
应用近红外光谱分析技术检测豆粕中掺杂三聚氰胺和尿素的研究
2014-01-22 05:44:52孙丹丹李军国董颖超
饲料工业 2014年19期
■孙丹丹 谷 旭 李 俊 李军国 董颖超
(中国农业科学院饲料研究所,北京100081)
三聚氰胺(melamine),化学名为2,4,6-三氨基-1,3,5-三嗪,是一种重要的氮杂环有机化工原料,在饲料工业中作为粘合剂使用,其含氮量约为66.7%。尿素是一种非蛋白含氮化合物,含氮46.7%,被广泛的应用于畜牧业,可代替反刍动物日粮中的部分蛋白质饲料。两者均为白色粉末,容易染色,混在饲料中不易被发现。饲料厂常用的测定粗蛋白的方法为“凯氏定氮法”,只能测出含氮量,而不能鉴定有无添加违规化学物质,因而这类物质被不法分子添加到宠物食品、动物饲料、饲料原料以及其他食品中。豆粕是主要的植物性蛋白饲料原料,是饲粮中蛋白质的主要来源,广泛用于畜禽、水产及特种动物的饲料中,豆粕中粗蛋白的含量对豆粕的价格有一定的影响。因此,这些非蛋白含氮化合物被非法添加在豆粕中以期提高粗蛋白含量。
农业部公告第1218号规定饲料原料和饲料产品中三聚氰胺限量值定为2.5 mg/kg。自2007年以来,不同的检测方法用来检测低水平的三聚氰胺,如酶联免疫吸附法、荧光偏振免疫分析法、气质联用法、液质联用法等。目前饲料中三聚氰胺的国家检测方法为高效液相色谱法和气相色谱质谱联用法。尿素常用的方法直接比色法、间接比色法、色谱法、中红外光谱法等,我国有鱼粉中尿素测定方法和限量,AOAC方法有动物饲料中尿素的测定方法。但是这些方法大都需要化学试剂,操作过程比较繁琐。
近红外光谱(near infrared spectroscopy,NIRS)分析技术是20世纪80年代发展起来的一种快速、绿色的定性、定量分析技术,近红外光谱区为780~2 526 nm的区域,光谱区与有机分子中含氢基团(O-H、N-H、C-H)振动的合频和各级倍频的吸收区一致,主要用于有机质定性和定量分析。近红外光谱分析技术具有测试简单、速度快、无损检测、对测试人员无专业化要求、多个组分同时测定、重复性好、适用样品范围广等优势,已广泛应用于饲料检测行业,成为一种重要的检测方法。Haughey等对4类掺入了三聚氰胺的豆粕建立定性定量近红外模型,但文中使用的主成分分析方法定性鉴别掺假豆粕有一定的局限性。显微近红外成像技术应用于豆粕中三聚氰胺的检测,对含有1%三聚氰胺的豆粕进行扫描条件优化。冯莉等建立了奶牛精料补充料和奶牛浓缩料这两种料型中尿素近红外模型,证明应用近红外光谱分析技术检测饲料中尿素的可行性,但样品的数量不多,样品的代表性较差。
本实验采用近红外光谱分析技术结合模式识别法鉴别非法掺有三聚氰胺和尿素的豆粕,探讨其作为一种检测豆粕掺假物质存在的快速、无损的绿色分析技术的可行性和实用性。
1 材料与方法
1.1 样本制备
豆粕采自中粮饲料(东台)有限公司,共30批次180个样品,样品于高速旋风粉碎机粉碎30 s,并与相应浓度的三聚氰胺(北京化学试剂公司)和尿素(西陇化工股份有限公司)混合均匀。制备三聚氰胺和尿素的浓度范围为0.1%~5%,共制备214个掺假样本,验证集和校正集的比例为4∶1。
1.2 实验仪器及软件
MATRIXTM-I型傅立叶变换近红外光谱仪(BRUKER,德国),带积分球附件、三维立体角镜RockSolidTM干涉仪,Pbs检测器。OPUS光谱采集软件(version 7.0;Bruker Optik GmbH,Germany),Mat⁃lab(v2013b,MathWorks,USA)和 Unscrambler(version 10.1;CAMO AS,Trondheim,Norway)化学计量学分析软件。
1.3 光谱采集
光谱采集条件为:近红外扫描范围为3 598~12 500 cm-1,分辨率为8 cm-1,扫描次数64次,实验环境温度为(25±2)℃,每个样本重复装样扫描3次。为了减少随机误差,随机抽取样本进行光谱数据采集。
1.4 数据预处理
在原始光谱数据采集过程中常会受到高频随机噪声、光散射、样本不均匀等因素的影响,为消除干扰信号的影响,应用化学计量学对原始光谱数据进行预处理。结合本实验样本状态和建模条件等实际情况,采用平滑、变量标准化、求导等方法对原始光谱数据进行预处理,平滑用来提高分析信号的信噪比,变量标准化用来校正样品间因散射而引起的光谱的误差,导数在消除基线漂移和背景干扰的同时,提高了分辨率和灵敏度。
1.5 建立模型方法
模式识别是一种很重要的化学计量学分类方法,包括有监督模式和无监督模式的识别组成。有监督模式比无监督模式在分类上应用更为广泛,在原料确证、产品质量控制与分析、品质鉴定、真假识别、分类判别等方面广泛应用。本实验比较了三种常见的有监督模式的建模方法,簇类独立软模式(SIMCA)、偏最小二乘判别分析(PLS-DA)和支持向量机(SVM)。
SIMCA(soft independent modelling of class analo⁃gy)是wold于1976年提出的,其思路是为每一类样本建立独立的主成分类模型,然后计算未知样本向量在各类模型的投影距离来判断未知样本归属于哪些类。SIMCA模型的评价指标包括识别率和拒绝率:
拒绝率=拒绝其它类样品个数/其它类样品总个数;
识别率=识别自身样品个数/该类样品总个数。
PLS-DA算法是基于PLS回归模型建立的判别分析算法,通过建立光谱数据与类别特征之间的回归模型,进行判别分析。回归模型得到的样本的预测值不是整数,需要设置阈值以判断样本的归属。本实验中阈值设置为0.5,即预测值与实际值之差的绝对值小于0.5,则判别正确,反之,则判别错误。
SVM由Vapnik提出的,将待解决的模式识别问题转化成为一个二次规划寻优问题,它解决了非线性可分问题。通过核函数和惩罚因子是两个重要的参数来建立最优分隔超平面,最大化两类的分隔边距。四个主要的核函数有线性函数、多项式函数、径向基函数和S型。在本研究中,RFB为核函数来建立SVM模型。
2 结果与分析

图1a 原始豆粕样品近红外光谱

图1b 尿素、掺入3%尿素的豆粕及纯豆粕的近红外光谱
2.1 图谱分析
由图1a可知,在12 500~9 000 cm-1区域,无吸收峰,属于无信息区,为减少数据量提高运算速度,将此区域的数据剔除后再进行处理。图1b是尿素、豆粕和掺入3%尿素的豆粕原始光谱图,在5 066 cm-1处的为最大吸收峰,此处掺假豆粕和纯豆粕之间的区别也最为明显。图1c是三聚氰胺、豆粕和掺入3%三聚氰胺的豆粕原始光谱图,掺入三聚氰胺的豆粕在6 812 cm-1处比纯豆粕多出一个尖峰。尿素和三聚氰胺中主要的含氢基团是-NH2,N-H键在近红外区域的主要吸收特点为:6 812~6 555 cm-1范围内的峰是由N-H键二级倍频的伸缩振动引起的,6 580~6 490 cm-1和6 670~6 580 cm-1是由于NH2一级倍频的对称和非对称伸缩振动引起,N-H的伸缩和弯曲振动在5 080~4 980 cm-1范围内。

图1c 三聚氰胺、掺入3%三聚氰胺的豆粕及纯豆粕的近红外光谱
2.2 SIMCA模型建立与验证
去除样本光谱前段无信息区,以9 000~3 598 cm-1光谱范围预处理数据作为变量,进行主成分分析,验证方法为交叉验证。图2是对所有校正集的样品进行主成分分析得到的得分图,掺假物浓度较高时,掺假豆粕可与纯豆粕区分开,但掺假物浓度较低时,纯豆粕和掺假豆粕有一定的重叠。根据SIMCA原理,分别对校正集中纯豆粕、掺入尿素的豆粕和掺入三聚氰胺的豆粕建立主成分分析模型,然后对预测集样本进行分类。在显著性水平为5%时,分类结果见表1,并比较了原始光谱数据和不同预处理方法对模型分类结果的影响。
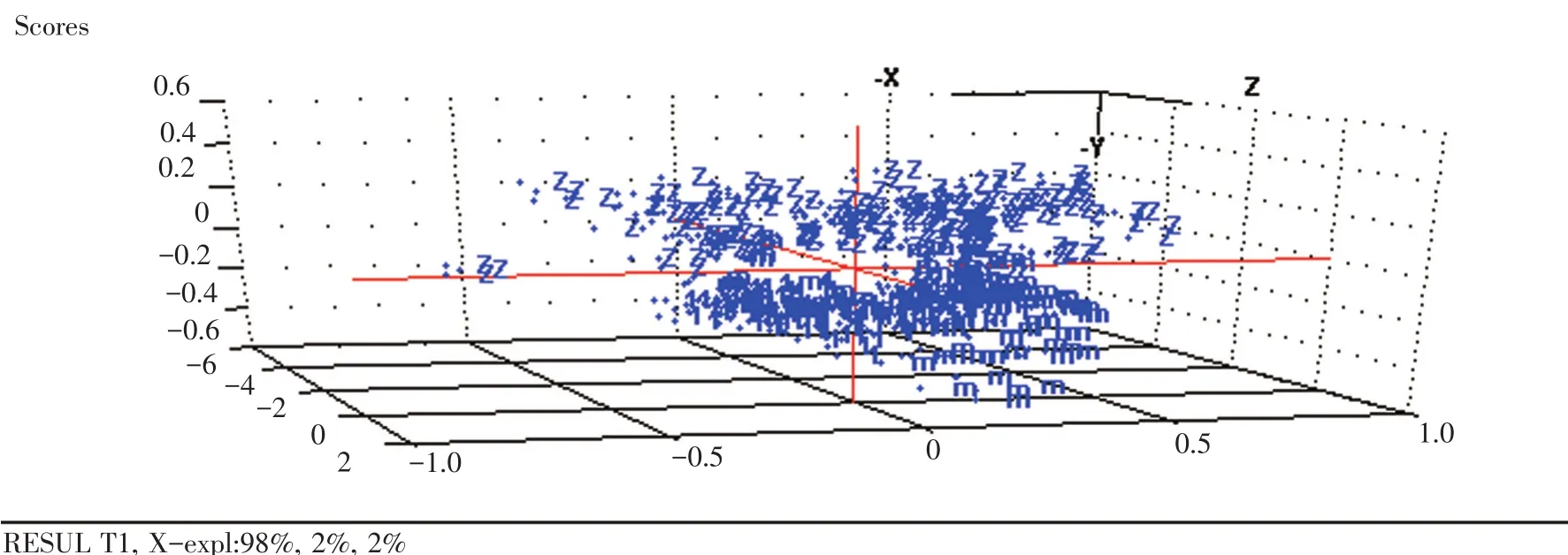
图2 豆粕样品主成分得分
SIMCA模型是纯豆粕、添加三聚氰胺的豆粕和添加尿素的豆粕各自建立独立的主成分类模型,从表1可以得出,每个主成分模型对自身类的识别率较高,但拒绝率较低,说明这三类模型有一定程度的重叠。在纯豆粕主成分模型中,含有低浓度的三聚氰胺和尿素与纯豆粕的光谱相似度极高,被误判为纯豆粕类。在掺有三聚氰胺的豆粕主成分模型中,纯豆粕和含有低浓度尿素的光谱与含有低浓度三聚氰胺的光谱相似度极高,因而被误判为掺有三聚氰胺类,导致识别率高,而拒绝率很低。在掺有尿素的豆粕主成分模型中也是如此。在SIMCA方法中,每个类的模型都是独立的,提取主成分时只能反映出有限的鉴别信息。当多维数据不同类中的子空间都非常接近时,由于类之间不必要的重叠,从而存在产生非优化鉴别模型的危险。与SIMCA方法相比,用一阶导数9点平滑的预处理方法,只对纯豆粕进行主成分分析得到的结果更好,其模型识别率为92.2%,拒绝率为88.5%。
2.3 PLS-DA模型的建立与验证
在9 000~3 598 cm-1光谱范围内,分别对掺入三聚氰胺的豆粕和掺入尿素的豆粕的校正集样本进行PLS回归,即令纯豆粕样本的值为0,掺入三聚氰胺的豆粕样本值为1,掺入尿素的豆粕样本值为1,分别建立纯豆粕样本与掺入三聚氰胺样本和纯豆粕样本与掺入尿素样本的PLS回归模型,并采用交叉验证,用验证集样本对建立的模型进行外部验证。验证集样本分类标准为:Y>0.5,且偏差<0.5,判定该样本属于掺假样本;Y<0.5,且偏差<0.5,判定样本属于纯豆粕;当偏差>0.5,该判别模型不稳定。本研究中,各验证集样品的偏差均小于0.5,校正集和验证集的准确率如图2所示,在三聚氰胺模型中,当预处理方法为一阶导数9点平滑时(图3),校正集准确率为96.9%,交互验证准确率为96.1%,验证集准确率为95.3%,模型的性能最好;在尿素模型中,各模型的预测准确率大于校正集准确率,这是由于验证集选择的样本尿素质量浓度比校正集高,当预处理方法为变量标准化+5点平滑时,校正集准确率为94.5%,交互验证准确率为93.8%,验证集准确率为94.2%,模型的性能最好。
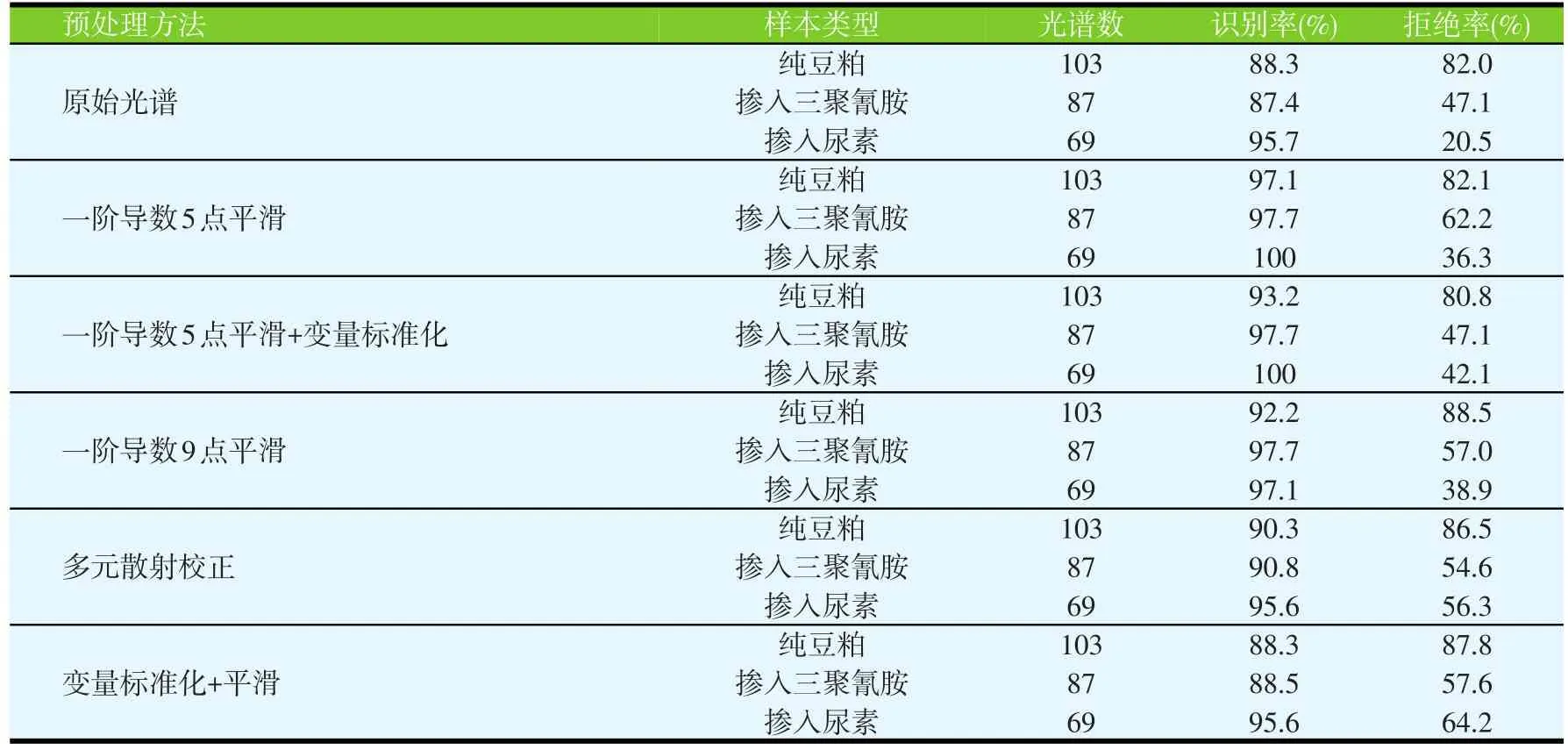
表1 不同预处理方法的SIMCA模型对判别分析结果的影响

图3a 预处理为一阶导数9点平滑时三聚氰胺模型校正集结果

图3b 预处理为一阶导数9点平滑时三聚氰胺模型验证集结果
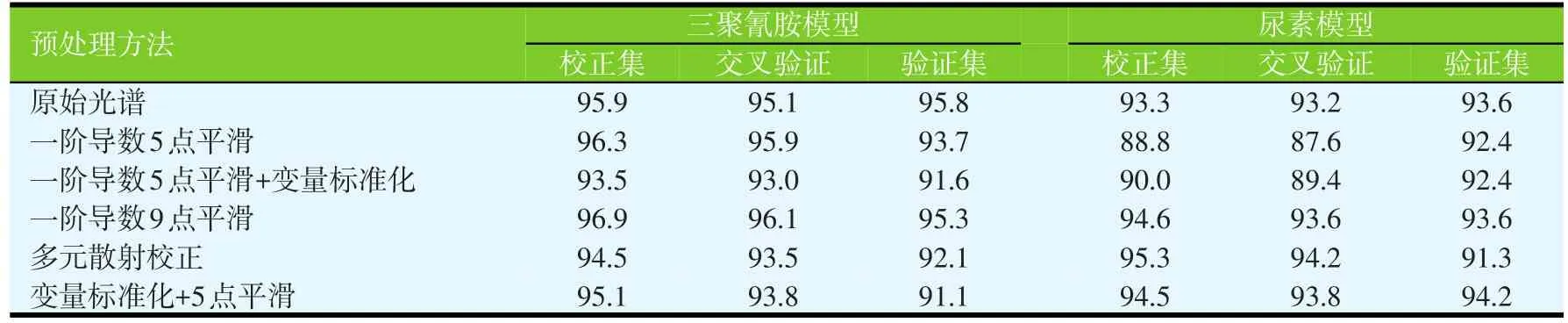
表2 不同预处理方法的PLS-DA模型判断准确率(%)
2.4 SVM模型的建立与验证
在本研究中,SVM方法用于鉴别三个类,是多分类的问题。多分类问题可以转化成二分类方法。纯豆粕为0类,掺入三聚氰胺的豆粕为1类,掺入尿素的豆粕为2类,预测结果用预测值减真实值表示,结果为0时表示判断正确,结果为其他值时,样品归属判断错误。目前,没有系统的方法来选择核函数,但是,与其他核函数相比,径向基核函数作为非线性核函数能够减少计算复杂度,处理光谱与目标属性的非线性关系。因此,本研究使用RBF作为SVM的核函数。所建SVM模型准确率见表3,预处理方法为变量标准化+5点平滑时,训练集和测试集准确率最好,分别为100%和98.1%。

表3 不同预处理方法的SVM模型判断准确率(%)
综合SIMCA、PLS-DA和SVM方法建立的判别模型,可以得出SVM建模方法得到的结果是最好的,PLS-DA其次,SIMCA最差。Guo Tang等应用近红外光谱法检测鱼藤酮制备中的添加剂甲胺磷,比较了SIMCA、PLSDA、ANN和SVM这几种有监督模式识别技术,方法优劣顺序与本研究是一致的。
3 结论
利用近红外光谱分析技术检测豆粕中的掺假物质三聚氰胺和尿素,结合三种有监督模式识别技术分别建立了掺假浓度为0.1%~5%的判别分析模型。近红外光谱预处理方法影响模型的判别精度,选择合适的处理方法以扣除干扰信息提取出有用的信息。SVM是检测掺假豆粕的一种有效方法,能得到相对满意的判别准确度,而SIMCA和PLSDA判别准确度相对较差,这说明SVM方法具有较好的适应性和灵活性。

图4a 预处理为平滑+变量标准化时训练集结果

图4b 预处理为平滑+变量标准化时测试集结果
研究结果表明采用近红外光谱分析技术和判别分析法相结合为豆粕中非蛋白氮的快速鉴别分析提供了一种有效的筛选方法。
(参考文献22篇,刊略,需者可函索)
猜你喜欢
中国化肥信息(2022年2期)2023-01-02 12:17:29
中国化肥信息(2022年8期)2022-11-30 06:20:14
装备制造技术(2020年4期)2020-12-25 05:26:14
今日农业(2020年13期)2020-12-15 09:08:51
当代水产(2019年11期)2019-12-23 09:03:54
当代水产(2019年7期)2019-09-03 01:02:18
当代水产(2019年6期)2019-07-25 07:52:10
中国化肥信息(2018年4期)2018-08-23 09:11:10
中国化肥信息(2018年2期)2018-08-23 09:09:16
河南畜牧兽医(2017年8期)2017-11-24 03:21:13
