)伪随机性:混沌系统的输出受混沌轨道不规则性及系统局部伸缩的影响,呈现出类似随机噪声的伪随机性。
(2)遍历性:在有限区域内,混沌轨道上的点可以任意接近,这使得对初始条件的预测变得非常困难。
(3)发散性:相平面上任意接近的两点随着过程的进行都会指数性发散。
可见,混沌系统是一种天然的密码系统。本文将结合混沌理论进行嵌入位置及嵌入模版的选择。
Logistic映射是一类非常简单的动力系统,其定义为xk+1=μxk(1-xk),0<xk+1<1。当μ满足一定条件时,通过logistic映射可以产生非周期不收敛的混沌序列。本文将以logistic为例,对嵌入位置及模版选取过程进行介绍。
对混沌序列进行0-1量化后可得到序列y,序列y即可作为嵌入位置及嵌入模版的选择依据。序列y因只和初值x0以及μ的取值有关,因此可以将(μ,x0)作为密钥使用。图3显示的是当μ=3.96,x0=0.100000001或x0=0.100000002时,两个logistic序列的差值。可以看出,开始的若干次迭代中两者的差值较小,随着迭代次数的增加两者差值呈现出了无规律的变化特征。为了获得更好的安全性,我们规定MQCL算法中logistic序列的取值从第31个开始。
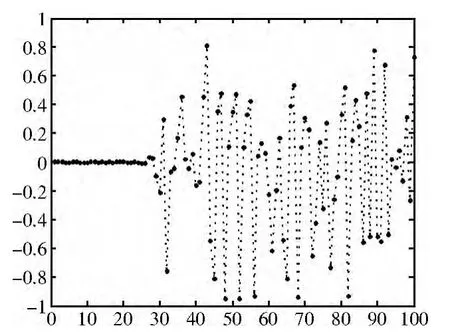
图3 初值的微小变化对logistic序列值得影响
MQCL方法中使用logistic映射进行嵌入位置及嵌入模版选择的具体过程如下:
(1)根据不同的p值确定logistic映射初值x0。x0和p满足x0=p/N,其中N为大于p的整数,可以自由设定。
(2)根据所需嵌入率选取适当的μ值满足3.5699456≤μ≤4,于是可以得到密钥(μ,x0)。
(3)首先根据密钥产生对应的y序列,然后将序列中(y34,y35,…,yp+30)作为位置选择序列即可得到待嵌入矩阵B。然后根据预先设定的q值即可得到最小嵌入单元。
(4)从最小嵌入单元C中抽取待嵌入序列(c1,c2,…,cr)的方法有多种,本文规定了8种待嵌入序列的抽取模版如图4所示。利用y序列中(y31,y32,y33)三位进行选择,(0,0,0)~(1,1,1)分别对应0~7这8种模版。图4中黑点表示抽取时的起始位置。
经以上步骤,我们便可得到待嵌入序列(c1,c2,…,cr)。例如,当q=7,m=3时
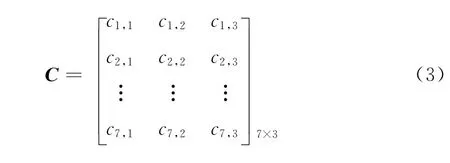
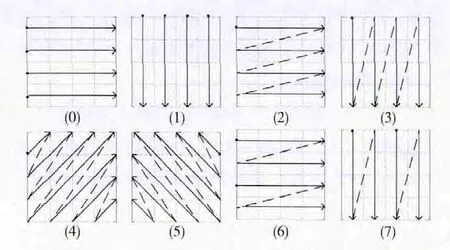
图4 块内待嵌入序列的8种嵌入模版
于是,我们依据图4中的8种嵌入模版可以得到此时与每个嵌入模版所对应的待嵌入序列,见表1。
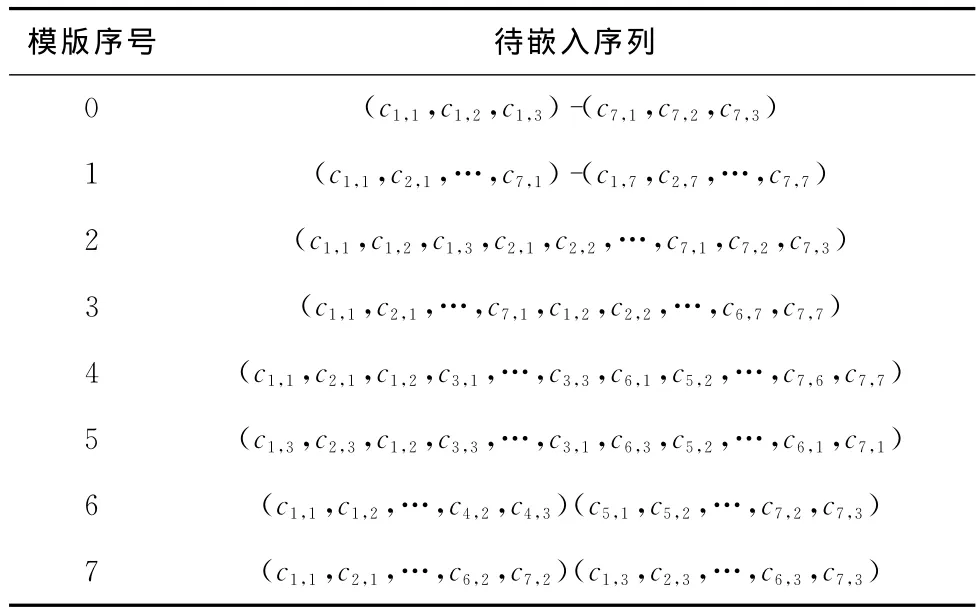
表1 嵌入模版及对应待嵌入序列
1.3 结合矩阵编码和QIM算法进行信息隐藏
本节将针对待嵌入序列c给出一种联合矩阵编码和QIM算法的信息隐藏方法,简称MQL(ME-QIM on LPC)方法。
假设c=(c1,c2,…,cn),秘密消息序列u=(u1,u2,…,uk),其中n和k为序列长度。假设生成矩阵为H=[h1h2…hn],其中hn表示为[h1,nh2,n…hk,n]T。则使用矩阵运算进行信息隐藏的一般办法可以概括如下:
(1)求解
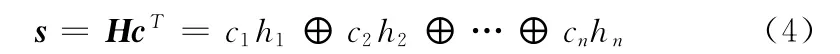
(2)令d=s⊕uT,其中d为k维列矢量。如果d=0,则s=c,此时待嵌入序列c不需要做任何改变。如果d≠0,则需要对c中数据进行修改使d=0。
假设此时c中最多需要修改δ位,则该算法特点可以表述为在n比特中最多修改δ位即可嵌入k比特秘密信息。通过对生成矩阵H的选取,可以根据需要对δ的值进行设定。当H为单位矩阵时,s=cT,δ=k,此时矩阵运算没有对嵌入效率产生任何贡献;当n=2k-1且mod2时,δ=1,此时矩阵运算对嵌入效率的贡献达到最大。本文思想即通过将矩阵运算和QIM嵌入方法结合,从而最大限度的提高嵌入效率。
MQL算法嵌入过程如下:
(2)求得生成矩阵
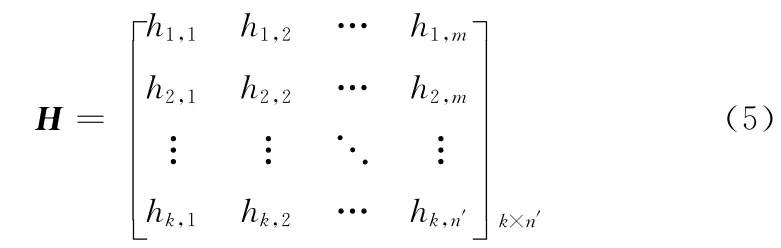
(3)根据式(5)求解s并由d=s⊕uT求得d。假设d=[d1d2…dj…dk]T,1≤j≤k,则
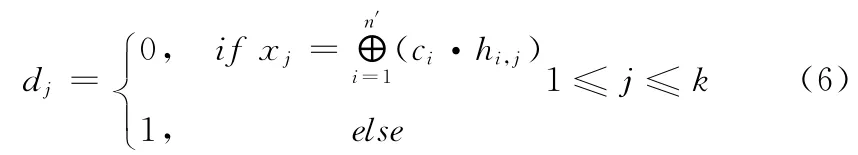
(4)为使d中所有元素均为0,只需根据
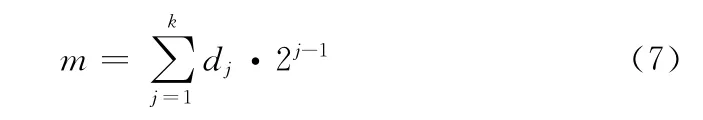
(5)利用QIM方法对cm对应的码字进行修改。
MQL算法解析时,只需要对混沌算法步骤的输出序列c进行以下计算即可获得秘密信息u=(u1,u2,…,uk)
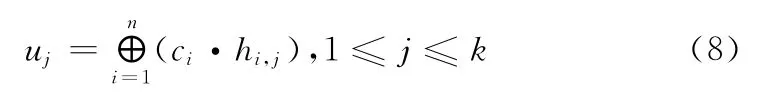
为了分析MQL方法的性能,我们将其与文献[9]中的LPC-QIM方法进行了比较。为此,我们首先定义一些用于衡量矢量替换的参数。
定义2 变化率D(n,k)表示在n个可修改矢量中嵌入k比特秘密信息时,每个矢量被修改的平均概率。假设Echange为嵌入过程中对矢量修改次数的数学期望,则D(n,k)可由下式求得
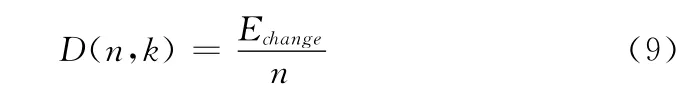
它反映了嵌入过程对宿主信息的影响程度。D(n,k)的值越小,嵌入对宿主造成的影响就越小,嵌入过程就越难以被发现。例如,当D(n,k)=0时,嵌入过程对宿主信息没有造成任何影响,此时隐写绝对安全。于是我们可求得两种方法的变化率为
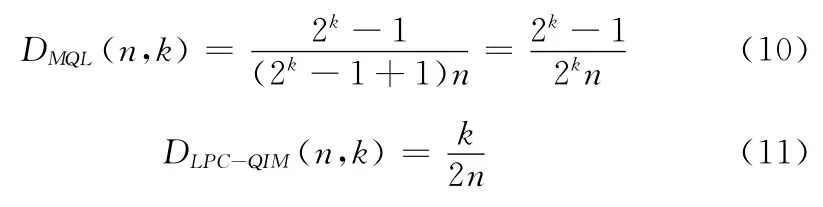
定义3 平均每个待嵌入矢量中嵌入的数据量称为数据嵌入率R(n,k),可由下式求得

它反映了宿主对秘密信息的承载能力。根据R(n,δ)的计算公式我们可以计算两种方法的数据嵌入率
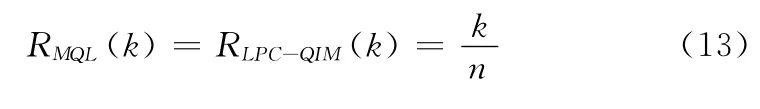
定义4 嵌入效率E(k)表示每次矢量替换所能嵌入的秘密信息比特数。
在矩阵编码过程中k为大于1的整数,所以由式(12)、式(13)及E(k)的定义可得
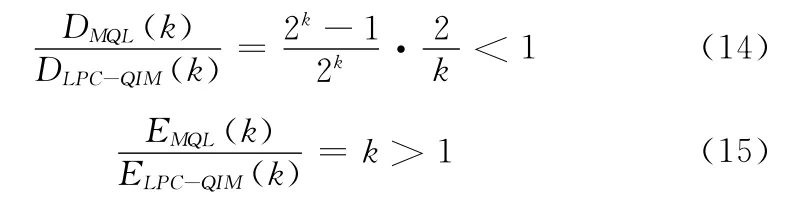
由此可知,MQL方法变化率小于LPC-QIM方法,这说明MQL方法对载体的影响更小;MQL方法的嵌入效率高于LPC-QIM方法,且前者是后者的k倍。
2 结果与讨论
实验从语音质量和检测准确率两方面进行,通过比较MQCL方法与LPC-QIM方法[9]的实验结果,对MQCL方法实际效果进行分析。
2.1 实验样本介绍
本文选择不同发音人的多个语音片段组成语音样本库。所用语音片段样本包含4个种类,分别是中文男声(Chinese speech man,CSM):包含498个语音片段、中文女声(Chinese speech woman,CSW):包含498个语音片段、英文男声(English speech man,ESM):包含500个语音片段、英文女声(English speech woman,ESW):包含499个语音片段,语音片段总计1995个。每个语音片段的时长为10秒,采样率为8000 HZ,对每个采样点用16比特进行量化,用PCM格式存储。
实验中选取了G.729和G.723.1这两种语音编码进行信息嵌入,其基本参数见表2。
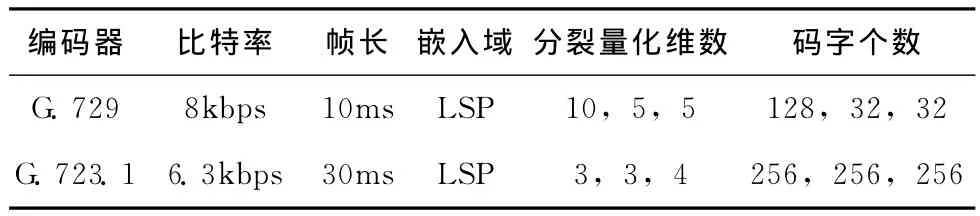
表2 两种语音编码基本参数
实验前首先针对每组样本及每种编码类型生成嵌入率分别为20%、40%、60%、80%和100%的掩密文件。其中MQCL方法采用模版0进行嵌入。使用MQCL方法进行嵌入时,每帧最多可以嵌入2bit秘密信息,而使用LPCQIM方法时,每帧最多可以嵌入3bit秘密信息。为了保证数据嵌入率相等,本实验中使用LPC-QIM嵌入时,在每帧的3个可嵌入位置中随机挑选两个进行嵌入。经过以上处理,我们共得到80组语音数据。
2.2 语音质量分析
为了解MQCL方法对载体语音质量的影响,本文随机挑选了4组语音文件并对其隐写前后的时域幅度谱进行了比较。采用G.729、G.723.1编码时的时域幅度谱分别如图5和图6所示。其中,隐写前后语音文件的幅度谱分别用灰色和黑色表示,嵌入率均为100%。从图中可以看出,即使在嵌入率为100%时,MQCL方法对载体语音文件的影响依然非常小。
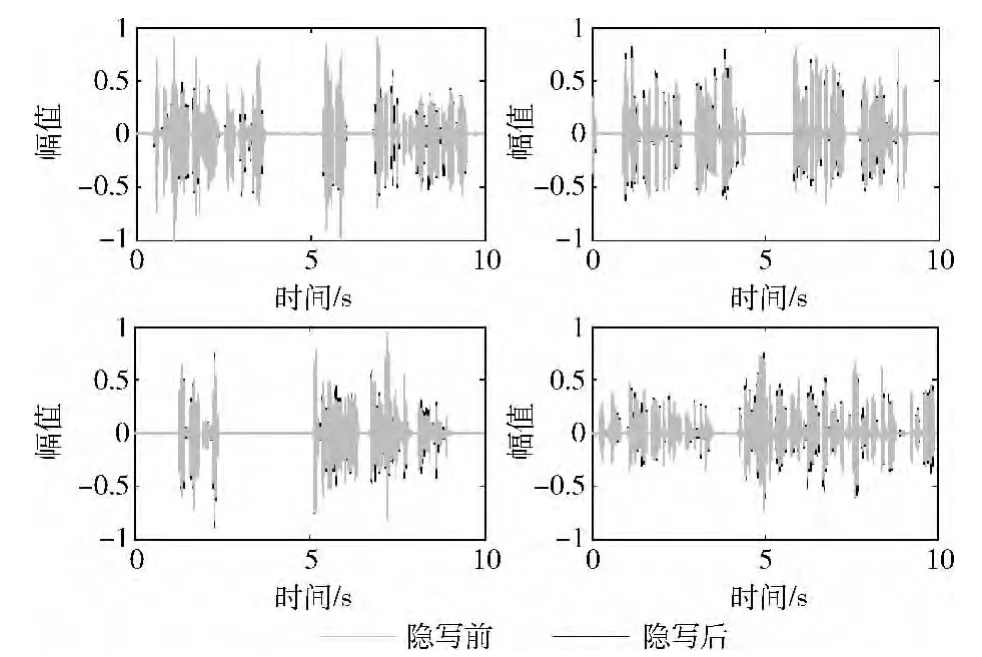
图5 采用G.729编码时的时域幅度谱
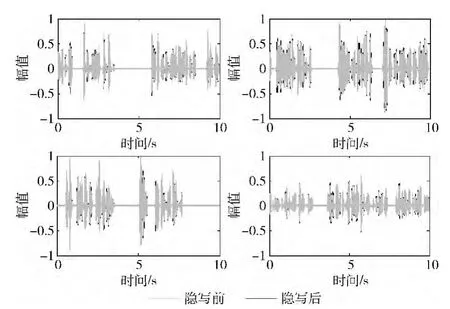
图6 采用G.723.1编码时的时域幅度谱
为了更加客观地评价MQCL方法对载体语音质量的影响,本文将对语音文件进行主观平均意见分(mean opinion score,MOS)评测。MOS为我们提供了一种评价语音质量的量化指标,其评分范围为1到5分,1分代表最低语音质量,5分代表最高语音质量。本实验采用ITU-T提供的自动MOS评分软件进行测试。为了比较MQCL方法与LPCQIM对载体语音质量的影响,本文对使用两种方法进行嵌入后的语音文件进行了MOS评测。为了便于观察,我们以LPC-QIM方法的测试数据为基准计算采用MQCL方法时的MOS变化率,结果见表3和表4。
从表3中可以看出,相较于LPC-QIM方法,采用MQCL方法进行信息嵌入时,20组数据中共有19组数据的MOS值出现了提高。这说明MQCL方法的嵌入过程对载体语音质量的影响更小。从表4中可以看出,20组数据中13组数据的MOS评分出现了提高但不如表3中明显。
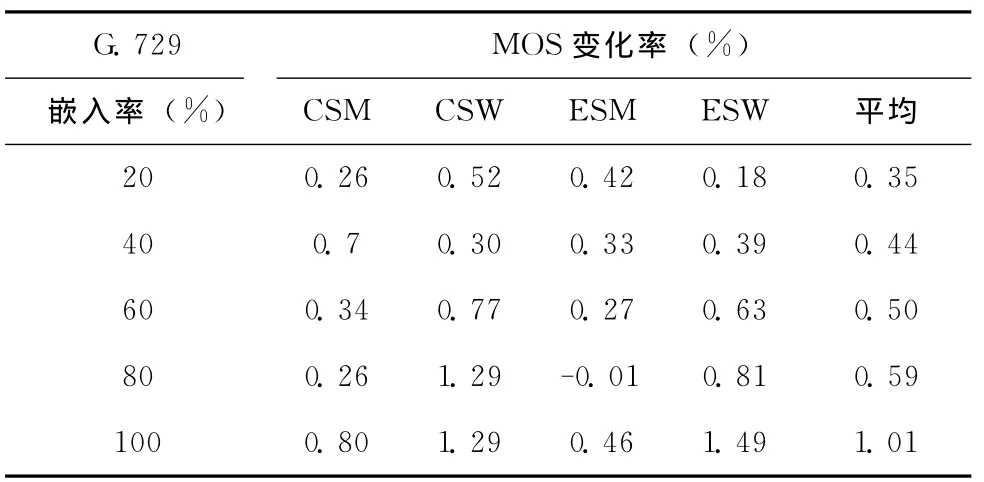
表3 采用G.729编码时的MOS变化率
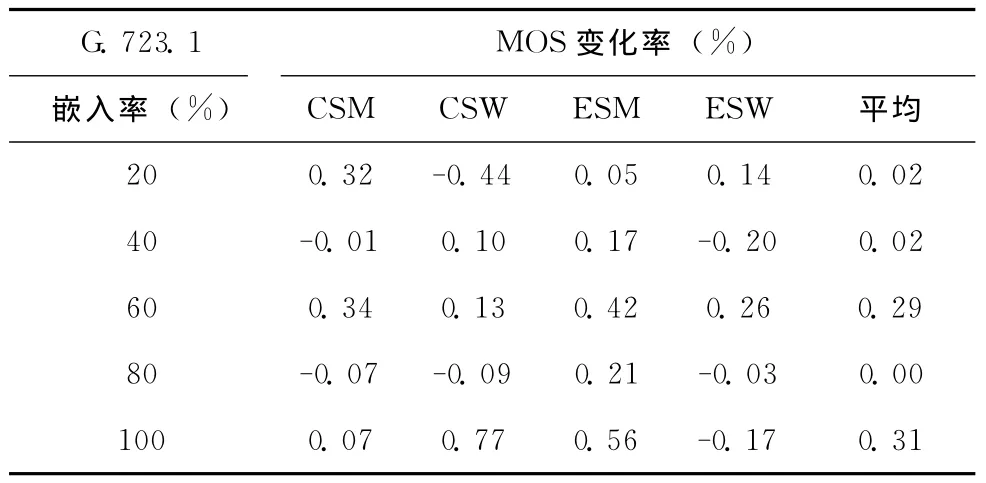
表4 采用G.723.1编码时的MOS变化率
这是因为MQCL优于LPC-QIM方法的本质原因是嵌入效率更高,嵌入过程中对系数修改次数的数学期望更小,因此帧数越多这种优势就越明显,帧数过少时改动次数差别不明显。
由以上分析可知,采用MQCL方法进行信息隐藏时对载体语音质量的影响更小。
2.3 隐蔽性分析
为了比较MQCL方法与LPC-QIM方法的隐蔽性,本文利用差分梅尔倒谱隐写检测方法[10]对两种方法进行了检测。图7为采用G.729编码时的检测准确率,从图7中可以看出MQCL方法被检测出的概率明显低于LPC-QIM方法。
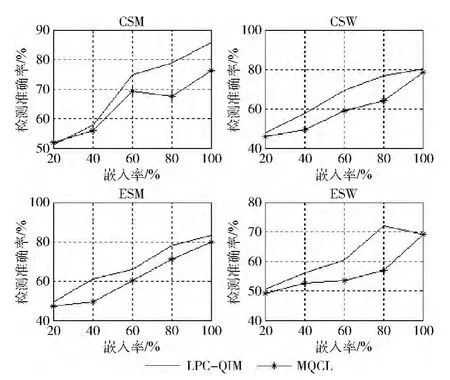
图7 采用G.729编码时的检测准确率
采用G.723.1编码时的检测准确率结果如图8所示。从图8中可以看出当嵌入率较低时检测结果大多集中在50%附近,这是因为使用G.723.1编码后生成帧数相对较少,嵌入率较低时会导致嵌入过程中对系数改动次数过少,致使隐写检测方法无法对其有效检测。当嵌入率较高时,从图8中可以看出LPC-QIM被检测出的概率明显增加,高于MQCL方法。
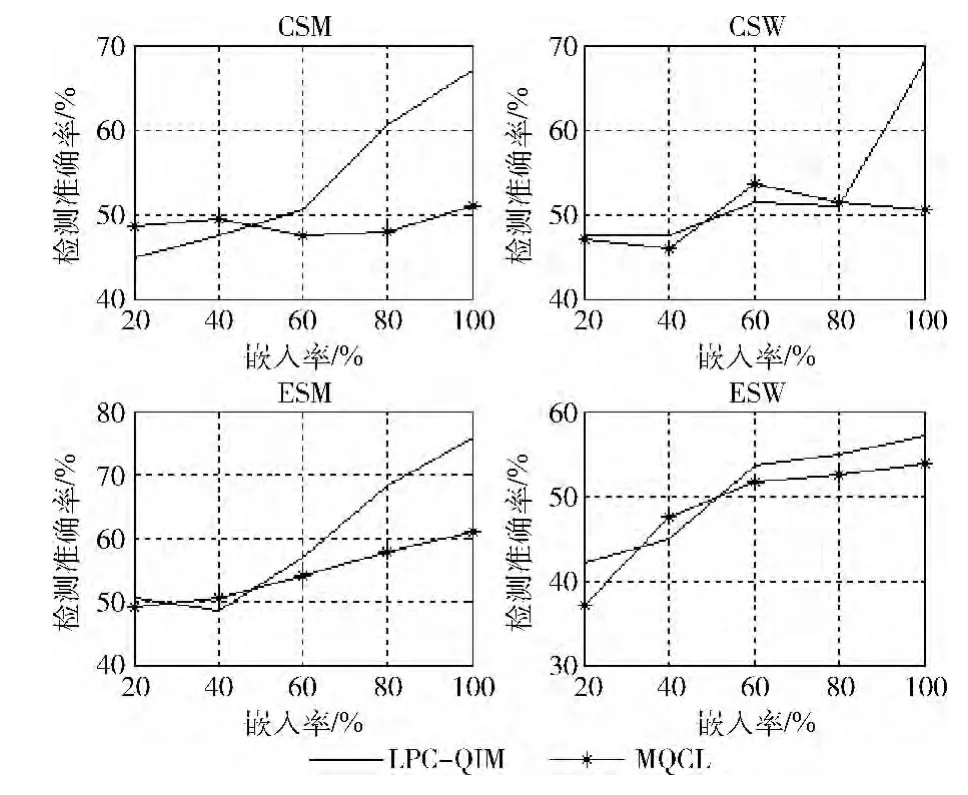
图8 采用G.723.1编码时的检测准确率
由以上分析可知,使用MQCL方法进行信息隐藏时,被检测出的概率更低,表明该方法具有更好的隐蔽性。
3 结束语
本文针对LPC过程提出了一种具有普适性的信息隐藏方法——MQCL方法。该方法通过结合矩阵编码和QIM方法提高信息嵌入效率达到减小失真、提高隐蔽性的目的。MQCL方法的嵌入效率是现有LPC-QIM方法的k(k>1)倍。此外,该方法还引入了可调安全等级的概念,结合混沌理论对嵌入位置及嵌入模版进行选择,从而进一步提高隐写的隐蔽性。实验结果表明,采用MQCL方法进行信息嵌入后语音质量和检测准确率均优于采用LPC-QIM方法的结果。
[1]Tian Hui,Zhou Ke,Jiang Hong,et al.An M-sequence based steganography model for voice over IP[C]//IEEE International Conference on Proceedings of the Communications,2009:1-5.
[2]Liu Lihua,Li Mingyu,Li Qiong,et al.Perceptually transparent information hiding in G.729 bitstream[C]//International Conference on Proceedings of the Intelligent Information Hiding and Multimedia Signal Processing,2008:406-409.
[3]Liu Jin,Zhou Ke,Tian Hui.Least-significant-digit steganography in low bitrate speech[C]//IEEE International Conference on Proceedings of the Communications,2012:1133-1137.
[4]Xu Tingting,Yang Zhen.Simple and effective speech steganography in G.723.1 low-rate codes[C]//International Conference on Proceedings of the Wireless Communications &Signal Processing,2009:1-4.
[5]Huang Yongfeng,Tang Shanyu,Yuan Jian.Steganography in inactive frames of VoIP streams encoded by source codec[J].IEEE Transactions on Information Forensics and Security,2011,6(2):296-306.
[6]Ito A,Abe S,Suzuki Y.Information hiding for G.711 speech based on substitution of least significant bits and estimation of tolerable distortion[C]//IEEE International Conference on Proceedings of the Acoustics,Speech and Signal Processing,2009:1409-1412.
[7]Yargicloglu A U,Ilk H G.Hidden data transmission in mixed excitation linear prediction coded speech using quantisation index modulation[J].Information Security,2010,4(3):158-166.
[8]Huang Yongfeng,Liu Chenghao,Tang Shanyu,et al.Steganography integration into a low-bit rate speech codec[J].IEEE Transactions on Information Forensics and Security,2012,7(6):1865-1875.
[9]Xiao Bo,Huang Yongfeng,Tang Shanyu.An approach to information hiding in low bit-rate speech stream[C]//Proceedings of the Global Telecommunications Conference.IEEE,2008:1-5.
[10]Liu Qingzhong,Sung A H,Qiao Mengyu.Temporal derivative-based spectrum and mel-cepstrum audio steganalysis[J].IEEE Transactions on Information Forensics and Security,2009,4(3):359-368.
猜你喜欢
华人时刊(2022年9期)2022-09-06
小学生学习指导(中年级)(2021年12期)2021-12-30
昆明医科大学学报(2021年4期)2021-07-23
华人时刊(2020年15期)2020-12-14
疯狂英语·新读写(2018年3期)2018-11-29
人大建设(2018年6期)2018-08-16
读与写·教育教学版(2017年10期)2017-11-10
科学中国人(2017年36期)2017-06-09
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
