
云计算视野下构建个性化的知识地图*
2013-11-26 07:25蔡荣啸高强陈刚
中国教育技术装备 2013年15期
蔡荣啸 高强 陈刚
扬州大学新闻与传媒学院 江苏扬州 225000
1 前言
自从布鲁克斯(B.C.Brooks)在其《情报学基础》中提出知识地图这一定义后[1],知识地图就以其直观、概括、有针对性[2]等特点赢得了广泛关注。目前在国内,从技术角度可以将对知识地图的研究分为三类:一类是以陈强、廖开际、奚建清、林福仁(Fu-ren Lin[3])等为代表的在数据挖掘基础上进行的知识地图研究;另一类是以胡元蛟、王昊等为代表的在数据挖掘和语义网络基础上进行的知识地图研究[4];第三类则是以刘彤、时艳琴、苏新宁(Hsin-Ning Su[5])等为代表的融合社会网络分析技术的知识地图研究[6]。
知识地图虽说有多种定义,但在形式上总离不开利用图表等可视化手段将纷繁的知识数据进行展示,以达到将知识的时空关系等分析要素更加简洁地呈献给研究者的目的。
2 构建个性化的知识地图
2.1 云计算视野下的知识地图
知识地图作为将知识可视化的形式之一,首先满足的应该是针对大量知识数据计算的结果。面对大量的数据,知识地图工具很难将个性化数据汇总出来并形成面对不同个体的知识地图。为解决这一问题,本文提出建立知识地图的系统,此系统的建立是以云计算思想为基础的。
1)建立分布式数据系统。围绕解决知识地图的个性化问题,本文提出建立分布式数据库系统。传统的知识地图是针对无差别的统一的数据进行数据分析与计算的,由于缺少对每个人个性化类别的需求分析,所以只能局限于某一数据中心进行计算,而面对不同领域的研究者,通过传统知识地图构成方式所得到的知识地图,其中包含大量的“垃圾”信息。为解决这一问题,其中一条解决方案就是收集每个人的浏览信息,而如果将收集信息并处理信息的工作都交给某一数据中心进行的话,那么处理速度下降和数据量的巨大很有可能导致数据中心的崩溃。
因此,若将互联网中每个终端的个性化信息收集和处理能力作为数据中心的一部分,那么上述难题将得到有效解决。围绕这一方法可建立一个关于知识地图的分布式的数据系统,此系统包括以下几部分。
①数据中心。数据中心负责对知识的汇总以及分析计算工作。此部分是通过收集并处理所有的知识信息,通过特定的算法将汇总的信息进行分析挖掘,得到知识间的关系,并以数据的形式进行保存。之所以使用数据的形式进行保存,是避免在形成知识地图后,由于新加的个性化信息不能表现在知识地图中而导致的重复计算、浪费时间。
②云端数据。借用云计算思想,所有处在互联网中的计算机都构成了这个网络中的一个端点。处在终端端点的数据是指将研究者在研究过程中所涉及的数据进行汇总与分析,得到研究者所涉猎的学科范围、关注的知识内容等;而处在中端端点的数据是指根据不同终端分析的学科范围数据按照学科类别归纳汇总的数据。例如:有4个终端,其中1、4号终端数据为教育学范畴内的,而2号终端数据是化学范畴内,3号终端数据是哲学范畴内,则可以将1、4号划归在某专门处理教育学的中端节点上,并由此节点专门对教育学知识进行计算、分析;同理,2号与3号终端数据则分别划归在化学知识中端与哲学知识中端节点进行计算、分析(具体如图1所示)。
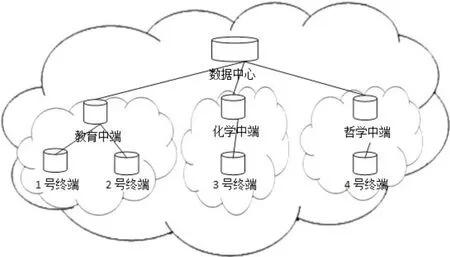
图1 云端数据分布图
2)建立统一的知识地图系统平台。为最后整合各终端的知识数据,需要统一的数据处理格式,那么要存储统一的数据格式且在用户使用软件的过程中存储,则必须使用统一的系统平台。
作为知识地图系统平台,它有以下作用:首先,能够呈现给研究者想要的反映知识间关系的图表,这一作用就是知识可视化的结果;其次是检索功能,即根据云端数据与数据中心数据的汇总计算后得到的知识间的关系。此检索功能有两个目的:一是根据研究者研究方向提供给研究者与检索词相关的其他知识间的关系图表;二是根据研究者所输入的检索词与研究者选择的图表中的知识,建立针对研究者本人的知识情况汇总。
3 实验验证
IBM公司曾对于云计算这一概念从3个层次进行了定义,分别是基础设施即服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS)。从上述定义可以看出,云计算实质上就是为用户提供服务,而且这种服务在用户来看是只针对他个人的。因此,本文要实施的个性化知识地图系统的构建,云计算思想是一种较好的达成目的的方法。
3.1 云计算准备
1)基础设施即服务(IaaS)。在云计算中,基础设施指的主要是硬件设备,为验证本文观点,笔者所使用的硬件设备如下:
①一台台式机:2 G内存,Intel i5处理器,操作系统是Windows 7,用来作为部署知识地图系统的服务器。除此之外,还需要利用VMware软件部署一台虚拟机,如使用Cent OS虚拟机,通过部署虚拟机相当于为该知识地图系统提供了硬件服务系统。
②一台便携式笔记本:2 G内存,Intel i3处理器,作为客户端测试系统。
③4口的思科有线路由器,网线2根。
2)平台即服务(PaaS)。该层位于基础设施层上层,主要是为系统进行并行计算、数据库的分配调用提供硬件资源。该平台包括虚拟机的Cent OS系统和服务器的Tomcat服务器等。
3)软件即服务(SaaS)。软件即服务处于PaaS层的上层,主要是指用户所使用的软件,在本文所指的知识地图系统中即通过IE浏览器看到服务器通过Tomcat所部属的知识地图系统软件。
4)数据安全(Security)。数据的安全性是网络时代不得不面对的一大问题,在云计算中由于数据量的庞杂,数据的安全性则尤为突出。为使该系统符合安全性要求,在该系统中使用账户登录方式可在一定程度上满足安全性要求,即用户信息只存储于自己账户的数据库中,其他账户的用户看不到。
5)数据资源供应(Provision)。笔者为实现数据资源的丰富性,利用Java语言从CNKI数据库中获取了《中国电化教育》《电化教育研究》《远程教育杂志》《中国远程教育》《现代远程教育研究》5本杂志近10年所刊登的文章。由于所获取的文章中知识量太大,为实验验证,本文均采用文章中的关键词作为知识进行知识地图的绘制。
3.2 云计算实现
本系统为满足知识地图系统对用户个性化数据的需求,将采用对平台的水平化集群的方式,即在台式机及其虚拟机中分别部属Tomcat服务器,同时利用Apache Tomcat connecter对两个Tomcat服务器进行均衡负载,使得虚拟机能够存储某个用户的个性化信息,而台式机则能对数据进行汇总和分派。
其中,workers.listoperties文件的基本配置如下:

在上述操作的基础上,要实现数据的个性化分布及其计算,则应对不同数据分别进行计算。因此,笔者在虚拟机上进行了hadoop架构,并可以根据hadoop功能对本地数据进行读取、计算以及记录。
准备工作一切就绪,下面进行系统的测试工作。
1)在便携式笔记本上登录本地Tomcat部署的网页。
2)假设用户已经登录,在输入关键词的文本框中输入“开放性”,点击“知识发现”按钮,得到“开放性”关键词的知识地图,如图2所示。
3)此时,进入虚拟机,打开用户账户保存数据的xml文件,可以看到用户所检索过的数据将被有选择地保留下来。

图2 “开放性”关键词的知识地图

图3 云端经用户干预后的知识地图
4 比较性实验
为反映云端用户的作用及云端对用户数据的记录作用,作者通过查询关键词“开放性”,连续点击与之相关的关键词“自主性”,这表示多次点击“自主性”关键词,与中心关键词“开放性”在云端是非常有意义的,见图3。将图2与图3对比后发现,关键词“自主性”离中心关键词“开放性”更近了,这可以充分证明本文观点的价值性。
5 结论
随着时代的进步、知识量的剧增,为研究者或决策者提供恰当的知识地图能够更加有效地提高工作效率。而传统的知识地图虽然能够体现知识的关系,却很难根据用户特点提供个性化的知识地图。本文通过采用云计算思想将知识地图与云计算进行结合,产生更加个性化的新的知识地图。
除上述实验展示的效果外,针对CNKI中知识地图的呈现方式,还可以如本文所提到的根据期刊是否是核心期刊等信息,给读者呈现出以期刊的重要性为第三维向量的三维立体地图,这样的知识地图将更加清晰与准确,这也将是笔者将来的研究方向。
[1]陈强,廖开际,奚建清.知识地图研究现状与展望[J].情报杂志,2006,25(5):43-46.
[2]刘勘,周丽红.面向专家的知识地图研究[J].情报资料工作,2012(2):18-19.
[3]Fu-ren Lin, Chih-ming Hsueh. Knowledge map creation and maintenance for virtual communities of practice[J].Information Processing and Management,2006(2):551-568.
[4]胡元蛟,王昊.面向CSSCI的学者知识地图构建与分析[J].现代图书情报技术,2011(3):38-44.
[5]Hsin-Ning Su, Pei-Chun Lee. Mapping knowledge structure by keyword co-occurrence: a first look at journal papers in Technology Foresight[J].Scientometrics,2010(1):65-79.
[6]刘彤,时艳琴.基于社会网络分析的专家知识地图应用研究[J].情报理论与实践,2010(3):68-71.
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
医药与保健(2022年2期)2022-04-19
河池学院学报(2021年1期)2021-07-10
中学生数理化·高一版(2021年2期)2021-03-19
英语文摘(2019年2期)2019-03-30
中华手工(2018年6期)2018-07-17
电子测试(2018年11期)2018-06-26
中国卫生(2015年7期)2015-11-08
中国交通信息化(2015年3期)2015-06-05
中国洗涤用品工业(2015年8期)2015-02-28
