
面向虚拟视点合成的深度图编码
2013-10-15 05:07:32陈贺新黎昌明
吉林大学学报(信息科学版) 2013年2期
高 凯, 陈贺新, 赵 岩, 王 钢, 黎昌明
(吉林大学 通信工程学院, 长春 130012)
0 引 言
随着3D视频显示[1]和自由视点视频(FTV: Free-Viewpoint Television)的发展[2], 虚拟视点合成成为构建3D视频和自由视点视频的重要工具, 对于虚拟视点合成, 多视点视频序列和相应的深度图序列的压缩至关重要。通常, 对不精确的深度图, 视点合成会受到绘制失真的影响, 尤其在目标边缘处更加严重。通常在虚拟视点目标边缘处, 不正确的深度值会导致绘制的相应像素误投影到3D空间中彩色图像坐标的深度平面。对于深度数据的有损压缩(例如H.264/AVC)不可避免地扭曲深度结构, 尤其是含有丰富高频成分的深度边缘[3]。通过分析视频和深度序列的相关性直方图, 可知深度图的结构特征不同于相应视频序列的结构特征[4], 当前的H.264/AVC的扩展部分JMVC (Joint Multi-view Video Coding)多视点视频联合编码框架并不适合深度图编码。另外, 对感兴趣区域的编码可提高图像的主观质量[5]。针对上述问题, 笔者提出在编码深度图当前块之前, 使用Sobel算子确定当前块中感兴趣目标边界, 基本块尺寸大小为16×16。
1 使用Sobel算子对深度图进行边缘检测
Sobel算子是进行边缘检测的典型工具, 根据相应像素的梯度判断目标边缘的位置, 通过比较梯度值和预设置门限值Th确定边缘的置, 当超过预设门限值时, 边缘被确定。使用简单有效的8方向的掩模确定边缘位置, 掩模模板如下所示


图1a为视频序列Breakdancers视点2的第1帧的深度图, 对其进行边缘检测, 通过设置门限阈值, 获得Sobel算子检测后的边缘图像(见图1b), 之后通过分析边缘检测后的图像块状态, 对深度图进行编码。
在编码当前宏块(MB: MacroBlock)前, 判断当前MB是否含有目标边界。图2是个16×16的宏块(MB)示意图, 它能分割为4个8×8的子宏块, 每个8×8的子宏块又可分为4个4×4块。索引号0,1,2,…,15代表16个4×4块。如图2所示, 当前宏块内部含有目标边界时, 若在索引号为0,1,2的8×8子宏块内, 则进一步分布在索引号为3,5~9,12的4×4块中, 文中定义了标志位SobelFlag16, SobelFlag8[4], SobelFlag4[16], 描述当前16×16宏块、 4个8×8子宏块、 16个4×4块是否含有目标边缘的状态。根据图2, 通过SobelFlag16={0}; SobelFlag8[4]={0,0,0,1}; SobelFlag4[16]={1,1,1,0,1,0,0,0,0,0,1,1,0,1,1,1}描述图2中块的状态, 其中‘0’代表块内含有目标边界, ‘1’代表块内不含有目标边界。

a 深度图像 b 边缘检测图像
2 编码端bit分配
本节详细描述了率失真优化编码中的bit分配, 分别定义编码中的16×16宏块, 8×8子宏块, 4×4块的标志位分别为
Flag16=SobelFlag16;
Flag8[i]=SobelFlag16|SobelFlag8[i],i=0,1,2,3
Flag4[j]=SobelFlag16|SobelFlag8[i]|SobelFlag4[j],i=0,1,2,3;j=0,1,2,…,15。
Flag16表示当前MB的预测模式是16×16时, 编码器量化参数QP的选择标志位; Flag8[i]表示当前宏块的预测模式是8×8时, 对应的每个8×8子宏块编码器QP的选择标志位; Flag4[j]表示当前宏块的预测模式是4×4时, 对应的每个4×4块编码器QP的选择标志位。每个标志位分配1 bit。当Flag16或Flag8[i]或Flag4[j]为0, LumaQP=QP+ΔQP, 则ΔQP=-5, 否则, ΔQP=5。对每个块, 比特流中增加了相应的标志位, 但由于调整了量化参数, 平均码流仅稍有增加。图3给出了16×16宏块中各标志位赋值状态及编码流程。

图3 16×16宏块中标志位赋值及编码流程图
3 仿真实验
实验中使用的计算机配置为Intel Core2处理器, 2.93 GHz主频, 2.0 GByte内存, 软件编程环境为VC++6.0。
该方法是在H.264/AVC的扩展部分多视点视频联合编码参考软件JMVC[6-10]中进行试验的, 配置中应用视点间预测, 采用Breakdancers和Ballet两个深度测试序列[11], 分辨率为1 024×768像素, YUV4 ∶2 ∶0格式, 帧率为15 Hz, 编码帧数为100帧, GOPSize值取1, 1帧周期为12, 序列帧间预测结构由视点2的所有帧通过视点0所有帧经过视点间预测得出, 而视点1的所有帧是通过视点0和视点2的所有帧经过视点间双向预测得到的[12,13], 对于Ballet序列, 采用视点4,5,6进行实验, 预测结构和Breakdancers序列一致。
虚拟视点合成使用由MPEG(Moving Pictures Experts Group)组织发布的VSRS3.0 (View Synthesis Reference Software)[14], 配置采用半像素精度。对于Breakdancers序列, 彩色纹理视频使用视点0和视点2未经压缩的原始彩色纹理视频, 深度图序列使用视点0和视点2的解码深度图序列, 视点1由视点0和视点2通过VSRS3.0虚拟合成。实验中对比了由笔者方法合成的虚拟视点1和原JMVC方法中合成的虚拟视点1。对Ballet序列采用同样的配置, 使用视点4和视点6虚拟合成视点5。
4 结果分析
4.1 Sobel算子门限阈值及适合序列分析
Sobel算子门限阈值Th的确定, 决定了边缘检测的效果, 进而影响到整体码流的大小。为选取最佳的Th, 实验中测试了Th值, 分别为9,11,13,15,17和19共6种情况。同样为了能测试算法在不同序列中的有效性, 对视频中目标运动快的Breakdancers和目标运动慢的Pantomime序列进行了测试, 进而寻找合适的Th和视频序列。
图4是对应不同序列不同Th情况下的bitrate和虚拟视点峰值信噪比曲线。图4a为Breakdancers序列量化参数为36时, 不同门限阈值情况下的bitrate。从图4a可看出, 当Th≥11时, 笔者的算法产生的bitrate基本趋于稳定, 且均高于JMVC产生的bitrate。当Th继续增大, 笔者算法产生的bitrate会逐渐减小, 最终与JMVC产生的bitrate相同。由图4b中不同的Th情况下虚拟视点的PSNR(Peak Signal to Noise Ratio,RPSNR)可看出, 在Th=13时, 虚拟视点的RPSNR低于原JMVC算法, 在其他采样Th情况下, 笔者的算法合成视点的RPSNR高于JMVC算法。由于笔者的最终目标是提高虚拟视点的质量, 所以对目标运动较快的序列如Breakdancers和Ballet, 使用产生最不理想的虚拟视点峰值信噪比的阈值(Th)进行测试。
图4c为Pantomime序列量化参数为36时, 不同门限阈值情况下的bitrate。图4d为Pantomime序列不同Th情况下虚拟视点的高度分量RPSNR。从图4c和图4d可看出, 笔者的方法不仅降低了虚拟视点的RPSNR, 而且总体编码bitrate高出58%, 显然笔者的方法不适合目标运动慢的序列, 如Pantomime和Champagne-tower。

a Th vs bitrate of Breakdancers b Th vs PSNR of Breakdancers
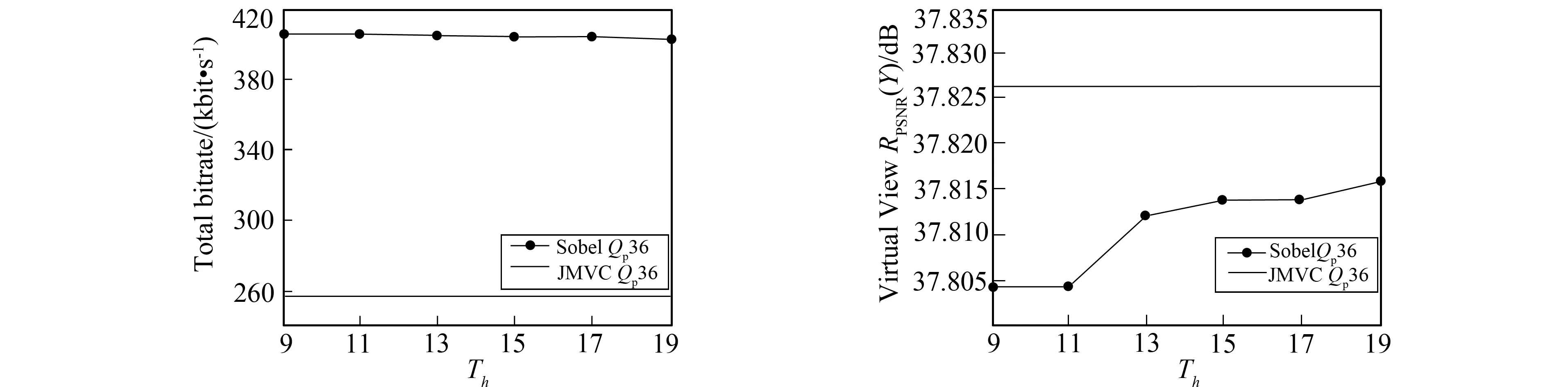
c Th vs bitrate of Pantomime d Th vs PSNR of Pantomime
4.2 虚拟视点质量评析
JMVC和笔者方法对Breakdancers序列的RPSNR和Bitrate结果比较如表1所示, 相比于原JMVC, 在5组不同QP值的情况下, 该方法的视点0和视点2比特率之和平均增加1.39%, 虚拟视点1亮度分量RPSNR(Y)平均减少0.016 dB。图5a显示了使用JMVC方法解码后的深度图虚拟合成后的视点图像及部分区域放大图像, 使用笔者方法解码后的深度图虚拟合成后的视点图像及部分区域放大图像如图5b所示。由各自的部分区域放大图像可看出, 使用原JMVC方法合成后的视点图像, 在第1幅局部放大图像中的帽檐处存在缺陷, 在第2幅局部放大图像的人脸部、 额头及头发存在空洞, 而经笔者方法合成后的视点图像很好地保留了帽檐的边缘, 且不存在空洞, 从主观质量上明显优于使用原始JMVC方法生成的视点图像。
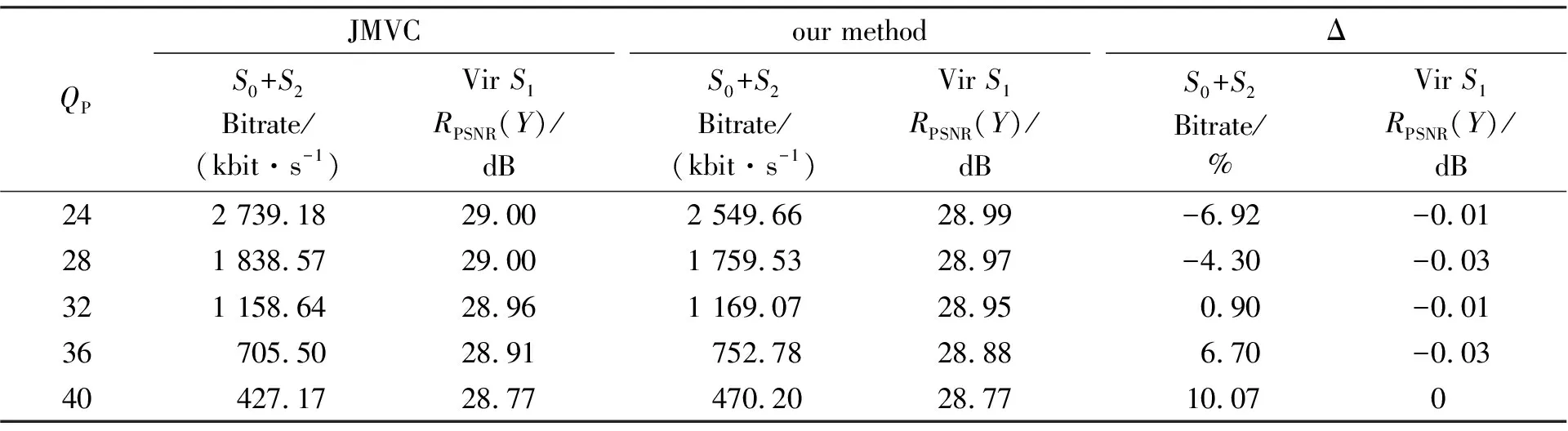
表1 Breakdancers在JMVC和笔者方法中的结果对比

a Virtual synthesis of JMVC

b Virtual synthesis of our method
表2是使用JMVC和笔者方法针对Ballet测试序列进行的PSNR和Bitrate对比结果, 相比于原JMVC, 在5组不同的QP值情况下,S4和S6视点比特率之和平均增加0.743 4%, 虚拟视点S5的亮度分量RPSNR(Y)平均减小0.078 dB。图6a为使用JMVC解码后的深度图虚拟合成后的视点图像及其部分放大图像, 图6b为使用笔者提出方法解码后的深度图虚拟合成后的视点图像及其部分放大图像。由部分放大图像可看出, JMVC生成的虚拟视点图像的头部及背部边缘存在严重锯齿形缺陷, 而使用笔者方法则能很好地保留头部及背部边缘, 因此通过主观的对比分析, 笔者方法优于原JMVC方法。

表2 Ballet序列使用JMVC和笔者方法的结果对比
从实验仿真结果分析, 可得到如下结论: 对于目标运动相对较快的序列, 通过调整了深度图中平坦区和边缘区的量化参数, 能很好地保留深度序列的目标边缘, 由图5和图6可以看出, 笔者方法生成的虚拟视点结果的主观效果优于JMVC方法。由此得出, 有选择性地最大程度保留深度图中的目标边缘对于合成虚拟视点是有利的, 也是值得进一步深入研究的。
5 结 语
笔者针对深度图中的深度值的分布特性, 对H.264/AVC标准扩展部分多视点编码框架进行改进, 提出了对深度图进行边缘检测, 以当前块是否有深度图边缘为依据, 调整压缩标准的量化参数而达到保护深度图边缘的目的, 以确保在使用解码后的深度图虚拟合成的视点的主客观质量。虽然应用该算法, 使虚拟视点的质量有所提高, 但在如何更加精确地确定块中是否含有边缘以及提高压缩性能, 仍是亟待解决的问题。因此, 未来的工作致力于在保证虚拟视点合成质量的前提下, 寻找更加出色的压缩方法, 以提高深度图的压缩性能。
参考文献:
[1]ONURAL L. Television in 3-D: What Are the Prospects? [J]. Proceedings of IEEE, 2007, 95(6): 1143-1145.
[2]TANIMOTO M. Overview of Free Viewpoint Television [C]∥Multimedia and Expo, 2009. ICME 2009. IEEE International Conference on. [s.l.]: IEEE, 2009: 1552-1553.
[3]ZHAO Yin, ZHU Ce, CHEN Zhen-zhong, et al. Boundary Artifact Reduction in View Synthesis of 3D Video: From Perspective of Texture-Depth Alignment [J]. IEEE Transactions on Broadcasting, 2011, 57(2):510-522.
[4]PHILIPP MERKLE, JORDI BAYO SINGLA, KARSTEN MULLER, et al. Correlation Histogram Analysis of Depth-Enhanced 3D Video Coding [C]∥Proceedings of 2010 IEEE 17th International Conference on Image Processing. Hong Kong: ICIP, 2010: 2605-2608.
[5]付文秀, 王世刚, 刘占声. 基于四叉树分割视频对象的可伸缩编码算法 [J]. 吉林大学学报: 信息科学版, 2003, 21(5): 1-6.
FU Wen-xiu, WANG Shi-gang, LIU Zhan-sheng. Scalable Video Object Coding Algorithm Based on Quadtree Segmentation [J]. Journal of Jilin University: Information Science Edition, 2003, 21(5): 1-6.
[6]DESDVS X, FERNANDO W A C, KODIKAEAAEACHCHI H, et al. Adaptive Sharpening of Depth Maps for 3D-TV [J]. Electronics Letters, 2010, 46(23): 1546-1548.
[7]GLENN VAN WALLENDAEL, SEBASTIAAN VAN LEUVEN, JAN DE COCK, et al. IEEE 3D Video Compression Based on High Efficiency Video Coding [J]. IEEE Transactions on Consumer Electronics, 2012, 58(1): 137-145.
[8]CHEN Y, PABDIT P, YEA S, et al. Draft Reference Software for MVC [EB/OL]. [2012-08-21]. http:∥wftp3.itu.int/av-arch/jvt-site/200906London.
[9]MERKLE P, SMOLIC A, MULLER K, et al. Multi-View Video Plus Depth Representation and Coding [C]∥ICIP 2007. San Antonio, TX: ICIP, 2007: 201-204.
[10]WEIGAND T, SULLIVAN G J, BJONTEGARD G, et al. Overview of the H.264/AVC Video Coding Standard [J]. IEEE Trans Circuits System Video Technology, 2003, 13(7): 560-576.
[11]KANG S B, ZITNICK L. MSI Sequences with Corresponding Calibration Parameters [DB/OL]. [2012-10]. http://research.microsoft.com/en-us/um/people/sbkang/3dvideodownload/.
[12]MERKLE P, SMOLIC A, MULLER K, et al. Efficient Prediction Structures for Multi-View Video Coding [J]. IEEE Trans on CSVT, 2007, 17(11): 1461-1473.
[13]ISO/IEC MPEG, ITU-T VCEG, Doc. N6909. Survey of Algorithms Used for Multi-View Video Coding (MVC) [S]. 2005.
[14]TANIMOTO M, FUJII T, SUZUKI K. View Synthesis Algorithm in View Synthesis Reference Software 3.0(VSRS3.0) [EB/OL]. [2012-08-21]. http:∥www.itscj.ipsj.or.jp/sc29/29w129∥.htm.
猜你喜欢
计算机应用(2019年3期)2019-07-31 12:14:01
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
河南电力(2016年5期)2016-02-06 02:11:24
电子设计工程(2015年24期)2015-08-26 06:39:42
新闻前哨(2015年2期)2015-03-11 19:29:22
中国水利(2015年5期)2015-02-28 15:12:40
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:36
上海大学学报(自然科学版)(2012年5期)2012-10-16 07:23:36
杭州电子科技大学学报(自然科学版)(2011年5期)2011-09-04 06:09:24
