
倾向性评分法中评分值的估计方法及比较*
2013-12-04 03:00第二军医大学卫生勤务学系卫生统计学教研室200433吴美京赵艳芳
中国卫生统计 2013年3期
第二军医大学卫生勤务学系卫生统计学教研室(200433) 吴美京 吴 骋 王 睿 赵艳芳 贺 佳
随着医院信息化建设的推进,越来越多的医院通过各类信息系统支撑日常医疗业务,如医院信息系统(HIS)、电子病历(EMR)等。大量临床诊疗数据存储在其中,并逐年递增。如能将这些数据有效利用,会为我们提供许多有价值的关于干预因素与结局之间因果关系的证据或“线索”,推动循证医学和卫生信息化研究和实践的发展。然而,这些临床诊疗数据往往是观察性资料,其中患者的分组可能是非随机的。若混杂因素在对比组中分布不均衡,就无法判断组间差异是由于处理因素还是组间的不均衡所引起,由此产生混杂偏倚。如何控制观察性研究中非随机化分组组间的混杂偏倚一直是热点问题。倾向评分法应运而生,成为目前解决该问题的有力工具之一。该方法易于理解、研究步骤标准化程度高,近些年来在欧美被广泛应用于大样本、非随机的观察性研究中〔1〕。
倾向性评分(propensity score,PS)的概念由Rosenbaum和Rubin在1983年首次提出,其基本原理是将多个协变量的影响用一个倾向评分值来表示(相当于降低了协变量的维度),然后根据倾向评分值进行不同对比组间的分层、匹配或加权,即均衡对比组间协变量的分布,最后在协变量分布均衡的层内或者匹配组中估计处理效应。在大样本的情况下,经过倾向评分值调整的组间个体,除了暴露因素和结局变量分布不同外,其他协变量应当均衡可比,相当于进行了“事后随机化”,使观察性数据达到“接近随机分配数据”的效果〔1〕。
那么,如何将多个协变量的影响用一个倾向评分值来表示呢?即如何估计倾向评分值呢?根据Rosenbaum和Rubin的定义〔2〕:倾向评分值为在给定一组协变量(Xi)条件下,研究对象i(i=1,2,…N)被分配到某处理组或接受某暴露因素(Zi=1)的条件概率。理论上,所有可计算得到该条件概率的方法均可用于估计倾向评分值。目前用于估计倾向评分值的方法有logistic回归、Probit回归、数据挖掘中的神经网络、支持向量机、分类与回归树、Boosting算法等机器学习方法。以下将对这些方法的使用情况及优缺点进行一一介绍。
logistic 回归估计法
logistic回归是最早提出的估计倾向评分值的方法,由于其原理为人们所熟悉且容易实现,也是目前最常用的估计方法。logistic回归模型如下:
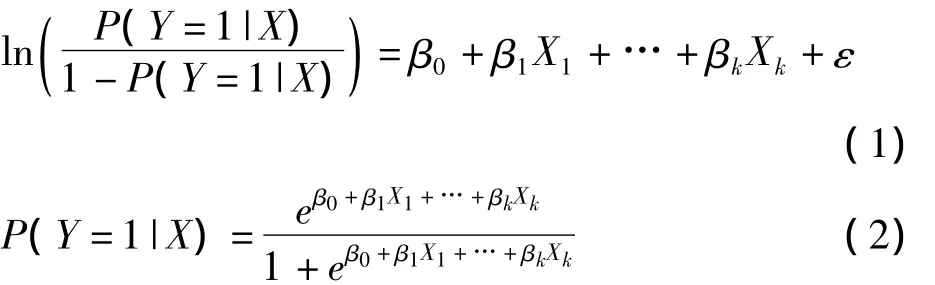
其中P(Y=1|X)表示在协变量X1,…,Xk存在的条件下事件Y发生的概率。当事件Y表示研究对象接受的处理时,P(Y=1|X)即为倾向性评分值。根据2004年一篇关于倾向性评分法应用的文献综述报道〔3〕,在入选的48篇文献中,有47篇文献采用logistic回归估计倾向评分值。Felix等人于2011年发表的关于社会科学领域倾向性评分法应用情况调查则显示,共有67篇文献采用logistic回归估计倾向评分值,约占调查总数的77.9%〔4〕。
然而,在logistic回归模型被广泛用于倾向评分值的估计时,其应用条件却被忽略了。只有当数据满足线性假设,即自变量与logit(y)(即ln[P/(1-P)])呈线性关系时,运用logistic回归模型得到的分析结果才可靠。但是,鲜有文章对此线性假设进行检验。据D’Agostino的综述报道,45篇文献中仅有一篇对该线性关系进行了评价,并且没有一篇文献考虑变量之间的交互作用〔5〕。Cepeda等人的研究结果表明,当事件数(即暴露组或处理组的最小样本量)与自变量个数之比小于8时,logistic回归的估计效果亦不佳〔6-7〕。
采用logistic回归模型估计倾向评分值具有模型简单、容易实现、可直接得到倾向评分值、结果易于解释等显著优势。然而其缺陷也不容忽视:协变量与logit(y)的线性假设常常被忽略;处理高维数据时,无法解决协变量之间存在的线性关系、非线性关系或交互作用,而忽略这些关系而得到的倾向评分值通常不可靠;当事件数与协变量数之比小于8时,logistic回归估计得到的倾向评分值也存在较大的偏倚。
Probit回归估计法
Probit回归模型如下:

该模型的结果即为倾向性评分值。据Felix等人关于社会科学领域倾向性评分法应用情况调查,87篇被调查的文献中,采用Probit回归估计倾向评分值的文献有6篇,约占调查总数的11.7%〔4〕。
Probit回归模型的优点在于其残差平方和比logitstic回归的残差平方和小,拟合效果优于logistic回归模型;缺点在于其结果的解释不如logistic回归直观〔8〕。logit函数经计算可得OR值,表示暴露组与对照组风险的优势比,实际意义比较直观;而probit的函数表示累积标准正态分布函数的逆函数或反函数,不易解释。因而,Probit回归应用不如logistic回归广泛。
机器学习估计方法
伴随着海量数据的积累,如何处理高维数据(即带有大量协变量的数据)成为医学研究的难点问题。logistic回归等传统的统计方法在处理高维数据方面明显能力不足,于是越来越多的学者开始探索如何将机器学习的方法引入倾向性评分法的领域。Breiman在他的文章“Statistical Modeling:The Two Cultures”中指出机器学习的分类算法比传统的统计方法表现更为出色,尤其是对于高维数据〔9〕。例如,当协变量个数大于样本量时,则无法构建logistic回归模型,由此便不能通过协变量获得有价值的信息。相比之下,人工神经网络等许多机器学习的方法则可以游刃有余地处理此类问题。因此,引入机器学习方法,可大大提高倾向性评分值估计的精确性和准确性。可用于估计倾向评分值或进行倾向分类的算法有很多,以下主要介绍神经网络、支持向量机、分类与回归树和Boosting算法等几种常用方法。
1.神经网络
神经网络(neural network,NN),又称人工神经网络(artificial neural network,ANN),是模仿人脑结构和功能而建立起来的、以复杂的数学运算规则为基础的一种信息处理系统。神经网络由三部分构成:包括输入层(input layer)、输出层(output layer)、隐藏层(Hidden layer),其基本工作原理在于通过处理输入层和输出层的数字信号来找出它们相互间的联系而获得相关的经验。神经网络的基本处理单元是智能节点,又称神经元。每个层均有若干个节点,各节点之间互相连接,上一层神经元的输出信号根据其权重调整后成为下一层神经元的输入信号,并得出最终信息。人工神经网络工作的一个重要前提是网络必须经过训练,当对网络提供某些已知的输出结果进行训练后,网络便掌握了对输入信息处理并判断决策的能力〔10〕。
神经网络估计倾向性评分值的基本原理是将所有可观察到的协变量作为各输入值,通过层内权重调整计算,输出值为研究对象分配到某个类别的概率或者研究对象是否分配到某个类别。如研究他汀类药物和死亡率之间的关系时,可采用神经网络方法预测在年龄、性别等协变量存在的条件下患者被分配到他汀组的概率,如图1所示,年龄、性别、BMI值等作为输入值,输出值为服用他汀类药物的概率,即倾向评分值〔11〕。

图1 三层神经网络的基本形式
相对于logistic回归而言,神经网络有两个主要的优势。第一,在高维数据的情况下,神经网络的分类更准确;第二,一个足够复杂(即有足够节点)的神经网络可对任何一个多项式函数进行估计,包含任意的多项式和任意的交互项,而不需要像logistic回归模型一样,在构建模型之前要先考虑哪些自变量之间会有交互作用,哪些自变量之间有线性关系或非线性关系。另外,神经网络可产生分类的概率,并且可通过SAS、R等软件实现,这些都让神经网络成为估计倾向评分值的一个可选工具〔11〕。
然而,神经网络在技术上仍存在一些难以解决的问题,如结构选择问题,局部极小值问题,过度拟合问题等。虽然多个作者提到可将神经网络用于估计倾向评分值〔12-13〕,也有作者将神经网络与 logistic回归进行了比较,但由于其存在上述的缺陷,目前仅发现一篇神经网络在倾向性评分中的模拟研究〔14〕。该文章的作者Setoguchi通过模拟发现,与logistic回归相比,无论在哪种情况下神经网络估计倾向评分值产生的偏倚均更小,尤其是在非线性关系存在的情况下二者差别更为明显。针对特定情况,优化神经网络,将估计倾向评分值的过程标准化,仍需深入的研究。
2.支持向量机
支持向量机(support vector machines,SVMs)属于广义线性分类器,其基本原理是将原始样本空间“升维”,即通过非线性函数(称为核函数)将原始观测点映射到高维甚至无穷维空间,然后在高维空间中寻找一个使得属于两个不同类的样品点间隔最大的平面(称为最大间隔超平面),从而达到将样品分类的目的。多分类问题可以通过多个二类支持向量机的组合来解决。支持向量机在很多实际的分类问题中都证实非常有效,例如垃圾邮件检测、癌症分类等。
支持向量机应用于倾向评分估计的基本原理是根据所有可观察得到的协变量构建核函数,找到一个最大间隔超平面,对患者进行倾向性分类。如图2所示,研究是否定期进行结肠癌筛查对死亡率的影响时,通过由年龄和年收入构建的核函数,可找到一个如虚线所示的最大间隔超平面,将患者分为两类,平面之上为有定期进行结肠癌筛查倾向的患者,平面之下为没有定期进行结肠癌筛查倾向的患者。但该方法无法得到患者被分配到两类的概率,因而也无法得到倾向评分值〔11〕。

图2 一个简单的线性分类
在应用于倾向性评分估计方面,支持向量机不仅可解决logistic回归中共线性、非线性问题,以及交互作用、协变量个数过多等由于高维数据带来的诸多问题,还可以避免神经网络算法的局部极值问题。
然而,支持向量机的最大的缺陷在于无法得到确切的倾向评分值,只能判别倾向分类。而基于支持向量机改进后的导入向量机(import vector machine,IVM)虽然可得到分类的概率,却由于其计算软件没有广泛推广而使该问题无法得到真正解决。此外,如何选择合适的核函数也往往影响到其实际应用效果,大多数非专业人士难以理解、掌握〔11〕。目前仅检索到一篇支持向量机应用于倾向评分法的文献。该文章介绍了一种预测B细胞表位的新方法,其中运用了支持向量机将蛋白质序列片段按各自的倾向分配到表位区与非表位区两个分类〔15〕。
3.分类与回归树
分类与回归树(catigorical and regression tree,CART)是一种树型分类方法,目的是将研究人群通过设定的危险因素分成若干个相对同质的亚人群。其结构类似一棵倒置的树,由主干和许多分支组成。在树中有许多节点即树结(tree node),以椭圆形框和方形框表示。椭圆形框为中间结,表示各项危险因素(或协变量)。长方形框为终止结(end node)。每个树结中的数字为分析结果,在椭圆形框下方标有判别条件,树结间有实线连接。终止结内为病例数或对照数,其下方为对应的概率〔16〕。CART的中间计算过程非常复杂,其大致的过程包括先建立一棵完整的树,然后用交叉印证(cross validation)的方法从末梢开始“剪枝”,直到“剪枝”后的模型明显变差为止。
以在军队人员中预测是否接种天花疫苗为例,如图3所示,年龄、2001年是否有执行任务两个危险因素为中间结,终止结为接种疫苗人数及未接种疫苗人数,其对应的概率表示在给定危险因素(或协变量)的条件下被分配到病例组或对照组的概率,前者即为倾向评分值〔11〕。
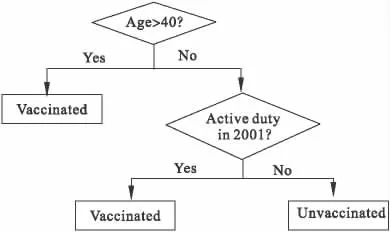
图3 分类与回归树简单示意图
CART的理论模型不要求自变量与应变量具有某种特定的分布,可用于任何分布类型的资料〔11〕;可将所有变量纳入分析过程,可评价交互作用,可避免共线性对结果的影响,并且能有效处理缺失数据,结果直观、明了、易于解释。
与其他统计分析方法一样,CART自身也存在缺点。如CART模型的稳定性较差,用类似研究资料建立的树形模型往往存在差异。CART本身是一种大样本的统计分析方法,样本量较小时模型更不稳定。对于内部同质性较好的数据,CART分析的结果与其他分析方法得到的结果基本一致〔16〕。
目前已有多项研究采用CART方法估计倾向评分值〔14,17-18〕。Stone 等人运用该方法估计了患有社区获得性肺炎的住院和门诊病人的倾向评分值,以均衡两组治疗前的混杂偏倚〔17〕。Pruzek等人将该方法运用于比较两种胆囊手术〔18〕。Setoguchi等人将CART方法与logistic回归方法进行比较,证明采用CART方法估计得到的倾向评分值的偏倚更小〔14〕。
4.Boosting 算法
Boosting算法是一种基于其他机器学习算法之上的用来提高算法精度和性能的方法。这种方法通过构造一个预测函数系列,然后以一定的方式将它们组合成一个预测函数,达到把一弱学习算法提升为强学习算法的目的。当应用于高维数据分析时,不需要构造一个拟合精度高、预测能力好的算法,只要一个效果只比随机猜测略好的粗糙算法即可,称之为基算法。通过不断地调用这个基算法就可以获得一个拟合和预测误差都相当好的组合预测模型〔19〕。Boosting算法可以应用于任何的基础算法,无论是线性回归、决策树、神经网络、还是SVM方法,都可以有效地提高精度。因此,Boosting可以被视为一种通用的增强基础算法性能的回归分类分析算法〔19〕。
广义Boosting算法(GBM)将通过迭代形成的简单回归树模型的集合叠加在一起估计倾向评分值p(x)。p(x)通过其对数优势g(x)=log(p(x)/(1-p(x)))间接得到。计算步骤如下:
第一步:设定g(x)的初始值为
第二步:寻找一个调整函数h(x),与g(x)相加,并提高模型的拟合程度。拟合度为下列方程的Bernoulli对数似然估计,值越大说明拟合程度越好。
调整函数h(x)可以为任意形式,此处为回归树,用以估计当前拟合的预测误差。当算法找到能提高模型拟合度的调整函数,模型的对数优势g(x)就变成g(x)+h(x)。通过不断迭代,每叠加一次调整函数,对数似然估计值就会相应增加,直到协变量的标准化绝对均数差的平均值(average standardized absolute mean difference,ASAM)达到最小时,停止迭代。使用回归树模型估计残差相当于估计对数似然函数的导数。因此,GBM实际上是对倾向评分值的对数优势g(x)求极大似然估计的算法〔20〕。
与决策树、神经网络以及SVMs相比,Boosting算法不但能提高这些算法的精度,且通常情况下不会产生过度拟合的问题,还可直接得到倾向评分值。另外,SAS,STATA和 R等多个软件均可实现Boosting算法。美中不足的是,Boosting算法不能提供可解释的系数〔20〕。但该缺陷对估计倾向评分值并没有太大影响。McCaffrey等人和Harder等人均将广义Boosting模型成功地运用于倾向评分值的估计〔20-21〕。McCaffrey等人将该方法应用于一项青少年滥用药物的感化治疗方案研究中〔20〕。Harder等人则在一项使用大麻对后期抑郁症发展的预测研究中运用该方法对大麻使用者和非大麻使用者进行了基线均衡〔21〕。
讨 论
无论是logistic回归、Probit回归等传统统计方法还是神经网络、Boosting算法等机器学习方法,在估计倾向评分值方面都各有利弊,但总体而言,机器学习方法优于logistic回归等传统统计方法。现从以下六个方面进行简要的总结比较:
(1)变量选择 logistic回归等传统统计方法在构建估计倾向评分值的模型时需涉及变量的选择问题。根据国外多项研究结果,变量选择的标准应该是纳入所有与结局变量有关的变量,具体应结合相关学科专业知识进行选择〔23〕,但无论是经验选择或者是逐步选择都会导致模型的均方误差较大〔11〕。机器学习方法则无须进行变量选择。
(2)模型假设 logistic回归等传统统计方法需满足对数线性等参数假设,机器学习方法则不需要。
(3)高维数据 对于高维数据,变量之间可能存在各种各样的线性及非线性关系或交互作用,机器学习方法在处理这些问题方面有着明显的优势。
(4)缺失数据 若某个或某几个协变量存在缺失,logistic回归等传统统计方法便无法直接得到倾向评分值,需先进行缺失值填补。而机器学习方法允许缺失数据的存在。
(5)软件应用 logistic回归等传统统计方法与机器学习方法中的分类与回归树、Boosting算法均可在SAS、R、Stata等多种软件中实现,神经网络可通过R、SAS软件进行计算,支持向量机则只能通过R软件计算。
(6)概率计算 logistic回归、分类与回归树、Boosting算法均可计算得到倾向评分值,支持向量机的最大的缺陷在于只能判别倾向分类,虽然改进后的导入向量机可计算倾向评分值,但其计算软件没有广泛推广,使得该方法在倾向性评分法领域也难以得到广泛应用。

表1 各种方法的比较〔11〕
(7)难易程度 毋庸置疑,logistic回归等传统统计方法是最简单的。在机器学习方法中,神经网络在技术上仍存在一些难以解决的问题,如结构选择问题,局部极小值问题,过度拟合问题等,分类与回归树则存在需要剪枝等问题,因而,有学者提出,Boosting算法应成为今后关注的焦点〔11〕。
展 望
由于研究费用高、伦理学因素、实际操作困难、不适用于周期很长的研究、结论外推受限等诸多问题,临床试验的大规模应用受到一定的限制。而医院信息化的发展,使得大量临床观察性数据唾手可得,为医学和政策问题的研究和解决提供了巨大的平台。倾向评分法,作为处理观察性研究中混杂偏倚的有力工具,具有广泛的应用前景。无论是logistic回归、Probit回归等传统统计方法还是神经网络、Boosting算法等机器学习方法,在估计倾向评分值方面都各有利弊,仅采用简单的logistic回归估计倾向评分值可能会降低该方法的有效性,在处理高维数据时,Boosting算法是值得推荐的方法。在实际应用时,应具体问题具体分析,根据不同的数据特点选择不同的方法。
1.王永吉,蔡宏伟,夏结来,等.倾向指数的基本概念和研究步骤.中华流行病学杂志,2010,31(3):347-348.
2.Rosenbaum PR,Rubin DB.The central role of the propensity score in observational studies for causal effects.Biometrika,1983,70:41-55.
3.Weitzen S,Lapane KL,Toledano AY,et al.Principles for modeling propensity scores in medical research:a systematic literature review.Pharmacoepidemiol Drug Safety,2004,13:841-853.
4.Thoemmes FJ,Kim ES .A Systematic Review of Propensity Score Methods in the Social Sciences.Multivariate Behavioral Research,2011,46(1):90 -118.
5.D’Agostino RB.Propensity score methods for bias reduction in the comparison of a treatment to a non-randomized control group.Stat Med,1998,17:2265-2281.
6.Cepeda MS,Boston R,Farrar JT,et al.Comparison of logistic regression versus propensity score when the number of events is low and there are multiple confounders.Am J Epidemiol,2003,158:280-287.
7.Cepeda1 MS,Ray B.Comparison of Logistic Regression versus Propensity Score When the Number of Events Is Low and There Are Multiple Confounders.Am J Epidemiol,2003,158:280-287.
8.李其富.Logistic回归模型与Probit模型及其在刑事作案人员分析中的应用.四川警官高等专科学校学报,2012,14(4):9-13.
9.Breiman L.Statistical modeling:the two cultures.Stat Sci,2001,16:199-231.
10.李军,杨秀兰,张伟,等.人工神经网络应用临床医学诊断的思考.医学与哲学,2008,29(10):60-62.
11.Westreicha D,Lesslerc J,Funk MJ.Propensity score estimation:neural networks,support vector machines,decision trees(CART),and metaclassifiers as alternatives to logistic Regression.Journal of Clinical Epidemiology,2010,63:826-833.
12.Glynn RJ,Schneeweiss S,Sturmer T.Indications for propensity scores and review of their use in pharmacoepidemiology.Basic Clin Pharmacol Toxicol,2006,98:253-259.
13.Cavuto S,Bravi F,Grassi M,et al.Propensity score for the analysis of observational data:an introduction and an illustrative example.Drug Dev Res,2006,67:208-216.
14.Setoguchi S,Schneeweiss S,Brookhart MA,et al.Evaluating uses of data mining techniques in propensity score estimation:a simulation study.Pharmacoepidemiol Drug Safety,2008,17:546-555.
15.Sweredoski MJ.Baldi P:a novel system for predicting continuous B-cell epitopes.Protein Eng Des Sel,2009,22:113-120.
16.武艳华,史宝林,葛丽平.分类与回归树分析方法及其在医学研究中的应用.河北北方学院学报,2008,25(6):72-73.
17.Stone,RA,Obrosky DS,Singer DE,et al.Propensity score adjustment for pretreatment differences between hospitalized and ambulatory patients with community-acquired pneumonia.Medical Care,1995,33(4):56-66.
18.Pruzek,RM,Cen L.Propensity score analysis with graphics:A comparison of two kinds of gallbladder surgery.Paper presented at the annual meeting of the Society for Multivariate Experimental Psychology.Charlottesville,VA.2002.
19.贾慧殉,刘晋,李康.Boosting方法在高维数据分析中的应用.中国医院统计,2011,18(1):1-5.
20.McCaffrey DF,Ridgeway G,Morral AR.Propensity score estimation with boosted regression for evaluating causal effects in observational studies.Psychol Methods,2004,9:403-25.
21.Harder VS,Morral AR,Arkes J.Marijuana use and depression among adults:testing for causal associations.Addiction.2006,101:1463-72.
22.李智文,李宏田,张乐.用SPSS宏程序实现观察对象的倾向评分配比.中国卫生统计,2011,28(1):89-92.
23.王永吉,蔡宏伟,夏结来.倾向指数第三讲应用中的关键问题.中华流行病学杂志,2010,3l(7):823-825.
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
宁夏师范学院学报(2021年1期)2021-03-18
计算机技术与发展(2020年2期)2020-04-15
世界知识画报·艺术视界(2017年7期)2017-07-27
自动化学报(2017年11期)2017-04-04
高中生学习·高三版(2016年9期)2016-05-14
