
优质教学资源推荐策略研究*
2013-10-11 02:10:40周鲁东李凤岐
中国教育信息化 2013年11期
杨 卓,周鲁东,李凤岐,夏 锋
(大连理工大学 软件学院,辽宁 大连 116620)
一、教学资源推荐
随着信息技术的不断发展,网络学习已经成为当代教育背景下学习的重要方式,而且许多地区和院校都建立了区域性的资源共享网络,网络资源十分丰富。然而在网络为学习者提供学习便捷的同时也存在着一些需要解决的问题。比如在如此丰富的网络资源中,学习者经常迷失于大量的信息空间中,无法及时找到自己需要的资源。这种现象的存在,一方面使优质的资源得不到充分的利用;另一方面,浪费了用户大量的时间,因此有必要实现高效的优质资源推荐策略,来帮助学习者更高效的找到其所需的资源信息,以提高学习的效率[1]。
资源推荐策略一般分为两种:显式的推荐和隐式的推荐。显式的推荐指的是传统意义上的资源检索服务,根据用户的请求,服务器被动响应,为了使这种推荐更为高效,有时会辅以专家评价;与之相对的是隐式的推荐,隐式的推荐指的是根据用户的历史学习记录,展开有针对性的个性化资源推荐。而个性化的资源推荐能够最大程度的考虑学习者的个人喜好,学习习惯和学习需求,因而对用户本身的学习显得意义重大。当前,我国的教育资源推荐发展缓慢,且尚未出现十分高效的优质资源推荐策略。然而在电子商务中,购物推荐发展比较迅速,比如Amazon、当当网的购物推荐,均能给我们带来比较有效的,符合需求的商品推荐,这对我们研究针对优质教学资源的推荐策略有重要的指导意义,因此,我们可以借助鉴购物推荐的经验,展开对于优质教学资源推荐的研究[2]。
基于此,本文作者提出了结合Pearson相关性计算和标签的教学资源推荐策略,这种策略将传统意义上的Pearson相关性计算进行“倒置”,即将Pearson相关性计算的对象进行转换,即通过将用户对资源的评价转化成资源相关性分析的驱动因子而非资源的聚类,结合资源的标签,综合获得资源之间的相关性,并利用用户的下载记录来进行有针对性的个性化资源推荐[3]。
二、基于资源相关性的教学资源推荐
基于资源相关性的教学资源推荐机制:资源被上传后,用户可进行下载,该机制提供评价系统,供用户对其浏览或下载后资源的优良做出自己的主观评价,资源的质量优劣由1~5的分值来量化:1分代表很差,以此递增,5分代表很好,值得推荐。用户可根据自己的体验,对资源进行主观的基于分值的量化,用户对资源的评价将被储存到数据库中。经过长时间的数据积累,特定类型和质量的资源会具有相对固定的特征,从而呈现出资源之间质量的差异性和资源类型之间的差异性,这样就可以对相似的资源进行聚类。进行聚类的一种比较容易和直接的算法是欧几里的距离评价,基本思想是:对于资源 A 和 B 的评分组成以下向量 VA(a1,a2,a3,…,am)和VB(b1,b2,b3,…,bn),其中,a 和 b 为资源的评分,筛选出同一用户对资源A和B都进行了评价的向量:VA’(a1,a2,a3,…,ak)和 VB’(b1,b2,b3,…,bk),其中 ai和 bi为同一用户对资源A和B的评分。ai-bi体现了用户对于资源A和B相关性的主观评价的差值,很显然,当两个资源的相关性比较好的时候,距离较短,此差值比较小。计算:sqrt=√(ai-bi)2,可以得出资源相似性的估计值,sqrt越小,相似性越大。此算法比较容易计算,但存在缺陷,即当某些用户总是倾向于给出更高的评价时,会产生较大的偏差。因此,在用户要求比较苛刻,或者需要更加精确的结果的时候,此方法并不适用[4]。
目前比较受认可的是Pearson的相关度评价算法。Pearson的算法较为复杂,但是它在数据不是很规范时,相比欧几里的距离评价算法能得到更好的结果,因此,在不是显著增加计算负担的时候,采用此算法是合适的。
本文还认为用户对自己上传的资源应有较深刻的认识,因此基于资源相关性的资源推荐机制还设置了资源标签。资源在上传时,提供资源标签,供上传用户对资源进行描述。该描述能够从整体上定位资源的分类,会对资源的聚类结果产生影响。
综合以上两点,可以得出整体的相关性描述为——基于评分的相关性+基于标签的相关性,因此可进行如下的推荐:根据用户对资源评分和资源本身的标签,综合计算资源的相关性,如果用户对某些资源比较感兴趣,根据资源的相关性,推荐相似的资源。
1.资源评分部分
Pearson的基本思想是拟合,在本次应用中,本文将原始Pearson算法中的计算对象“倒置”,将计算对象转化成资源的相关性。首先在二维坐标中,(ai,bi)代表一个点,通过对所有{(ai,bi)|ai∈VA,bi∈VB}点进行线性的拟合,可以得出量化的拟合效果,如果拟合的效果比较好,表明资源A和B具有较好的相关性。由于这种拟合是基于用户对资源的主观感受计算出来的,因此这种相关性不仅体现在质量,而且对资源的类型也有适当的体现。通过拟合的效果可以对资源进行分类。
具体计算步骤如下[5]:
(1)得到对特定资源A和B的用户评分的向量VA(a1,a2,a3,…,am)和 VB(b1,b2,b3,…,bn)。
(2)过滤 VA和 VB,使 VA和 VB中包含的 ai和 bi为同一用户的评价(i≤m,i≤n),这样得到 VA’(a1,a2,a3,…,ak)和 VB’(b1,b2,b3,…,bk)。
(3)如果统计的结果k为0,则当前没有用户对这两个资源都进行了评价,暂时无法得出资源的相关性,默认返回0。否则进入第4步。
(7)计算皮尔逊相关性:
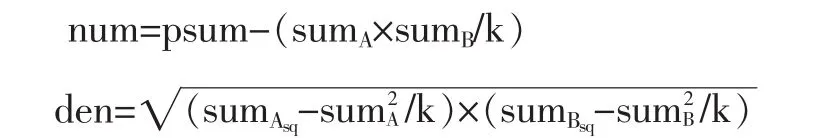
如果den=0,则说明资源的相关性为0,返回0
否则,r1=(num/den)
返回r1。
r1即为基于评分的资源相关性的计算值。
2.资源标签部分
资源在上传时,本推荐机制要求用户提供资源描述的关键字,即标签,关键字的描述能够从整体上定位资源的分类,并对资源的聚类结果产生影响,基于标签的相关性的具体算法如下:
(1)得到对特定资源 A 和 B 的标签 TA(ta1,ta2,…,tam)和 TB(tb1,tb2,…,tbn)。
(2)比较 tai和 tbi,其中 0≤i≤m,0≤j≤n。获得 ta和 tb相等的个数,赋值给count。
(3)获得 max=max(m,n)。
(4)规定 r2=(count/max)。
r2即为基于标签的资源相关性的计算值。
最后对结果进行归一化处理:
综合相关性:r=α*r1+(1-α)*r2,0≤α≤1。 α 的值根据具体环境和推荐效果进行调整。
3.优质资源推荐
最后考虑用户最近的下载情况,当用户下载了某一资源时,本机制将从资源的相关性表中选择与用户所下载的资源相关性最高的资源,更新到用户的资源推荐列表中并显示出来。
需要特别注意的问题——
更新策略:在资源比较多的情况下,鉴于每两个资源之间都需要进行计算,计算量较大,故此选择合适的时间点进行以上过程以更新数据显得尤为重要。例如:可采用数据库中的在某一具体时间触发的Job的机制,在某一特定的,用户在线量较少的时间点触发计算过程,以进行数据更新。
新用户的资源推荐:由于新添加的用户并未下载任何资源,故此以上过程对于新用户无效。这种情况下需要根据历史的统计信息,为用户推荐下载量最高的资源,或者是用户质量评价最高的资源[6]。
资源的特殊性:当用户下载某一资源,且在此资源与其他的资源均相关性不高的情况下(设定某一阈值),本推荐机制向用户推荐的是下载量最高的资源,或者是用户质量评价最高的资源。
三、本推荐策略优点
1.计算的实用性
假设本文作者所提出的优质资源推荐策略应用系统拥有N个资源,则进行基于评分的相关性计算需要进行N*(N-1)次,而且本机制采用在特定时间进行计算的方式,故此计算负担不是很重。而基于标签的相关性计算更为便捷,资源的标签是描述资源的关键字,有严格的长度限制。加入标签的额平均长度是M(一般不超过5),在拥有N个资源的系统中,需要关键字之间的比较次数是N*M2。因此,以上本推荐机制所采用的资源相关性算法,在计算上具有很高的实用性。
2.个性化的推荐
以上所阐述的过程经过计算所得到的是资源的相关性,以往,用户在进行资源的搜索时,很少能够在一次搜索的结果下得到其所需要的资源。而在本推荐机制下,用户根据其他用户下载的历史记录,被推荐与下载结果最为相近的资源,在一定程度上满足了用户的资源需求。
3.推荐的实时性
如果想要比较及时的根据用户需求的改变进行更加准确的推荐,可以调整以上算法对资源更新的计算频率,以达到资源的实时推荐,从而达到动态的个性化推荐。
4.资源推荐的准确性
本文所提出的资源推荐策略是需要进行自我学习的,即经过对历史数据的处理和过滤,通过以上方式得到推荐的资源属于经过过滤的优质资源,随着历史数据的不断积累,资源推荐的准确性将会越来越高。
四、优质资源推荐策略的应用
本文作者在Talent教学管理系统中部署了该优质资源推荐策略,当用户下载某一资源时,系统会自动将与被下载资源相关性较强的资源推荐给用户,以试图减少用户的资源搜索时间,提高优质资源的利用率。系统实现效果如图1所示。

图1 系统实现效果图
五、结语
信息技术高速发展,网络学习已成为当代教育背景下学习的重要方式之一,而且许多地区或者院校都建立了区域性的资源共享网络,网络资源十分丰富。然而在资源纷繁复杂的情况下,用户很难在短时间内寻找到自己真正需要的资源,因此,优质教学资源的推荐成为网络学习应用中的一个重要环节。
本文提出了基于Pearson相关度和标签相结合的优质资源推荐策略,它根据用户本身特点,提供个性化的优质教学资源推荐。本文作者将其部署到Talent教学资源管理系统中,进行了实际检验,结果表明,本策略比较好的实现了优质教学资源的推荐。一方面使得优质的教学资源得到充分的利用;另一方面,节约了用户的时间,提高了学习效率,说明此策略具有较好的实用性。随着科技的不断发展,智能化成为时代发展的方向,我们有理由相信,未来的网络学习将会更加智能、高效。
[1]荆永君,李兆君,李昕.基础教育资源网中个性化资源推荐服务研究[J].中国电化教育,2009(8):102-105.
[2]G.Linden,B.Smith and J.York.Amazon.com Recommendations:Item-to-item Collaborative Filtering[J],IEEE Internet Computing,2003(7):76–80.
[3]杨焱,孙铁利,邱春艳.个性化推荐技术的研究[J].信息工程大学学报,2005(6):84-87.
[4]Toby Segaran.Programming Collective Intelligence:Building Smart Web 2.0 Applications[M]. O'Reilly Media,2007.
[5]项亮.推荐系统实践[M].人民教育出版社,2012.
[6]王永固,邱飞岳,赵建龙,刘晖.基于协同过滤技术的学习资源个性化推荐研究[J].远程教育杂志,2011(3).
猜你喜欢
四川蚕业(2022年1期)2022-06-06 02:04:16
今日农业(2021年15期)2021-11-26 03:30:27
四川蚕业(2021年2期)2021-03-09 03:15:36
活力(2019年15期)2019-09-25 07:21:20
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
公民与法治(2016年10期)2016-05-17 04:12:58
中国教育技术装备(2016年15期)2016-03-01 02:46:18
计算机工程(2015年8期)2015-07-03 12:20:27
中国教育技术装备(2015年6期)2015-03-01 02:36:21
