
一种基于信息增益的特征选择方法
2013-10-22 09:01黄志艳
山东农业大学学报(自然科学版) 2013年2期
黄志艳
(泰山职业技术学院,山东 泰安 271000)
1 引言
随着网络信息技术与资讯的迅猛发展,文本分类成为处理和组织大量文档数据的关键技术,文本分类技术是依据预先定义的类别,对网络中大量的未知信息进行分类,以提高信息的利用率,来实现信息对研究者的价值。文本分类包含文本预处理、文本语料库、构造分类器、特征降维、文本表示、测评六个部分。其中特征降维是诸多步中最关键的一步,它在提高分类精度、节省空间、降低计算时间复杂度等方面起到最为重要的作用。
特征提取是在原有的特征基础上依据一种函数映射关系,提取一个不同的新的特征子集。得到的这个特征空间能够更好的区分各类文本,并且特征之间独立性更强。特征选择是从已知的总特征集合中,利用对特征不同的特征权值计算公式,选择区分类别强的特征作为分类训练的特征子集合。特征选择根据不同的出发角度可以得到不同的定义,其中在分类前有类别标记的被称为监督特征选择方法,分类前没有类别标记的称为无监督特征选择方法。本文首先对数据集按类进行特征选择,减少数据集不平衡性对特征选取的影响。其次运用特征出现概率计算信息增益权值,降低低频词对特征选择的干扰。最后使用离散度分析特征在每类中的信息增益值,过滤掉高频词中的相对冗余特征,并对选取的特征应用信息增益差值做进一步细化,获取均匀精确的特征子集。通过对照不同算法的测评函数值,表明本文选取的特征子集具有更好的分类能力。特征选择(Feature Selection)也称特征子集选择(Feature Subset Selection,FSS),或属性选择(Attribute Selection),是指从原始全部特征中选取一个最能代表该类的特征子集,用构造出来的模型进行分类的性能更精确更好[12]。那些冗余或不相关的特征在特征选择过程中能被移除,目的就是实现减少运行时间,减少特征个数,提高模型精确度。从另一个角度说,相关性强的特征简化了模型,使得数据产生的过程就更加容易的被人理解。
2 信息增益简介
信息增益(Information Gain,IG)在计算特征权重时,信息增益考虑了特征出现与不出现时,特征对文本类别的信息表示量。通过信息量的多少作为特征的权值,进而进行特征的选取。信息增益的公式如下。
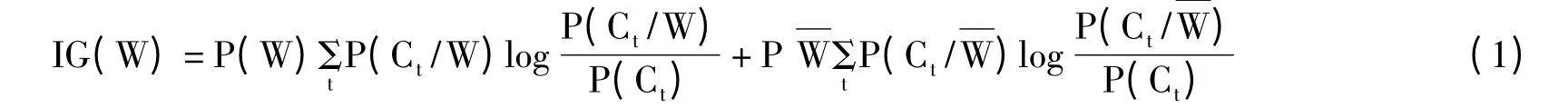
式(1)中,t 表示类别总数,P(W)表示特征W 在文本中出现的概率,P(Ct)表示Ct类文本在文本集中出现的概率,P(Ct/W)表示文本包含特征W 时属于Ct类的条件概率,)表示文本中不包含特征W 的文本的概率,表示文本不包含特征W 时属于Ct类的条件概率。[1]
在信息增益中,重要性的衡量标准就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。因此我们选择信息增益值大特征构成分类的特征子集,提取对分类系统重要的特征。虽然信息增益算法有很好的性能,但也存在着不足,下节介绍信息增益算法的不足以及改进。
3 信息增益的不足与改进
3.1 改善不平衡数据集对特征选择的影响
信息增益只考察特征对整个系统的贡献,而不能具体到某个类别上,这就使得它只适合用来做所谓“全局”的特征选择,而无法做“本地”的特征选择。例如有4个类:教育、政治、哲学和历史,教育、政治、哲学三类各含有1000个文档,历史只含有50个文档。现在有“朝代”这个特征,其中前三类都不含有此特征,但是历史类中每个文档都含有这个特征,说明“朝代”特征对历史类有很好的区分能力。[2]
3.2 减少低频特征的影响
在类分布和特征分布高度不均的情况下,低频词不出现的概率远大于出现的概率,即。此时信息增益的值是由公式后半部分决定的,大大降低了信息增益提取特征的效果。只有在本类中不出现而在其它类中出现的次数越多的特征,对于分类才更有意义。例如有4个类:教育、政治、哲学和历史,每个类都含有500个文档。现在有国家,中国两个特征,其中国家在教育,政治,哲学中各出现400 次,中国在历史中出现400 次。可以很明显的发现中国比国家有更好的区分类的能力。因此我们考虑不出现在本类中的词语在所有类中出现的概率,而不是考虑在其他类中也不出现的概率。基于以上分析思想本文将信息增益公式中的第二部分使用P(W)代替,则可以得到信息增益的公式如(2)所示。[3]

得到的新的信息增益公式信息增益,不仅考虑了出现在本类中的特征对文本分类的贡献,而且还考虑了本类中不出现在其他类别中出现的特征对文本分类的贡献,减少低频特征对特征权重的影响。以上是我们对IG 算法进行的改进,分别对每类计算特征的信息增益权值。通过信息增益权值大小选择文本分类特征,IG'虽然比传统IG 算法得到了一定的提高,减少了低频词的影响,但是对于提取的特征,我们可以通过去除特征间冗余,选择更优的特征子集,进一步提高分类性能。
3.3 去除高频特征的冗余
集合每个类中选择的特征,首先去除特征集中重复出现的特征,重复特征的出现是因为每个类分别进行的信息增益'计算,然后消除特征间的冗余。我们通过考虑特征在每个类中,信息增益权值的波动大小来衡量特征对于分类是否存在冗余。信息增益权值波动的大表明特征在每个类中的文本表示值差异大,则特征值对应到每个类中的中心值距离远,可以对文本进行更好的分类。例如有四个类:教育、政治、哲学和历史,有特征“促进”在四个类中的信息增益'取值分别为0.933、0.411、0.797、0.025,观察它的信息增益权值我们可以发现,它的波动性很大,通过文本中“促进”的取值可以很好的对文本进行类别区分。
离散度是来衡量一组数据的波动大小的重要的量,因此本文中我们使用离散度来衡量特征在每类中信息增益'值的变化大小。数据的离散度是通过数据的方差来计算的,因此可得离散度公式如式(3)所示。

式(3)中n 表示选取的特征总数,wij表示第i个特征在第j 类的信息增益'取值,表示第i个特征在所有类中信息增益'值的平均值,t 表示文本类别数。变化大的特征在分类过程中,将测试集样本与训练集样本进行比较过程中,能对文本进行更好的分类。但是特征离散度衡量的是特征在所有类中的波动性,并不能很好的表示类与类之间信息增益值的变化。这种思想映射到信息增益值,表示的就是特征在类中的最大信息增益值与其余信息增益值的差值越大对分类的贡献越大。而这种差值只需要通过最大信息增益值与第二信息增益值的差值来衡量。因此如公式(4)所示。

如果MAXIG'与SECIG'的差值越大就表明,特征出现的次数都集中在一个类中,这也是我们最想找的分类特征。因此本文在进行离散度选择特征后,又增加了SUBIG'的限制函数对特征进一步的选择。最后将选择的特征进行分类实验,来验证本文提取特征的分类性能高于其它的信息增益的分类性能。
4 实验结果及分析
4.1 性能评测
1)文本表示采用变形的Okapi[9]公式。公式如式5:

2)经变形后的文本采用KNN 分类器进行分类,KNN 分类器中文本间距离采用Mandistance 距离进行测量。文本分类的评测指标采用文本分类评测标准中的平均准确率,平均召回率和F1 值。各评价参数定义如下:
1)平均准确率
分类的准确率=分类正确文本/分类的实际文本数

其中n为总的分类数,Pj为第j 类的准确率。
2)平均召回率
分类的召回率=分类正确文本/分类应有的文本数

其中n为总的分类数,Rj为第j 类的召回率。
3)平均F1 值
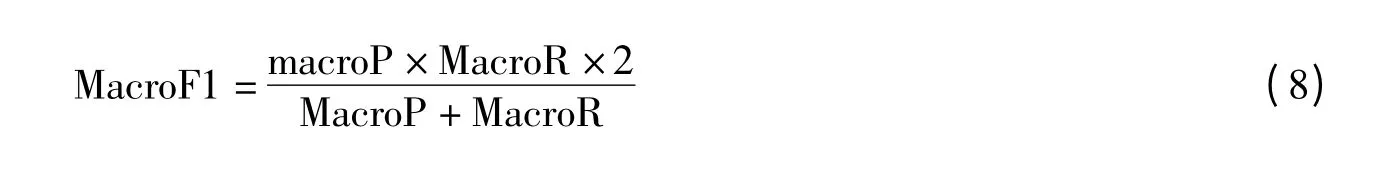
其中MacroP 是平均准确率,MacroR 是平均召回率。
4.2 实验结果及分析
通过分类选择特征,改善文本信息在各类中不均衡现象对特征选择的影响;用P(W)代替,减少出现概率低的特征对分类准确度的影响;使用信息增益'做判断条件,去除高频特征的冗余。通过分析对比实验的结果说明,在类和特征分布不均时,由改进后的信息增益算法提取的特征,计算各参数的性能指标,都有了很大的提高。最后经对测试集全特征以及前1000个特征进行分类的对比实验,可以得到针对前1000个特征的分类性能比全局的略好,提高了KNN 分类效率。训练集中对每类出现频率高的前1000个特征分别进行信息增益、信息增益、新信息增益三种特征权重计算,特征选择IG 是一种有效特征选择方法,众多研究者通过对比实验如文献[17-19],也验证了IG 特征选择算法的优越性。特征对于类的重要性在信息增益中是通过特征负载信息量的大小来衡量。负载的信息量越大,特征对于文本来说越重要。因此我们选择IG 值大的特征构成分类特征子集,以此来提高分类系统的效率。
虽然IG 算法是有效的全局特征选择算法,针对不均衡数据集,IG 算法对小样本集抽取概率降低,减少小样本集的特征提取概率。它同时考虑了特征出现与特征不出现两种情况,对于小数据集,不出现的特征权值将产生主导作用。因此提取小样本集中的特征是很困难的。其次IG 算法倾向于提取高频特征,忽略提取特征间的相互关联性,缺少对特征子集的进一步筛选。
对于现实生活中不均衡数据集的普遍存在,为广泛应用IG 算法,我们需优化IG 算法。针对IG 算法只适用于全局变量的缺陷,文献[50-52]采用不同方法对IG 等特征选择算法进行改进,提出适用于不平衡数据集的新算法。但是文献[50]中当类的重叠度较小且存在类不平衡时,此算法精度会下降,且适用范围小,没有普遍性;文献[51]通过IG、CHI、CC 以及OR 四种特征选择的组合,得到适应不平衡数据集的特征选择方法,但是它的限制条件很多,适应性差;用p(w)替换来降低不平衡数据集中,低频词对选取特征性能的影响。在不平衡数据集时文献[52]虽然改进了低频词对选取特征的影响,但是改进算法并没完全解决不平衡数据集的影响。文利用词频信息提高IG,DF 及IM 的性能。对提取特征仍需做进一步的降维处理,以此来提高分类的性能。
基于传统IG 算法以及算法的不足,本文从三方面对IG 算法进行改进,提出一种改进的信息增益特征选择方法。一方面对数据集进行分类特征选择,减少由不均衡数据集对特征选取带来的影响。另一方面使用特征出现概率计算信息增益权值,降低低频词对特征选择的干扰。最后利用离散度分析在每类中特征的信息增益值,对提取特征做进一步细化,过滤掉高频词中的冗余特征,获取均匀精确的特征子集。来验证本文特征提取算法有效的提高了文本分类精度。传统信息增益特征选择算法与信息增益'特征选择算法性能比较,如图1 所示。
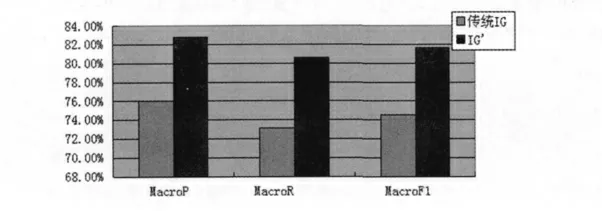
图1 传统信息增益特征选择算法与信息增益'特征选择算法性能比较Fig.1 The traditional information gain feature selection algorithm and the information gain 'feature selection algorithm performance comparison
由图1 可知,信息增益'特征选择算法相对于传统信息增益特征选择算法在MacroP,MacroR,MacroF1都有很大的提高。另外使用P(W)代替减少了低频词对特征选择的影响,选择每个特征中出现的高频词。

图2 信息增益'特征选择算法与新信息增益特征选择算法性能比较Fig.2 Information gain 'feature selection algorithm and the new information gain feature selection algorithm performance comparison
由图2 可知,新信息增益特征选择算法相对于信息增益'特征选择算法MacroP,MacroR,MacroF1 都有一定提高。这是因为新信息增益特征选择算法增加了高频词的冗余处理,提取出本类中出现频率高,其余类出现频率低的特征,提取的特征对类有更高的区分贡献率,因此得到了更为理想的分类效果。
5 总结
网络信息增速惊人,人们对技术的要求也是越来越高,本文只是分别对传统特征选择算法进行了部分改进,面对这么巨大的任务,我们需要将各种特征选择算法的优点集合起来增加它的适应性,提高它的性能。研究表明对于提取的高频词中存在特征冗余,为了能更好的提高分类的准确度与降低时间消耗本文。利用特征在类间的最大信息增益值与第二信息增益值的差值,进一步对筛选的特征做更深一步的处理,选择集中出现在一类的特征,特征对此类的区分度越强,则该特征对此类来说越重要。
[1]Mladenic D,GrobelnkM.Feature selection for unbalanced class distribution and naive Bayes[C]//Proceedings of the 16th Int’1 Con.f on Machine Learning(ICML'99).San Francisco:Morgan Kaufmann Publishers,1999:258-267
[2]YANG Y,PEDERSEN J.A Comparative Study on feature selection in text categorization[C]//Proceedings of the 14thInternational Conference on Machine Learning(ICML'97).Nashvillr:Morgan Kaufmann Publishers,1997:412-420
[3]刘庆和,梁正友.一种基于信息增益的特征优化选择方法[J].计算机工程与应用,2011:130-136
[4]杨玉珍,刘培玉等.应用特征项分布信息的信息增益改进方法研究[J].山东大学学报(理学版),2009:48-51
[5]单丽莉,刘秉权.文本分类中特征选择方法的比较与改进[J].哈尔滨工业大学学报,2011:319-324
[6]许朝阳.文本分类中特征选择方法的分析和改进[J].计算机与现代化,2010:37-39
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
自动化学报(2017年7期)2017-04-18
电子制作(2017年23期)2017-02-02
现代电子技术(2016年15期)2016-12-01
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
