
一种基于云平台的防汛文档智能生成模型构建
2013-09-24 10:04戚荣志
水利信息化 2013年3期
姜 鹏,许 峰,戚荣志
(河海大学计算机与信息学院,江苏 南京 211100)
0 引言
随着水利信息化的发展,越来越多的防办单位希望将水利信息系统融入到自身的工作内容中,发挥信息系统的高效性和正确性,减轻相关人员的工作压力,提高工作效率。而防汛防旱简报的编写则是一项非常繁琐的任务。
防汛防旱简报是水利局防汛防旱指挥部根据需要定期编写的,针对当前水情、雨情、气象、险情、灾情和一些突发情况所做的汇报文档。文档中包含当前的实时情况、险情灾情等造成的损失,下一阶段采取的措施等内容,形式上有工作通报、汛情汇报、汛期通报、防汛汇报等。
能否快速获取当前汛情、险情、灾情等信息至关重要,所以防汛防旱简报的快速自动生成是信息化发展的必然趋势,也是重中之重。
1 研究现状与相关工作
对于文档自动生成,国内外的研究有很多,如曲明成[1]构建了一套基于工作流的文档生成系统,实现了电力制造企业中某些复杂计算的自动化;Jiirgen Buchner[2]结合 MVC 架构设计了一种文档描述模型框架 HotDoc;葛芬[3]提出了基于 VBA,ADO 和 ASP 等多项技术,利用模板生成 Word 文档的自动生成平台;曾庆良[4]提出了支持作战仿真系统的基于 XML/Macro 的文档生成体系结构;亓祥波和马腾[5-6]提出了信息抽取的相关策略。
可见,文档生成的研究成果,大部分应用于统计和计算,即给出文档范本,对某个特定业务进行处理、统计或计算,得出文档;或者根据业务规律,预先设计好文档模板,在具体业务中根据一些规则抽取相关信息进行填充,生成文档,如办公自动化中的成绩单或一些其他领域的报表生成。
现阶段研究成果存在以下不足:
1)智能化不足,生成规则单一。生成的文档基本是高度结构化的报文、表单,或者是一些公式的计算,并且文档模板是事先做好不可更改的。
2)信息量不大,数据来源单一。抽取的数据通常来源于本地,或局域网内数据库,数据量少。而今后的发展,数据量会逐渐庞大,趋于海量。数据获取来源也会从单一的数据库变成网络云服务。
3)复杂性不高,业务逻辑单一。一方面由于防汛业务的复杂性和不确定性,使得文档的自动生成逻辑复杂,难于控制;另一方面,水利对象数据繁多,通常需要调用多个业务系统获取数据,使得相关工作难于入手。这也是文档自动生成难以应用防汛防旱文档生成的主要原因之一。
在传统的业务处理模式中,信息系统已发挥了相当一部分作用,以防汛为例,如某一特定信息(如水雨情、气象等)的统计和汇总,工作人员会从与其相关的业务系统中获取信息,填入防汛文档中。但在文档生成的工作中,相当一部分是高度流程化的业务任务,这部分工作完全可以以工作流的方式自动执行。
将工作流应用于防汛防旱简报生成,不仅将原本需要人工编写的离散的文件内容抽象为具象、统一、标准的一体化工作流,而且可实现任务的自动完成,从而快速生成格式规范、数据准确、内容完善的防汛文档。
另一方面,在“水利云”环境下,基于 SOA 架构对遗产系统进行升级改造,将调用业务数据的相关逻辑代码仍保留在原业务系统中,同时在此基础上开发一套 RESTful API 接口,提供其他业务系统的访问。现下,各业务信息(如水雨情信息)统一由单一功能服务(如水雨情查询服务)接入数据中心,获取数据,其他系统在获取水雨情信息时调用该服务相关接口。这样不仅提高代码的利用率和开发效率,同时也使不同服务易于个性化组合,提高服务质量。在文档生成工作流过程中,涉及实时数据的部分,只需调用不同的服务接口,就可以高效获取业务数据。
为此,设计一套基于水利云的防汛文档自动生成模型,并给出相关算法,建立一套完整的文档自动生成系统(以下简称系统)。目前该系统已在水利局防汛防旱指挥部投入使用,功能比较完善。
2 系统结构
操作时,将现有的历史文档离散化,并保存至数据库中。而历史文档都是 Word 格式的文件。从文件到离散化的文本数据,必须建立 1 套存储规则,将文件中的数据一一保存至数据库,这样才能实现工作流各个节点对文档数据的读取和操作。文档离散化存储结构图如图 1 所示。
工作流中,每个节点操作的文档内容不一样,有的针对文档结构,有的针对章节,有的针对文档段落内容,有的针对文档的实时数据和图表。因此文档存储的基本单元不能是文档,必须至少细化至每个段落。针对不同业务需求,将文档分为文档、章节和段落 3 类对象,并离散化保存至数据库。各个流模块将这些离散数据结合用户需求和实际情况再进行组合,得到生成的文档。
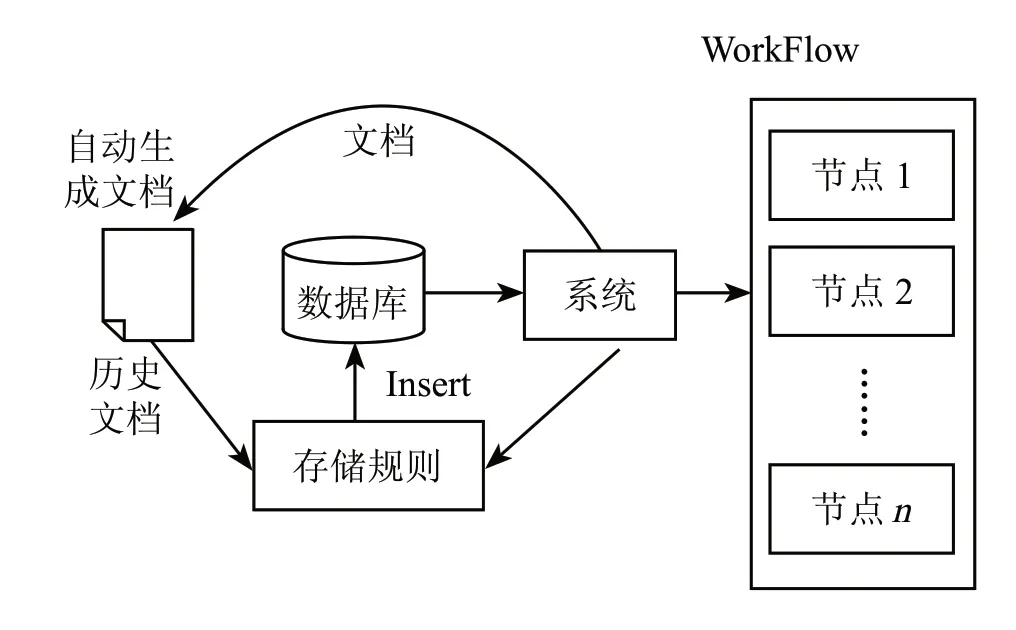
图1 文件化文档离散化存储结构图
文档组成元素结构图如图 2 所示。

图2 文档元素结构图
生成文档时,需要根据需求,寻找最符合的章节块或段落。寻找过程需要给出相应算法,结合用户需求、数据指标,并参考历史文档进行智能选择。
当智能选择的结果不符合用户需求时,能够对特定的段落做相似内容匹配,即寻找与该段落内容相似的其他段落内容,并做整段替换。系统结构如图 3 所示。
3 模型构建与算法设计
经分析,防汛文档的自动生成包括文档结构、章节、段落的自动生成。
业务人员通过选择或输入,确定文档需求,并根据文章需求确定文章组成结构。如需生成工作汇报,则选择工作汇报相关文档结构。
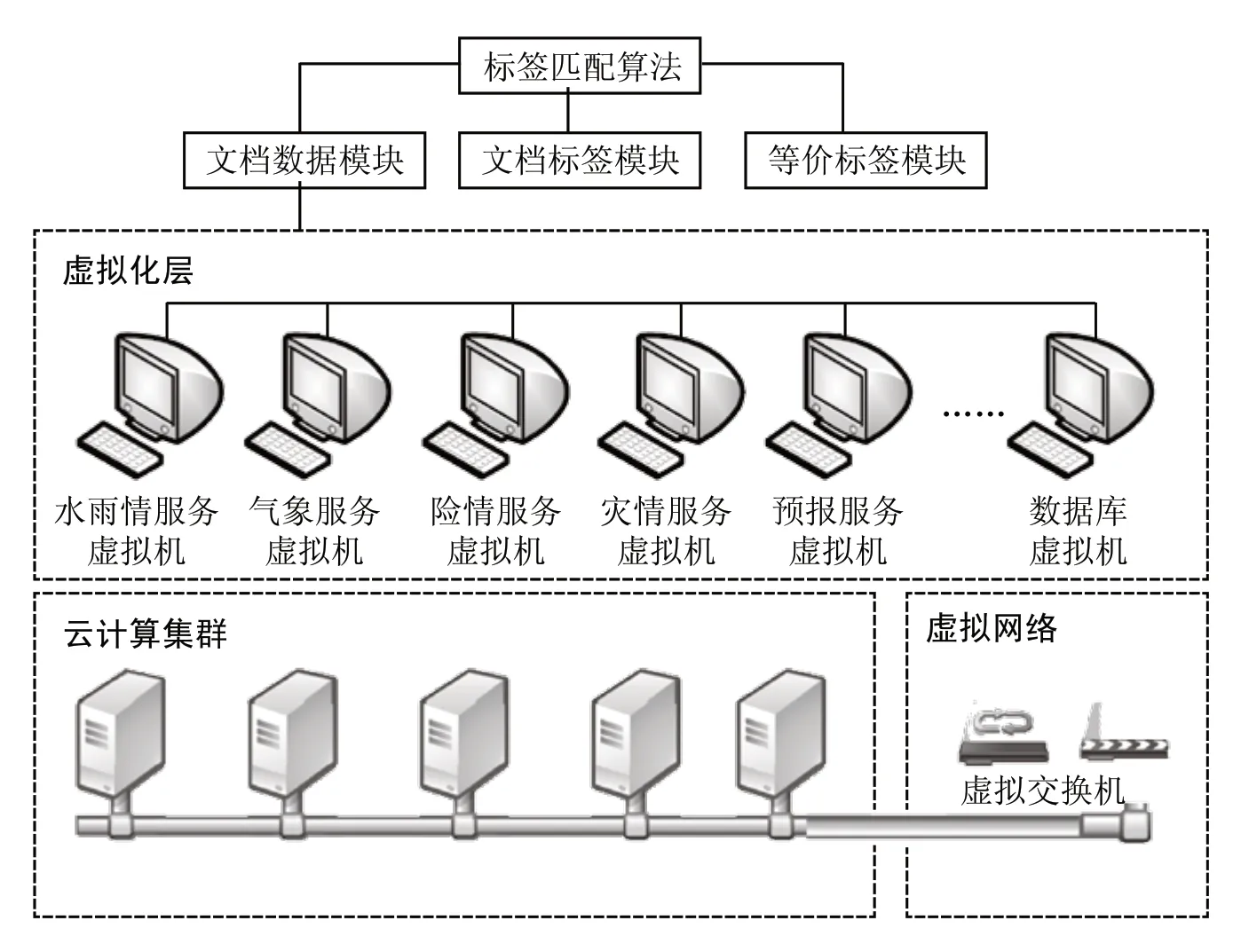
图3 系统总体结构图
模型构建时,首先定义文档各组成元素结构,然后给出每种元素之间的相互逻辑关系,随后总结出 1 套完整可靠的文档生成工作流模块,并根据流模块需求完成文档各元素的构造算法,最终给出文档自动生成的模型。模型的构建依赖于业务逻辑,并以业务人员的工作经验为构建法则。模型的求解就是智能生成文档的工作流程。文档数据的获取统一来自于云服务,访问方式统一根据水利云中设定的 RESTful API 接口。
3.1 文档描述模型
本文给出的文档描述模型是基于标签的,根据文档内容、撰写时间、投递对象等信息,总结出符合文档的标签,用于描述文档的内容和属性。
文档描述模型规则如下:
1)文档结构。在本模型下,每篇实际文档由文档(Doc)、章节(Section)、段落(Para)3 种对象实体进行描述,每类对象实体又同时由 1 个或多个标签对象(Label)进行描述,这 4 类对象构成该模型下的文档组成结构。
2)文档对象。文档对象记录文档的标题、日期、章节结构,1 个文档对象包含多个章节,任意 1 个文档对象实体都可以根据文档-章节关系、章节-段落关系还原 1 篇实际文档。具体关系如下:
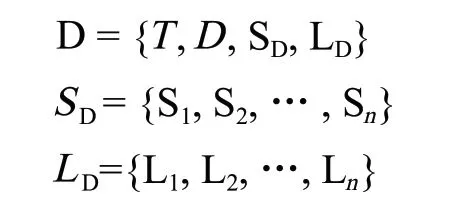
式中:D 表示 1 个文档对象,是 1 个 4 元集合;T 为文档标题;D 为文档时间;SD为章节集合;LD为文档标签集合。其中章节与标签集都由多个章节和标签对象组成。
3)章节对象。每篇文档会有多个章节,章节对象描述该章节的名称,1 个章节包含多个段落。具体关系如下:
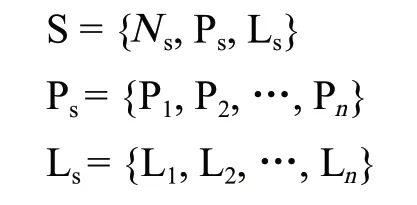
式中:S 表示 1 个章节对象,是 1 个 3 元集合;Ns为章节名;Ps为段落集合;Ls为章节标签集合。其中段落集与标签集都由多个段落和标签对象组成。
4)段落对象。段落是组成文档的基本对象,段落对象记录文档中对应段落的名称、内容,具体关系如下:
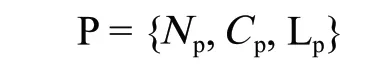
式中:P 表示 1 个段落对象,是 1 个 3 元集合;Np为段落名;Cp为段落内容;Lp为段落标签集合。其中标签集由多个标签对象组成。
5)标签对象。标签对象是用于描述上述 3 种对象的元对象,主要用于描述文档、章节、段落的基本内容,便于进行分类、检索,具体关系如下:
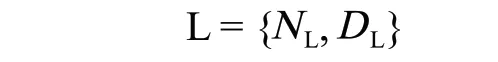
式中:L 表示 1 个标签对象,是 1 个 2 元集合;NL为标签名;DL为标签文字描述。
本模型中,主要对文档内容进行分类,并将各类信息进行抽象、定义和使用,使原本文件化的文档离散化,抽象为可被记录和检索的数据对象。这种描述方式不仅保留了原文档的全部信息,同时也可以对其进行不同对象的数据检索,增加了数据检索的灵活性。
3.2 段落模板模型
防汛文档中,某些段落需要进行数据抽取,而提高数据抽取准确性的主要途径是在某种程度上理解数据源的内容[5]。目前,流行且易实现的技术一般采用关键词与通配符序列组合作为模板的方式[6]。本文也采用段落模板的方式,实现对文档中实时数据的替换。
定义 1:段落模板 P = < I, W>,其中 I 表示模板中所需替换的实时数据集,W 表示段落中的实际文字。为方便替换,将所需替换为实时数据的段落位置用占位符代替,再获取数据或替换。
为保证段落统一性,将不包含实时数据的段落作为空模板。空模板 P = W 无需做任何处理。
定义 2:数据集为 I = {I1, I2, …, In},I = <ω, μ, τ >。式中:ω,μ,τ 均为元数据,ω 为数值数据,μ 为特征比较值,τ 表示时间。
如 2011 年 7 月 20 日洪泽湖蒋坝水位为 11.94 m,低于汛限水位 0.56 m,元数据表述为
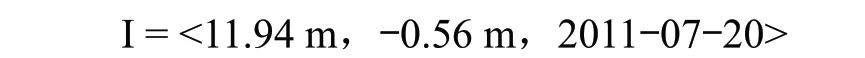
为了使系统能在逻辑上理解数据的含义,在该模型下,将数据与占位符进行了绑定,如 1 号数据为当日降雨,则占位符(用“{1}”表示)固定被解释为当日降雨信息。占位符可以被添加和删除,不可进行修改。
针对需求,将多类段落模板组合拼接为文章模板,最后填充数据即可得到生成的文档。
模板替换算法如下:
1)获取替换规则编号 ruleId;
2)根据替换规则编号,从数据库中获取替换规则类名 className;
3)运行替换规则类方法,
Class.forName (className).createData ( )
得到数据获取类,并执行该类实现的获取数据接口方法,方法中进行数据对应云服务的安全认证,并获取数据;
4)将原文中的数据替换为对应占位符,生成原文模板;
5)将模板中的占位符依次替换,得到实时数据段落;
6)返回段落内容。
实时数据在处理结束后,得到的数据信息还将传递给图表生成类进行图表的生成,根据需求的不同生成不同的图表,返回到前台,并实时插入至对应段落后。
所有工作完成后,就得到自动生成的 1 篇新文档。
3.3 文档标签匹配算法
在该模型下,需要能够从用户输入的少量信息中提取出更多有效的数据和文档内容,智能、自动生成相关文档,这就要求算法能够对内容进行智能选择。
传统算法根据用户输入信息进行匹配,将匹配结果作为选择内容。这种做法直观且易实现,但由于要求与用户输入的信息完全匹配,条件过强,往往搜索不到结果。同时,传统算法通常为确定性算法,而文档的智能生成一般没有定向性,确定算法的解未必适用。
为此吸收传统做法的优点,在简单匹配中加入一些启发式信息[7],结合 Rough Set 理论[8],根据文档描述模型,设计了 1 套多模式文档标签匹配算法(MLMA 算法)。该算法是根据用户输入进行的一种模糊匹配算法,步骤如下:
1)等待用户输入的标签集。标签集中包含 1 个或多个用户需要检索的标签。
2)单个标签匹配。单个标签匹配是根据某个特定的标签,检索出与该标签匹配的文档、章节或段落对象。单个标签匹配需要按顺序使用 4 类匹配模式进行匹配(以搜索文档为例)。
a)完全匹配。即输入内容与描述该文档的标签内容完全一致,匹配成功,匹配度为 match_dA= 1。
b)语义等价匹配。这种匹配需要借助已建立的语义等价表,在实际应用中如“未来计划”、“未来打算”、“下阶段计划”、“下阶段打算”在语义上是一致的,若用户输入的是“未来计划”,则“未来计划”为完全匹配,“下阶段打算”等为语义等价匹配,匹配度为 match_dB= 1。
这里根据实际情况、常识或语言习惯,给出多种等价标签对,并保存至等价语义库中。
c)部分联想匹配。当完全和语义等价 2 种匹配都失效,可采用部分联想匹配。如针对用户输入的标签与实际标签的部分内容完全一致,例如用户输入“雨情”,与“全市雨情”实际上语义相近,可作为近似联想匹配。联想后字数为 n,匹配字数为 m,匹配度为
d)破坏匹配。这是标签匹配的最坏情况,当标签匹配都不满足上面 3 种情况时,可以尝试使用破坏匹配。这种匹配是将被匹配的 2 个标签破坏掉部分文字后达到完全或语义等价匹配。这类匹配的目的是防止用户在检索时输入错误,但是有时候会造成语义上的偏差。最终匹配字数为 n,破坏字数总数为 k,匹配度为
若检索“防汛通报”,则标签“汛情通报”与其破坏匹配度为(4-1)/4 = 0.75;而标签“工作总结”与其破坏匹配度为(4 - 4)/4 = 0。
破坏匹配认为,在破坏原词组结构的同时,语义匹配度也随时降低,从而使其在破坏语义的情况下,破坏匹配的匹配度会尽量低。
根据匹配规则,选择匹配度最高的 1 组标签组作为匹配结果,显然完全和语义等价 2 种匹配会优先被选择。当匹配度低到一定程度后认为匹配失败。
3)全集合匹配。枚举库中的文档,将文档的标签与用户的输入标签集合一一匹配,计算文档与标签集合相似度,相似度由如下公式计算:
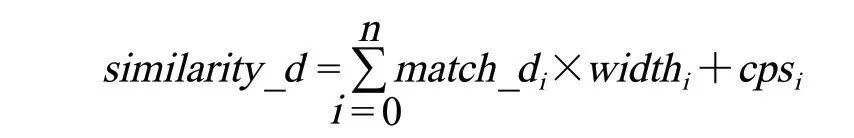
式中:widthi为每个标签匹配度的权值,由权值向量W 给出;cpsi为每个标签的匹配补偿,由补偿向量 C给出。权值与补偿向量会根据用户需求,文档类型动态改变。如对于传统匹配算法,权值向量为 W = [1, 0, 0, 0],补偿向量为 C = [0, 0, 0, 0],目前所使用的权值向量为 W = [1, 1, 0.75, 0.5],补偿向量为 C = [0, 0, 0.2, 0.3]。
即完全匹配与等价匹配权值为 1,无补偿;部分联想权值为 0.75,做 0.2 的补偿修正;破坏匹配权值为 0.5,做 0.3 的补偿修正。
根据公式得到文档相似度,并根据降序排序,选择前 10 个(可配置)文档作为检索结果返回,显然相似度最高的文档可能满足用户的搜索需求。一旦用户输入的需求过多而无法找到完全匹配的结果,该算法就会自动降低搜索条件,将部分满足条件的结果返回,使用户不至于一无所获,提高了用户体验,同时增强了模型的兼容性。
该算法不仅可以在用户搜索文档时使用,也可以检索文档、章节、段落之间的相似度。当用户需要替换某个章节或段落时,就可以用该算法匹配出相似度最高的章节或段落作为推荐。
3.4 文档生成工作流模型
工作流是一类能够完全或部分自动执行的经营过程,根据一系列过程规则,文档、信息或任务能够在不同的执行者之间传递和执行[9]。如今,利用工作流将日常工作与信息系统相结合的做法越来越普遍,也越来越受到各行各业的认可。
要实现文档生成工作的智能执行,首先必须建立工作的模型,进行工作流程定义[10],给出工作流模型。
在本文中,工作流模型用有向图的方式给出,图中节点表示工作流的节点,边表示活动流动关系。
定义 3:用 N 表示工作流中的某个节点,即某个工作步骤。

式中:N 是 1 个 7 元组,n 表示节点名称;t 表示节点类型;r 表示节点角色,用于区分该节点针对用户还是计算机;C 为该节点条件集;D 表示该节点数据集;NP和 Nn表示与当前节点相连的前驱边集和后继边集。
定义 4:有向边 E 描述节点之间的数据流动和任务完成关系。E = <N1, N2> 表示从节点 N1到节点 N2有 1 条有向边,N1为前驱节点,N2为后继节点,数据从 N1传递至 N2。
定义 5:条件集 C 为该节点的激活条件,在条件集不全为真的情况下,节点不被激活。

定义 6:有向图 G 表示 1 个过程,G = <m, N, E>,m 表示过程名;N 表示全部节点集;E 表示全部有向边集。
最终设计的工作流结构图如图 4 所示。
4 系统实现
依据上文中定义的各类模型、相关操作和算法,构建防汛文档自动生成系统,系统将相关操作、算法及各类函数封装为特定的功能模块最终实现文档生成系统。
系统分为文档管理、录入与生成 3 大模块。
1)文档管理模块。主要工作是对现有的文档数据库进行管理,包括文档增加、删除、分类查看。根据文档的实时性特点、编写时间进行分类。
2)文档录入模块。依据给出的文档描述模型对文档进行描述。实际工作中,用户需要根据模型,对历史文档进行录入,流程图如图 5 所示。
文档录入页面效果图如图 6 所示。
3)文档生成流程。关键步骤在于对智能化标签匹配算法的实现,而该算法已经封装与模块中,提供接口直接调用,流程图如图 7 所示。
文档中包含的实时数据,需要提示用户输入时间,输入后可自动根据时间替换相应的数据信息。
最终生成的文档如图 8 所示。
5 结语
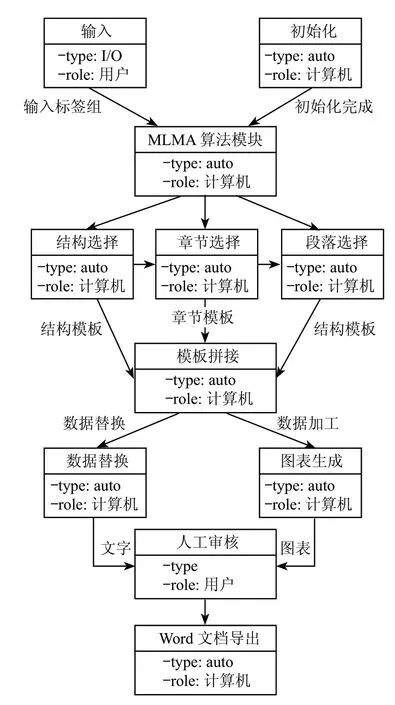
图4 工作流结构图

图5 文档录入流程图

图6 文档录入页面
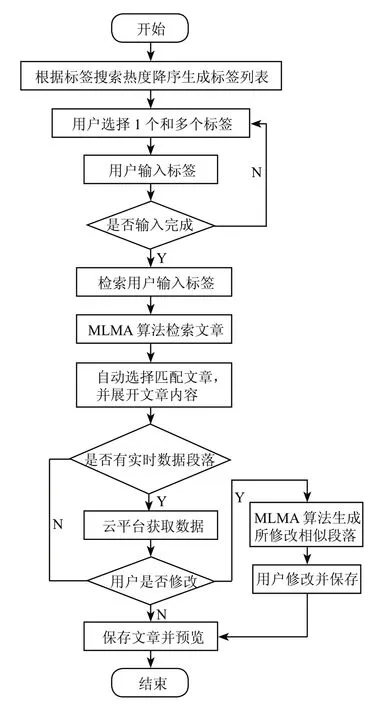
图7 文档生成流程图
传统的文档生成主要针对业务相对单一,数据量小的流程设计。针对防汛防旱业务过程的文档生成难题,提出的防汛文档自动生成模型,通过给出的对文档的分解和各模块的定义,以及相关算法,能解决文档内容在智能生成中语义匹配的难题。根据模型,以水利局防汛业务为背景,水利云计算平台环境,构建的防汛文档自动生成系统,在业务复杂度、数据量,以及智能化程度上都有一定的突破。
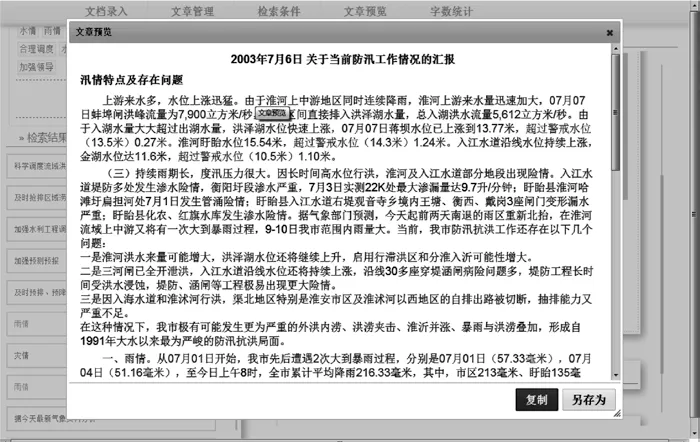
图8 文档预览页面
目前防汛文档自动生成系统已经投入使用,在实际使用中,能够满足防汛防旱指挥部对文档自动生成的业务需求,大大提高了防汛决策效率和准确性。但该系统目前的适用范围较小,今后可以在系统中进一步扩展其他文档生成功能,进一步提高水利行业文档编写的效率。
参考文献:
[1] 曲明成,廖明宏,吴翔虎,等. 一种文档自动生成模型的构建及其应用[J]. 计算机集成制造系统, 2008, 14 (7): 1297-1305.
[2] Buchner J, Fehnl T, Kunstmann T. HotDoc: a flexible framework for spatial composition[C]//Visual Languages, 1997. Proceedings. 1997 IEEE Symposium on. IEEE, 1997: 92-99.
[3] 葛芬,吴宁. 基于多种技术的 Word 设计文档自动生成平台[J]. 电子科技大学学报,2007, 36 (2): 263-266.
[4] 曾庆良,王伟,范文慧,等. 基于 XML/Macro 的文档自动生成系统的研究与实现[J]. 计算机应用研究,2006 (7): 121-122.
[5] 亓祥波,南琳,张福顺. 基于元数据和 XML 的信息抽取 与集成技术研究[J]. 信息与控 制,2008, 37 (1): 52-57.
[6] 马腾. 基于 ontology 的信息抽取系统的研究与实现[D]. 电子科技大学,2006.
[7] 代建华,李元香. 粗集中属性约简的一种启发式遗传算法[J]. 西安交通大学学报,2002, 36 (12): 1286-1290.
[8] Pawlak Z, Skowron A. Rough set rudiments[J]. Bulletin of International Rough Set Society, 1999, 3 (4): 181-185.
[9] 罗海滨,范玉顺,吴澄. 工作流技术综述[J]. 软件学报,2000, 11 (7): 899-907.
[10] 李伟平,李莉,薛劲松,等. 工作流管理系统实现技术研究[J]. 计算机集成制造系统,2002, 8 (3): 202-206.
猜你喜欢
大众科学(2022年8期)2022-08-26
今日农业(2020年15期)2020-12-15
小学阅读指南·低年级版(2020年9期)2020-10-12
阅读(快乐英语高年级)(2020年9期)2020-01-08
福建基础教育研究(2019年11期)2019-05-28
人大建设(2018年9期)2018-11-13
中学数学研究(广东)(2018年24期)2018-03-12
散文诗(2017年17期)2018-01-31
治淮(2017年5期)2017-06-01
读写算(下)(2016年11期)2016-05-04
