
一种新词自动提取方法*
2014-02-07 06:18:13李亚松王玉龙
电信工程技术与标准化 2014年12期
李亚松, 王玉龙
(1 北京邮电大学网络与交换技术国家重点实验室,北京 100876; 2 东信北邮信息技术有限公司,北京 100191)
一种新词自动提取方法*
李亚松1,2, 王玉龙1,2
(1 北京邮电大学网络与交换技术国家重点实验室,北京 100876; 2 东信北邮信息技术有限公司,北京 100191)
当前网络语料会不断出现大量新词已经成为一种普遍的趋势,这里面包含大量网友创造的新词,以及一些社会热点形成的新词。同时社交网络产生的社交性语料存在大量口语化、简称和随意的表达。这些都对中文分词的准确性造成了困扰。本文提出了一种新词自动提取方法,旨在能准确快速地在特定的语料里提取新词,生成特定领域词典,更准确地对网络语料进行中文分词。通过从语料中提取候选词,计算候选词的支持度和置信度,通过阈值刷选出新词,从而实现从海量文本中准确且快速的提取新词。
新词提取;支持度;置信度;离散度;GINI指数
随着互联网的快速发展和网民规模不断膨胀,新词大量出现在网络并迅速渗入人们的日常生活,这已经成为一种语言现象。网络舆情监控的一个基本任务就是从大量的网络语料数据中快速地识别大量出现的携带新词的新话题、热点话题、突发事件[1]。同时,在诸如信息检索、自动分词、词典编纂以及机器翻译等众多中文信息处理领域,新词提取的效果,在很大程度上影响着这些中文信息处理领域的效果,由于中文自身的特点,它不像英文那样在词与词之间有明显的空格间隔,如何将不断涌现的新词准确提取出来已经是中文信息处理中至关重要的一步。因此,有效的提取新词,将对提高中文信息处理相关领域的效果起到重要的作用。
文献[2]提到基于监督方法提取候选新词,包括基于隐马尔可夫模型、决策树、支持向量机模型。这些方法一方面需要人工标注的训练语料,一方面模型本身比较复杂,所以难以应用于大规模语料的新词提取。文献[3]公开了一种结合内部聚合度和外部离散信息熵的网络新词发现方法,包括对网络语料库包含的所有文本句子进行切词处理,并将切分出来的所有互不相同的字串作为候选字串;对在网络语料库中出现的频率超过固定阈值的候选字串,计算其内部聚合度和外部离散信息熵,并根据该候选字串的内部聚合度和外部离散信息熵进一步判断候选目标词串是否为网络新词。该技术方案实现较复杂,当判断一个候选字串是否为新词时需考虑两个因素:内部聚合度和外部离散信息熵。当针对于互联网上的海量文本时,该技术方案所产生的计算量较大,并不能快速、有效的发现和提取新词。
因此,如何从海量文本中准确且快速的提取新词,仍是一个值得深入研究的技术问题。
1 方法思路
本文提出的新词自动提取方法基本思路是从语料中提取所有的候选词,再结合候选词的支持度,置信度和离散度筛选出新词。具体如下。
(1)对文本句子进行切词处理,并将其中字数长度不大于S+1的候选词提取出来,然后将提取出的所有互不相同的候选词保存在候选词库中。
(2)计算候选词库中每个候选词的支持度,并将所有支持度大于支持度阈值的候选词构成一个频繁词组。
(3)为频繁词组中的每个候选词构建一个子词组,并将候选词和频繁词组中的所有其它候选词相比较,如果候选词中包含有其它候选词时,则将其它候选词保存在该候选词的子词组中,然后根据候选词和子词组中每个子词在知识库中出现的频数,计算候选词的置信度,当候选词的置信度大于置信度阈值时,则保留该候选词。
(4)最后结合候选词的离散度进行刷选,当候选词的离散度大于离散度阈值时,则候选词是提取的新词。
2 主要流程
根据上面所述的基本思路,本文所设计的新词自动提取方法包括如下步骤。
步骤1:对语料库包含的所有文本句子进行切词处理,可以通过标点符号,将语料库中的所有文本句子分割成多个短句,并将每个短句中字数长度不大于S+1的候选词提取出来,然后将提取出的所有互不相同的候选词保存在候选词库中,其中,S是预先设定的新词的字数长度上限;由于新词的字数长度上限一般为4,所以可以优选S=4。
例如对于短句“小说剧情精彩”来说,当截词窗口的宽度width为1时,所截取的字数长度为1的候选词有小、说、剧、情、精、彩;当截词窗口的宽度width为2时,所截取的字数长度为2的候选词有小说、说剧、剧情、情精、精彩;当截词窗口的宽度width为3时,所截取的字数长度为3的候选词有小说剧、说剧情、剧情精、情精彩;当截词窗口的宽度width为4时,所截取的字数长度为4的候选词有小说剧情、说剧情精、剧情精彩;当截词窗口的宽度width为5时,所截取的字数长度为5的候选词有小说剧情精、说剧情精彩。
步骤2:根据候选词在知识库中出现的频数与相同字数长度的所有候选词在知识库中出现的频数的比值,计算候选词库中每个候选词的支持度,并将所有支持度大于支持度阈值的候选词构成一个频繁词组。
步骤3:为频繁词组中的每个候选词C构建一个子词组Z(C),并将候选词C和频繁词组中的所有其它候选词相比较,如果候选词C中包含有其它候选词时,则将其它候选词保存在候选词C的子词组Z(C)中,然后根据候选词C以及子词组Z(C)中每个子词在知识库中出现的频数,计算频繁词组中的每个候选词C的置信度,当候选词C的置信度大于置信度阈值时,则候选词 C是提取的新词。
例如,当候选词C是“电影院”时,其字数长度n(C) =3,从频繁词组中找到其子词:电影、影院,即候选词C的子词组Z(C):{电影,影院}。
计算候选词C的置信度:
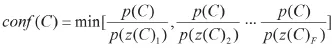
其中,p(C)是候选词C在知识库中出现的频数,F是Z(C)中的子词数,z(C)1,z(C)2… z(C)F分别是候选词C的子词组Z(C)中包含的所有子词,p(z(C)1,p(z(C)2…p(z(C)F分别是z(C)1,z(C)2… z(C)F在知识库中出现的频数,分别是候选词C与其子词的置信度,从候选词C与其子词的置信度中挑选出最小值作为候选词C的置信度conf(C)。
步骤4:从候选词库中找出候选词C的所有左邻字和右邻字,并根据候选词C的每个左或右邻字在所有左或右邻字中的出现概率,计算候选词C的离散度,然后判断候选词C的离散度是否大于离散度阈值,如果是,则说明候选词C是提取的新词。
根据候选词C的字数长度n(C),从候选词库中挑选出所有字数长度为n(C)+1且以候选词C为前缀或后缀的其它候选词,如果候选词C是挑选出的候选词的前缀,则将挑选出的候选词中的最后一个字保存到候选词C的右邻字组中,如果候选词C是挑选出的候选词的后缀,则将挑选出的候选词中的最前一个字保存到候选词C的左邻字组中。
例如,对于候选词“剧情”来说,从候选词库中找到其它候选词“说剧情”、“剧情精”,则将“说”保存到候选词的左邻字组中,将“精”保存到候选词的右邻字组中。
比较候选词C的左邻字和右邻字的GINI指数值大小,并将其中的最小值作为候选词C的离散度。
还值得一提的是,支持度阈值、置信度阈值或离散度阈值可以预先设置,或者根据候选词C的字数长度来分别计算。当根据候选词C的字数长度来分别计算时,支持度阈值、置信度阈值或离散度阈值的计算公式是:

为了进一步提高新词提取的准确度,当候选词C的字数长度为2时,支持度阈值、置信度阈值或离散度阈值还可以在上述计算公式的基础上,进一步调整:,其中,是候选词的字数长度为2时的支持度、置信度或离散度阈值, M2是候选词库中字数长度为2的候选词的总数,α2(k)是第k个字数长度为2的候选词的支持度、置信度或离散度, k是区间[1,M2]范围内的一个整数。
步骤5:将步骤4提取的新词和现有词库进行比较,当所述提取的新词不存在于现有词库中时,所述提取的新词是系统最终自动提取的新词。
3 实验结果
使用中国移动手机阅读的用户评论文本数据(大小为350 MB),运用本文方法进行测试,通过调试支持度、置信度、离散度阈值,最终得到的结果示例如表1所示。
表1为提取出的两字词示例,可见该方法能很容易识别“萧炎”、“若曦”、“林暮”等电子图书中出现的人名,同时也能识别出“腹黑”、“萝莉”、“坑爹”、“泪奔”等网络流行词,在未展示的提取出的新词里,还发现了“菇凉(姑娘)”、“鸡冻(激动)”等网友大量使用的带错别字的新词,以及“威5”、“宫1”这种汉字与数字或英文的组词。从实验结果上看,该方法能识别的新词非常丰富,并且准确性很高。
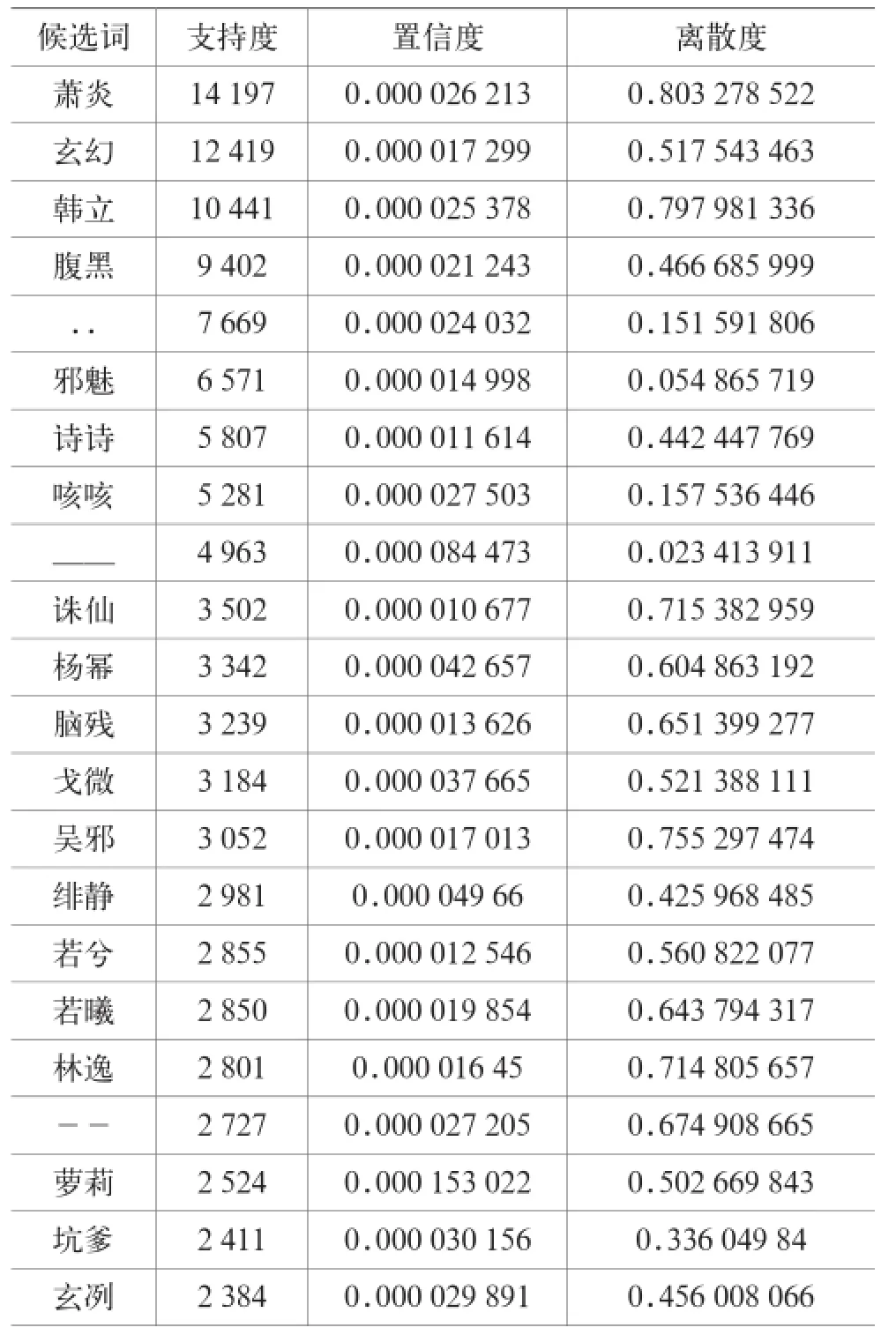
表1 候选词示例

续表
4 结束语
与现有技术相比,本文提出的方法简单可行,且计算量小。在考虑置信度的基础上,还可以进一步结合离散度,从而大大提高了新词提取的准确度。支持度阈值、置信度阈值或离散度阈值还可以根据候选词的字数长度以及所有相同字数长度的候选词的支持度、置信度或离散度来灵活设置,从而使得该方法在各个应用场景中更具有通用性。
[1] 王伟,徐鑫. 基于聚类的网络舆情热点发现和分析[J]. 现在图书情报技术, 2009(3):74-79.
[2] 张海军,史树敏,朱朝勇,等.中文新词识别技术综述[J].计算机科学,2010,37(3):6-16.
CDCC AWARDS数据中心年度大奖揭晓
11月28日,由中国工程建设标准化协会信息通信专业委员会主办,中国数据中心工作组(CDCC)、综合布线工作组联合承办的2014中国数据中心年度论坛在北京新云南皇冠假日酒店胜利闭幕。

论坛中揭晓了“2014年度中国优秀数据中心评选”活动中各大奖项。参评数据中心项目共65个,其中15个数据中心获得中国数据中心标准化示范项目奖,7个数据中心获得中国数据中心标准化示范项目入围奖。相对于2013年度评选,2014年度各大奖项竞争更为激烈,在申报项目总数大大增加的情况下(2013年度为46个,2014年度为65个),获奖项目数量和去年相同。
其中,凭借出色表现,百度M1数据中心获得了数据中心年度能效奖。中国移动国际信息港一期数据中心、中国联通呼和浩特基地数据机房楼A-2楼及油机楼C-2楼提出的基础设施代维服务获得了年度运维奖。国家超级计算机广州中心、京东商城华东云数据中心分别获得了数据中心专业设计奖和数据中心设计理念奖。优秀金融数据中心奖花落中国农业银行河北省分行数据中心、临商银行生产数据中心。云基地深圳盐田港数据中心、Telehouse BDA 数据中心二期工程获得了数据中心施工质量奖。优秀企业数据中心奖在2014年度评选中再度空缺。
评选委员会主席由中国工程标准化协会专家技术委员会委员、中国数据中心工作组组长、中国数据中心专家委员会主任委员钟景华先生担任,评选委员会委员由来自于设计院、行业用户在内的100多位资深专家组成。评选委员会自4月起专门召开了多次会议,商讨评选方案及评估模型。评选以大量的数据采集为依据,以完善的评估模型为基础,在深度分析报告基础上对部分数据中心项目进行现场实际考核,并先后召开了初评会、专家现场答辩会,最终评选出2014年度中国各大优秀数据中心,以确保评选过程完整全面,真正凝聚不同领域内精英的专业智慧。
亨通亮相国际线缆展
近日在宁波举行的2014国际电线电缆及材料设备展上,江苏亨通线缆科技有限公司携综合布线、4G基站、数据中心、电梯电缆、轨道交通用线缆五大解决方案抢滩全球市场,成为展会一大亮点。
亨通线缆是亨通集团旗下一家专业生产和销售线缆产品的高新技术企业。此次参展,亨通线缆通过样品展示、资料分发以及技术人员的现场讲解及交流互动等方式,详细介绍了亨通线缆的最新产品及解决方案,进一步提升了公司品牌的知名度和影响力。同时,该公司还充分利用本次参展机会,与前来参观的客户和经销商充分交流与洽谈,了解同行先进企业的产品特点,以便更好地完善自身产品结构,发挥自身优势。
Polycom推出云媒体框架三大解决方案
日11月25日,Polycom公司再度推出实时会议、云跨界和云媒体中心三大解决方案,以一站式的方式将视频在云技术框架下的应用和功能提升到一个全新高度,给用户带来更大价值,并推动企业云平台的更多潜能。
云媒体解决方案是继实时会议解决方案和云视频解决方案的又一次革命性突破,可以为企业级实时安全会议协作、内部及外部应用以及全面深入的资源和知识管理分享,提供一站式解决方案以及跨界的应用。在知识分享方面,云媒体能够实现企业赋予授权的员工将工作相关的视频上传,以让其他人观看学习。云媒体还能提供在线培训、在线答疑、线上考试、证书颁发等,通过全媒体、嵌入式的应用,将信息嵌入到用户的网站,还可以与企业的OA等内部系统集成,实现资源共享最大化,真正体现云时代的应用和体验。
小米公司采用Avaya技术打造全新客户体验平台
经过严格的筛选,Avaya为小米公司部署了Avaya Aura Contact Center解决方案,涵盖了Avaya Open Queue网络服务、Avaya Aura Workforce Optimization人力优化应用、Avaya Experience Portal,以及统一通信客户端Avaya one-X communicator。Avaya专业服务部门还提供了系统部署和开发支持服务,涉及统一通信客户端与第三方软电话的整合,以及社交媒体的整合,包括小米即时通信系统“米聊”和汇聚了大批米粉的官方社区。
小米公司高级客服总监杨京津说:“与传统的呼叫中心模式不同,小米的客服中心是一个综合了业务、产品和服务的平台,整合了硬件产品、软件产品和售后服务,因此需要一个稳定的、强有力的系统提供保障。Avaya解决方案为我们提供了出色的跨渠道客户体验管理,系统的开放性还为小米的自主创新提供了有力支持。”
爱立信携手IBM开展5G天线设计
爱立信与IBM日前宣布,将合作研究5G相控阵天线设计,使网络能够为客户提供的数据传输速率较现在提升多个数量级。
爱立信与IBM将合作研究利用相控阵天线技术开发原型系统,服务更多移动用户,在同一频段上提供更多的新增服务,同时提供高出今天多个数量级的数据传输速率。这些技术革新实现后,将可以把100个无线接收器高度集成在一张信用卡大小的芯片上,从而极大促进这些技术应用于室内及人口密集城区的高容量小蜂窝网络。
2014年度中国综合布线十大品牌揭晓
11月28日,中国综合布线工作组宣布,“2014年度中国综合布线十大品牌”评选活动正式落幕。最终,康普公司、美国康宁公司、罗格朗中国、耐克森综合布线系统(亚太区)、美国泛达网络、南京普天天纪楼宇智能有限公司、罗森伯格亚太电子有限公司、施耐德电气(中国)有限公司、美国西蒙公司、泰科电子(上海)有限公司安普布线系统等10家企业荣获“2014年度中国综合布线十大品牌”称号。
在当日举行的“2014年度数据中心工程标准化建设年度论坛”上,综合布线工作组组长、中国移动通信集团设计院有限公司数据所副所长张晓微女士揭晓了十大品牌评选活动结果。十家获奖企业的高层代表莅临论坛,并就综合布线市场发展、数据中心布线之道、布线技术创新等话题,进行了交流。
本次论坛活动,由中国工程建设标准化协会信息通信专业委员会主办,中国数据中心工作组、综合布线工作组联合承办。包括协会领导、设计院专家、数据中心领域技术专家、领导厂商专家、新闻媒体等在内的1000名代表出席了本次论坛。
2014年中国|全球光通信最具竞争力企业10强榜单出炉
11月20日,“2014(第八届)中国光通信发展与竞争力论坛暨2014中国|全球光通信最具竞争力企业10强评选活动颁奖典礼(ODC)”在北京隆重举行。ODC论坛由中国通信学会光通信委员会、亚太光通信委员会主办,已经成功举办了8届,影响力已经得到业界同仁的广泛认同。
在今年的评选活动中,华为、烽火、长飞、亨通、DSM等众多企业分别在全球及中国光纤光缆、光传输、光器件和品牌榜单中荣获奖项。
本届论坛围绕“面向下一代光网络”主题,工信部科技委常务副主任韦乐平、中国通信学会副理事长兼秘书长张新生、工信部通信科技委专职常委、亚太光通信委员会主任委员、《网络电信》杂志社主编毛谦、北京邮电大学原校长林金桐、运营商高层代表张成良、唐雄燕、武汉邮科院副院长、中国通信学会光通信委员会主任委员余少华、华为传送网副总裁王丽彪等各企业高层代表发表了各自在不同角度的观点,并在圆桌论坛中与业内同仁展开热烈讨论。
此次评选由NTR网络电信信息研究院、亚太光通信委员会共同主办,由国内通信领域和经济学、管理学、统计学等领域的权威专家组成。各项大奖根据参评企业的生产规模、市场表现、产品性能、售后服务、增长速度和企业管理及文化等方面共73项要素指标进行评选,对参选企业的竞争力进行了客观、系统的分析,为光通信行业竞争力分析提供了参考依据。
New method for the auto-extraction of new words
LI Ya-song1,2, WANG Yu-long1,2
(1 Beijing University of Posts and Telecommunications Networking and Switching Technology, State Key Laboratory, Beijing 100876, China; 2 EBUPT Information Technology Co., Ltd., Beijing 100191, China)
It has been a widespread tendency that large amount of new words are emerging in web text corpus. Among these are many new words created by netizens or arising from social focuses, and are also many colloquial expressions, abbreviations in the social intercourse corpus created by SNS. All the above cases together make it diff cult for words segmentation. In this essay a new extraction method for new words is proposed, aiming to extract new words in a certain corpus, to generate a dictionary and to segment the Chinese expressions more accurately. The new method f rstly extracts candidate words from the corpus, and then calculates its support and conf dence, sifts the new words out, and f nally extracts new words accurately and rapidly from huge text data.
new words extraction; support; conf dence; dispersion; GINI index
TN915
A
1008-5599(2014)12-0083-04
2014-11-01
国家973计划项目(编号:2013CB329102);国家自然科学基金资助项目(No. 61372120, 61271019, 61101119, 61121001);长江学者和创新团队发展计划资助(编号:IRT1049);教育部科学技术研究重点(重大)项目资助(编号:MCM20130310);北京高等学校青年英才计划项目(编号:YETP0473)。
猜你喜欢
作文小学中年级(2022年1期)2022-03-03 08:30:50
核科学与工程(2021年4期)2022-01-12 06:30:22
音乐天地(音乐创作版)(2019年12期)2019-02-09 12:30:40
计算机应用(2018年5期)2018-07-25 07:41:26
快乐语文(2016年32期)2016-04-10 10:47:25
轴承(2015年2期)2015-07-25 03:51:04
语文知识(2014年12期)2014-02-28 22:01:18
数学教学通讯·初中版(2013年9期)2013-04-29 00:44:03
疯狂英语·原声版(2013年2期)2013-03-18 01:14:20
海外华文教育(2013年3期)2013-03-11 16:37:01
