
一种爬虫监控系统的设计与实现*
2014-02-07 06:18:12张军强李炜沈奇威
电信工程技术与标准化 2014年12期
张军强,李炜,沈奇威
(1 北京邮电大学网络与交换技术国家重点实验室,北京 100876; 2 东信北邮信息技术有限公司,北京 100191)
一种爬虫监控系统的设计与实现*
张军强1,2,李炜1,2,沈奇威1,2
(1 北京邮电大学网络与交换技术国家重点实验室,北京 100876; 2 东信北邮信息技术有限公司,北京 100191)
随着互联网爆炸式的发展,网络爬虫的重要性越来越重要。一个搜索引擎搜索结果的数量以及质量在一定程度上取决于网络爬虫爬取结果的质量,而如何能更好的组织这些爬虫也成了一件能影响爬虫效率的事情。随着在服务器上部署爬虫的增加,对一个能够有效管理爬虫监控系统的需求也就越来越紧迫。本文对爬虫监控系统的设计和实现将会给爬虫的管理带来很大的方便。
网络爬虫;监控系统;Heritrix
随着互联网中海量信息的爆炸性增长,通用搜索引擎面临着更新速度、索引规模和个性化需求等方面的挑战。面对这些挑战,主题爬虫应用而生。主题爬虫是指适应特定主题和个性化搜索的网络爬虫,基于主题网络爬虫的搜索引擎已经成为当前搜索引擎和Web信息挖掘的一个研究热点。
通用爬虫的任务是尽可能多的搜集信息页面,而在这一过程中并不在意搜集的顺序和主题,需要消耗非常多的系统资源和网络带宽。主题网络爬虫则是尽可能快的搜集相关主题的网页,然而随着网站系统规模的加大,需要的主题量的增多,部署的主题爬虫也会渐渐增多,这个时候对于这些主题爬虫的监管系统就面临着很大的压力。
本文主要针对现在比较流行的一个爬虫Heritrix进行再设计并实现监控, Heritrix是一个优秀的互联网信息采集工具,高可扩展性,页面抓取能力强,用户可以方便地对其定制开发。
1 相关技术
1.1 Heritrix
Heritrix项目是一个开源的、可扩展的Web爬虫项目,基于Java语言实现。利用其出色的可扩展性,开发者可以扩展它的各个组件,来实现自己的抓取逻辑。Heritrix项目始于2003年,目前有Heritrix 1.14.4和Heritrix 3.x两个主要版本。
1.1.1 Heritrix主框架
Heritrix 3.x的框架主要分为Engine和Component两大部分。Engine是爬虫的主要功能模块,负责实际的抓取任务。Component可以认为是爬虫的Web用户接口,用户可以通过Web界面对爬虫进行管理。Heritrix采用了模块化的设计,用户可以在运行时选择要用的模块。
Heritrix由核心类和插件模块构成。核心类可以配置,但不能被覆盖,插件模块可以由第三方模块取代。因此,本文采用实现了特定抓取逻辑的第三方模块来取代默认的插件模块,以满足抓取需求。
Heritrix的整体结构如图1所示。其中下载控制器(CrawlController)是下载过程的总控制者,整个抓取工作的起点,决定整个抓取任务的开始和结束。每个URI 都有一个独立的线程,它从边界控制器(Frontier)获取新的 URI,然后传递给处理链(Processor Chains)经过一系列处理器(Processor)处理。
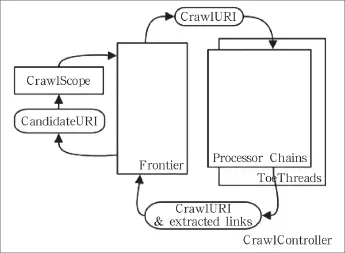
图1 Heritrix运行流程
处理链由多个处理器组成,在处理器里面依次对CrawlURI进行处理,抓取页面,分析页面,存储页面,并将解析到的新链接加入Frontier队列,不断循环,如图2所示。
Processor Chain从Frontier里获取CrawlURI,Processor Chain中的处理器链依次对CrawlURI进行处理,抓取页面,分析页面,存储页面,并将解析到的新链接加入Frontier队列,不断循环。
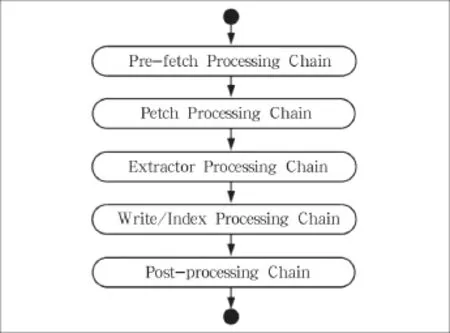
图2 URI运行链
1.1.2 Heritrix处理链
Heritrix处理链由5个部分组成:Pre-fetchChain、FetchChain、ExtractorChain、WriteChain和PostprocessChain。Pre-fetchChain是预处理链,主要用于判断抓取时的一些先决条件,如 robot协议、DNS等。FetchChain主要负责页面的抓取与解析工作,ExtractorChain负责URI的过滤,决定哪些URI可以被加入Frontier。WriteChain是写处理链,它负责数据的存储。Post-processChain负责页面的存储与URI的后续处理工作,并将经过ExtractorChain过滤后的URI加入Frontier。
上述处理链均继承自ProcessorChain类,每个Chain内部又由若干个处理器(Processor)组成。如FetchChain中的主要Processor有FetchDNS、FetchHTTP和ExtractorHTML等。Heritrix中所有处理器均继承自Processor类,Heritrix提供了丰富的处理器供用户选择,用户可以根据实际需求添加或删除已有Processor,也可扩展自己的Processor加入系统。
除此之外,Heritrix还使用了Spring技术,用户通过修改配置文件crawler-beans.xml就可以调整Processor Chain的处理器设置,Heritrix在初始化运行时会读取配置文件,自动装填各个处理器链。
1.2 RestFul模块分析
Rest指的是一组架构约束条件和原则,满足这些约束条件和原则的应用程序或设计就是RestFul。Web 应用程序最重要的Rest原则是客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,适合云计算环境。客户端可以缓存数据以改进性能。
在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有应用程序对象、数据库记录、算法等。每个资源都使用URI得到一个唯一的地址。所有资源都共享统一的界面,以便在客户端和服务器之间传输状态。使用的是标准的HTTP方法,比如Get、Put、Post和Delete。Hypermedia是应用程序状态的引擎,资源表示通过超链接互联。
Heritrix使用的是RestLet(一个轻量级的RestFul框架)。在Heritrix主函数里面构建了一个Component组件,而这个组件可以操作RestLet系统的启动,在主函数里面利用RestLet设置了权限验证,用于对敏感资源的保护,并绑定了IP和端口,用于Web客户的访问,Component里面绑定的EngineApplication是负责用户请求路由的关键。在这个类里面实现了不同的请求交给不同的资源类来处理从而返回结果。
在资源类里面是根据请求的类型(Get、Post)来决定数据表单的处理流向,最后完成对请求的处理。
2 Heritrix多任务模块设计与实现
目前Heritrix爬虫手动配置时,每个爬虫只能运行一个任务,一定程度上造成了资源浪费,需要对其进行一些适应性改造。针对Heritrix功能方面的不足,本文在Heritrix3.1.1基础上,设计并实现了一个全新的任务管理模块。Heritrix将一个爬取任务定义为一个Crawl Job。每个CrawlJob有自己的种子列表、线程、队列和过滤规则等,它们独立运行,不会互相干扰。所有的CrawlJob建立在一个共同的Heritrix Engine上,由Heritrix Engine管控所有任务的运行。
Heritrix中多个CrawlJob可以同时运行,为配合这一机制,增量模块设计了一套数据结构,用于存储每个任务的增量参数与信息。多任务管理模块依照Heritrix 3.x的任务框架,建立了MyEngine->MyCrawlJob模式。MyEngine里存着Heritrix Engine的引用,并有一HashMap<String, MyCrawlJob>型的成员变量Jobs,保存每个CrawlJob对应的MyCrawlJob。MyCrawlJob保存每个CrawlJob的增量参数与信息,并提供增量任务运行过程中要用到的各种方法。
MyCrawlJob有3个重要的成员变量:CrawlJob Job,是对应的真实爬虫任务CrawlJob的引用,通过Job可以直接控制爬虫任务。String JobName是任务名,File JobDir是任务的文件目录。这3个成员变量在增量任务运行的各个阶段都会用到。任务配置模块MyProperties负责读取JobDir中的配置文件crawljob.properties,设置爬虫任务的队列数等。
3 爬虫监控系统的设计
爬虫监控系统实现了动态增加新爬虫源和监控系统网站两方面功能。动态增加爬虫源是在Heritrix主爬虫的Launch流程下完成的,本文在此流程中添加了反射机制,具体流程如图3所示。

图3 Launch流程图
首先,在网页上点击Launch(即启动这个任务),之后启动一个名字叫Launcher的线程,在这个线程的run方法里面得到了CrawlController的实例,并且利用这个实例的request CrawlStart方法启动了爬取任务。
其次,在requestCrawlStart方法里面设置了一个爬取线程的线程池。设置线程池的setupToePool函数中,新建ToePool(线程池)实例,用这个实例的setSize方法新建了线程,并且启动,从而开始了爬取的任务。动态增加爬虫源是在爬虫的运行当中,上传定制任务的配置文件和Jar分组,然后新的爬取任务利用这些上传来的文件进行爬取的过程,流程图如图4所示。
在监控系统的操作界面上传新建任务的文件之后点击Rescan按钮,这个按钮的主要功能就是使Heritrix主爬虫根据上传上来的文件新建爬取任务(CrawlJob)。具体的流程是点击这个按钮之后会触发Heritrix里面的findJobConfigs函数,进而调用这个函数的addJobDirectory子方法,在这个方法里面会根据目录下面的文件实例化出一个CrawlJob,后面任务的启动停止等操作都是利用这个CrawlJob实例来完成的。
至此,动态的新增加任务的主框架基本完成。
新建任务时,在上传配置文件之外还上传了该任务的Jar分组,以形成一个定制的处理器链。爬取任务的URI处理器链形式相同(如图2所示),但是针对不同的任务会有对应的Extractor处理器实现。因此,每个新任务都需要针对Extractor处理器进行改造,之后处理成Jar分组的形式上传。在爬虫主程序运行的时候会通过反射机制从Jar分组里面实例化出Extractor处理器,进而构造出一个处理器链运行新的任务。
以下是关于监控系统网站的设计,监控系统是针对分布在多个服务器上的Heritrix爬虫设计的,是用来减小多个爬虫的监管复杂度,监控框架如图5所示。

图4 实例化CrawlJob流程图
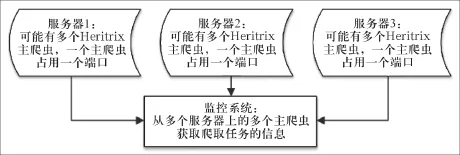
图5 监控系统主框架
通过图5可以看出,监控系统是独立于各个爬虫,通过HTTP来操作各个爬虫的,首先通过各个主爬虫的JSON接口获得多个爬取任务的动态信息,例如爬取的速度,爬取链接的统计等信息,然后利用前端框架展示出来,其次可以利用监控系统向主爬虫发起HTTP请求,由于Heritrix实现了RestFul接口,爬虫是可以处理这些HTTP请求从而完成爬虫的启停等操作,这就是大体上监控系统的框架。
以下是针对上述主体框架而对爬虫进行的改造。首先通过对爬虫的RestLet模块改造,制定JSON接口,以获得各个爬虫的信息。在Heritrix主程序里面启动了一个RestLet Component,该组件绑定了一个EngineApplication资源,其中实现了路由规则,并制定了请求URL的处理类,即Web请求的处理链,其createRoot函数中可以新建自己的规则。本文只要通过HTTP请求获得JSON信息,所以需要创建一个路由规则用于处理这个HTTP请求。
本文制定了一个资源类来获得爬虫的动态信息,在Heritrix里面有一个StatisticsTracker类是用来定义和存储每个CrawlJob的实时动态信息的类,我们只需要在资源类里面持有CrawlJob类的引用,而这个引用里面又会持有StatisticsTracker的引用,便可以获得爬虫任务的实时信息。
资源类里面分别定义了用来处理Get请求、Post请求和Delete请求等其它请求的处理方法,里外还有用来控制是否能访问这些方法的allow方法。用来获得爬虫实时的JSON信息的是Get方法的任务,然而用来处理爬虫控制,例如启停操作请求的就是Post方法的任务,在Post方法里可以获得外部的网页请求,在这个资源类里面的Represent方法是用来响应Get请求,只需要实现这个方法,在里面用JSON的格式打印出爬取任务的实时信息就可以了。至此,JSON接口方面设计完成。
本文基于PHP的Yii框架,搭建了一个Web应用层框架以展示爬虫的动态信息以及动态的添加新任务。由于监控系统应获得爬虫部署的具体服务器,设计一个数据表来存储主爬虫所在服务器的IP地址以及占用的端口号。添加主爬虫界面可实现人工的向这个数据表添加一条主爬虫的记录。监控系统可以通过这个数据表的信息来管理多个爬虫。监控系统通过使用PHP的curl模块向爬虫服务器发出HTTP请求,分别得到爬虫JSON格式的消息,从而用来展示多个爬虫,也可以通过这个模块对各个爬取任务进行启停操作。
除此之外,另一个重要的模块就是向各个主爬虫添加子任务的操作,由于之前的动态增加新爬虫源的实现,现在只需要实现通过监控系统的网站向爬虫服务器上传文件的页面。
因为添加子任务是针对一个Heritrix而言的,所以上传任务文件也应当是针对一个Heritrix主程序,即针对Heritrix的Jobs文件夹上传文件,这个模块是利用PHP的上传文件模块和SSH2扩展模块来实现的,由于SSH2实现了远程文件传输功能,所以非常适合用来实现服务器之间的文件传输。
最后,还可以在Heritrix爬虫里面进行一些更细化的定制化工作,例如每天任务的定时爬取和每个任务每天爬取量的统计,并把这些信息存库,利用一些前端的图形化插件(如HighCharts)进行数据的可视化,从而更直观的查看各个爬虫的运行状况。
简而言之,对于监控系统的搭建,主要难点是在对于爬虫后端的了解及其定制化开发,后端的信息获取接口及处理模块完成之后,Web端只需要完成对后端的调用即可。
4 结束语
本文基于Heritrix 3.1.1设计实现了监控系统,对于具有多个爬虫的系统有很好的监控管理效果,尤其更适用于垂直搜索领域。目前,本文所设计的定制化网络爬虫监测的网站达几十个,包括新浪微博和水木论坛等,稳定运行时间接近1年,采集了大量网页,对爬虫监管统计提供了一个有效的方式,同时为用户提供了大量有价值的数据,在实际应用中取得良好效果。
Design and implement of crawler monitoring system
ZHANG Jun-qiang1,2, LI Wei1,2, SHEN Qi-wei1,2
(1 Beijing University of Posts and Telecommunications Networking and Switching Technology, State Key Laboratory, Beijing 100876, China; 2 EBUPT Information Technology Co., Ltd., Beijing 100191, China)
With the explosive growth of Internet, the importance of web crawler is becoming increasingly important. The quantity and quality of search results of a search engine is depends to some extent on the quality of web crawler's crawling results, and how to organize these crawlers better have become a things can affect the eff ciency of crawler. With the increase of crawlers deployed on the server, the need for an effective management of monitoring system is more and more urgent. In this paper, the design and implementation of reptile monitoring system will bring great convenience to the crawler's management.
Web crawler; monitoring system; Heritrix
TN915
A
1008-5599(2014)12-0074-05
2014-11-01
国家973计划项目(编号:2013CB329102);国家自然科学基金资助项目(No. 61372120, 61271019, 61101119, 61121001);长江学者和创新团队发展计划资助(编号:IRT1049);教育部科学技术研究重点(重大)项目资助(编号:MCM20130310);北京高等学校青年英才计划项目(编号:YETP0473)。
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
保健医苑(2022年1期)2022-08-30 08:39:14
现代信息科技(2021年21期)2021-05-07 02:54:12
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
环球市场(2017年36期)2017-03-09 15:48:21
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
电脑爱好者(2011年11期)2011-06-22 08:20:18
河北软件职业技术学院学报(2010年3期)2010-06-06 07:18:42
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08 07:28:38
