
利用优化的DBSCAN算法进行文献著者人名消歧
2014-01-16 01:09:24任景华
图书馆理论与实践 2014年12期
●任景华
(1.武汉大学新闻与传播学院,武汉430072;2.昌吉学院中文系,新疆昌吉831100)
利用优化的DBSCAN算法进行文献著者人名消歧
●任景华1,2
(1.武汉大学新闻与传播学院,武汉430072;2.昌吉学院中文系,新疆昌吉831100)
人名歧义;人名消歧;DBSCAN;文献著者
通过对文本聚类算法DBSCAN算法优化对文献著者人名进行消歧,结果表明,相对标准文本聚类算法来说,优化后的算法能取得更好的人名消歧效果。
人名歧义是一种身份不确定的现象,指的是文本中具有相同姓名的字符串指向现实世界中的不同实体人物。该现象普遍存在于文献数据库与网页中,即不同的用户拥有同一姓名的现象。其中,文献著者歧义是人名歧义的一种,如在文献数据库中查询某研究者所发表的文章时,现有的系统将会把与该研究同名的作者的所有文章返回,这样会使得用户对返回结果产生混淆。因此,对文献著者进行人名消歧,不仅可以帮助用户搜索由特定作者撰写的所有文章,而且也能排除其他同名作者的文章。
聚类是人名消歧中非常关键的一项任务,即将指向实际生活中同一个人的文档聚为一类,于是,文本聚类技术是当前人名消歧义的主要方法。常用的聚类方法有基于层次、基于密度与基于网格的聚类方法。已有的相关研究大多集中在如何探讨选取特征以此实现人名消歧,而对通过优化文本聚类方法以此来实现人名消歧探讨较少。DBSCAN算法是一种典型的基于密度文本聚类算法,且在人名消歧中已取得较好的实验效果。所以,本文通过标准DBSCAN算法进行优化,以此提高文献著者人名消歧的性能。
1 国内外研究现状
现有的消歧方法几乎都是将问题转化为机器学习[1]的相关分类和聚类问题。其中,基于分类思想的相关研究有Huang等[2]利用Online-SⅤM学习算法计算量文献之间相似度,再用DBSCAN聚算法实现作者消歧。该类方法虽在进行文献著者消歧有较高的准确度,但需人工构建训练集,面对海量数据集进行人工标注几乎是不可能完成的,从而限制了该方法在文献著者消歧中的应用。
利用聚类思想进行人名消歧的相关研究有:杨欣欣等[3]针对现有很多基于特征的人名消歧方法不适用于文档本身特征稀疏的问题,提出一种借助丰富的互联网资源,使用搜索引擎查询并扩展出更多与文档相关特征的方法;章顺瑞等[4]利用层次聚类算法对新闻语料中的中文人名进行了消歧;王英师[5]探讨了浅层语义分析特征在人名消歧义作用的基础上,根据网页的主题相关性和名字上下文噪音提出一种基于主题模型LDA和上下文摘要聚类相集合的Web人名消歧方法。宋文强等[6]尝试了层次、K-means、AP三种不同的聚类消歧方法,并分析了各个聚类方法的优缺点。
因聚类方法不需要训练数据,实用性较高,是当前人名消歧的主流方法。以上研究主要从特征选择方面对人名消歧问题进行了研究,没有对聚类方法进行优化。基于此,本文通过改进DBSCAN以此提高人名消歧的实验效果。
2 DBSCAN算法优化
2.1 传统的DBSCAN算法
DBSCAN(Density-Based Spatial Clustering of ApplicationswithNoise)算法是一种基于密度的算法,[7]即通过采用迭代查找的方法,查找到所有直接密度可达的对象,也就是找到各个簇包含所有密度可达的对象。具体方法如下。(1)检测数据库中没有被检查到的对象P,如果P未被处理,则将其归入某个簇标记为噪声点,再次检查其领域EPs。若该邻域中包含的对象小于MinPts,建立新簇C,将EPs中所有点加入该簇中。(2)检查C中所有尚未被处理的对象q的邻域EPs,若EPs包含的对象不少于MinPts个,将该领域中还未归入到其他簇的对象加入到C中。(3)重复步骤2,继续检查C中未被归类的对象,直到无新的对象加入到类簇C中为止。(4)重复步骤1-3,直到所有对象都能加入到某个类簇或者被标记为噪声数据。
该算法的主要优点在于能发现任意大小形状的类簇,并且其聚类效果受到噪声点的影响比较小。但是,在数据量较大时该算法对主存的要求比较高,算法受到全局参数MinPts和EPs的影响;若参数选择不当,聚类质量将降低;对于不均匀的数据集,由于参数MinPts和EPs是全局的,聚类的质量也不理想。
2.2 优化后的DBSCAN算法
本文通过对DBSCAN算法初始参数选择的优化,把对算法中EPs值的确定转换为用户对数据中噪音水平的估计,使参数的决定更具有客观性,从而能够在大容量数据集中实现人名消歧。其中,MinPts与EPs值的确定参见如下流程:
3 实验及结果分析
3.1 实验数据集
本文的数据集是通过爬虫程序从CNKⅠ(中国知网)数据库中采集并经过进一步的处理获得的数据。共采集了五所高校在CNKⅠ数据库中22年的文献,其相关文献数见表1所示。其中,本文数据采集方式为:以这五所高校名为机构名,时间限定在“1990~2012”年,然后获得每篇文献的英文标题、英文作者、英文关键词、英文摘要信息。最后,将所采集到的数据导入MySQL数据库中。
鉴于本文只对五所高校教师做著者消歧,数据中重名信息量太少,为了更好地验证本文实验结果,将数据库中的文献作者名的拼音进行人名缩写,从而得到人名缩写数据集。在很多情况下,若两位作者的英文名缩写相同,则认为二者是同名,如“Li Ping”与“Li Peng”属于同名作者。由于“同缩写者”的个数要比同名者的个数多,这样就提供了更丰富的数据集合,更能有效地验证人名消歧的算法。人名缩写数据集合中的部分统计信息见表2。3.2实验过程

表1 五所高校分别在CNKⅠ数据库中检索到的文献数

表2 人名缩写数据集合的部分统计信息
文本预处理是进行文本聚类的重要步骤。先对每篇论文的记录(即英文标题、英文摘要与英文关键词)进行分词、英文词干化、去除停用词等操作,将每篇论文表示为向量形式。然后,在此工作基础上,再进行文本特征表示与文本之间的相似度计算。
(1)文本特征表示。采用向量空间模型对文档特征进行表示,利用所选取的特征将文档形式化为n维空间向量,空间中的每一维表示选取的特征词,其表示形式参见公式1所示。其中,wi表示第i个特征的权值,n表示特征向量维数。本文采用TF-ⅠDF值[6]来计算特征词的权重值。使用向量空间模型表示文档可极大地提高文档可计算性,这也是向量空间模型在知识表示上的一个巨大优势。

(2)文本相似性计算。分别将每条文献数据的title、keywords、abstract三字段进行向量化。首先将文档集分成只包含title或keywords或abstract字段值的三组文档集,再按照文本信息特征词建立的过程分别对三组文档集进行特征词提取、生成倒排文件索引、建立特征向量,从而使得每篇文章分别由title、keywords、abstract三个字段的向量进行表示。因此,两文章的相似性就转化为对加权合并后的三向量之间的相似性。文档之间的相似度定义如公式2所示:
sim(D1,D2)=α×simtitle(D1,D2)+β×simkeywords

其中,simtitle(D1,D2)、simkeywords(D1,D2)、simabstract(D1,D2)分别表示两文档中title、keywords与abstract向量之间的相似性,本文分别利用欧式距离与余弦值计算两向量之间的相似性。α、β表示权值,本文将其值分别设置为0.5、0.3。
(3)人名消歧聚类方法。将消歧聚类问题定义为:用P表示一篇文献,PA表示作者名为A的所有文献集合{p1,p2,……}。其中,属于第i个名为A的作者的文献子集为Ci={pk1,pk2,……},则人名消歧义的任务就是将文献集合PA正确地划分为C1,C2……Ck。本文主要采用改进后的DBSCAN算法来实现人名消歧义,其具体实现过程如下。
输入:同一人名(即人名缩写形式相同)的N个待分类的文档
输出:K个不同人物个体的文档集合D1,D2...Dk
①确定EPs及MinPts参数值
1)取MinPts=4,首先构建描述数据对象集合的第4近邻距离图,然后去EPs略低于噪音水平百分比的值,最后再按照标准DBSCAN算法实现聚类;
2)利用各聚类结果中的和对象来构建最小生成树;
3)取MinPts=1,EPs为各个聚类结果所构成的最小生成树的最大边值,再次按照DBSCAN算法进行聚类。
②获得直接可达的聚类
1)将每个文本作为数据点,遍历所有数据点,判断当前数据点是否是核心点,且成为核心点需满足的条件:大于或者等于MinPts个点到该点的距离小于EPs。
2)计算其他各点到当前点的距离,如果距离小于EPs,则将当前点归并到指定点所在的类,并计数,如果数量大于MinPts,则当前点可作为核心点,把当前点及与该点归入一类的点标记为已分类。
3)对所有直接可达的聚类进行合并,找出间接可达的聚类,即对(2)中聚类结果进行合并,如果两个类之间有交集,则合并为一类。
4)重复3)直至分类稳定,即得到最后结果。
5)输出代表K个不同人物的文档集合。
3.3 实验结果评测与分析
(1)实验结果评测。为评价不同聚类方法在人名消歧方法中的表现,采用了信息检索与文本聚类分析中的评测方法,如准确率(Precision)、召回率(Recall)、F1值(F-measure)与纯度(Purity)[6]来对最终实验结果进行评测。其中,表3与表4分别表示基于余弦距离公式的优化后DBSCAN算法与标准DBSCAN算法对“Huang L”的人名消歧效果。经过对两表中相关评测指标对比分析可知,针对缩写名“Huang L”来说,优化后DBSCAN算法的消歧效果优于标准DBSCAN算法。另外,本文的整体实验效果参见表5、表6。

表3 基于余弦距离公式的优化DBSCAN算法对“Huang L”的人名消歧效果
(2)实验结果分析。①从表5可以看出,针对人名消歧效果来说,优化后的DBSCAN算法的实验效果优于标准的DBSCAN算法。同时,由表6可以看出,优化后的DBSCAN算法在运行效率上也有显著提高。另外,针对同一欧式距离计算公式,优化的DBSCAN算法运行时间比标准DBSCAN算法相比降低了20%左右。同时,内存消耗上优化的DBSCAN算法运行时间与标准DBSCAN算法相比减少约17.8%。针对同一余弦距离计算公式,优化后的DBSCAN算法运行时间比标准DBSCAN算法降低18%,且内存消耗降低了25%。
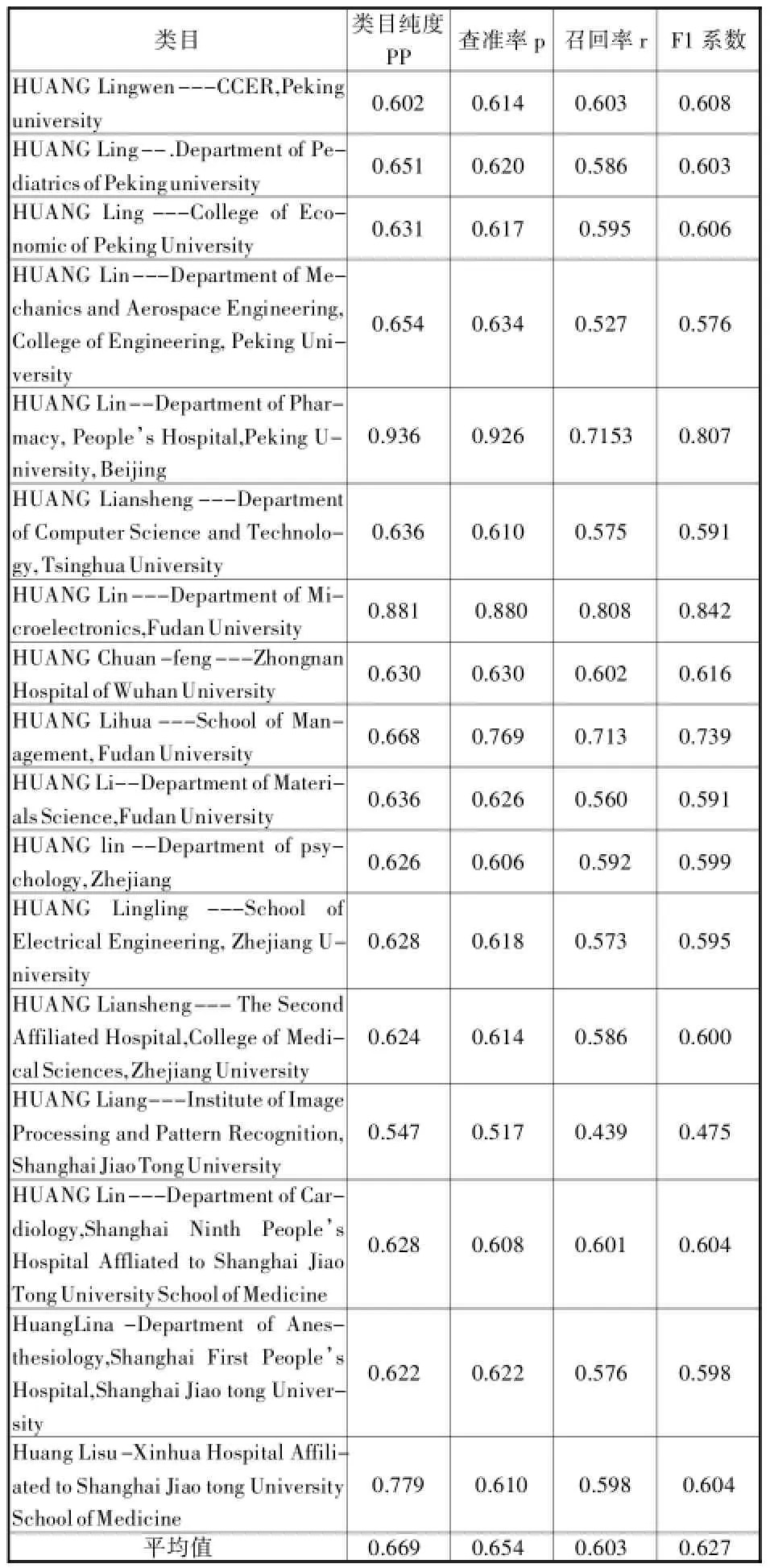
表4 基于余弦距离公式的标准DBSCAN算法对“Huang L”的人名消歧效果
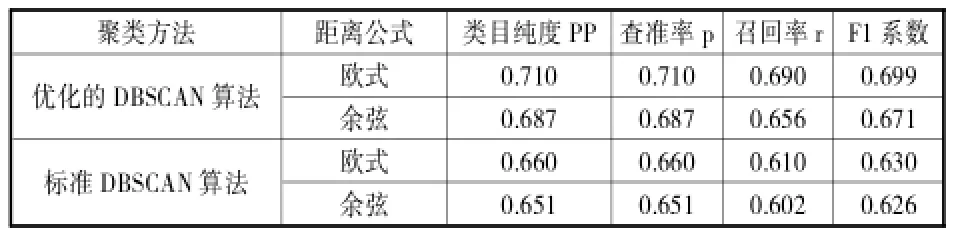
表5 人名消歧结果的各评价指数比较
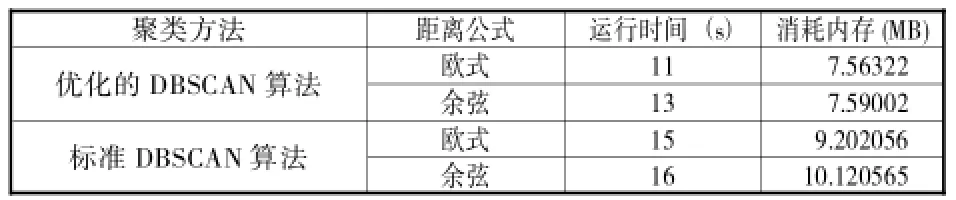
表6 各人名消歧方法的运行时间及消耗内存
②从表5可以看出,针对优化后的DBSCAN算法来说,基于欧式距离的聚类纯度比基于余弦距离的聚类纯度高出7.6个百分点;从F1系数上来看,前者比后者高出10.1%。同理可获得,针对标准DBSCAN算法来说,基于欧式距离的实验效果优于基于余弦距离的方法。另从表6中可对比出,针对优化后DBSCAN算法和标准DBSCAN算法来说,在时间消耗上和内存消耗上,基于欧式距离优于基于余弦距离的方法。因此,以上实验结果再次验证了在DBSCAN算法中,使用欧式距离来计算文本之间相似度的有效性。
通过以上比较分析,说明本文对算法的优化取得了可观的成效,同时在人名消歧方面发挥了较好的效果。另外,再次验证了基于DBSCAN聚类算法的文本距离公式使用欧式距离较佳。
4 实验总结与展望
本文主要通过改进文本聚类算法DBSCAN算法来提高人名消歧的实验效果。其中,针对DBSCAN算法,本文主要对其参数进行了优化。实验结果表明,改进的DBSCAN算法其标准算法在人名消歧实验中取得更好的实验效果。另外,以上改进的文本聚类方法除可用于文献著者消歧外,还可用于领域专家发现以及专家专长识别研究。但本文依然存在一些不足,在后续工作中需要深入探讨的地方:(1)进一步扩展数据源,除探讨文献著者消歧外,还尝试采集更加丰富的语料,以此探讨网页文本中的人名消歧义;(2)本文依然是针对英文文献的著者消歧,后续工作将对中文文献的著者人名消歧进行探讨;(3)针对DBSCAN算法,如何能最大化地减少其对初始值EPs及MinPts的依赖性,也是值得深入研究的问题。
[1]T M Mitchell.Machine learning[M].New York: McGrawHill,1997.
[2]J Huang,et al.Efficient name disambiguation for large-scale databases[J].Knowledge Discovery in Databases(PKDD2006),2006:536-544.
[3]杨欣欣,等.基于查询扩展的人名消歧[J].计算机应用,2012,32(9):2488-2490.
[4]章顺瑞,游宏梁.基于层次聚类算法的中文人名消歧研究[J].现代图书情报技术,2010(11):64-68.
[5]王英帅.Web人名消歧方法的研究与实现[D].苏州:苏州大学,2010.
[6]宋文强.科技文献作者重名消歧与实体链接[D].哈尔滨:哈尔滨工业大学,2011.
[7]王归芝,王广亮.改进的快速DBSCAN算法[J].计算机应用,2009,9(29):2505-2508.
G250.74;G254.922
A
1005-8214(2014)12-0061-04
任景华(1962-),女,博士,副研究馆员,副教授,研究方向:传播学与情报学相关理论与方法。
2014-03-24[责任编辑]阎秋娟
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
中国新闻周刊(2021年26期)2021-07-27 04:02:12
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
卫拉特研究(2020年0期)2020-01-19 01:21:18
无锡职业技术学院学报(2019年3期)2019-12-27 21:14:56
电脑与电信(2018年12期)2018-03-23 02:37:20
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中文信息学报(2012年4期)2012-06-29 06:29:14
电脑迷(2012年4期)2012-04-29 06:12:13
