
联合语义角色标注和指代消解
2013-10-15 01:52:04吕雅娟
中文信息学报 2013年6期
熊 皓,刘 群,吕雅娟
(1.中国科学院 计算技术研究所,北京100190;2.橙译中科信息技术有限公司,北京100010)
1 导论
语义角色标注和指代消解是自然语言处理中的两个重要基础研究,相关的研究都被广泛应用于其他的自然语言处理应用中。基于直觉上来说,这两个任务之间具有很强的联系性,即语义角色标注的结果可以帮助改进指代消解[1-2],而指代消解的结果可以帮助语义角色标注。前者已经有相关的工作验证,后面一个假设目前来说没有相关的研究工作可以参考。以 OntoNote[3]语料中的一篇文章片段为例:
1.Because[I]ARG0know [this situation]ARG1.
2.Right,like those whom we interviewed just now.
3.[It]ARG1was easy to handle once everyone understood.
其中第3个句子的“It”指代的是第1个句子的“this situation”。在这个例子中,第3个句子的“It”由于出现在谓词前面,很容易被错误的标注为“ARG0”,但是如果能够知道“It”和前面的“this situation”指的是同一实体,而“this situation”指的是事务,更多时候是受事者,因此“It”标注为“ARG1”的可能性更大。因此基于语义角色标注和指代消解相互关联这个直觉,我们提出使用马尔科夫逻辑网对它们进行联合学习推导。
马尔科夫逻辑网络(MLN)是Richardson和Domingos[4]提出的一种知识表达方式,被广泛的应用于一些联合任务中,如指代消解[5-6],语义角色标注和语义消歧[7]。由于马尔科夫逻辑网络模型简单,对于一个新的问题常常只需要定义一些新的逻辑表达式,特别对于联合模型来说,可以通过简单的增加一些约束表达式来完成联合任务,因此本文选用马尔科夫逻辑网络来联合语义角色标注和指代消解。本文最后大量的实验表明,采用联合学习后,两者的标注性能相比于单独标注系统都有了1.6个F值的提升。据我们所知,这也是第一篇证明指代消解结果可以帮助语义角色标注的工作。
本文的章节组织结构如下:我们首先在第2节简单介绍一下马尔科夫逻辑网络的背景知识;在第3节将详细介绍我们的模型采用的联合学习规则;第4节是实验部分;最后在第5节我们将总结我们的工作和对未来工作做出一些展望。
2 马尔科夫逻辑网络
仅仅使用本地特征在语义角色标注任务中是不够的,一些研究者试图利用一些全局特征[8]来提高标注的性能,或者采用联合学习方式来共同提高两者的性能。随着当前机器学习研究的进展,有多种方式可以实现我们的目标,例如整数线性规划、马尔科夫逻辑网络等等。在这里我们选用后者,因为其定义简单,支持判别式训练,更重要的一点是目前有很多相关的开源软件可供使用,有利于快速、高效的验证实验结果。
简单来说,马尔科夫逻辑网络可以认为是对传统一阶逻辑模型的扩充,马尔科夫模型对一阶逻辑中的公式(formula)增加了权重,用于衡量约束的强度,试图用带有权重的公式集合去描述已知知识的概率分布。
下面我们结合本文相关的任务实例来具体讲解马尔科夫逻辑网络。
逻辑谓词①为了和语义角色标注中的谓词相区分,我们对马尔科夫逻辑网络中的谓词添加了逻辑两个字用于区分。(predicate)
以指代消解为例,我们要做的决策是判别两个提及mi和mj是否构成共指关系。因此我们可以通过一个二元的逻辑谓词来表达这个决策:coref(mi,mj),并且这个逻辑谓词是隐藏的,可以叫做隐藏逻辑谓词(hidden predicates),因为在测试时我们并不知道此逻辑谓词的真假。在马尔科夫逻辑网络中还有一类逻辑谓词叫作已观察到的逻辑谓词(observed predicates),表示这些信息是我们在测试集中可以观察到的。例如我们可以定义一个相应的逻辑谓词headMatch(mi,mj)表示表示两个提及的中心词是否匹配。
公式(formula)
根据上面的逻辑谓词定义,我们可以使用一些带有权重的一阶逻辑公式(first-order logic formulae)来表达我们的研究动机。例如,我们可以定义如下一条公式:

上面这条公式不一定在所有条件下成立,但是我们可以认为在大多数情况下成立。因此我们给上面的公式一个权重ω,一般来说当ω越大时,上面这条公式在我们的模型中成立的可能性就越大。并且ω的取值不需要人为指定,可以从训练语料中学习得到。
虽然上面的公式使用传统的本地分类器(local classifier)也可以达到相同的效果,但是使用马尔科夫逻辑网络我们可以完成更强的推导,例如:
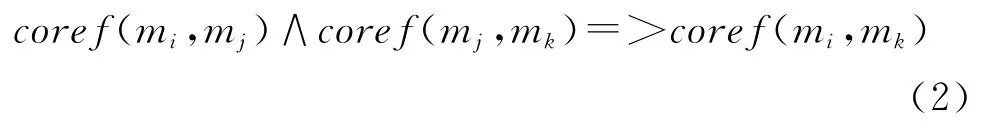
在上面这个公式中,我们定义了一条本地分类器无法实现的全局约束规则,即指代消解中常见的指代传递性问题[9]。而此类全局约束规则也是本文的核心思想,通过马尔科夫逻辑网络我们能够轻松的实现这些目标。
形式化定义
形式化来说,马尔科夫逻辑网M是一个带权公式的集合,表示为{(Φi,ωi)}i,其中 Φi为一阶逻辑公式,ωi为其对应的权重。马尔科夫逻辑网络试图通过调整ωi的大小来描述可能世界的概率。例如假设y表示一个可能的世界(possible world),或者说是基态原子(ground atoms)集合,则这个可能的世界出现的概率p(y)可以定义如下:
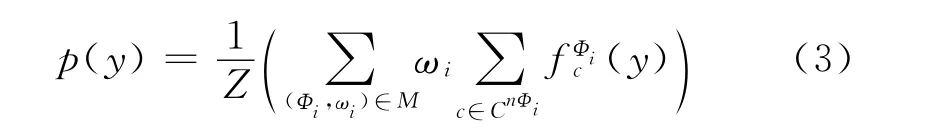
其中c是Φi中可以实例化自由变量的常量,fΦi表示一个二值特征函数,如果使用c对Φi中的自由变量进行替换后,得到的基态公式(ground formula)在世界y中仍然是正确的,则返回1,否则返回0。nΦi是公式Φi中自由变量的个数。CnΦi是可以用于实例化自由变量的常量集合,Z是归一化常量。需要说明的是,分布p(y)对应于一个马尔科夫网络,其中图中的节点表示基态原子,因子(factor)表示基态公式。例如,在世界y中,我们有两个提及实例A,B,并且有逻辑谓词headMatch构成的基态原子headMatch(A,B),headMatch(B,C)。根据上面的公式(1),(2),我们可以得到如图1所示的马尔科夫图模型,其中因子1和因子2对应于公式(1),因子3对应于公式(2)。
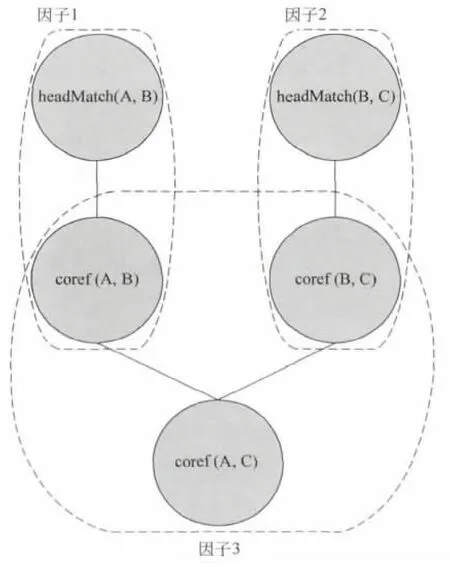
图1 根据公式(1),(2)和逻辑谓词headMatch生成的马尔科夫网络模型(其中虚线为马尔科夫图模型中的因子(factor))。
模型应用
一般来说,利用马尔科夫逻辑网络进行任务求解时,我们只需要定义好类似于公式(1),(2)的启发式规则。虽然我们需要对整个模型进行训练,例如给公式分配不同的权重w,以及给定一些观察信息时,如何从图模型中推理出最可能的基态原子等,但是一般的开源工具,如Alchemy①http://alchemy.cs.washington.edu/和 Markov thebeast②http://code.google.com/p/thebeast/都提供了相应的求解算法,因此我们需要做的仅仅是根据他们的格式定义,在训练语料中抽取出相应的基态原子实例。
3 联合标注模型中使用的公式
在我们的联合任务中,语义角色的分类以及指代消解中的提及分类都是本地化的不涉及到全局特征,而语义角色的推导,指代消解中的实体推导以及两个任务之间的联合推导都是全局化的,需要使用到彼此之间的推导结果,因此我们将公式分为两种:本地公式和全局公式。通过将本地公式和全局公式融入到马尔科夫逻辑网络中实现联合分析的目的。
3.1 本地公式
本地公式由若干个已观察到的逻辑谓词和最多一个隐藏逻辑谓词组成。对于语义角色标注来说,观察到的逻辑谓词大部分来自前人工作总结的比较有效的判别特征[8,10-13],最后结果如表1所示,隐藏逻辑谓词只有一个:role。对于指代消解来说,我们参 照现有 一 些 研 究 工 作[6,14-16],使 用 的 观 察 到 的 逻辑谓词如表3所示,隐藏逻辑谓词只有一个:coref。两个任务使用的本地公式如表2,表4所示,其中符号“+”表示针对当前公式里面可以替换的常量我们单独给予一个权重。
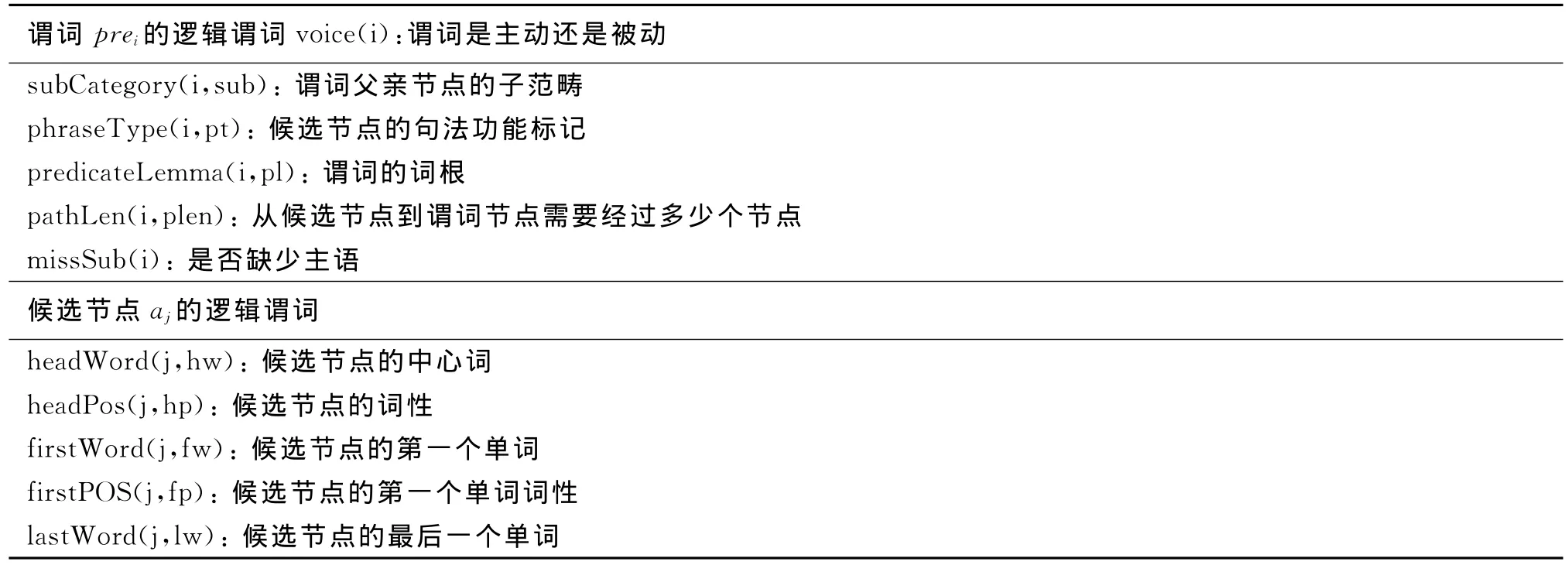
表1 语义角色任务中使用的已观察到逻辑谓词

续表
3.2 全局公式
由于我们是联合语义角色标注和指代消解任务,首先我们给出语义角色推导中使用的一些全局约束,然后在指代消解任务中,我们参考宋洋等人的工作[6]使用全局约束的规则,最后我们定义新的联合两个任务的全局公式。
3.2.1 语义角色标注全局公式
在语义角色标注中,一个节点只可能被标注为一个角色,因此我们有如下的公式:
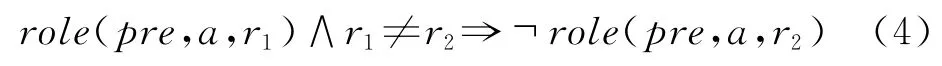
此外对于ARG0~ARG5来说,在一个谓词中只出现一次。

其中unique(r)为全局谓词,其中的常量为ARG0~ARG5。此外对于R-*和C-*来说,他们出现时必然有对应的核心角色出现。
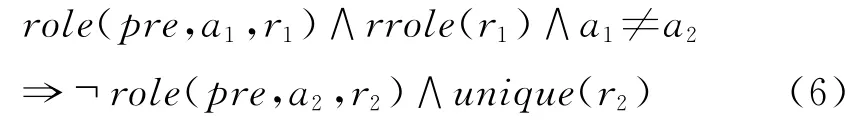
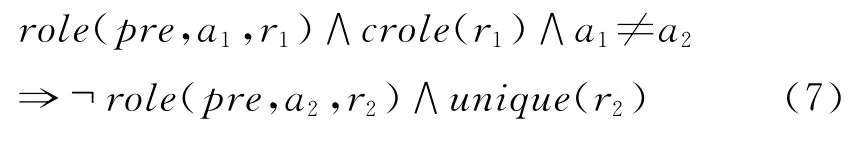
其中rrole和crole为全局谓词,其中的常量分别为R-ARG0~R-ARG5和C-ARG0~C-ARG5。
3.2.2 指代消解标注全局公式
在指代消解问题的推导过程中,可以采取最近优先和最好优先两种策略,前者搜索当前提及前面的第一个共指提及,后者搜索前面概率最高的共指提及。在这里我们采用最好优先策略,因此定义下面的全局公式:
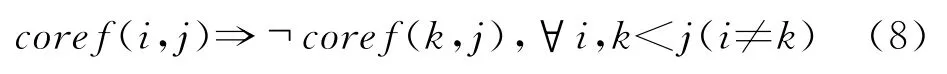
此外在指代消解的过程中如果不加入任何约束条件,容易出现如下矛盾情况,如对于3个提及i,j,k来说,可能分类的结果是coref(i,j)和coref(i,k),但是j和k分类为非共指,按照一般的算法判别的结果就是i,j,k都是指向同一实体,这样就产生了矛盾。为了解决这个问题,Luo等人[9]通过使用Bell-Tree来搜索可以加入共指链的提及,在这里我们通过加入几条全局公式来约束生成的共指链不存在上述的矛盾关系。
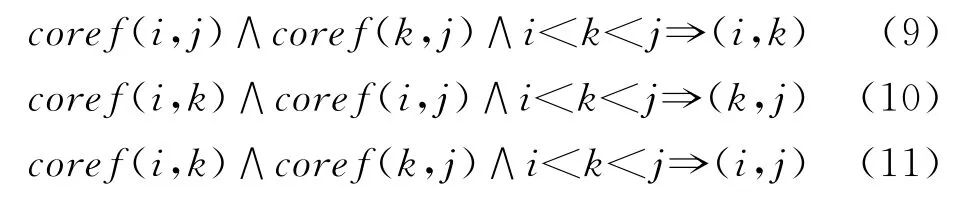
3.2.3 联合任务全局公式
值得注意的是,在我们的语义角色标注任务中,每一个和谓词没有区间交叉的节点都可以认为是谓词的候选标注节点,而在指代消解任务中候选提及一般都是名词短语,并且大部分提及实际上都不是一个语义角色。如果我们直接将两个模型联合起来求解,很有可能在指代的影响下导致大量的非语义角色节点最后标注了语义角色。因此我们首先利用表2的本地公式首先进行一次角色分类,将第一次分类标为语义角色的节点保留为候选节点,然后再联合两个模型起来求解。
首先我们认为如果两个节点是指代关系,则他们更可能标注为同一个角色,于是有如下公式:
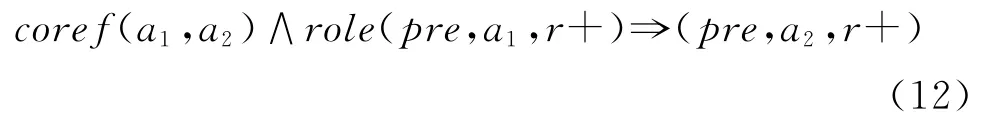
并且我们可以定义的更细致一些,约束到同一类谓词:
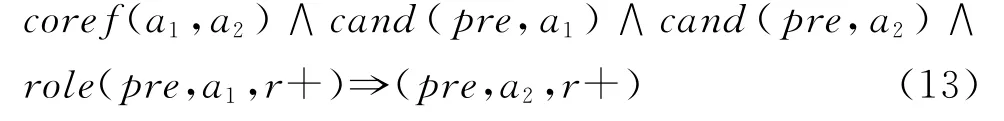
另外我们发现角色相对于谓词的顺序以及谓词是否被动对于标注为ARG0还是ARG1影响很大,因此添加下面三条公式:

此外,如果两个提及都标注为同样的角色,则他们共指的可能性也很大,因此我们考察提及前后两个谓词的标注角色是否一致:
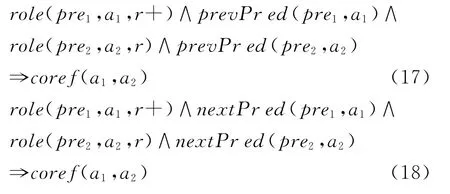

表2 语义角色任务中使用的本地公式

续表

表3 指代消解任务中使用的已观察到逻辑谓词
根据篇章向中对齐理论,对于在同一个句子中的提及来说,对于句子中的每一个谓词,如果他们标注的角色都相同,那么他们共指的可能性也很大[2]:
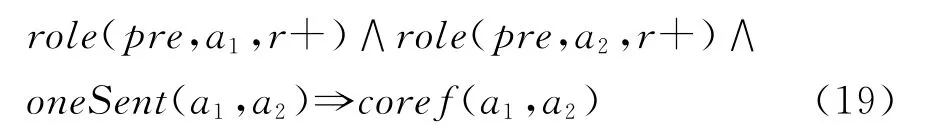
由于我们使用了多条联合推理公式,当数据集很大时速度很慢,因此我们使用开源工具先进行初步的指代消解,然后将构成实体的提及作为我们的候选提及,采用马尔科夫逻辑网络重新训练学习。

表4 指代消解任务中使用的本地公式
4 实验设计
4.1 实验数据
由于常用的语义角色标注库PropBank[17]数据集没有指代标注,我们选用OntoNote数据集作为我们的实验数据。我们使用CoNLL-2012[18]的数据切分进行实验对比,由于我们的系统不需要调节参数,因此在实验部分本文只给出测试集上的实验结果。
对于语义角色标注任务我们采用准确率、召回率和F值三个评价指标;而对于指代消解我们采用CoNLL-2012使 用的 MUC[19],BCUB[20],CEAF[21],BLANC[22]以及 MUC,BCUB和基于实体级别的CEAFE三者的平均值Avg作为评价指标。
此外我们使用开源工具thebeast①http://code.google.com/p/thebeast/进行马尔科夫逻辑网训练和推导,并且使用平均感知机[23]算法,迭代10轮进行参数训练,其他都使用默认参数。
4.2 基准系统
4.2.1 语义角色标注基准系统
我们首先利用表2使用的本地特征以及公式(4)、(5)、(6)使用thebeast进行一次语义角色标注任务,以此来生成联合标注的候选节点。表5给出了测试集上使用本地特征在标准句法分析结果和自动句法分析结果上面进行标注的性能,以及不考虑标注的结果是否和参考答案匹配,仅仅考虑其是否为一个语义角色的性能,其中系统上限为基准系统标注的语义角色节点作为候选节点可能达到的性能上限。
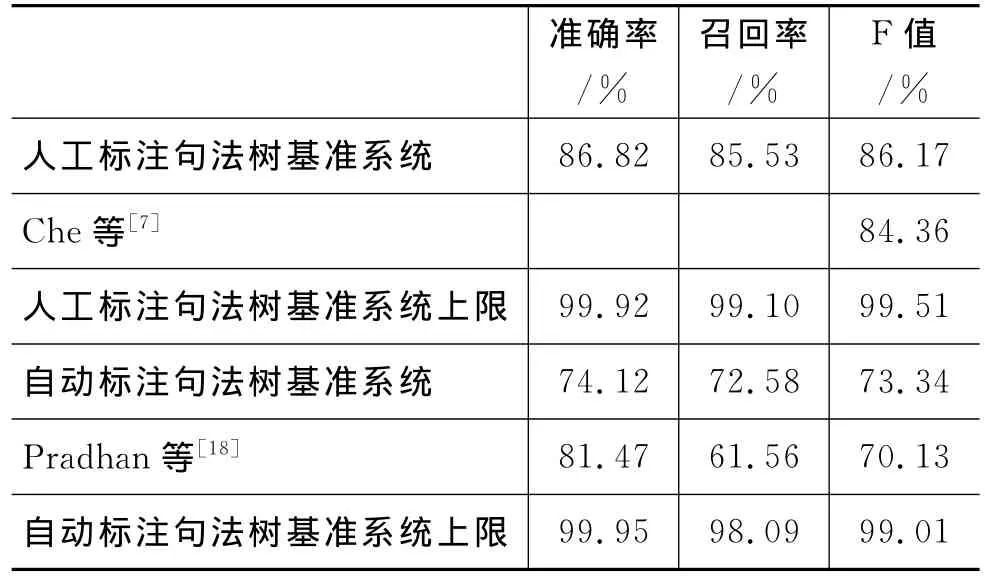
表5 语义角色标注基准系统性能
虽然到目前为止,还没有相关的研究工作汇报在CoNLL-2012上面语义角色标注的性能,但是我们可以参考CoNLL-2012官方报告[18]给出的自动句法分析树上面标注的语义角色F值为70.13%,低于我们的标注性能,他们使用的标注器是Assert①http://cemantix.org/assert.html开源标注器,并且在OntoNote上面使用训练集重新训练,但是最后的性能还是比我们的基准系统要低。此外我们可以参考 Che等人[7]利用 Onto-Note3.0进行联合语义角色标注和语义消岐的工作,他们将人工标注的句法树转为依存树进行标注,使用他们自己的切分方案得到的语义角色标注最好F值为84.36%。从对比性能上来看,我们的基准系统很强,因此基于此对比系统进行的性能提升很有说服力。
4.2.2 指代消解基准系统
此外对于指代消解,我们也先使用Standford-CoreNLP②http://www-nlp.stanford.edu/software/corenlp.shtml进行初步指代消解任务,然后在其基础上我们使用表4的本地特征以及公式(8)、(9)使用thebeast进行更进一步的指代消解任务,表6给出了系统的提及识别性能以及5个指代消解评价指标的得分,其中sys1为使用全部人工标注的句法树、命名实体识别等信息,sys2为使用自动标注的识别信息。sys3为使用sys1的结果进行马尔科夫逻辑网训练推导的结果,sys4为使用sys2的结果进行马尔科夫逻辑网训练推导的结果。

表6 指代消解基准对比系统性能
从表6中可以看到我们使用人工标注和自动标注的结果分别进行指代消解,自动标注的信息对于指代消解的性能还是略微有影响,差距大概在1~2个点左右,和Prahan等人的结论相当[18]。不过总体而言,Standford-CoreNLP的水平还是处于世界最好水平之一,使用自动标注时,MUC,BCUB,CEAFE三个指标的平均得分59.45%比CoNLL-2012的系统最好水平63.37%[24]相差4个点,但是与其他系统性能水平相差不是很大[18],差距也主要在于Standford-CoreNLP是2011年设计的系统,CoNLL-2012较CoNLL-2011系统水平有了很大改进。不过我们采用二次消解的基准系统仍然取得了60.29%的平均水平相比于Standford-CoreNLP仍然有0.8个点左右的性能提升。并且我们的方法可以应用于任何单系统,不局限于使用某一个开源工具。
最重要的一点是,通过单独进行语义角色标注和指代消解两个任务,我们可以初步过滤掉大部分候选节点,并且保持非常高的系统性能上限(指代消解任务的提及识别召回率即为联合推导系统上限),因此在后面的联合推导模型中将在去除大量噪音的基础上推导出更好的结果。
4.3 实验结果
在前面一章中提到,本文一共使用了8条联合推导规则,其中前5条是指代作用于语义角色标注,后3条相反。根据使用公式的不同,我们对如下几个系统进行实验,需要说明的是,我们的实验都是基于自动标注的结果上进行的,因为人工标注的结果对于实际应用来说用处不是很大,而上文给出的人工标注结果只是作为和其他研究工作对比的参考依据。
·sys1:使用公式(12)。
·sys2:使用公式(13)。
·sys3:使用公式(14)~(16)。
·sys4:使用公式(17)~(18)。
·sys5:使用公式(19)。
·sys6:使用公式(12)~(16)。
·sys7:使用公式(17)~(19)。
·sys8:使用所有联合推导公式。
·gold1:类似系统sys6并且使用人工标注的指代进行语义角色标注。
·gold2:类似系统sys7并且使用人工标注的语义角色标注进行指代消解。
我们先进行系统gold1和gold2的实验,用于查看我们的系统所能达到的最好性能。表7给出了两个系统的语义角色标注和指代消解的结果。

表7 使用列表4.3的gold1和gold2系统进行的实验结果
从表7中我们可以看到指代消解可以帮助语义角色标注性能达到75.67%,相比于表5基准系统73.34%的性能有了2.3%的F值提升,主要提升来自于篇章级别的语义角色标注一致性,避免了指代相同的提及分配的角色不一致的问题。此外使用语义角色标注改进指代消解在CoNLL-2012综合得分可以达到63.34%,接近于当前数据集的最好实验水平,不过我们使用的是人工标注的语义角色标注结果。实验的结果也基本和以往的研究工作结论相近[1-2]。此外我们发现从两者的贡献度来分析,语义角色标注对于指代消解的帮助更大,可以解释的原因是语义角色本身已经具有比较高的正确率,并且指代消解的贡献多集中于ARG0,ARG1以及ARGM,TMP这几个数量较多的角色,然而基准系统对于这几个角色的标注准确率已经性能不错了,因此提升空间受限。尽管如此,能够提升2+的性能对于语义角色标注来说已经是很显著的性能提升。
我们继续对本文提出的8条联合推导公式进行单独和联合的实验,表8给出了详细的实验结果。
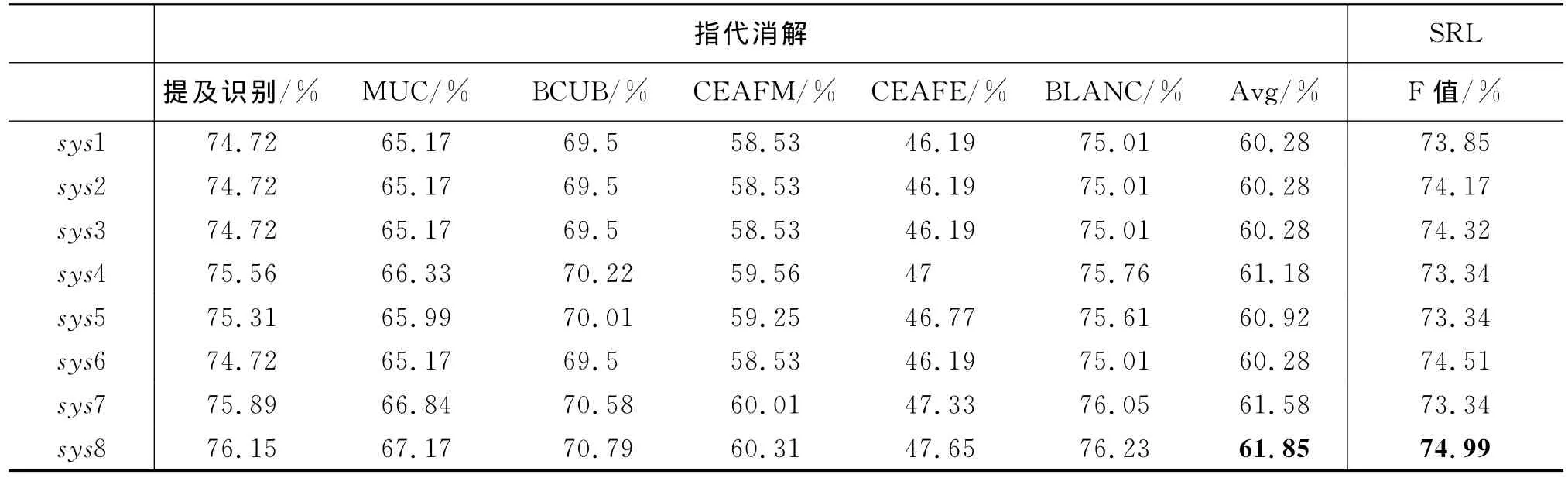
表8 使用列表4.3的系统进行的对比实验结果
从表8的结果中首先我们可以发现本文提出的8条联合推导规则在自动标注的情况下仍然有效。其次由于我们优化时是单独对隐含变量role和coref进行优化的,所以只有混合了所有规则的sys8才同时改变了两个任务的性能,而前面的组合只能单独改变某一任务性能。另外从性能提升上面来看,其中在自动指代消解的情况下,可以提升语义角色标注最多1.2个点,当联合起来推导时可以提升1.65个点;反方向的实验结果也类似,当使用联合推导时性能依然能够提升。但是我们也可以发现,语义角色标注最好的结果为74.99%,低于可能达到的最好性能75.67%,而指代的差距就更大了,最好的结果三个指标平均值只有61.85%,远低于可能达到的最好性能63.34%。最大原因在于由于我们是联合篇章级别的语义角色标注,因此一类谓词的标注错误,将导致同一链条上的指代错误,所以由于角色标注本身性能并不是很好,最后能提升的结果距离性能上限有所差距。
总体而言,使用马尔科夫逻辑网络联合推导后,两个任务的性能都有了显著的提升,由于语义角色标注本身的基准系统已经是已知研究工作中达到的最好结果,所以在其基础上所做的提升仍然是单系统的最好性能。而指代消解的最终结果也仅次于今年CoNLL-2012的最好系统性能,具有很强的可对比性。
5 本文总结和未来展望
在本文中,我们提出了利用马尔科夫逻辑网络进行联合语义角色标注和指代消解的任务。通过借鉴以往的研究工作,以及本文综合创新提出的8条联合推导规则后,本文的实验证明,通过分析篇章级别的语义角色之间的指代关系,我们能够显著的提升角色标注的性能;此外通过语义角色标注的特征用于帮助指代消解任务,实验也验证了前人研究工作提出的相关结论。本文最后通过联合两个任务的特征,使用联合马尔科夫逻辑规则推导,在两个任务中都得到了性能的显著提升。此外本章的另外贡献在于给出了在OntoNote5.0数据集上使用CoNLL-2012切分方案所能达到的语义角色标注最好性能,以及具有性能可对比性的指代消解实验结果。
在未来的工作中我们将在中文中尝试联合标注,并且尝试不同语种之间的联合学习标注。
[1]Simone Paolo Ponzetto and Michael Strube.Exploiting semantic role labeling,wordnet and Wikipedia for coreference resolution[C]//Proceedings of the Main Conference on Human Language Technology Confer-ence of the North American Chapter of the Association of Computational Linguistics.Sydney, Australia:ACL Publication Chairs,2006:192-199.
[2]Fang Kong,GuoDong Zhou,and Qiaoming Zhu.Employing the centering theory in pronoun resolution from the semantic perspective[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Singapore: ACL Publication Chairs,2006:987-996.
[3]Eduard Hovy,Mitchell Marcus,Martha Palmer,et al.Ontonotes:the 90%solution[C]//Proceedings of the Human Language Technology Conference of the NAACL,Companion Volume:Short Papers.Sydney,Australia:ACL Publication Chairs,2006:57-60.
[4]Matthew Richardson and Pedro Domingos.Markov logic networks[J].Machine learning,2006,62(1):107-136.
[5]Hoifung Poon and Pedro Domingos.Joint unsupervised coreference resolution with markov logic[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Waikiki,Honolulu,Hawaii:EMNLP Publication Chairs,2008:650-659.
[6]Yang Song,Jing Jiang,Wayne Xin Zhao,et al.Joint learning for coreference resolution with markov logic[C]//Proceedings of the 2012Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning.Jeju Island,Korea:EMNLP Publication Chairs,2012:1245-1254.
[7]Wanxiang Che and Ting Liu.Jointly modeling wsd and srl with markov logic[C]//Proceedings of the 23rd International Conference on Computational Linguistics(Coling 2010).Beijing,China:Coling Publication Chairs,2010:161-169.
[8]Kristina Toutanova,Aria Haghighi,and Christopher D Manning.A global joint model for semantic role labeling[J].Computational Linguistics,2008,34(2):161-191.
[9]Xiaoqiang Luo,Abe Ittycheriah,Hongyan Jing,et al.A mention synchronous coreference resolution algorithm based on the bell tree[C]//Proceedings of the 42ndMeeting of the Association for Computational Linguistics(ACL'04).Barcelona,Spain:ACL Publication Chairs,2006:135-142.
[10]Daniel Gildea and Daniel Jurafsky.Automatic labeling of semantic roles[J].Computational Linguistics.2002,28(3):245-288.
[11]Mihai Surdeanu,Sanda Harabagiu,John Williams,and Paul Aarseth.Using predicate-argument structures for information extraction[C]//Proceedings of the 41st Annual Meeting on Association for Computa-tional Linguistics-Volume 1.Sapporo,Japan:ACL Publication Chairs,2003:8-15.
[12]Sameer Pradhan,Wayne Ward,Kadri Hacioglu,et al.Shallow semantic parsing using support vector machines[C]//Proceedings of HLT/NAACL.Boston,USA:NAACL Publication Chairs,2004:233.
[13]刘挺,车万翔,李生.基于最大熵分类器的语义角色标注[J].软件学报,2007,18(3):565-573.
[14]Wee Meng Soon,Hwee Tou Ng,and Daniel Chung Yong Lim.A machine learning approach to coreference resolution of noun phrases[J].Computational linguistics.2001,27(4):521-544.
[15]Vincent Ng and Claire Cardie.Improving machine learning approaches to coreference resolution[C]//Proceedings of 40th Annual Meeting of the Association for Computational Linguistics.Philadelphia,Pennsylvania,USA:ACL Publication Chairs,2002:104-111.
[16]Emili Sapena,Lluis Padrdo,and Jordi Turmo.Relaxcor participation in conll shared task on coreference resolution[C]//Proceedings of the 15th Conference on Computational Natural Language Learning:Shared Task.Portland,Oregon,USA:ACL Publication Chairs,2011:35-39.
[17]Martha Palmer,Daniel Gildea,and Paul Kingsbury.The proposition bank:An annotated corpus of semantic role[J].Computational Linguistics.2005,31(1):71-106.
[18]Sameer Pradhan, Alessandro Moschitti,Nianwen Xue,et al.Conll-2012shared task:Modeling multilingual unrestricted coreference in ontonotes[C]//Joint Conference on EMNLP and CoNLL-Shared Task.Jeju Island,Korea:ACL Publication Chairs,2012:1-40.
[19]Marc Vilain,John Burger,John Aberdeen,et al.A model theoretic coreference scoring scheme[C]//Proceedings of the 6th conference on Message understanding.MIT,Cambridge,Massachusetts,USA,Proceedings.Morgan Kaufmann Publisher,1995:45-52.
[20]Amit Bagga and Breck Baldwin.Algorithms for scoring coreference chains[C]//The first international conference on language resources and evaluation workshop on linguistics coreference.Granada,Spain:LREC Publication Chairs,1998:563-566.
[21]Xiaoqiang Luo.On coreference resolution performance metrics[C]//Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing.Michigan,USA:ACL Publication Chairs,2005:25-32.
[22]Marta Recasens and Eduard Hovy.Blanc:Implementing the rand index for coreference evaluation[J].Natural Language Engineering.2011,17(4):485.
[23]Michael Collins and Terry Koo. Discriminative reranking for natural language parsing[J].Computational Linguistics.2005,31(1):25-70.
[24]Eraldo Fernandes,et al.Latent structure perceptron with feature induction for unrestricted coreference resolution[C]//Joint Conference on EMNLP and CoNLL-Shared Task.Jeju Island,Korea:ACL Publication Chairs,2012:41-48.
猜你喜欢
初中生学习指导·提升版(2023年11期)2023-12-16 12:44:18
科学咨询(2022年19期)2022-11-24 04:23:25
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:34
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30 17:00:36
资源导刊(信息化测绘)(2020年5期)2020-06-22 08:37:00
西夏研究(2020年2期)2020-06-01 05:19:12
外语学刊(2016年4期)2016-01-23 02:33:55
湖北师范大学学报(自然科学版)(2015年1期)2016-01-10 08:41:30
中学生数理化·八年级数学人教版(2015年12期)2015-05-30 10:48:04
河南科技(2014年11期)2014-02-27 14:10:11
