
基于HTK的白族语音识别方法
2013-09-19 09:28:08张令通
大理大学学报 2013年10期
张令通
(大理学院工程学院,云南大理 671003)
由于计算机应用的日益普及,需要人与计算机进行语音交互的场合越来越多,如语音拨号、语音监听、声控家电、智能信息服务等。语音识别技术的研究目的是让计算机听懂人的语言,包括白族等少数民族语言。而目前国内大多数语音识别的工作都是针对汉语普通话进行的,对少数民族语言,仅有少数人对为数不多的几种语言进行了语音识别研究,而对白族语识别的研究目前尚属空白。白族具有悠久的历史,特别是经历了南诏、大理国时期的繁荣与发展,创造出了灿烂辉煌的民族文化,但在形式上,虽然曾经创立了新、老两种白族文字,但由于官方没有进行规范和推广,白文一直没能发展为全民族通用的文字,大多数白族文学艺术作品都是靠口头创作,口耳相传〔1〕。在当今经济全球化的大环境中,在西方强势文化的冲击下,以及随着汉语普通话在少数民族地区的进一步普及,白族语和其他少数民族的语言一样正面临着消亡的危境。让计算机能够识别少数民族语音是保护和传承民族文化的重要手段之一,因此研究计算机对少数民族语音的识别具有积极的意义。
通过对白族语音特征的分析和研究,根据白族语音辅音、元音及音调较汉语更为复杂,其声、韵、调相互依存制约的关系非常密切,音节发音有松与紧的区别的特点,提出了一种应用隐马尔可夫模型工具箱(Hidden Markov Model Toolkit,HTK)实现计算机对白族语音进行识别的方法,以白族语音素为基本识别单元,通过提取白族语音信号的39维Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)为特征参数,使用Viterbi算法完成隐马尔可夫模型(Hidden Markov Model,HMM)参数的训练,然后用训练好的HMM模型与输入的语音数据进行匹配来实现识别。
1 白族语音特征分析
白族语属于汉藏语系藏缅语族,与汉藏语系的其他语言一样,白族语也是单音节的词根语,词序和虚词是表示语法意义的重要手段。由于和汉语、藏缅语密切而复杂的关系,白族语在语音、词汇、语法上既有很多和藏缅语对应的地方,也有不少特点和汉语相同或相似,但也有着其独特的语言特征。白族语语音的一般特征如下:辅音方面,有双唇、唇齿、舌尖、舌面、舌根5组,共21个辅音,此外,其中的怒江方言还另有舌尖后和小舌2组辅音,其塞音和塞擦音有清、浊对立;元音方面,分松紧2类,包括8个单元音,8个复元音和14个鼻化元音共30个。白族语辅、元音情况见表1和表2。声调方面,有8个声调,声调和声母有密切联系,并可按元音松紧分为松紧2类。词汇上,单音节词较多,多音节词较少。构词形式有附加式、重叠式和复合式3类。白族语词汇中还有大量的汉语借词(用音译的方式借用汉语词汇),汉语借词的声调和白族语的声调之间有明显的对应关系〔2〕。

表1 白族语辅音表

表2 白族语元音表
2 算法原理
本文所提白族语音识别方法利用HTK工具对白族语音进行训练和识别。训练作为识别的前提,其结果是提供能够表征白族语音音频信号特征的诸多模型参数,而识别过程则是将输入音频信号与模型进行模式匹配,计算各个模型的输出概率。基于HTK的白族语音识别算法原理如图1所示。
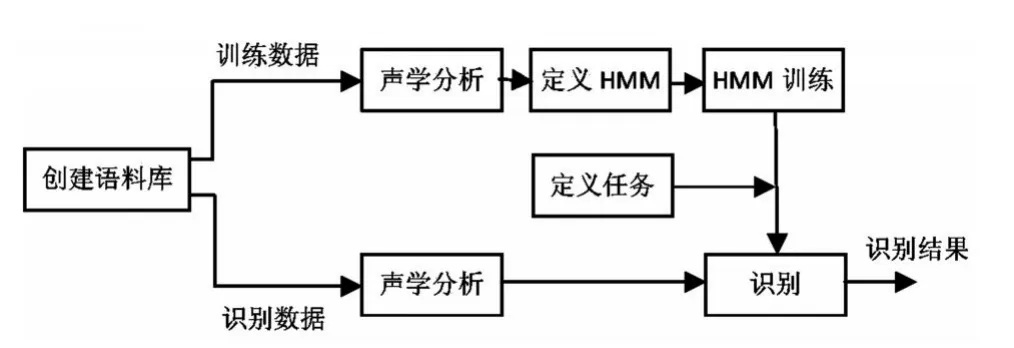
图1 白族语音识别算法原理图
2.1 HTK简介 HTK是由英国剑桥大学工程系(CUED)研发的一套基于HMM的工具箱,主要用于语音识别研究〔3〕。HTK由一系列实现语音分析,训练以及进行识别结果分析的库模块构成,包括C语言形式的可用工具,可自由下载。具有良好的可读性和可扩充性,以及强大的调试功能,可以极大地缩短开发人员的编程时间,提高系统开发效率。其缺点是由于是基于Linux环境开发,因此只能以命令方式运行〔4〕。
2.2 创建语料库 为了对白族语音识别进行研究,建立了白族语音语料库。该语料库分别收录了包括数词、名词、动词、形容词和代词5大类13个小类355个白族语常用词汇,由于不同性别、年龄人的发音有所不同,因此选择了45位不同性别、年龄的白族人分别对上述355个词汇进行录音得到45组音频数据,其中男性25、女性20人,年龄在20岁以下11人,20岁至35岁12人,36岁至50岁12人,51岁以上10人。音频数据文件的格式均为单声道、采样速率16 kHz、解析度16 bit的WAV格式语音文件。
利用HTK的HSLab工具进行语音信号的录制和标注。每次录音均用一个.wav格式文件保存。录制完成后,要对语音信号进行标注,利用HSLab模块的Mark功能,选择你要打标签的区域进行标注,应标注3个连续的区域:开始停顿(标记为sil)、录音音频信号、结束停顿(标记为sil)。对于白族语音而言,由于其元、辅音及音调较多,且还有松、紧之分,同一词汇在不同语境下发音会有不同,以单词为基本识别单元对识别的准确率有较大影响。因此采用音素作为识别的基本单元,以所有白族语的元、辅音作为音素,将每个单词切分为若干个音素组合而成,以〔sil音素列表sil〕的格式进行语音标注。这三个区域不能重叠(即使它们之间间隙很小)。这三个标注完成之后,将标签文件以.lab格式保存。将上述45组音频信号进行标注后,分别作为训练数据和识别数据进行训练和识别。以音素作为音频信号的基本识别单元,能够获取到更多的音频特征,从而保证了有较高的识别率。
2.3 声学分析 语音识别工具不能直接处理波形语音,需要通过更简洁有效的方法来表示波形语音,这就是声学分析〔5〕。声学分析包含以下步骤。
(1)分帧
在实际处理时可以将语音信号分成很小的时间段,称之为“帧”,作为语音信号处理的最小单位,帧与帧的非重叠部分称为帧移,而将语音信号分成若干帧的过程称为分帧。将语音信号分成连续的帧,一般每帧长度介于20~40 ms之间,帧移为帧长的1/3~1/2。
(2)预加重
预加重的目的是加强语音中的高频共振峰,使语音信号的短时频谱变得更为平坦,还可以起到消除直流漂移、抑制随机噪声和提高清音部分能量的效果,便于进行频谱分析和声道参数分析。预加重采用一阶零点数字滤波器来实现。
(3)加窗
加窗的目的是使信号主瓣更尖锐,旁瓣更低。语音信号数字处理中常用的窗函数是矩形窗和汉明窗,本文选取的是汉明窗,使每帧与窗函数相乘来实现加窗。
(4)特征提取
特征提取是对原始的语音信号运用一定的数字信号处理技术进行适当的处理,从而得到一个矢量序列,这个矢量序列可以代表原始的语音信号所携带的信息,初步实现数据压缩。特征参数主要有:能量、幅度、过零率、频谱、倒谱和功率谱等,本文选用了Mel频率倒谱系数(MFCC)进行特征参数的提取。
利用HTK的HCopy工具可用来转换原始波形文件,生成一系列声学向量,其中包括.conf格式的配置文件,用于设置声学系数提取参数。.txt格式的文本文件用于指定用于处理的每个波形文件的名称和存放位置,以及目标系数文件的名称和存放位置。由于MFCC特征是基于人的听觉特性利用人听觉的屏蔽效应,在Mel标度频率域提取出来的倒谱特征参数,它充分考虑了人的听觉特性,而且没有任何前提假设,具有良好的识别性能和抗噪能力。因此,在配置文件中,使用了MFCC分析,对每个信号帧,提取39个MFCC系数向量。
2.4 定义HMM 识别模型的选择是语音识别系统中最重要的环节。选择识别模型的目的是在特征空间上把不同的识别基元区分开来。HMM模型能够描述语音信号特征的动态变化和统计分布,是准平稳时变信号的有利分析工具。该模型在语音识别系统中得到广泛的应用〔6〕。
每个声学事件需要使用HMM隐马尔可夫模型建模,设计一个HMM模型。首先要为每个HMM模型选择一个priori结构。选择priori结构主要应考虑状态数、观察函数的形式(对应每个状态)和状态转换排列。在这里,我们为每个HMM模型选择如图2所示的结构。
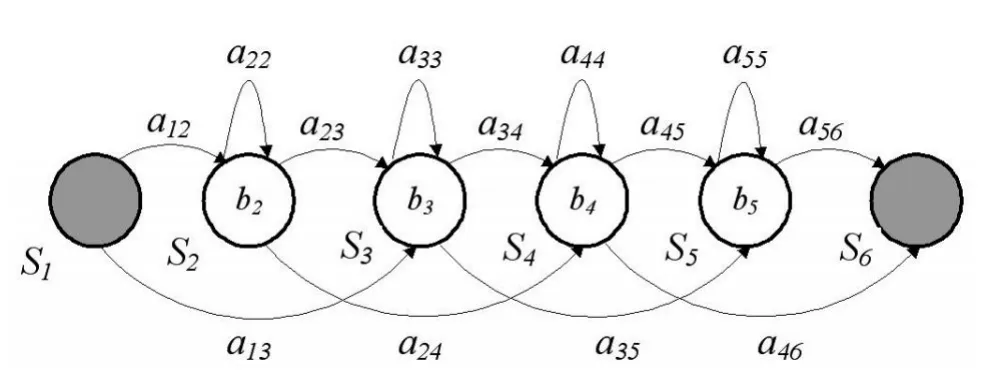
图2HMM模型结构
该模型包含4个活动状态{S2,S3,S4,S5}以及开始和结束状态{S1,S6},{S1,S6}是非发散状态(无观察函数),仅供HMM语音识别工具用于一些功能的实现。观察函数bi是带对角矩阵的高斯分布。aij表示由状态i转换到状态j的可能性。aij为Null值则说明相应的转换不允许。其它值将被进行强制初始化,只要保证矩阵的每行之和为1即可,在训练过程中再根据实际情况对其进行修改。
在HTK中,HMM模型是通过文本文件来描述的〔7〕。在描述模型的文件中包含系数向量大小(39个系数)、系数类型(MFCC)、HMM模型名称、模型的状态总数、模型的观察函数(使用带有对角矩阵的单一高斯观察函数)、观察函数的平均向量、观察函数的变化向量、HMM模型的6×6转换矩阵等信息。
2.5 HMM模型训练 构建好的每一个HMM初始化模型使用Viterbi算法训练其每个HMM模型参数,生成HMM模型库。训练HMM模型就是通过重估迭代,估计HMM模型参数(每个观察函数的变换可能性、加平均、变化向量等)的最佳值。利用HTK工具进行模型训练的过程描述如图3所示。
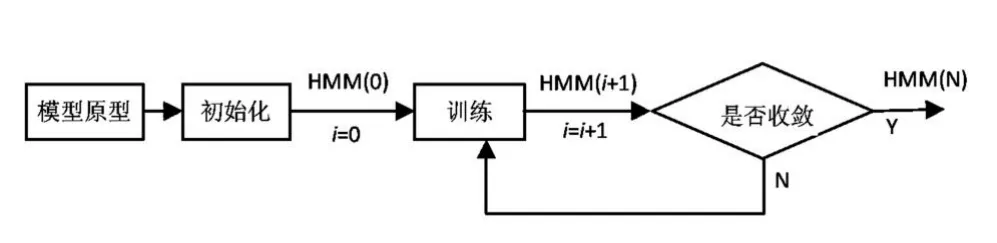
图3 完整的训练过程
2.5.1 初始化 在训练过程开始之前,为了使得训练算法快速精准收敛,HMM模型参数必须根据训练数据正确初始化。HTK提供了2个不同的初始化工具:HInit和 HCompv。
HInit工具是使用Viterbi算法通过训练数据的时间轴对HMM模型进行初始化,由HInit输出的HMM模型文件和输入原型具有相同的名字。HCompv工具用来对模型进行平坦初始化。HMM模型的每个状态给定相同的在整个训练集上全局计算而得的平均向量和变化向量。
在训练迭代过程中,与特定HMM模型状态相关联的训练帧数可能很低。该状态的估计变化值会很小(如果只有一个可用的训练帧的话,变化甚至为空Null)。这种情况下,可用基底来替代,避免变化值趋于极小(甚至产生计算错误)〔8〕。
2.5.2 训练 训练的首要问题是估计模型的参数λ,使在此模型下,产生给定训练数据X的似然值P(X/λ)最大。在此采用高斯混合模型(GMM)来估计模型参数〔9〕。GMM是用多个N维高斯分布概率密度函数的加权组合来描述矢量在概率空间分布的混合模型。一个M阶高斯混模型就是M个单高斯分布的加权组合。不同的M值将会产生不同的模型参数,从而也会对识别结果产生影响。GMM个数M越大,将越逼近状态空间的本来的分布,因而识别效果也将更好,但是随着M增大,自由参数的数目也会迅速的增加,容易导致各个参数训练不充分,反而会降低系统识别效果。同时M增大也会大大增加计算量,因此M并非越大越好。
使用HTK的HRest工具可实现一次再估计迭代,估计HMM模型参数(每个观察函数的变换可能性、加平均、变化向量)的最佳值,对于每个要训练的HMM模型,这个过程要重复许多次。每次HRest迭代(即当前再估计迭代中的迭代)显示在屏幕上,通过change量度标示收敛性。一旦这个量度值不再从一个HRest迭代到下个迭代减少(绝对值),过程就该停止了。在实际应用中,2或3次再估计迭代就足够了。
2.6 识别 识别过程就是将待识别的音频信号的特征与HMM模型进行模式匹配〔10〕。首先利用HTK的HCopy工具对待识别音频信号进行声学分析,得到其MFCC参数序列。根据所提取的特征,利用HTK的HVite工具与训练得到的HMM模板进行匹配,然后使用Viterbi算法处理输入观察,该算法用来测试输入观察是否与识别器的HMM模型相一致。根据输入的待识别音频语音信号特征相对于HMM模型库中的模板的输出概率或失真距离来确认识别结果。输出概率越大或失真距离越小就说明待识别样本语音信号与HMM模型库中该样本语音信号的模板更接近〔11〕。
3 实验结果及分析
3.1 实验目的和实验数据 为了检验基于HTK的白族语音识别算法的性能,搭建了以该算法为模型的系统,通过实验分别获得在不同MFCC维数和不同GMM个数条件下的基于单词级特征和基于因素级特征的性能参数。
实验数据来自自建的白族语音语料库中的45组,每组355个音频数据。在实验中,选取44组数据用于模型训练,1组数据用于识别,为了避免因数据集有限而导致模型“欠训练”的问题,采用了十字交叉法进行实验,从而保证结果的准确性、可靠性、普适性和完备性等特征。
3.2 评价方法说明 使用HTK性能评估工具HResults对识别结果进行评价〔12〕。该工具对识别结果采用动态规划的方法,将其与参考序列进行最优对齐,计算它们之间的替代、删除、插入误差,以识别正确率A为最终评价指标〔13〕:

其中,N:数据源中词的总数,
D:识别结果中删除的词的个数,
S:识别结果中替换的词的个数,
I:识别结果中插入的词的个数。
3.3 实验过程及结果 实验过程及结果如下。
(1)特征选取实验
将语料库中的45组白族语音的音频数据进行标注,从其中任选44组数据用于训练HMM模型,另外1组数据用于识别,并采用十字交叉法进行实验。以基于音素级特征进行实验,并通过改变MFCC维数观察识别结果。实验结果如表3所示。

表3 不同MFCC维数的识别率A
实验结果表明,对于白族语音,随着MFCC维数的增加,识别率是成单调上升的。
(2)模型中参数M选取实验
在HMM模型下,GMM个数M大小对识别结果是有很大影响的,在实验中,通过改变M观察对实验结果的影响。以39维MFCC参数为基准,实验结果如表4所示。

表4 不同GMM个数M识别率A的影响
实验结果表明,随着GMM个数的增加,识别准确率随之上升,但当M>6后,识别准确率不再上升甚至有所下降,而M增大会大大增加计算量,所以M并非越大越好,由实验结果得出M的最佳值为6,最高识别准确率为93.3%。
4 结束语
本文提出的基于HTK的白族语音识别的方法,经过充分分析白族语发音特点,将白族语音分割为音素的组合,以音素为基本识别单元,通过提取并处理音频信号的MFCC特征参数,建立HMM模型,采用Viterbi算法进行模型训练和匹配。利用HTK工具搭建了系统原型,并采用自建语料库中的白族语音音频数据进行了测试,实验结果表明,该方法具有较高的识别准确率,为进一步开展白族语大规模连续语音识别、不同方言白族语说话人识别奠定了良好的基础,同时也对其他少数民族语音识别研究具有较好的参考价值。
〔1〕赵金灿,闫正锐,张钰芳.白族语言使用现状及语言态度调查〔J〕.大理学院学报,2012,11(8):31-35.
〔2〕徐琳,赵衍荪.白语简志〔M〕.北京:民族出版社,1984.
〔3〕Lipeika Antanas,Lipeikiene Joana.On the use of the formant features in the dynamic time warping based recognition of isolated words〔J〕.Informatica,2008,19(2):213-226.
〔4〕Chaiwongsai,Jirabhorn.An architecture of HMM-based isolated-word speech recognition with tone detection function〔C〕//2008 International Symposium on Intelligent Signal Processing and Communication Systems.ISPACS,2008.
〔5〕魏巍,张海涛.一种基于HTK的数字语音识别系统〔J〕.计算机系统应用,2011,20(9):17-21.
〔6〕王炳锡,屈丹,彭煊.实用语音识别基础〔M〕.北京:国防工业出版社,2005.
〔7〕涂俊辉,续晋华.基于HTK的连续语音识别系统及其在TIMIT上的实验〔J〕.现代计算机,2009,319(11):29-33.
〔8〕Yuan Lichi.An improved HMM speech recognition model〔C〕//2008 International Conference on Audio,Language and Image Processing.2008:1311-1315.
〔9〕杨建华,于小宁.说话人识别中语音特征参数研究〔J〕.大理学院学报,2009,8(8):32-35.
〔10〕Fujimura H.N-Best rescoring by adaboost phoneme classifiers for isolated word recognition〔C〕//2011 IEEE Workshop on Automatic Speech Recognition&Understanding(ASRU).2011:83-85.
〔11〕Im Jung-Hui,Lee Soo-Young.Unified Training of Feature Extractor and HMM Classifier for Speech Recognition〔J〕.Signal Processing Letters,2012,19(2):111-114.
〔12〕曾妮,费洪晓,姜振飞.基于HTK的特定词语音识别系统〔J〕.计算机系统应用,2011,20(3):157-160.
〔13〕Kazemi A R.Isolated word recognition based on intelligent segmentation by using hybrid HTD-HMM〔C〕//5th WSEAS International Conference on Circuits,Systems,Signal and Telecommunications(CISST'11).2011:38-41.
猜你喜欢
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
家庭影院技术(2018年11期)2019-01-21 02:20:52
小说界(2018年5期)2018-11-26 12:43:42
电子制作(2018年19期)2018-11-14 02:37:08
大理文化(2017年6期)2017-07-31 22:06:55
电子制作(2017年9期)2017-04-17 03:00:46
民族音乐(2016年1期)2016-08-28 20:02:52
启蒙(3-7岁)(2016年9期)2016-02-28 12:26:55
