
基于AdaBoost行人检测优化算法的研究*
2014-01-22 05:26刘卫国李亚文
机电工程 2014年10期
杨 英,刘卫国,钟 令,李亚文
(1.东北大学机械工程与自动化学院,辽宁沈阳110819;2.浙江省汽车安全技术研究重点实验室,浙江杭州311228)
0 引言
道路行人识别的核心是利用安装在运动车辆上的摄像机检测行人,从而估计出潜在的危险以便采取策略保护行人[1]。基于统计分类的方法是通过机器学习,从一系列训练数据中得到一个分类器,利用该分类器对输入窗口图像进行识别,并判断是否为行人[2]。基于统计分类方法的优点是鲁棒较好,但是需要很多训练数据,实时性差。目前,基于统计分类方法识别行人主要类型有:神经网络、支持向量机和AdaBoost方法。神经网络方法可以描述极为复杂的模式,已经成功地应用在字符识别和人脸检测上,它在行人的检测上也有应用,但实时性和鲁棒性都不够理想。支持向量机是基于结构风险最小化原理的统计学习理论,该方法比神经网络方法具有更好的泛化能力。Ada⁃Boost是一种分类器组合的策略,它的目的是将一些弱分类器组合成一个强分类器,广泛应用于模式识别和计算机视觉领域[3]。
本研究提出一种基于AdaBoost 的行人检测优化算法,该算法在行人识别分类器训练时,通过在线更新分类器错误率权重,实时调整权重系数,并采用扩展的类Haar 特征,在保证分类器准确率的前提下,降低分类器的级数,减少分类器识别行人所需时间,减少计算的复杂性,满足实时性要求。
1 AdaBoost 权重更新算法的改进
AdaBoost 是一种构建准确分类器的学习算法,该算法包括两个基本问题[4]:一是每一轮循环中训练集上的样本权重如何分布;二是多条弱规则如何合并成为一条准确的预测规则。
1.1 传统的AdaBoost算法
传统的AdaBoost 算法,将训练集中的每一个样本集赋予相同的权重ω。然后,进行迭代运算。该算法根据每次迭代运算中样本集的分类错误率εt,对训练集中的每一个样本集重新赋予一个新的权重值ωt。ωt是一个与εt相关的函数,即分类错误率小的样本集权重值小,反之,分类错误率大的样本集权重值大。
它含两个步骤[5]:
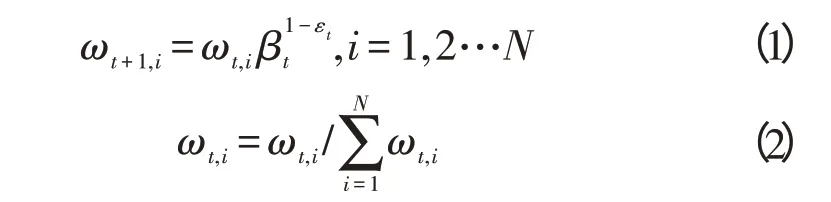
式(1)为样本权重更新过程,式(2)为样本集归一化过程。在传统的AdaBoost 算法中,当单个样本权重更新时,如果前一轮弱分类器分类错误,则那些样本的权重不断增大,结果每轮产生的弱分类器的错误率相对增大,并在最后的加权投票中所占的权重变得很小。
1.2 样本权重与分类错误率的关系
权重与分类错误率密切相关,分类错误率由两部分构成:一是正样本错分率(False Positive Rate,FPR),即包含行人的正样本,没有检查出来;二是负样本的错分率(False Negative Rate,FNR),即不包含行人的样本,检查出来是行人。为了能够准确地描述错分率,权重更新过程应该同时考虑正负样本错分率,因此,将式(1)的扩展为:

式中:k—调节因子,可以调节或改变样本权重。
为了研究样本权重对分类错误的影响规律,正、负样本分布有3 种情况:①正、负样本的分布比较均匀;②正样本分布比较集中,负样本分布比较分散;③负样本分布比较集中而正样本分布分散。为了描述样本权重与分类错误率的关系,本研究进行仿真实验。
本研究将正、负样本的分布通过二维平面内的点集进行仿真分析。用实心点表示正样本,空心点表示负样本。在Matlab 下,由rand 函数随机生成一组点集,如图1所示,每个点集都包含1 000 个数据。点集1中正样本750个,负样本250个,分别仿真3种不同分布情况,在AdaBoost 训练过程中,仅用样本点的坐标(x,y)作为简单特征。为了分析FNR和FPR对新的权重更新方法的影响,本研究使用全局归一化权重方法,并保持k=1不变。
图1 样本点集
通过大量仿真实验得出:
(1)当负样本分布比较集中而正样本分布分散时,适合通过(1-FPR)作为指数修正样本权重,增加算法对正样本的重视度;
(2)对于正样本分布比较集中而负样本分布分散的情况,用(1-FNR)作为指数修正样本权重更适合,增加算法对负样本的重视度;
(3)当正负样本分布比较均匀时,根据需要可使用(1-FPR)或(1-FNR)作为指数来修正样本权重,可以达到相同的效果。
1.3 阈值自适应的权重更新
通过对权重与分类错误率的关系进行实验分析,本研究采用了一种阈值自适应的权重更新算法[6],这种算法的优势在于可以根据需要,限制FNR或FPR的值。在AdaBoost训练过程中,研究者先关注正样本的分类正确率,当FNR降低足够小以后,再注重整体的误差率,尽量降低负样本的错分率。阈值自适应权重更新算法:
(1)初始化,样本权重初始值为1/N,N为样本总数;
(5)全局归一化样本集,进入下一轮训练。
注:f1—正样本的错分率;f2—负样本的错分率。并且f1<f2,k<1。
阈值自适应的样本权重更新优化方法可以在保证整体误差率一定的情况下,在更少的训练轮数内迅速降低FNR的值。
2 扩展的类Haar 特征
目标特征的选取是实现目标检测的重要环节之一。类Haar 特征是行人检测领域中广泛运用的一种常见特征,但由于其易受光照变化等因素的影响,该特征仅适用于静态目标检测。本研究针对行人运动情况和光照情况定义了一个新的对角线特征,该扩展特征能够根据两帧图片的不同提取运动信息从而提高特征的鲁棒性[7]。扩展的类Haar 特征如表1所示。
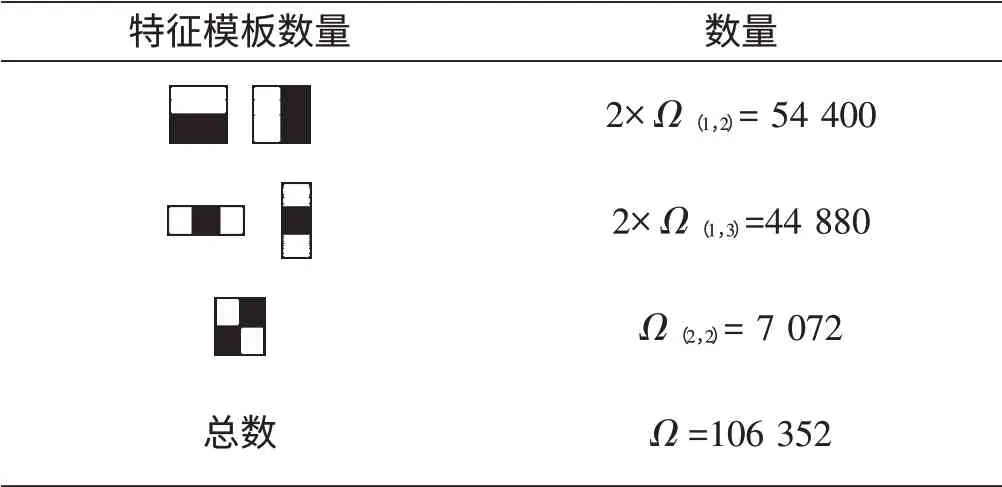
表1 图像(16×32)特征模板数量
本研究利用OpenCV 进行样本特征提取和强、弱分类器的训练,形成用于确定行人候选区域的级联分类器。其中,所设置的训练阶段数为N=24,检测子窗口的大小为16×32,计算得到子窗口类Haar 特征数量如表1所示。所设置的每个阶段分类器的最小命中率为0.995,总的错误警告率0.5。
训练得到的行人分割级联分类器包含24 个强分类器,每个强分类器包含了不同个数的弱分类器,每个弱分类器由一个Haar特征、阈值和指示不等号方向的组成,对于本研究的矩形特征来说,弱分类器的特征值就是上面计算的矩形特征的特征值。训练得到的前5 个强分类器中所包含的类Haar 特征及其数量如表2所示。
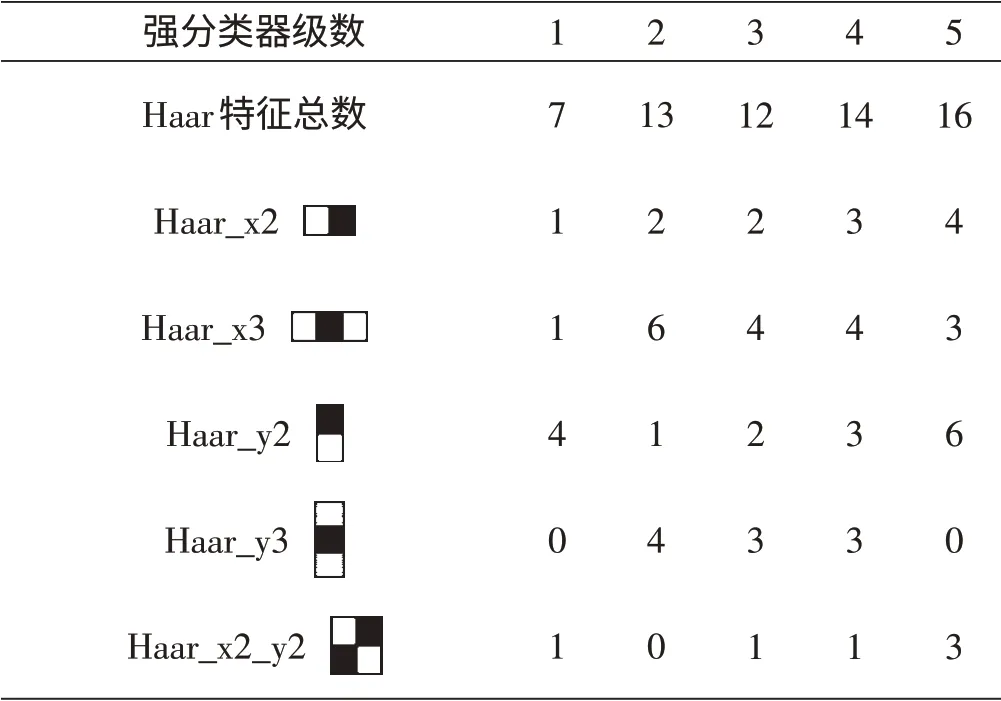
表2 前5个强分类器的类Haar特征数量
3 行人分割分类器的训练
AdaBoost 算法是一种分类器算法,是利用大量的分类能力一般的简单分类器通过一定的方法叠加起来,构成一个分类能力很强的强分类器,再将若干个强分类器串联成为级联分类器完成图像搜索检测。具体训练步骤如下[8]:
(1)给定N个训练样本组成的集合、弱分类器空间H。其中:xi—样本特征向量,yi—对应于行人假样本和真样本,。已知训练样本包含有k个假样本,l个真样本,N=k+l。
(3)对于每个t=1,2,…,T(其中:T—训练次数)进行如下操作:
①归一化权重:

②对每个特征j,训练得到相应的弱分类器hj(x):

式中:pj—不等式的方向,只能取±1;fj(x)—特征值;θj—阈值。
③计算弱分类器的加权错误率εj:
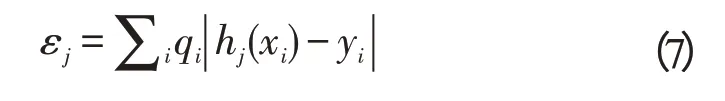
④选择具有最小误差εt的简单分类器ht(x)加入到强分类器中去:

⑤按照这个最佳的简单分类器ht(x),采用前文1.3节中的阈值自适应方法,更新每个样本所对应的权重。
(4)经过T次迭代后,获得了T个最佳弱分类器ht(x),h2(x),…hT(x),可以将它们按照下面的方式组合成一个强分类器:
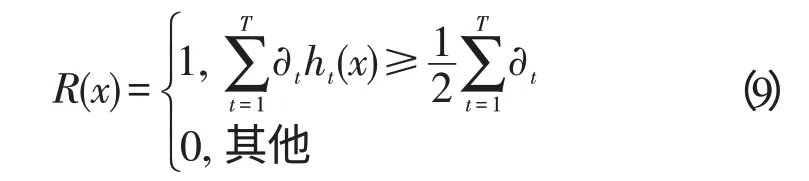
其中:∂t=log[(1-εt)/εt]。
算法训练分类器的特点是:当提取的分类器对于某些样本分类正确时,减小这些样本的权重;反之,则增加这些样本的权重。其结果是,后序训练的简单分类器就会更加强化对这些分类错误样本的训练,根据训练数据,取f1=0.054 3,f2=0.298 1,k=0.333 3。
4 行人识别实验及结果分析
为了验证算法的有效性,本研究将该算法采用Vi⁃sual C++6.0编程实现。行人分类检测系统在2.2 GHz的处理器1.00 GB 的内存,WINDOWS XP 操作系统上运行,分类器训练是在OpenCV软件平台上进行,并将该程序加载训练得到的分类器,实现图像中行人候选区域的在线分割。
训练样本包括两个行人图像数据库样本,第一样本库选取2 700 个来自MIT 数据库的行人图像,第二样本库是来自东北大学校园的1 188 个拍摄图像,训练样本库中部分样本图像如图2所示。训练样本分为真样本和假样本,训练样本是通过手工标定的方法获取,它们的尺寸被统一进行缩放成320×240 大小的图像。
通过在校园内试验分析,该试验得到了较好的效果,基本可以把行人分割出来。

图2 训练样本库中部分图像
本研究采用上述样本分别采用传统和改进两种方法进行分类器离线训练,得到行人识别分类器,再应用采集的118幅图像作为测试集,判断分类器性能,部分图像的行人区域分割结果如图3所示。从图3中可以看出,该算法取得了很好的行人定位效果。

图3 行人检测结果
两种方法的对比试验结果如表3所示。可见改进后的算法实时性好,检测速度快,系统检测一幅320×240大小的图像需要的时间仅为0.308 s。在保证检测准确率的前提下,提高了行人检测的实时性。跟传统的行人分割方法比较,基于AdaBoost 算法行人分割算法在速度方面具有很大的优越性。
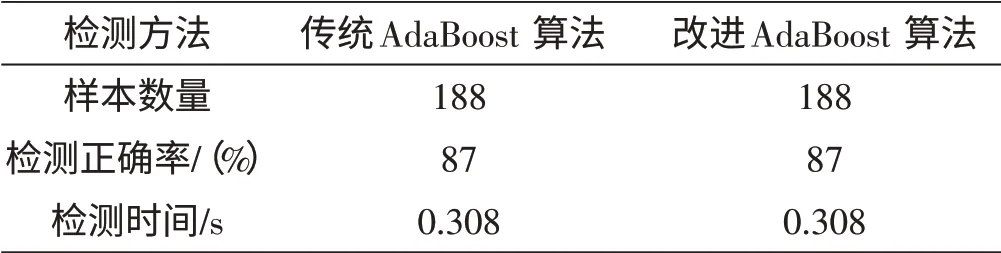
表3 传统与改进AdaBoost 算法对比
5 结束语
本研究提出一种基于AdaBoost 算法的新的行人检测方法,针对类Haar特征易受光照变化等因素的影响,对其进行了改进和扩展,增强了其光照不变性;然后,笔者对AdaBoost 算法加以改进,提出了阈值自适应的权重更新方法,该方法可以在保证整体错分率一定的情况下,有效地限制正样本的错分率;也可以在保证整体错分率一定的情况下,根据实际需要限定正样本或负样本的错分率,明显减少强分类器所需的特征数目,优化分类器结构,降低算法复杂性。试验结果表明:在相同的误检率下,改进的AdaBoost 算法具备更少的检测时间;在相同的训练层数下,改进算法具有更高的识别率。
(References):
[1]贾慧星,章毓晋.车辆辅助驾驶系统中基于计算机视觉的行人检测研究综述[J].自动化学报,2007,33(1):84-90.
[2]常好丽,史忠科.基于单目视觉的运动行人检测与跟踪方法[J].交通运输工程学报,2006,6(2):55-59.
[3]孔凡芝,张兴周,谢耀菊.基于AdaBoost 的人脸检测技术[J].应用科技,2005,32(6):7-9.
[4]吕慧娟,武 澎.基于改进的AdaBoost 算法的人脸检测[J].河南大学学报:自然科学版,2010,40(1):81-84.
[5]SUN Yi-jun,TODOROVIC S,LI Jian.Unifying multi-class AdaBoost algorithms with binary base learners under the margin framework[J].Pattern Recognition Letters,2007,28(5):631-643.
[6]武 妍,项恩宁.动态权值预划分实值Adaboost 人脸检测算法[J].计算机应用研究,2007,24(10):178-184.
[7]黄如锦,李 谊,李文辉,等.基于多特征的AdaBoost 行人检测算法[J].吉林大学学报:理学版,2010,48(3):449-453.
[8]蒋 焰,丁晓青.基于多步校正的改进AdaBoost 算法[J].清华大学学报:自然科学版,2008,48(10):1613-1616.
猜你喜欢
意林(2021年5期)2021-04-18
河南化工(2021年3期)2021-04-16
新课程·上旬(2019年1期)2019-03-18
扬子江(2019年1期)2019-03-08
湖南教育·C版(2017年12期)2018-01-03
读写算·高年级(2017年6期)2017-06-27
小天使·一年级语数英综合(2017年6期)2017-06-07
教师·中(2017年3期)2017-04-20
试题与研究·教学论坛(2016年27期)2016-08-11
读写算·高年级(2015年7期)2015-07-12
